基于BoF算法的图像分类
基于BoF算法的图像分类
图像分类一直是计算机视觉中的一个重要问题,BoF(Bag of features)算法在图像分类中具有着重要的作用。本文旨在介绍BoF算法的基本原理和过程并且给出Python代码的实现:用于解决在Caltech 101数据库上的多分类问题。
算法起源
起源1:纹理识别
纹理(texture)是由一些重复的纹理单元(texton)组成的,如图1所示。

我们想要进行纹理的识别,应该关注组成这些纹理的纹理单元的类型,而不是空间的分布。一副纹理图像包含很多种的纹理单元,我们可以将所有可能出现的纹理单元组成一个集合或者说叫做纹理单元字典(texton dictionary),然后统计对于某图像中某纹理单元出现的个数,就可以得到该图像对应的直方图,如图2所示。
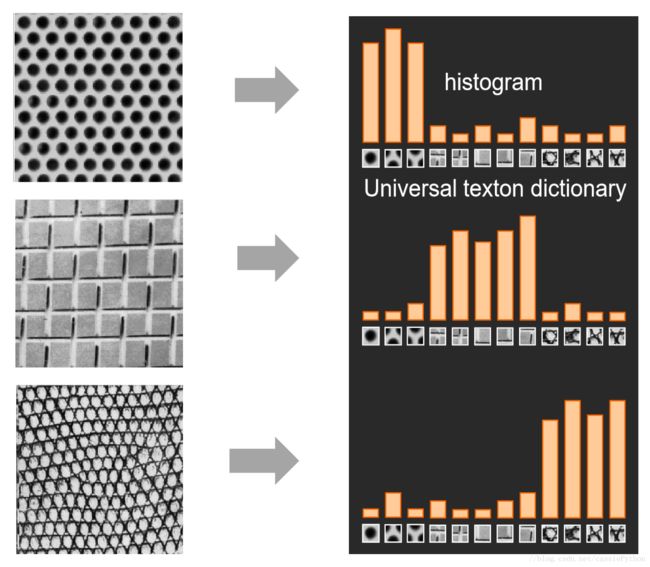
显然,这些直方图可以很好地表示原始的纹理图像。假如我们有一堆纹理图像,可以得到一堆这样的直方图,送入某种分类器中进行训练,然后就可以进行纹理的分类了。
起源2:Bag-of-Words模型
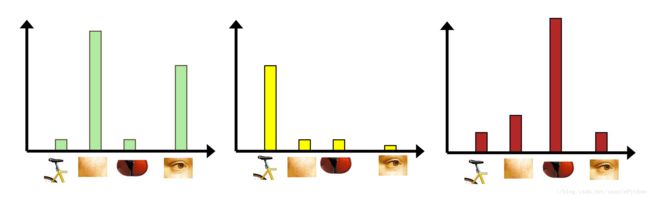
Bag-of-Words模型的思想很简单:我们想要了解一段本文的核心内容,最简单直接的方式是找出其中的关键词,然后根据关键词出现的频率来确定该段文本要想表述的意思。

从上图中,我们知道关键词是iraq和terrorists,由此可以推荐该文本的主题与伊拉克的恐怖主义有关。这里所说的关键词,就是Bag-of-Words中的words,它们是区分度较高的单词。根据这些 words,
我们可以很快地识别出文章的内容,并快速地对文章进行分类。
Bags of Features算法
Bag of features算法分为四步:
- 提取图像特征;
- 对特征进行聚类,得到可视化字典(visual vocabulary);
- 根据字典将图片表示成向量,即直方图;
使用得到的直方图表示的特征进行分类器的训练。
特征提取
首先我们从原始图像中提取特征,如图4所示。常用的特征提取方法有SIFT,SURF。SIFT得到的特征描述是128维度的向量,相比SISF,SURF计算量更小些,得到的特征是64维的向量。也有使用HoG和LBP来进行特征提取的。注意特征提取的方法要满足旋转不变性以及尺寸不变性。

字典生成
对所有的图片提取完特征后,将所有的特征进行聚类,比如使用K-Means聚类,得到K类,每个类别看作一个word,这样我们就得到了字典,如下图所示。

直方图表示
上一步训练得到的字典,是为了这一步对图像特征进行量化。对于一幅图像而言,我们可以提取出大量的特征,但这些特征(如SIFT提取的特征)仍然属于一种浅层的表示,缺乏代表性。因此,这一步的目标,是根据字典重新提取图像的高层特征。具体做法是,对于每一张图片得到的每一个特征(如SIFT提取的特征),都可以在字典中找到一个最相似的word(实际上就是将特征输入到得到的聚类模型,得到类别),统计相似的每种word的数量,于是就得到一个K维的直方图。如下图所示。
训练分类器
对于每张图片,我们得到了其对应的直方图向量,当然也知道其对应的属于哪种物品的标记。这样我们就可以构造训练集来训练某种分类器。当需要进行预测时,我们先测试集的图片中提取特征,然后利用字典量化得到直方图,输入训练好的分类器,得到预测的类别。
代码实现
下面让我们一起使用Python来实现基于基于BoF算法的图像分类。首先需要下载数据集Caltech-101。解压后进入caltech101(点击进行下载),再进入其子目录,可以看到有102个文件夹,其中每个文件夹对应一种物品。简单起见,我们使用三种物品:bonsai,ferry和laptop。
数据预处理
在进行Bag-of-Features算法的实现之前,首先我们来读取所需要的图片。
import os
"""
功能:读取文件夹中的图片
输入:
data_dir:某种物品图片所在的文件夹
输出:
imgs:某种物品所有的图片路径
"""
def read_imgs(data_dir):
imgs = os.listdir(data_dir)
imgs = [data_dir + "/" + img for img in imgs]
return imgs
data_dir = 'caltech101/101_ObjectCategories/'
catalog = ['bonsai', 'ferry', 'laptop']
imgSet = [
read_imgs(data_dir + catalog[0]),
read_imgs(data_dir + catalog[1]),
read_imgs(data_dir + catalog[2]),
]实现输出代码,输出一下每种物品的数量信息。
print ("Label\t\tcount")
print ("---------------------")
for i, item in enumerate(catalog):
print ("%s\t\t%s" %(item, len(imgSet[i])))输出结果如下。

其中第一列表示物体的种类,第二列表示对应的图片的数量。
在上面的代码基础上,我们进行训练集和测试集数据的划分和生成。
import random
"""
功能:产生训练集和测试集
输入:
imgSet:包含所有物品种类的图片路径
split:根据split进行划分训练集和测试集,
表示训练集的比例
输出:
train_datas:训练集数据,列表类型
test_datas:测试集数据,列表类型
train_labels:训练集标签,列表类型
test_labels:测试集标签,列表类型
"""
def make_dataset(imgSet, split):
train_datas=[]
test_datas = []
train_labels = []
test_labels = []
#用index来表示label,即三种类型物体标签如下:
# bonsai --- 0
# ferry ---- 1
# laptop --- 2
for index, item in enumerate(imgSet):
random.shuffle(item) #将某种物品数据打乱
interval = int(len(item) * split)
train_item = item[:interval]
test_item = item[interval:]
train_datas += train_item
test_datas += test_item
train_labels += [index for _ in range(len(train_item))]
test_labels += [index for _ in range(len(test_item))]
return train_datas, test_datas, train_labels, test_labels
train_datas, test_datas ,train_labels, test_labels = make_dataset(imgSet, 0.7)
特征提取
首先我们用一个函数将原始的RGB图转换为灰度图,然后使用OpenCV的SURF算法来进行特征的提取,最后使用几行代码来测试下效果。
import cv2
"""
功能:将一张RGB图转换为灰度图
输入:
color_img:RGB图
输出:
gray:灰度图
"""
def to_gray(color_img):
gray = cv2.cvtColor(color_img, cv2.COLOR_RGB2GRAY)
return gray
"""
功能:提取一张灰度图的SURF特征
输入:
gray_img:要提取特征的灰度图
输出:
key_query:兴趣点
desc_query:描述符,即我们最终需要的特征
"""
def gen_surf_features(gray_img):
#400表示hessian阈值,一般使用300-500,表征了提取的特征的数量,
#值越大得到的特征数量越少,但也越突出。
surf = cv2.xfeatures2d.SURF_create(400)
key_query, desc_query = surf.detectAndCompute(gray_img, None)
return key_query, desc_query
#测试gen_surf_features的结果
import matplotlib.pyplot as plt
img = cv2.imread(train_datas[0])
img = to_gray(img)
key_query, desc_query = gen_surf_features(img)
imgOut = cv2.drawKeypoints(img, key_query, None, (255, 0, 0), 4)
plt.imshow(imgOut)
plt.show()
为了展示该阈值的影响,这里我们使用两种不同的Hessian阈值(400和3000)得到两张结果的图示。因为代码中在划分训练集和测试集时进行过随机处理,所以这两张图并不一定是同一物体。
接下来我们来实现一个函数,它可以利用上面已经实验的函数来提取所有的特征。
"""
功能:提取所有图像的SURF特征
输入:
imgs:要提取特征的所有图像
输出:
img_descs:提取的SURF特征
"""
def gen_all_surf_features(imgs):
img_descs = []
for item in imgs:
img = cv2.imread(item)
img = to_gray(img)
key_query, desc_query = gen_surf_features(img)
img_descs.append(desc_query)
return img_descs
img_descs = gen_all_surf_features(train_datas)至此我们已经完成了特征提取的部分,得到了提取到的SURF特征。接下来进行字典的生成。
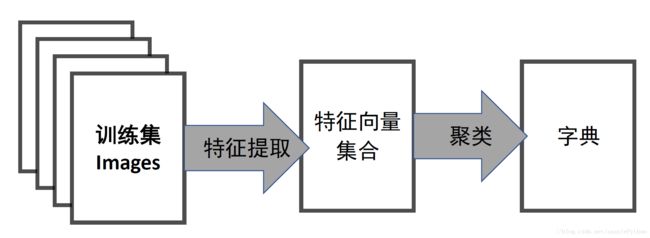
字典生成
我们先再来回顾下生成字典的流程,对训练集的所有图片进行特征提取,将提取的所有的特征向量进行聚类,从而得到字典。如下图所示。
import numpy as np
from sklearn.cluster import MiniBatchKMeans
"""
功能:提取所有图像的SURF特征
输入:
img_descs:提取的SURF特征
输出:
img_bow_hist:条形图,即最终的特征
cluster_model:训练好的聚类模型
"""
def cluster_features(img_descs, cluster_model):
n_clusters = cluster_model.n_clusters #要聚类的种类数
#将所有的特征排列成N*D的形式,其中N表示特征数,
#D表示特征维度,这里特征维度D=64
train_descs = [desc for desc_list in img_descs
for desc in desc_list]
train_descs = np.array(train_descs)#转换为numpy的格式
#判断D是否为64
if train_descs.shape[1] != 64:
raise ValueError('期望的SURF特征维度应为64, 实际为'
, train_descs.shape[1])
#训练聚类模型,得到n_clusters个word的字典
cluster_model.fit(train_descs)
#raw_words是每张图片的SURF特征向量集合,
#对每个特征向量得到字典距离最近的word
img_clustered_words = [cluster_model.predict(raw_words)
for raw_words in img_descs]
#对每张图得到word数目条形图(即字典中每个word的数量)
#即得到我们最终需要的特征
img_bow_hist = np.array(
[np.bincount(clustered_words, minlength=n_clusters)
for clustered_words in img_clustered_words])
return img_bow_hist, cluster_model
K = 500 #要聚类的数量,即字典的大小(包含的单词数)
cluster_model=MiniBatchKMeans(n_clusters=K, init_size=3*K)
train_datas, cluster_model = cluster_features(img_descs,
cluster_model)经过上述代码(主要是进行聚类分析),对于每张原始图片,我们得到了其对应的最终的特征(直方图)。接下来我们来学习如何进行分类器的训练以及进行结果的预测,得到最终的Accuracy值。
from sklearn.multiclass import OneVsRestClassifier
from sklearn.svm import LinearSVC
"""
功能:分类
输入:
train_datas:训练集,即最终的特征(所有图像的直方图集合),
要求是numpy.array类型
train_labels:训练集的label,要求是numpy.array类型
输出:
classifier:训练好的分类器
"""
def run_svm(train_datas, train_labels):
classifier = OneVsRestClassifier(
LinearSVC(random_state=0)).fit(train_datas, train_labels)
return classifier
#将训练集label转化为numpy.array类型
train_labels = np.array(train_labels)
classifier = run_svm(train_datas, train_labels)对于分类器的选择我们也可以使用多层感知机或其他的神经网络:
from sklearn.multiclass import OneVsRestClassifier
from sklearn.svm import LinearSVC
from sklearn.neural_network import MLPClassifier
"""
功能:分类
输入:
train_datas:训练集,即最终的特征(所有图像的直方图集合),
要求是numpy.array类型
train_labels:训练集的label,要求是numpy.array类型
输出:
classifier:训练好的分类器
"""
def run_svm(train_datas, train_labels):
#注释内容:SVM分类器
#classifier = OneVsRestClassifier(
# LinearSVC(random_state=0)).fit(
# train_datas, train_labels)
classifier = MLPClassifier(
solver='lbfgs', alpha=1e-10,
hidden_layer_sizes=(100,),
random_state=1).fit(train_datas, train_labels)
return classifier接下来我们来进行预测并得到最终的Accuracy结果。进行预测的过程如下:
- 提取每张测试集图像的SURF特征;
- 利用训练好的字典得到每张图片的直方图;
- 对每张图片的直方输入分类器得到结果;
计算Accuracy值。
首先我们来实现一个函数,用来从一张图片得到对应的直方图向量。
"""
功能:将一张图片转化为直方图的形式
输入:
img_path:一张图片
cluster_model:已经训练好的聚类模型
输出:
img_bow_hist:直方图向量
"""
def img_to_vect(img_path, cluster_model):
"""
Given an image path and a trained clustering model (eg KMeans),
generates a feature vector representing that image.
Useful for processing new images for a classifier prediction.
"""
img = cv2.imread(img_path)
gray = to_gray(img)
kp, desc = gen_surf_features(gray)
clustered_desc = cluster_model.predict(desc)
img_bow_hist = np.bincount(clustered_desc,
minlength=cluster_model.n_clusters)
#转化为1*K的形式,K为字典的大小,即聚类的类别数
return img_bow_hist.reshape(1,-1)接下来我们来实现最终的测试函数。
"""
功能:对测试集数据进行预测,得到Accuracy
输入:
test_datas:测试集数据,要求是numpy.array类型
test_labels:测试集label,要求是numpy.array类型
输出:
无返回值,输出Accuracy
"""
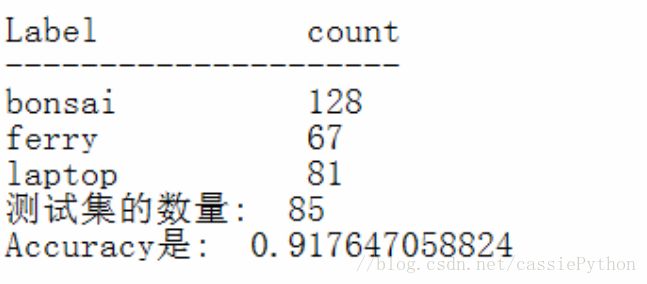
def test(test_datas, test_labels, cluster_model, classifier):
print ("测试集的数量: ", len(test_datas))
preds = []
for item in test_datas:
vect = img_to_vect(item, cluster_model)
pred = classifier.predict(vect)
preds.append(pred[0])
preds = np.array(preds)
idx = preds == test_labels
accuracy = sum(idx)/len(idx)
print ("Accuracy是: ", accuracy)
test_labels = np.array(test_labels)
test(test_datas, test_labels, cluster_model, classifier)得到的结果为。
当然每次运行得到的结果会有所差异。
参考:
https://www.cnblogs.com/jermmyhsu/p/8195727.html
https://ww2.mathworks.cn/help/vision/examples/image-category-classification-using-bag-of-features.html
http://www.cs.unc.edu/~lazebnik/spring09/lec18_bag_of_features.pdf