hadoop实现wordcount的三种方法
很多小伙伴在搭建完hadoop集群后,还不太会在上面跑测试程序,作为大数据入门学习的Hello world程序,我总结了三种方法。
第一种:用hadoop上自带的jar包(hadoop-mapreduce-examples-2.7.0.jar)实现
1、如何找到hadoop自带的jar包呢?
路径:/usr/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar(我的hadoop是安装在linux的usr目录下的)

2、如何运行,在linux上运行格式是怎样的?
四步:
(1)首先自己在linux本地新建一个txt文件 (vi /tmp/wordcount.txt)
(2)在分布式文件系统上新建一个存放wordcount.txt的文件夹(hdfs dfs -mkdir hdfs://hadoop-senior:9000/tmp/wordcount_input)
(3)将linux本地wordcount.txt文件上传到分布式文件系统wordcount_input中
(4)用上面我们找到的自带jar包运行wordcount程序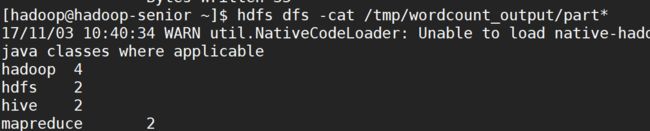

hadoop jar /usr/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar wordcount hdfs://hadoop-senior:9000/tmp/wordcount_input/
hdfs://hadoop-senior:9000/tmp/wordcount2_output/ 注意:wordcount_input是我们在dfs上自己建立的用于输入文件夹,而wordcount_out是系统生成的用于输出的文件夹(提前新建会报错)

此时会在wordcount_output中生成两个文件,
查看最终结果:hdfs dfs -cat /tmp/wordcount_output/part*
第二种:不用自带的包,我们自己导出JAR包,在集群中运行(3个java源程序,我这里就不提供了)
(1)在eclipse的项目管理器列表中右击WordMain.java,选择export,选择导出为“JAR file”格式
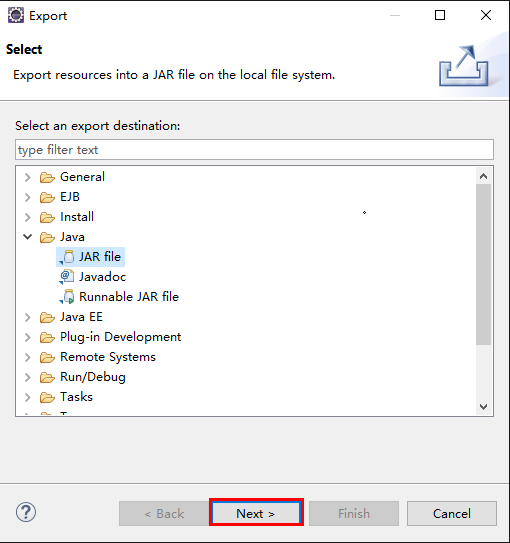
(2)单击“Next>”按钮,输入JAR包名称,导出jar包后,自己通过WinScp放到linux的一个目录下(我这里是放在staging下)
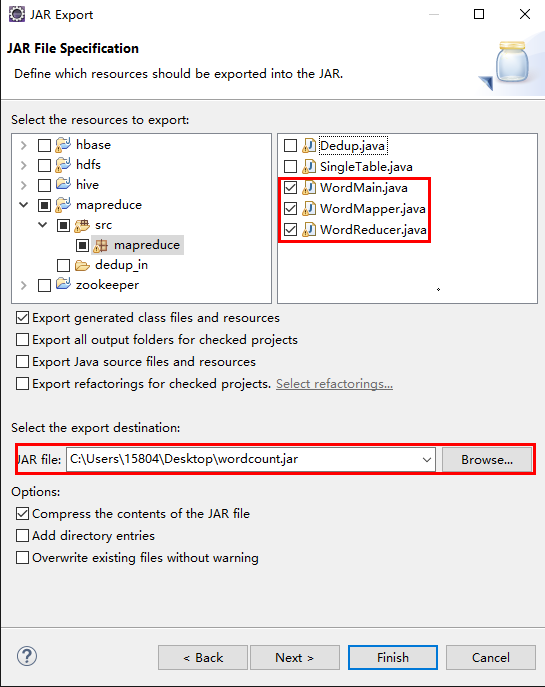
(3)新建输入目录
[hadoop@master~]$ hdfs dfs -mkdir -p /tmp/wordcount_in
(4)上传文件
[hadoop@master~]$ hdfs dfs -put /tmp/WordCount.txt wordcount_in/
(5)运行WordCount,其中的“wordcount_in/”是输入目录,“wordcount_out/”是输出目录(注意在程序运行之前wordcount_out文件夹是不存在)。
格式:hadoop jar [jar文件位置] [jar主类] [HDFS输入位置] [HDFS输出位置]
[hadoop@master ~]$hadoop jar /staging/wordcount.jar mapreduce.WordMain /tmp/wordcount_in /tmp /wordcount_out/
结果上面一样的,这里就不截图了。
第三种:在IDE中运行,eclipse怎么连接集群请参考这篇博文:http://blog.csdn.net/dopamy_busymonkey/article/details/50672564
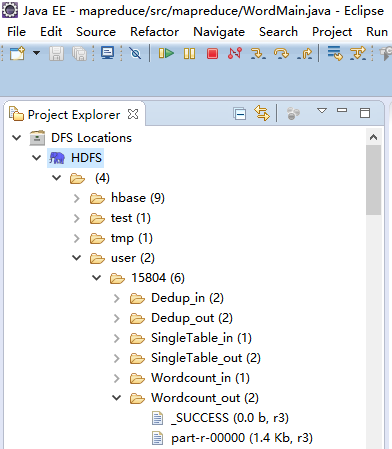
(1)Eclipse HDFS文件系统中,在/user/目录下新建一个文件夹(文件夹命名为Window Eclipes连接Hadoop集群的用户名)
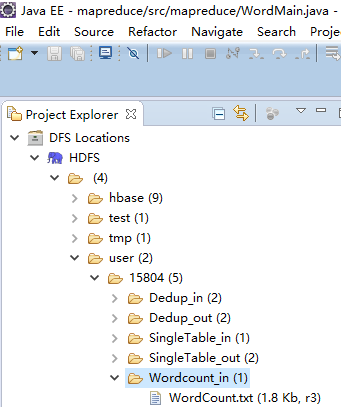
(2)在用户名文件夹下,新建Wordcount_in文件夹,上传WordCount.txt文件
(3)右键->Run As->RunConfigurations->Arguments(在左边的导航列表点击Java Application选择WordMain Java程序)。
输入目录:hdfs://192.168.85.81:9000/user/15804/Wordcount_in
输出目录:hdfs://192.168.85.81:9000/user/15804/Wordcount_out

(4)点击运行在输出目录会生成两个文件,part-r-00000文件保存的是运行结果