Hadoop(2)HDFS文件系统
- 一 HDFS概念
- 1 概念
- 2 组成
- 3 HDFS文件块大小
- 二 HFDS命令行操作
- 1 基本语法
- 2 参数大全
- 3常用命令实操
- 三 HDFS客户端操作
- 1 eclipse环境准备
- jar包准备
- eclipse准备
- 2 通过API操作HDFS
- HDFS获取文件系统
- HDFS文件上传
- HDFS文件下载
- HDFS目录创建
- HDFS文件夹删除
- HDFS文件名更改
- HDFS文件详情查看
- HDFS文件夹查看
- 3 通过IO流操作HDFS
- HDFS文件上传
- HDFS文件下载
- 定位文件读取
- 1 eclipse环境准备
- 四 HDFS的数据流
- 1 HDFS写数据流程
- 剖析文件写入
- 网络拓扑概念
- 机架感知副本节点选择
- 2 HDFS读数据流程
- 3 一致性模型
- 1 HDFS写数据流程
- 五 NameNode工作机制
- 1 51 NameNodeSecondary NameNode工作机制
- 2 镜像文件和编辑日志文件
- 3 滚动编辑日志
- 4 namenode版本号
- 5 SecondaryNameNode目录结构
- 6 集群安全模式操作
- 7 Namenode多目录配置
- 六 DataNode工作机制
- 1 DataNode工作机制
- 2 数据完整性
- 3 掉线时限参数设置
- 4 DataNode的目录结构
- 5 服役新数据节点
- 6 退役旧数据节点
- 7 Datanode多目录配置
一、 HDFS概念
1、 概念
HDFS,它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的设计适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合用来做网盘应用。
2、 组成
1)HDFS集群包括,NameNode和DataNode以及Secondary Namenode。
2)NameNode负责管理整个文件系统的元数据,以及每一个路径(文件)所对应的数据块信息。
3)DataNode 负责管理用户的文件数据块,每一个数据块都可以在多个datanode上存储多个副本。
4)Secondary NameNode用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
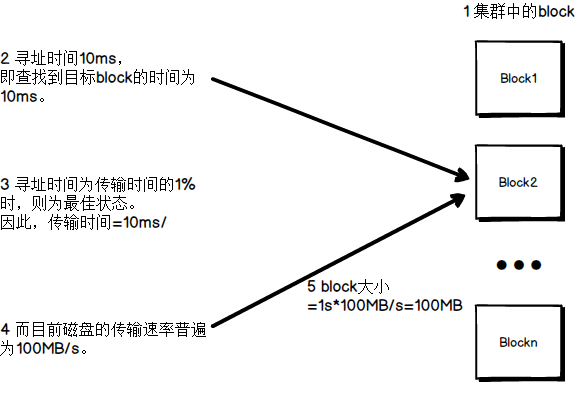
3、 HDFS文件块大小
HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M
HDFS的块比磁盘的块大,其目的是为了最小化寻址开销。如果块设置得足够大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。因而,传输一个由多个块组成的文件的时间取决于磁盘传输速率。
如果寻址时间约为10ms,而传输速率为100MB/s,为了使寻址时间仅占传输时间的1%,我们要将块大小设置约为100MB。默认的块大小128MB。
块的大小:10ms*100*100M/s = 100M
二、 HFDS命令行操作
1、 基本语法
bin/hadoop fs 具体命令
2、 参数大全
`bin/hadoop fs`
[-appendToFile ... ]
[-cat [-ignoreCrc] ...]
[-checksum ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] ... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] ... ]
[-copyToLocal [-p] [-ignoreCrc] [-crc] ... ]
[-count [-q] ...]
[-cp [-f] [-p] ... ]
[-createSnapshot []]
[-deleteSnapshot ]
[-df [-h] [ ...]]
[-du [-s] [-h] ...]
[-expunge]
[-get [-p] [-ignoreCrc] [-crc] ... ]
[-getfacl [-R] ]
[-getmerge [-nl] ]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [ ...]]
[-mkdir [-p] ...]
[-moveFromLocal ... ]
[-moveToLocal ]
[-mv ... ]
[-put [-f] [-p] ... ]
[-renameSnapshot ]
[-rm [-f] [-r|-R] [-skipTrash] ...]
[-rmdir [--ignore-fail-on-non-empty] ...]
[-setfacl [-R] [{-b|-k} {-m|-x } ]|[--set ]]
[-setrep [-R] [-w] ...]
[-stat [format] ...]
[-tail [-f] ]
[-test -[defsz] ]
[-text [-ignoreCrc] ...]
[-touchz ...]
[-usage [cmd ...]] 3、常用命令实操
(1)-help:输出这个命令参数
bin/hdfs dfs -help rm
(2)-ls: 显示目录信息
hadoop fs -ls /
(3)-mkdir:在hdfs上创建目录
hadoop fs -mkdir -p /aaa/bbb/cc/dd
(4)-moveFromLocal从本地剪切粘贴到hdfs
hadoop fs - moveFromLocal /home/hadoop/a.txt /aaa/bbb/cc/dd
(5)-moveToLocal:从hdfs剪切粘贴到本地(尚未实现)
[atguigu@linux01 hadoop-2.7.2]$ hadoop fs -help moveToLocal
-moveToLocal :
Not implemented yet (6)–appendToFile :追加一个文件到已经存在的文件末尾
hadoop fs -appendToFile ./hello.txt /hello.txt
(7)-cat :显示文件内容
(8)-tail:显示一个文件的末尾
hadoop fs -tail /weblog/access_log.1
(9)-chgrp 、-chmod、-chown:linux文件系统中的用法一样,修改文件所属权限
hadoop fs -chmod 666 /hello.txt
hadoop fs -chown someuser:somegrp /hello.txt
(10)-copyFromLocal:从本地文件系统中拷贝文件到hdfs路径去
hadoop fs -copyFromLocal ./jdk.tar.gz /aaa/
(11)-copyToLocal:从hdfs拷贝到本地
hadoop fs -copyToLocal /user/hello.txt ./hello.txt
(12)-cp :从hdfs的一个路径拷贝到hdfs的另一个路径
hadoop fs -cp /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
(13)-mv:在hdfs目录中移动文件
hadoop fs -mv /aaa/jdk.tar.gz /
(14)-get:等同于copyToLocal,就是从hdfs下载文件到本地
hadoop fs -get /user/hello.txt ./
(15)-getmerge :合并下载多个文件,比如hdfs的目录 /aaa/下有多个文件:log.1, log.2,log.3,…
hadoop fs -getmerge /aaa/log.* ./log.sum
(16)-put:等同于copyFromLocal
hadoop fs -put /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
(17)-rm:删除文件或文件夹
hadoop fs -rm -r /aaa/bbb/
(18)-rmdir:删除空目录
hadoop fs -rmdir /aaa/bbb/ccc
(19)-df :统计文件系统的可用空间信息
hadoop fs -df -h /
(20)-du统计文件夹的大小信息
[admin@linux01 hadoop-2.7.2]$ hadoop fs -du -s -h /user/atguigu/wcinput
188.5 M /user/atguigu/wcinput[admin@linux01 hadoop-2.7.2]$ hadoop fs -du -h /user/atguigu/wcinput
188.5 M /user/atguigu/wcinput/hadoop-2.7.2.tar.gz
97 /user/atguigu/wcinput/wc.input(21)-count:统计一个指定目录下的文件节点数量
hadoop fs -count /aaa/
[admin@linux01 hadoop-2.7.2]$ hadoop fs -count /user/atguigu/wcinput
1 2 197657784 /user/atguigu/wcinput
嵌套文件层级; 包含文件的总数(22)-setrep:设置hdfs中文件的副本数量
hadoop fs -setrep 3 /aaa/jdk.tar.gz

这里设置的副本数只是记录在namenode的元数据中,是否真的会有这么多副本,还得看datanode的数量。因为目前只有3台设备,最多也就3个副本,只有节点数的增加到10台时,副本数才能达到10。
三、 HDFS客户端操作
1、 eclipse环境准备
1 jar包准备
1)解压hadoop-2.7.2.tar.gz到非中文目录
2)进入share文件夹,查找所有jar包,并把jar包拷贝到_lib文件夹下
3)在全部jar包中查找sources.jar,并剪切到_source文件夹。
4)在全部jar包中查找tests.jar,并剪切到_test文件夹。
2 eclipse准备
1)配置HADOOP_HOME环境变量
2)采用hadoop编译后的bin 、lib两个文件夹(如果不生效,重新启动eclipse)
3)创建第一个java工程
public class HdfsClientDemo1 {
public static void main(String[] args) throws Exception {
// 1 获取文件系统
Configuration configuration = new Configuration();
// 配置在集群上运行
configuration.set("fs.defaultFS", "hdfs://linux01:9000");
FileSystem fileSystem = FileSystem.get(configuration);
// 直接配置访问集群的路径和访问集群的用户名称
// FileSystem fileSystem = FileSystem.get(new URI("hdfs://linux01:9000"),configuration, "atguigu");
// 2 把本地文件上传到文件系统中
fileSystem.copyFromLocalFile(new Path("f:/hello.txt"), new Path("/hello1.copy.txt"));
// 3 关闭资源
fileSystem.close();
System.out.println("over");
}
}
4)执行程序
运行时需要配置用户名称
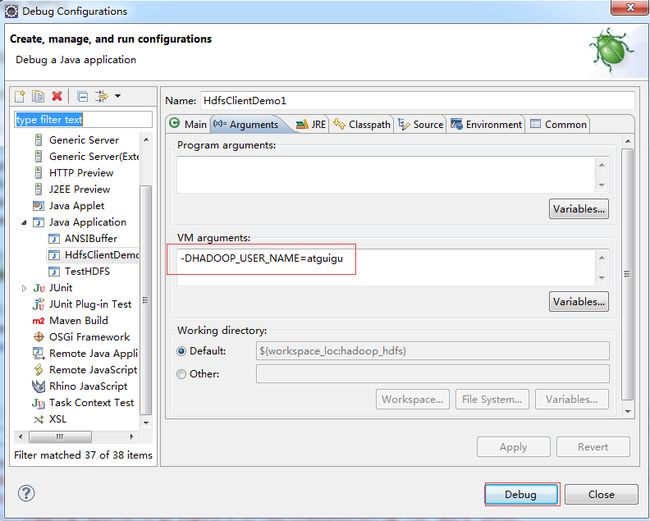
客户端去操作hdfs时,是有一个用户身份的。默认情况下,hdfs客户端api会从jvm中获取一个参数来作为自己的用户身份:-DHADOOP_USER_NAME=admin,admin为用户名称。
2、 通过API操作HDFS
1 HDFS获取文件系统
1)详细代码
@Test
public void initHDFS() throws Exception{
// 1 创建配置信息对象
// new Configuration();的时候,它就会去加载jar包中的hdfs-default.xml
// 然后再加载classpath下的hdfs-site.xml
Configuration configuration = new Configuration();
// 2 设置参数
// 参数优先级: 1、客户端代码中设置的值 2、classpath下的用户自定义配置文件 3、然后是服务器的默认配置
// configuration.set("fs.defaultFS", "hdfs://linux01:9000");
configuration.set("dfs.replication", "3");
// 3 获取文件系统
FileSystem fs = FileSystem.get(configuration);
// 4 打印文件系统
System.out.println(fs.toString());
}2)将core-site.xml拷贝到项目的根目录下
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://linux01:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/module/hadoop-2.7.2/data/tmpvalue>
property>
configuration>2 HDFS文件上传
@Test
public void putFileToHDFS() throws Exception{
// 1 创建配置信息对象
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://linux01:9000"),configuration, "admin");
// 2 创建要上传文件所在的本地路径
Path src = new Path("e:/hello.txt");
// 3 创建要上传到hdfs的目标路径
Path dst = new Path("hdfs://linux01:9000/user/admin/hello.txt");
// 4 拷贝文件
fs.copyFromLocalFile(src, dst);
fs.close();
}3 HDFS文件下载
@Test
public void getFileFromHDFS() throws Exception{
// 1 创建配置信息对象
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://linux01:9000"),configuration, "admin");
// fs.copyToLocalFile(new Path("hdfs://linux01:9000/user/admin/hello.txt"), new Path("d:/hello.txt"));
// boolean delSrc 指是否将原文件删除
// Path src 指要下载的文件路径
// Path dst 指将文件下载到的路径
// boolean useRawLocalFileSystem 是否开启文件效验
// 2 下载文件
fs.copyToLocalFile(false, new Path("hdfs://linux01:9000/user/admin/hello.txt"), new Path("e:/hellocopy.txt"), true);
fs.close();
}4 HDFS目录创建
@Test
public void mkdirAtHDFS() throws Exception{
// 1 创建配置信息对象
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://linux01:9000"),configuration, "admin");
//2 创建目录
fs.mkdirs(new Path("hdfs://linux01:9000/user/admin/output"));
}5 HDFS文件夹删除
@Test
public void deleteAtHDFS() throws Exception{
// 1 创建配置信息对象
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://linux01:9000"),configuration, "admin");
//2 删除文件夹 ,如果是非空文件夹,参数2必须给值true
fs.delete(new Path("hdfs://linux01:9000/user/admin/output"), true);
}6 HDFS文件名更改
@Test
public void renameAtHDFS() throws Exception{
// 1 创建配置信息对象
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://linux01:9000"),configuration, "admin");
//2 重命名文件或文件夹
fs.rename(new Path("hdfs://linux01:9000/user/admin/hello.txt"), new Path("hdfs://linux01:9000/user/admin/hellonihao.txt"));
}7 HDFS文件详情查看
@Test
public void readListFiles() throws Exception {
// 1 创建配置信息对象
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://linux01:9000"),configuration, "admin");
// 思考:为什么返回迭代器,而不是List之类的容器
RemoteIterator listFiles = fs.listFiles(new Path("/"), true);
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println(fileStatus.getPath().getName());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getLen());
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
for (BlockLocation bl : blockLocations) {
System.out.println("block-offset:" + bl.getOffset());
String[] hosts = bl.getHosts();
for (String host : hosts) {
System.out.println(host);
}
}
System.out.println("--------------分割线--------------");
}
} 8 HDFS文件夹查看
@Test
public void findAtHDFS() throws Exception, IllegalArgumentException, IOException{
// 1 创建配置信息对象
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://linux01:9000"),configuration, "admin");
// 2 获取查询路径下的文件状态信息
FileStatus[] listStatus = fs.listStatus(new Path("/"));
// 3 遍历所有文件状态
for (FileStatus status : listStatus) {
if (status.isFile()) {
System.out.println("f--" + status.getPath().getName());
} else {
System.out.println("d--" + status.getPath().getName());
}
}
}3、 通过IO流操作HDFS
1 HDFS文件上传
@Test
public void putFileToHDFS() throws Exception{
// 1 创建配置信息对象
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://linux01:9000"),configuration, "admin");
// 2 创建输入流
FileInputStream inStream = new FileInputStream(new File("e:/hello.txt"));
// 3 获取输出路径
String putFileName = "hdfs://linux01:9000/user/admin/hello1.txt";
Path writePath = new Path(putFileName);
// 4 创建输出流
FSDataOutputStream outStream = fs.create(writePath);
// 5 流对接
try{
IOUtils.copyBytes(inStream, outStream, 4096, false);
}catch(Exception e){
e.printStackTrace();
}finally{
IOUtils.closeStream(inStream);
IOUtils.closeStream(outStream);
}
}2 HDFS文件下载
@Test
public void getFileToHDFS() throws Exception{
// 1 创建配置信息对象
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://linux01:9000"),configuration, "admin");
// 2 获取读取文件路径
String filename = "hdfs://linux01:9000/user/admin/hello1.txt";
// 3 创建读取path
Path readPath = new Path(filename);
// 4 创建输入流
FSDataInputStream inStream = fs.open(readPath);
// 5 流对接输出到控制台
try{
IOUtils.copyBytes(inStream, System.out, 4096, false);
}catch(Exception e){
e.printStackTrace();
}finally{
IOUtils.closeStream(inStream);
}
}3 定位文件读取
1)下载第一块
@Test
// 定位下载第一块内容
public void readFileSeek1() throws Exception {
// 1 创建配置信息对象
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://linux01:9000"), configuration, "admin");
// 2 获取输入流路径
Path path = new Path("hdfs://linux01:9000/user/admin/tmp/hadoop-2.7.2.tar.gz");
// 3 打开输入流
FSDataInputStream fis = fs.open(path);
// 4 创建输出流
FileOutputStream fos = new FileOutputStream("e:/hadoop-2.7.2.tar.gz.part1");
// 5 流对接
byte[] buf = new byte[1024];
for (int i = 0; i < 128 * 1024; i++) {
fis.read(buf);
fos.write(buf);
}
// 6 关闭流
IOUtils.closeStream(fis);
IOUtils.closeStream(fos);
}2)下载第二块
@Test
// 定位下载第二块内容
public void readFileSeek2() throws Exception{
// 1 创建配置信息对象
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://linux01:9000"), configuration, "admin");
// 2 获取输入流路径
Path path = new Path("hdfs://linux01:9000/user/admin/tmp/hadoop-2.7.2.tar.gz");
// 3 打开输入流
FSDataInputStream fis = fs.open(path);
// 4 创建输出流
FileOutputStream fos = new FileOutputStream("e:/hadoop-2.7.2.tar.gz.part2");
// 5 定位偏移量(第二块的首位)
fis.seek(1024 * 1024 * 128);
// 6 流对接
IOUtils.copyBytes(fis, fos, 1024);
// 7 关闭流
IOUtils.closeStream(fis);
IOUtils.closeStream(fos);
}3)合并文件
在window命令窗口中执行
type hadoop-2.7.2.tar.gz.part2 >> hadoop-2.7.2.tar.gz.part1
四、 HDFS的数据流
1、 HDFS写数据流程
1 剖析文件写入

1)客户端向namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在。
2)namenode返回是否可以上传。
3)客户端请求第一个 block上传到哪几个datanode服务器上。
4)namenode返回3个datanode节点,分别为dn1、dn2、dn3。
5)客户端请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成
6)dn1、dn2、dn3逐级应答客户端
7)客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答
8)当一个block传输完成之后,客户端再次请求namenode上传第二个block的服务器。(重复执行3-7步)
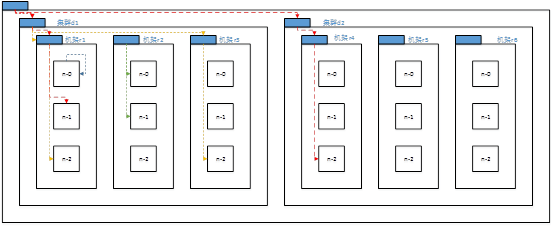
2 网络拓扑概念
在本地网络中,两个节点被称为“彼此近邻”是什么意思?在海量数据处理中,其主要限制因素是节点之间数据的传输速率——带宽很稀缺。这里的想法是将两个节点间的带宽作为距离的衡量标准。
节点距离:两个节点到达最近的共同祖先的距离总和。
例如,假设有数据中心d1机架r1中的节点n1。该节点可以表示为/d1/r1/n1。利用这种标记,这里给出四种距离描述。
Distance(/d1/r1/n1, /d1/r1/n1)=0(同一节点上的进程)
Distance(/d1/r1/n1, /d1/r1/n2)=2(同一机架上的不同节点)
Distance(/d1/r1/n1, /d1/r3/n2)=4(同一数据中心不同机架上的节点)
Distance(/d1/r1/n1, /d2/r4/n2)=6(不同数据中心的节点)
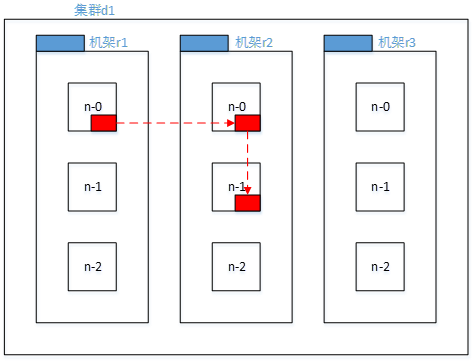
3 机架感知(副本节点选择)
1)官方ip地址:
http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/RackAwareness.html
http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#Data_Replication
2)低版本Hadoop副本节点选择
第一个副本在client所处的节点上。如果客户端在集群外,随机选一个。
第二个副本和第一个副本位于不相同机架的随机节点上。
第三个副本和第二个副本位于相同机架,节点随机。
3)Hadoop2.7.2副本节点选择
第一个副本在client所处的节点上。如果客户端在集群外,随机选一个。
第二个副本和第一个副本位于相同机架,随机节点。
第三个副本位于不同机架,随机节点。

2、 HDFS读数据流程
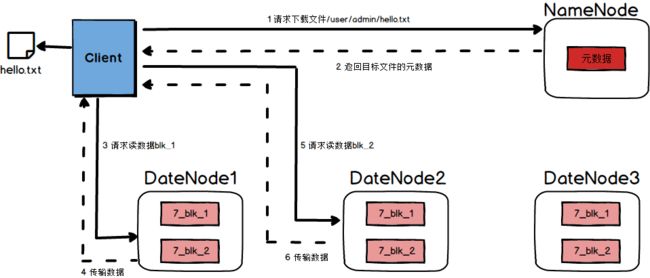
1)客户端向namenode请求下载文件,namenode通过查询元数据,找到文件块所在的datanode地址。
2)挑选一台datanode(就近原则,然后随机)服务器,请求读取数据。
3)datanode开始传输数据给客户端(从磁盘里面读取数据放入流,以packet为单位来做校验)。
4)客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
3、 一致性模型
1)debug调试如下代码
@Test
public void writeFile() throws Exception{
// 1 创建配置信息对象
Configuration configuration = new Configuration();
fs = FileSystem.get(configuration);
// 2 创建文件输出流
Path path = new Path("hdfs://hadoop102:9000/user/atguigu/hello.txt");
FSDataOutputStream fos = fs.create(path);
// 3 写数据
fos.write("hello".getBytes());
// 4 一致性刷新
fos.hflush();
fos.close();
}
2)总结
写入数据时,如果希望数据被其他client立即可见,调用如下方法
FsDataOutputStream. hflush (); //清理客户端缓冲区数据,被其他client立即可见五、 NameNode工作机制
1、 5.1 NameNode&Secondary NameNode工作机制
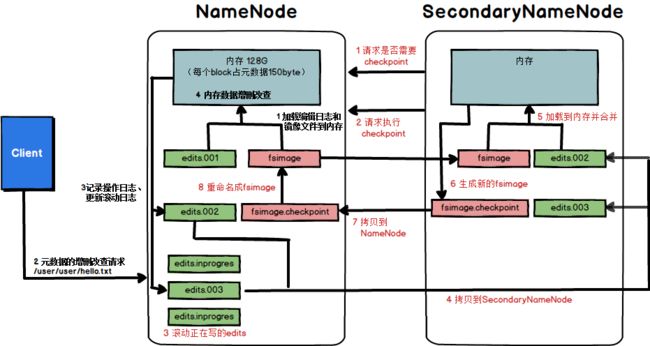
1)第一阶段:namenode启动
(1)第一次启动namenode格式化后,创建fsimage和edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求
(3)namenode记录操作日志,更新滚动日志。
(4)namenode在内存中对数据进行增删改查
2)第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问namenode是否需要checkpoint。直接带回namenode是否检查结果。
(2)Secondary NameNode请求执行checkpoint。
(3)namenode滚动正在写的edits日志
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint
(7)拷贝fsimage.chkpoint到namenode
(8)namenode将fsimage.chkpoint重新命名成fsimage
3)web端访问SecondaryNameNode
(1)启动集群
(2)浏览器中输入:http://linux01:50090/status.html
(3)查看SecondaryNameNode信息

4)chkpoint检查时间参数设置
(1)通常情况下,SecondaryNameNode每隔一小时执行一次。
[hdfs-default.xml]
<property>
<name>dfs.namenode.checkpoint.periodname>
<value>3600value>
property>
(2)一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
<property>
<name>dfs.namenode.checkpoint.txnsname>
<value>1000000value>
<description>操作动作次数description>
property>
<property>
<name>dfs.namenode.checkpoint.check.periodname>
<value>60value>
<description> 1分钟检查一次操作次数description>
property>
2、 镜像文件和编辑日志文件
1)概念
… namenode被格式化之后,将在/opt/module/hadoop-2.7.2/data/tmp/dfs/name/current目录中产生如下文件
edits_0000000000000000000
fsimage_0000000000000000000.md5
seen_txid
VERSION(1)Fsimage文件:HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和文件idnode的序列化信息。
(2)Edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到edits文件中。
(3)seen_txid文件保存的是一个数字,就是最后一个edits_的数字
(4)每次Namenode启动的时候都会将fsimage文件读入内存,并从00001开始到seen_txid中记录的数字依次执行每个edits里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成Namenode启动的时候就将fsimage和edits文件进行了合并。
2)oiv查看fsimage文件
(1)查看oiv和oev命令
[atguigu@hadoop102 current]$ hdfs
oiv apply the offline fsimage viewer to an fsimage
oev apply the offline edits viewer to an edits file(2)基本语法
hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径
(3)案例实操
[admin@linux01 current]$ pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs/name/current
[admin@linux01 current]$ hdfs oiv -p XML -i fsimage_0000000000000000025 -o /opt/module/hadoop-2.7.2/fsimage.xml
[admin@linux01 current]$ cat /opt/module/hadoop-2.7.2/fsimage.xml将显示的xml文件内容拷贝到eclipse中创建的xml文件中,并格式化。
3)oev查看edits文件
(1)基本语法
hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径
(2)案例实操
[admin@linux01 current]$ hdfs oev -p XML -i edits_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-2.7.2/edits.xml
[admin@linux01 current]$ cat /opt/module/hadoop-2.7.2/edits.xml将显示的xml文件内容拷贝到eclipse中创建的xml文件中,并格式化。
3、 滚动编辑日志
正常情况HDFS文件系统有更新操作时,就会滚动编辑日志。也可以用命令强制滚动编辑日志。
1)滚动编辑日志(前提必须启动集群)
[admin@linux01 current]$ hdfs dfsadmin -rollEdits2)镜像文件什么时候产生
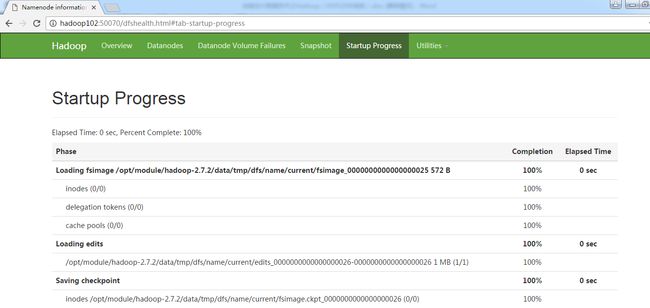
Namenode启动时加载镜像文件和编辑日志
4、 namenode版本号
1)查看namenode版本号
在/opt/module/hadoop-2.7.2/data/tmp/dfs/name/current这个目录下查看VERSION
namespaceID=1933630176
clusterID=CID-1f2bf8d1-5ad2-4202-af1c-6713ab381175
cTime=0
storageType=NAME_NODE
blockpoolID=BP-97847618-192.168.10.102-1493726072779
layoutVersion=-632)namenode版本号具体解释
(1) namespaceID在HDFS上,会有多个Namenode,所以不同Namenode的namespaceID是不同的,分别管理一组blockpoolID。
(2)clusterID集群id,全局唯一
(3)cTime属性标记了namenode存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为0;但是在文件系统升级之后,该值会更新到新的时间戳。
(4)storageType属性说明该存储目录包含的是namenode的数据结构。
(5)blockpoolID:一个block pool id标识一个block pool,并且是跨集群的全局唯一。当一个新的Namespace被创建的时候(format过程的一部分)会创建并持久化一个唯一ID。在创建过程构建全局唯一的BlockPoolID比人为的配置更可靠一些。NN将BlockPoolID持久化到磁盘中,在后续的启动过程中,会再次load并使用。
(6)layoutVersion是一个负整数。通常只有HDFS增加新特性时才会更新这个版本号。
5、 SecondaryNameNode目录结构
Secondary NameNode用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
在/opt/modules/hadoop-2.7.2/data/tmp/dfs/namesecondary/current这个目录中查看SecondaryNameNode目录结构。
edits_0000000000000000001-0000000000000000002
fsimage_0000000000000000002
fsimage_0000000000000000002.md5
VERSIONSecondaryNameNode的namesecondary/current目录和主namenode的current目录的布局相同。
好处:在主namenode发生故障时(假设没有及时备份数据),可以从SecondaryNameNode恢复数据。
方法一:将SecondaryNameNode中数据拷贝到namenode存储数据的目录;
方法二:使用-importCheckpoint选项启动namenode守护进程,从而将SecondaryNameNode用作新的主namenode。
1)案例实操(一):
模拟namenode故障,并采用方法一,恢复namenode数据
(1)kill -9 namenode进程
(2)删除namenode存储的数据(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/*
(3)拷贝SecondaryNameNode中数据到原namenode存储数据目录
cp -R /opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary/* /opt/module/hadoop-2.7.2/data/tmp/dfs/name/
(4)重新启动namenode
sbin/hadoop-daemon.sh start namenode
2)案例实操(二):
模拟namenode故障,并采用方法二,恢复namenode数据
(0)修改hdfs-site.xml中的
<property>
<name>dfs.namenode.checkpoint.periodname>
<value>120value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>/opt/module/hadoop-2.7.2/data/tmp/dfs/namevalue>
property>
(1)kill -9 namenode进程
(2)删除namenode存储的数据(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/*
(3)如果SecondaryNameNode不和Namenode在一个主机节点上,需要将SecondaryNameNode存储数据的目录拷贝到Namenode存储数据的平级目录。
[atguigu@hadoop102 dfs]$ pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs
[atguigu@hadoop102 dfs]$ ls
data name namesecondary(4)导入检查点数据(等待一会ctrl+c结束掉)
bin/hdfs namenode -importCheckpoint
(5)启动namenode
sbin/hadoop-daemon.sh start namenode
(6)如果提示文件锁了,可以删除in_use.lock
rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary/in_use.lock
6、 集群安全模式操作
1)概述
Namenode启动时,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作。一旦在内存中成功建立文件系统元数据的映像,则创建一个新的fsimage文件和一个空的编辑日志。此时,namenode开始监听datanode请求。但是此刻,namenode运行在安全模式,即namenode的文件系统对于客户端来说是只读的。
系统中的数据块的位置并不是由namenode维护的,而是以块列表的形式存储在datanode中。在系统的正常操作期间,namenode会在内存中保留所有块位置的映射信息。在安全模式下,各个datanode会向namenode发送最新的块列表信息,namenode了解到足够多的块位置信息之后,即可高效运行文件系统。
如果满足“最小副本条件”,namenode会在30秒钟之后就退出安全模式。所谓的最小副本条件指的是在整个文件系统中99.9%的块满足最小副本级别(默认值:dfs.replication.min=1)。在启动一个刚刚格式化的HDFS集群时,因为系统中还没有任何块,所以namenode不会进入安全模式。
2)基本语法
集群处于安全模式,不能执行重要操作(写操作)。集群启动完成后,自动退出安全模式。
(1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
(2)bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
(3)bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
(4)bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态)
3)案例
模拟等待安全模式
1)先进入安全模式
bin/hdfs dfsadmin -safemode enter
2)执行下面的脚本
编辑一个脚本
#!/bin/bash
bin/hdfs dfsadmin -safemode wait
bin/hdfs dfs -put ~/hello.txt /root/hello.txt3)再打开一个窗口,执行
bin/hdfs dfsadmin -safemode leave
7、 Namenode多目录配置
1)namenode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性。
2)具体配置如下:
hdfs-site.xml
<property>
<name>dfs.namenode.name.dirname>
<value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2value>
property>六、 DataNode工作机制
1、 DataNode工作机制

1)一个数据块在datanode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
2)DataNode启动后向namenode注册,通过后,周期性(1小时)的向namenode上报所有的块信息。
3)心跳是每3秒一次,心跳返回结果带有namenode给该datanode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个datanode的心跳,则认为该节点不可用。
4)集群运行中可以安全加入和退出一些机器
2、 数据完整性
1)当DataNode读取block的时候,它会计算checksum
2)如果计算后的checksum,与block创建时值不一样,说明block已经损坏。
3)client读取其他DataNode上的block.
4)datanode在其文件创建后周期验证checksum
3、 掉线时限参数设置
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval
而默认的dfs.namenode.heartbeat.recheck-interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。
<property>
<name>dfs.namenode.heartbeat.recheck-intervalname>
<value>300000value>
property>
<property>
<name> dfs.heartbeat.interval name>
<value>3value>
property>
4、 DataNode的目录结构
和namenode不同的是,datanode的存储目录是初始阶段自动创建的,不需要额外格式化。
1)在/opt/modules/hadoop-2.7.2/data/tmp/dfs/data/current这个目录下查看版本号
[admin@linux01 current]$ cat VERSION
storageID=DS-1b998a1d-71a3-43d5-82dc-c0ff3294921b
clusterID=CID-1f2bf8d1-5ad2-4202-af1c-6713ab381175
cTime=0
datanodeUuid=970b2daf-63b8-4e17-a514-d81741392165
storageType=DATA_NODE
layoutVersion=-562)具体解释
(1)storageID:存储id号
(2)clusterID集群id,全局唯一
(3)cTime属性标记了datanode存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为0;但是在文件系统升级之后,该值会更新到新的时间戳。
(4)datanodeUuid:datanode的唯一识别码
(5)storageType:存储类型
(6)layoutVersion是一个负整数。通常只有HDFS增加新特性时才会更新这个版本号。
3)在/opt/modules/hadoop-2.7.2/data/tmp/dfs/data/current/BP-97847618-192.168.10.102-1493726072779/current这个目录下查看该数据块的版本号
[admin@linux01 current]$ cat VERSION
#Mon May 08 16:30:19 CST 2017
namespaceID=1933630176
cTime=0
blockpoolID=BP-97847618-192.168.10.102-1493726072779
layoutVersion=-564)具体解释
(1)namespaceID:是datanode首次访问namenode的时候从namenode处获取的storageID对每个datanode来说是唯一的(但对于单个datanode中所有存储目录来说则是相同的),namenode可用这个属性来区分不同datanode。
(2)cTime属性标记了datanode存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为0;但是在文件系统升级之后,该值会更新到新的时间戳。
(3)blockpoolID:一个block pool id标识一个block pool,并且是跨集群的全局唯一。当一个新的Namespace被创建的时候(format过程的一部分)会创建并持久化一个唯一ID。在创建过程构建全局唯一的BlockPoolID比人为的配置更可靠一些。NN将BlockPoolID持久化到磁盘中,在后续的启动过程中,会再次load并使用。
(4)layoutVersion是一个负整数。通常只有HDFS增加新特性时才会更新这个版本号。
5、 服役新数据节点
0)需求:
随着公司业务的增长,数据量越来越大,原有的数据节点的容量已经不能满足存储数据的需求,需要在原有集群基础上动态添加新的数据节点。
1)环境准备
(1)克隆一台虚拟机
(2)修改ip地址和主机名称
(3)修改xcall和xsync文件,增加新增节点的同步
(4)删除原来HDFS文件系统留存的文件
/opt/modules/hadoop-2.7.2/data
2)服役新节点具体步骤
- (1)在namenode的/opt/module/hadoop-2.7.2/etc/hadoop目录下创建dfs.hosts文件
[admin@linux04 hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[admin@linux04 hadoop]$ touch dfs.hosts
[admin@linux04 hadoop]$ vi dfs.hosts
添加如下主机名称(包含新服役的节点)
linux01
linux02
linux03
linux04- (2)在namenode的hdfs-site.xml配置文件中增加dfs.hosts属性
<property>
<name>dfs.hostsname>
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hostsvalue>
property>- (3)刷新namenode
[admin@linux01 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful- (4)更新resourcemanager节点
[admin@linux01 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
17/06/24 14:17:11 INFO client.RMProxy: Connecting to ResourceManager at linux02/192.168.1.103:8033- (5)在namenode的slaves文件中增加新主机名称
增加105 不需要分发
linux01
linux02
linux03
linux04 - (6)单独命令启动新的数据节点和节点管理器
[admin@linux04 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-atguigu-datanode-linux04.out
[admin@linux04 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-atguigu-nodemanager-linux04.out- (7)在web浏览器上检查是否ok
3)如果数据不均衡,可以用命令实现集群的再平衡
[admin@linux01 sbin]$ ./start-balancer.sh
starting balancer, logging to /opt/module/hadoop-2.7.2/logs/hadoop-atguigu-balancer-linux01.out
Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved6、 退役旧数据节点
1)在namenode的/opt/modules/hadoop-2.7.2/etc/hadoop目录下创建dfs.hosts.exclude文件
[admin@linux01 hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[admin@linux01 hadoop]$ touch dfs.hosts.exclude
[admin@linux01 hadoop]$ vi dfs.hosts.exclude添加如下主机名称(要退役的节点)
linux04
2)在namenode的hdfs-site.xml配置文件中增加dfs.hosts.exclude属性
<property>
<name>dfs.hosts.excludename>
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts.excludevalue>
property>3)刷新namenode、刷新resourcemanager
[admin@linux01 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
[admin@linux01 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
17/06/24 14:55:56 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.1.103:80334)检查web浏览器,退役节点的状态为decommission in progress(退役中),说明数据节点正在复制块到其他节点。

5)等待退役节点状态为decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。注意:如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役。

[admin@linux04 hadoop-2.7.2]$ sbin/hadoop-daemon.sh stop datanode
stopping datanode
[admin@linux04 hadoop-2.7.2]$ sbin/yarn-daemon.sh stop nodemanager
stopping nodemanager6)从include文件中删除退役节点,再运行刷新节点的命令
(1)从namenode的dfs.hosts文件中删除退役节点linux04
linux01
linux02
linux03
(2)刷新namenode,刷新resourcemanager
[admin@linux01 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
[admin@linux01 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
17/06/24 14:55:56 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.1.103:80337)从namenode的slave文件中删除退役节点linux04
linux01
linux02
linux03
8)如果数据不均衡,可以用命令实现集群的再平衡
[admin@linux01 hadoop-2.7.2]$ sbin/start-balancer.sh
starting balancer, logging to /opt/module/hadoop-2.7.2/logs/hadoop-atguigu-balancer-linux01.out
Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved7、 Datanode多目录配置
1)datanode也可以配置成多个目录,每个目录存储的数据不一样。即:数据不是副本。
2)具体配置如下:
hdfs-site.xml
dfs.datanode.data.dir
file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2