Spring IOC 源码分析-bean标签解析
概述
Spring ioc 解析配置文件过程中,核心的处理就是解析bean标签
重点关系图
bean标签定义实体类- 在内存中的映射和继承关系图

这里的AbstractBeanDefinition 实现了对bean标签的缺省初始化配置,字段中保存了bean的大部分通用属性,比如scope,abstract,autoware等bean标签属性
bean解析类-用于解析bean标签的代理工具类
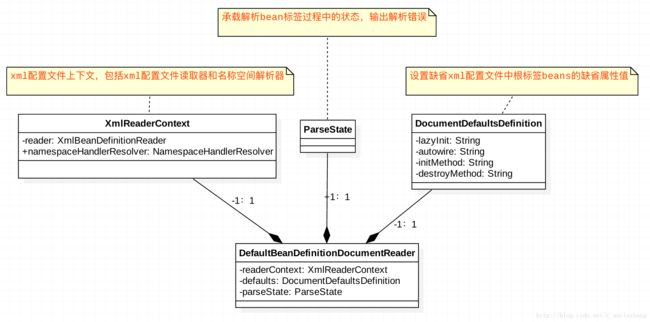
BeanDefinitionParserDelegate就是缺省bean解析器,主要用于解析bean标签 返回BeanDefinitionHolder,BeanDefinitionHolder实际上是一个包装类,用于装载解析后的bean,其中包括唯一性名称beanName和所有别名aliases数组,还有解析完成后的beanDefinition实例
代码流程分析
//解析bean标签的入口,ele为bean标签根节点元素(在前边已经通过document解析器读取xml配置文件并分离出Element(bean)元素,containingBean为嵌入beanDefinition,默认为null)
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele, @Nullable BeanDefinition containingBean) {
//提取id属性
String id = ele.getAttribute(ID_ATTRIBUTE);
//提取name属性
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
//如果包含多个名称,解析后放到别名数组中
List<String> aliases = new ArrayList<>();
if (StringUtils.hasLength(nameAttr)) {
String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);
aliases.addAll(Arrays.asList(nameArr));
}
String beanName = id;
if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) {
beanName = aliases.remove(0);
if (logger.isDebugEnabled()) {
logger.debug("No XML 'id' specified - using '" + beanName +
"' as bean name and " + aliases + " as aliases");
}
}
//坚持beanName在全局名称中是否唯一
if (containingBean == null) {
checkNameUniqueness(beanName, aliases, ele);
}//正式开始解析ele
AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);进入parseBeanDefinitionElement方法
//把当前解析的bean名称封装成实体入栈,方便后续日志输出(
this.parseState.push(new BeanEntry(beanName));
String className = null;
if (ele.hasAttribute(CLASS_ATTRIBUTE)) {
className = ele.getAttribute(CLASS_ATTRIBUTE).trim();
}
String parent = null;
if (ele.hasAttribute(PARENT_ATTRIBUTE)) {
parent = ele.getAttribute(PARENT_ATTRIBUTE);
}
try {
//调用工具类创建GenericBeanDefinition实体,并根据参数初始化
AbstractBeanDefinition bd = createBeanDefinition(className, parent);
//解析bean属性 封装到bd中,这个方法就是对bean标签中的各个属性,比如lazy_init,scope,singleton等进行解析并封装,逻辑很简单,有兴趣的可以自行阅读源码,这里不再做详述
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));
//解析meta标签
parseMetaElements(ele, bd);
//解析 lookup标签
parseLookupOverrideSubElements(ele, bd.getMethodOverrides());
// 解析replace标签
parseReplacedMethodSubElements(ele, bd.getMethodOverrides());
//解析constructor标签
parseConstructorArgElements(ele, bd);
//解析property标签
parsePropertyElements(ele, bd);
parseQualifierElements(ele, bd);
//设置资源(从context中获取当前资源)
bd.setResource(this.readerContext.getResource());
bd.setSource(extractSource(ele));
return bd;
}
catch (ClassNotFoundException ex) {
//输出parseState中当前bean信息
error("Bean class [" + className + "] not found", ele, ex);
}
catch (NoClassDefFoundError err) {
error("Class that bean class [" + className + "] depends on not found", ele, err);
}
catch (Throwable ex) {
error("Unexpected failure during bean definition parsing", ele, ex);
}
finally {
//出栈,释放资源
this.parseState.pop();
}这里重点分析一下对property属性的分析,因为平时用的最多的就是这个子元素标签
进入parsePropertyElement这个方法
//解析property标签
public void parsePropertyElement(Element ele, BeanDefinition bd) {
//提取property中的唯一性标识name属性(跟bean标签流程类似)
String propertyName = ele.getAttribute(NAME_ATTRIBUTE);
if (!StringUtils.hasLength(propertyName)) {
error("Tag 'property' must have a 'name' attribute", ele);
return;
}
this.parseState.push(new PropertyEntry(propertyName));
try {
if (bd.getPropertyValues().contains(propertyName)) {
error("Multiple 'property' definitions for property '" + propertyName + "'", ele);
return;
}
//解析property中 value属性和ref属性
Object val = parsePropertyValue(ele, bd, propertyName);
PropertyValue pv = new PropertyValue(propertyName, val);
parseMetaElements(ele, pv);
pv.setSource(extractSource(ele));
bd.getPropertyValues().addPropertyValue(pv);
}
finally {
this.parseState.pop();
}
}进入parsePropertyValue ,注意思路跟上,不要断,这是最后一步分析,也是相对比较复杂的逻辑
public Object parsePropertyValue(Element ele, BeanDefinition bd, @Nullable String propertyName) {
String elementName = (propertyName != null) ?
" element for property '" + propertyName + "'" :
" element" ;
// Should only have one child element: ref, value, list, etc.
//提起property属性的子元素比如 list ref等
NodeList nl = ele.getChildNodes();
Element subElement = null;
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element && !nodeNameEquals(node, DESCRIPTION_ELEMENT) &&
!nodeNameEquals(node, META_ELEMENT)) {
// Child element is what we're looking for.
if (subElement != null) {
error(elementName + " must not contain more than one sub-element", ele);
}
else {
subElement = (Element) node;
}
}
}
//解析ref属性
boolean hasRefAttribute = ele.hasAttribute(REF_ATTRIBUTE);
//解析value属性
boolean hasValueAttribute = ele.hasAttribute(VALUE_ATTRIBUTE);
if ((hasRefAttribute && hasValueAttribute) ||
((hasRefAttribute || hasValueAttribute) && subElement != null)) {
error(elementName +
" is only allowed to contain either 'ref' attribute OR 'value' attribute OR sub-element", ele);
}
//解析ref属性
if (hasRefAttribute) {
String refName = ele.getAttribute(REF_ATTRIBUTE);
if (!StringUtils.hasText(refName)) {
error(elementName + " contains empty 'ref' attribute", ele);
}
RuntimeBeanReference ref = new RuntimeBeanReference(refName);
ref.setSource(extractSource(ele));
return ref;
}
//解析value属性
else if (hasValueAttribute) {
TypedStringValue valueHolder = new TypedStringValue(ele.getAttribute(VALUE_ATTRIBUTE));
valueHolder.setSource(extractSource(ele));
return valueHolder;
}
//解析子元素
else if (subElement != null) {
return parsePropertySubElement(subElement, bd);
}
else {
// Neither child element nor "ref" or "value" attribute found.
error(elementName + " must specify a ref or value", ele);
return null;
}
}这里主要流程分为五部分
- 列表内容 解析出子元素 ref,value,bean,list map等

- 判断是否同时拥有ref属性和value属性 或存在ref属性或者value属性,但是又子元素,用这样的规则来检验正确性,其实就是关于xml schema中的设置进行检验
- 解析ref属性 ,用RuntimeBeanReference封装
- 解析value属性,用TypedStringValue封装
- 子元素处理 ,比如进入子元素处理逻辑 parsePropertySubElement

if (!isDefaultNamespace(ele)) {
return parseNestedCustomElement(ele, bd);
}
else if (nodeNameEquals(ele, BEAN_ELEMENT)) {
BeanDefinitionHolder nestedBd = parseBeanDefinitionElement(ele, bd);
if (nestedBd != null) {
nestedBd = decorateBeanDefinitionIfRequired(ele, nestedBd, bd);
}
return nestedBd;
}
else if (nodeNameEquals(ele, REF_ELEMENT)) {
// A generic reference to any name of any bean.
String refName = ele.getAttribute(BEAN_REF_ATTRIBUTE);
boolean toParent = false;
if (!StringUtils.hasLength(refName)) {
// A reference to the id of another bean in a parent context.
refName = ele.getAttribute(PARENT_REF_ATTRIBUTE);
toParent = true;
if (!StringUtils.hasLength(refName)) {
error("'bean' or 'parent' is required for element", ele);
return null;
}
}
if (!StringUtils.hasText(refName)) {
error(" element contains empty target attribute", ele);
return null;
}
RuntimeBeanReference ref = new RuntimeBeanReference(refName, toParent);
ref.setSource(extractSource(ele));
return ref;
}
else if (nodeNameEquals(ele, IDREF_ELEMENT)) {
return parseIdRefElement(ele);
}
else if (nodeNameEquals(ele, VALUE_ELEMENT)) {
return parseValueElement(ele, defaultValueType);
}
else if (nodeNameEquals(ele, NULL_ELEMENT)) {
// It's a distinguished null value. Let's wrap it in a TypedStringValue
// object in order to preserve the source location.
TypedStringValue nullHolder = new TypedStringValue(null);
nullHolder.setSource(extractSource(ele));
return nullHolder;
}
else if (nodeNameEquals(ele, ARRAY_ELEMENT)) {
return parseArrayElement(ele, bd);
}
else if (nodeNameEquals(ele, LIST_ELEMENT)) {
return parseListElement(ele, bd);
}
else if (nodeNameEquals(ele, SET_ELEMENT)) {
return parseSetElement(ele, bd);
}
else if (nodeNameEquals(ele, MAP_ELEMENT)) {
return parseMapElement(ele, bd);
}
else if (nodeNameEquals(ele, PROPS_ELEMENT)) {
return parsePropsElement(ele);
}
else {
error("Unknown property sub-element: [" + ele.getNodeName() + "]", ele);
return null;
}这里就是对property各种子元素进行处理的逻辑,请自行分析,不再详述
以上就是对bean标签解析的全过程,不知道有没有蒙圈,下边通过一张活动图来梳理一下主要的解析步骤
解析活动图
