xmpp即时通信开发---1、tigase源代码的编译---idea+postgresql+gradle
前言
xmpp协议是即时通信的其中一个基础协议,而java上面有spark以及服务端的实现—tigase。
本篇文章将直接获取源代码,导入到idea中变为可编译以及执行的项目。
而文章后面将给出最后的源代码以及将数据库备份打包一份出来方便大家导入。
声明
本文编译时候,tigase server的版本是7.1.4
参考资料:
搭建Tigase进行二次开发
idea搭建tigase源码环境
tigase服务端二次开发官方文档
tigase相关参考资料–linux+tigase+postgresql 二次开发环境搭建【草稿】
获取必要源代码
tigase的服务端包括三个项目,tigase-server,tigase-utils,tigase-xmltools,针对当前版本,7.1.4 而言,先用git克隆到本地:
git clone https://git.tigase.tech/tigase-server.git ~/git-projects/tigase-server-beta

导入 tigase-utils

git clone https://git.tigase.tech/tigase-utils.git ~/git-projects/tigase-utils

导入tigase-xmltools:

然后:
git clone https://git.tigase.tech/tigase-xmltools.git ~/git-projects/tigase-xmltools

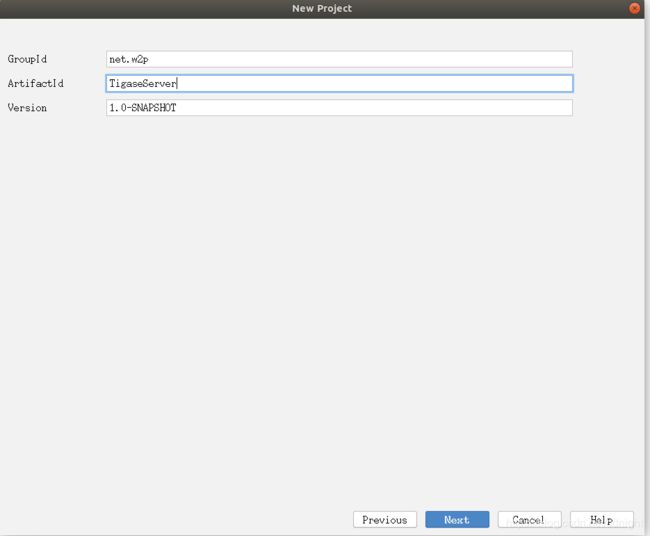
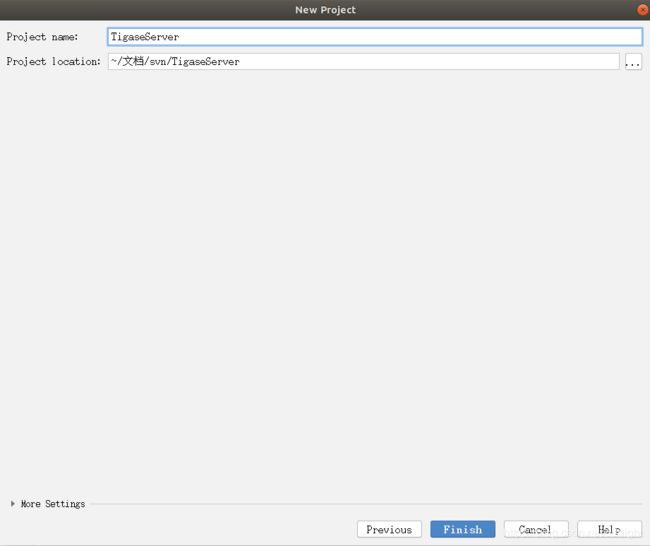
新建idea项目
新建项目的时候选gradle以及groovy,其他以后再说:

一步一步下去:

复制合并源代码
将tigase-server-beta下面的server文件夹的内容都复制到TigaseServer项目下面,
将tigase-utils的src以及tigase-xmltools下面的src都复制合并到TigaseServer下面,

正常来说,合并过程是不会有覆盖文件提示的—因为他们都是同一个项目的。。。不会文件冲突
然后重启idea:
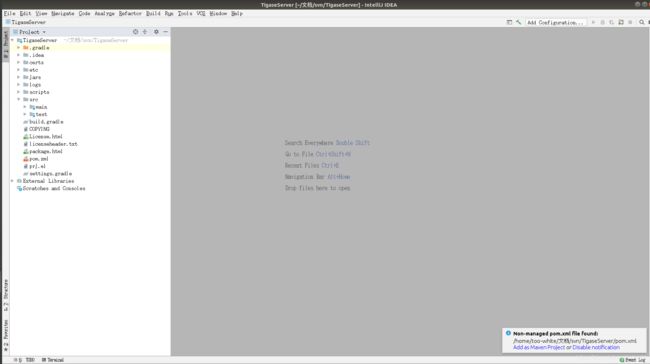
有maven项目导入的提示,别管他,我们用的是gradle。
配置依赖
tigase-server项目的pom.xml文件肯定有依赖,我们现在来解决一下,将依赖都放到build.gradle下面。
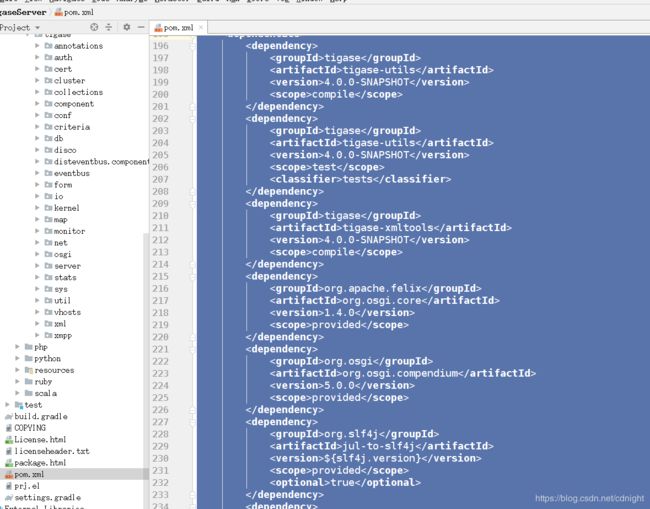
咦,pom里面都已经写明了对 tigase-utils以及tigase-xmltools的依赖。。。额,我们刚才的下载源代码合并的操作估计是多此一举。不过算了,继续:
build.gradle内容:
plugins {
id 'groovy'
id 'java'
}
group 'net.w2p'
version '1.0-SNAPSHOT'
/***所有项目共通***/
allprojects {
sourceCompatibility = 1.8
targetCompatibility = 1.8
apply plugin: 'java'
apply plugin: 'idea'
apply plugin: 'groovy'
idea {
module {
inheritOutputDirs = true
}
}
tasks.withType(JavaCompile) {
options.encoding = "UTF-8"
}
tasks.withType(GroovyCompile) {
groovyOptions.encoding = "MacRoman"
}
repositories {
maven{
//更换为阿里的仓库
url 'http://maven.aliyun.com/nexus/content/groups/public'
}
//有些jar包在中央仓库是没有的,需要手动添加上去
// flatDir { dirs 'local_jars' }
// mavenCentral()
}
}
dependencies {
compile 'org.codehaus.groovy:groovy-all:2.3.11'
testCompile group: 'junit', name: 'junit', version: '4.12'
compileOnly 'org.apache.felix:org.osgi.core:1.4.0'
compileOnly 'org.osgi:org.osgi.compendium:5.0.0'
compileOnly 'org.slf4j:jul-to-slf4j:${slf4j.version}'
compileOnly 'org.codehaus.groovy:groovy:2.5.2'
compileOnly 'org.codehaus.groovy:groovy-json:2.5.2'
compileOnly 'org.codehaus.groovy:groovy-jsr223:2.5.2'
compileOnly 'org.codehaus.groovy:groovy-templates:2.5.2'
compileOnly 'org.codehaus.groovy:groovy-xml:2.5.2'
testCompile 'mysql:mysql-connector-java:5.1.40'
testCompile 'net.sourceforge.jtds:jtds:1.2.8'
testCompile 'org.postgresql:postgresql:9.4.1207'
testCompile 'org.apache.derby:derby:10.12.1.1'
}
注意,修改build.gradle文件以后请重新加载依赖库。
然后找到:
DBSchemaLoader
以这个类为demo,进行编译。
编译执行结果:
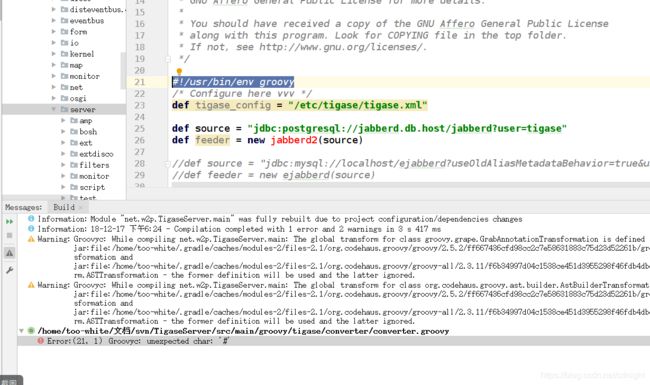
#!/usr/bin/env groovy
嗯,这个是用来在linux下面直接作为shell运行的,idea,jvm不认可。。。
改了,然后:
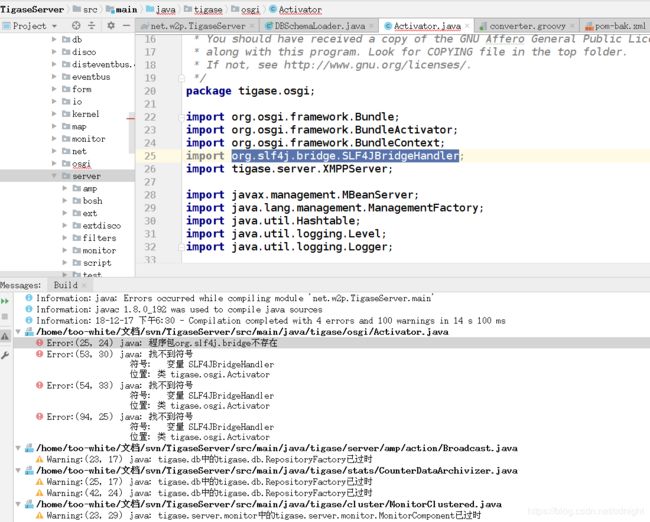
我们看看slf4j的jar包:
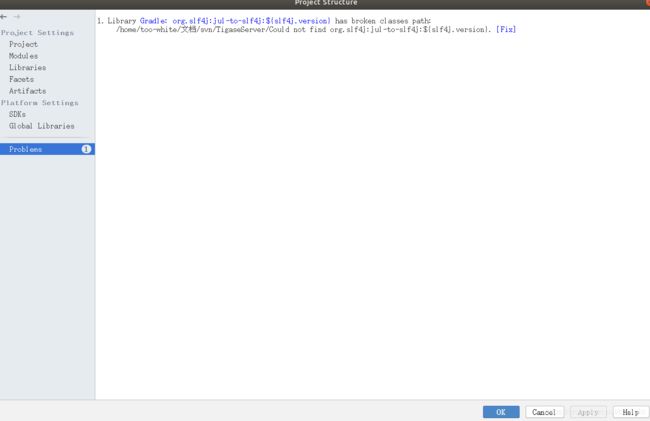
这个导入不成功。。。嗯,
好了,改为:
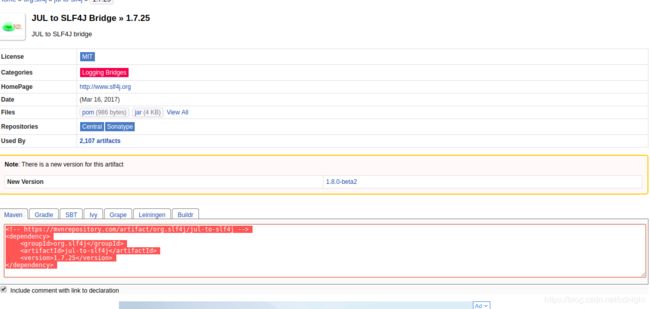
org.slf4j
jul-to-slf4j
1.7.25
继续编译:
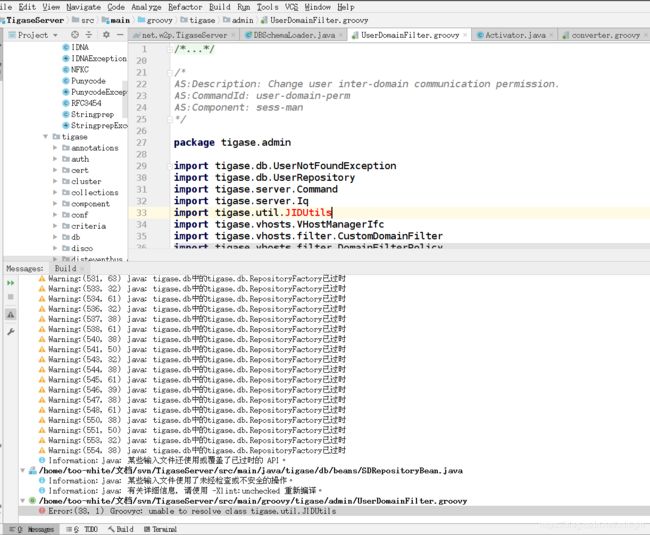
额。。完全找不到jidutils。。。实在没办法,注释掉再说:
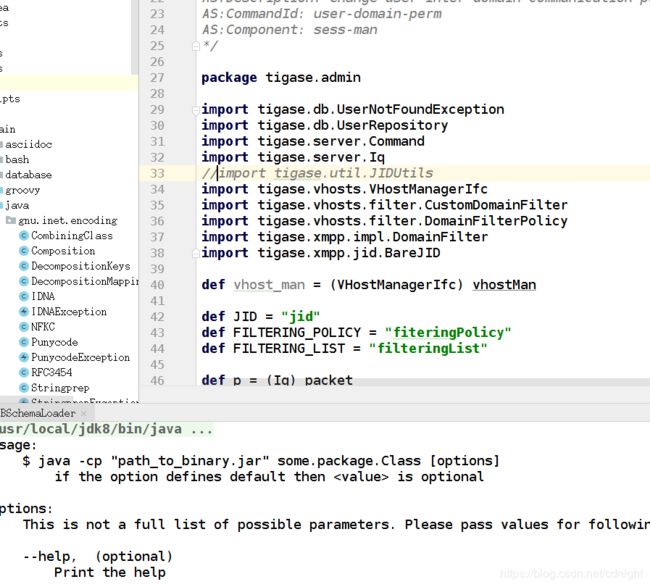
然后就执行成功了,不过有提示,没按规则运行:

基本正常运行
数据库初始化
可以参考下以下兄弟的做法:
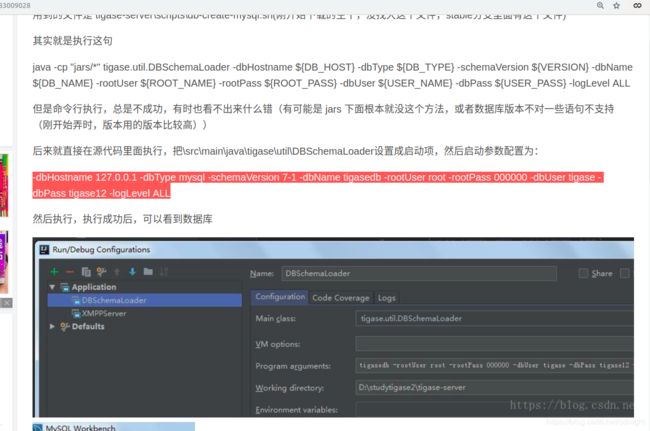
所以我们这样做:

然后添加参数:
-dbHostname 127.0.0.1 -dbType postgresql -schemaVersion 7-1 -dbName tigasedb -rootUser postgres -rootPass 123456 -dbUser tigase -dbPass tigase1234 -logLevel ALL
---------------------
作者:敢吹-敢喷-敢随-敢送
来源:CSDN
原文:https://blog.csdn.net/bornonew/article/details/83009028
版权声明:本文为博主原创文章,转载请附上博文链接!
请针对你自己的数据进行设置

然后执行。
有问题:

dbType不见了。。。
查找资料可知,换个方向:
Tigase手动安装过程
封宇兄弟做过这个了,

直接执行sql文件—我也觉得这样虽然底层不过出错率低,
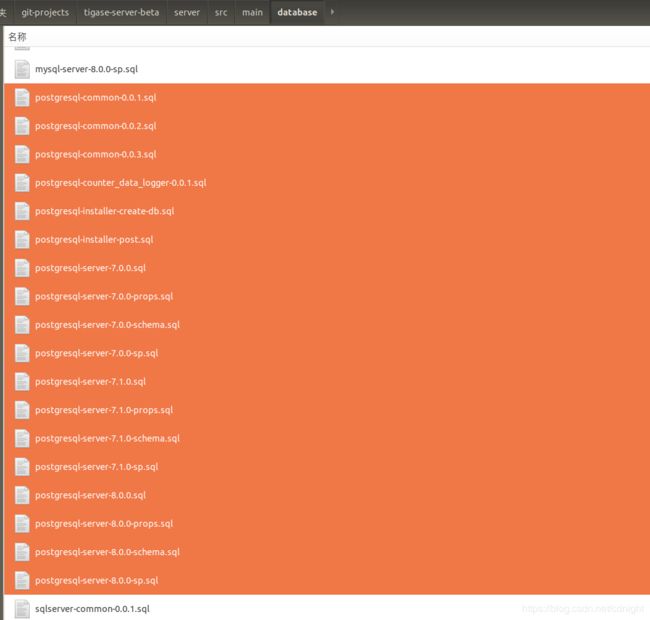
可以看到pg数据库的脚本不到20个,可以试一试。
创建数据库,链接数据库—ubuntu上面我用的是datagrip来链接数据库。


将所有pg脚本打开,然后查看各个sql内容,进行sql文件的执行排序。
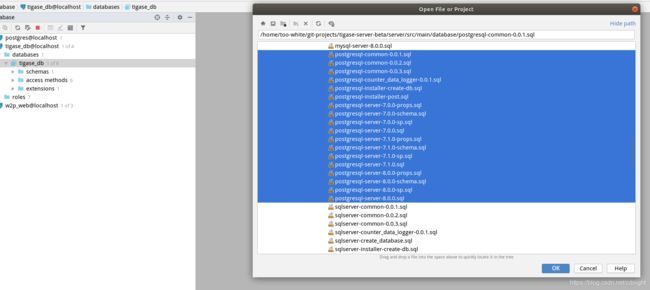
最后肉眼排序可以得到执行顺序为:
额。。人家名字都帮忙排好序了,直接按照名字执行:
遇到的错误杂锦:
1、
postgresql-counter_data_logger-0.0.1.sql 中有错
源文件内容:
-- QUERY START:
create table tig_stats_log (
lid serial,
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
hostname varchar(2049) NOT NULL,
cpu_usage double precision not null default 0,
mem_usage double precision not null default 0,
uptime bigint not null default 0,
vhosts int not null default 0,
sm_packets bigint not null default 0,
muc_packets bigint not null default 0,
pubsub_packets bigint not null default 0,
c2s_packets bigint not null default 0,
s2s_packets bigint not null default 0,
ext_packets bigint not null default 0,
presences bigint not null default 0,
messages bigint not null default 0,
iqs bigint not null default 0,
registered bigint not null default 0,
c2s_conns int not null default 0,
s2s_conns int not null default 0,
bosh_conns int not null default 0,
primary key (ts, hostname(255))
);
-- QUERY END:
-- QUERY START:
do $$
begin
if not exists (select 1 from information_schema.columns where table_catalog = current_database() and table_schema = 'public' and table_name = 'tig_stats_log' and column_name = 'ws2s_conns') then
ALTER TABLE tig_stats_log ADD `ws2s_conns` INT not null default 0;
end if;
end$$;
-- QUERY END:
-- QUERY START:
do $$
begin
if not exists (select 1 from information_schema.columns where table_catalog = current_database() and table_schema = 'public' and table_name = 'tig_stats_log' and column_name = 'ws2s_packets') then
ALTER TABLE tig_stats_log ADD `ws2s_packets` INT not null default 0;
end if;
end$$;
-- QUERY END:
-- QUERY START:
do $$
begin
if not exists (select 1 from information_schema.columns where table_catalog = current_database() and table_schema = 'public' and table_name = 'tig_stats_log' and column_name = 'sm_sessions') then
ALTER TABLE tig_stats_log ADD `sm_sessions` INT not null default 0;
end if;
end$$;
-- QUERY END:
-- QUERY START:
do $$
begin
if not exists (select 1 from information_schema.columns where table_catalog = current_database() and table_schema = 'public' and table_name = 'tig_stats_log' and column_name = 'sm_connections') then
ALTER TABLE tig_stats_log ADD `sm_connections` INT not null default 0;
end if;
end$$;
-- QUERY END:
其中,primary key限制
primary key (ts, hostname(255)) 语法错误
而 判断有没有column没有就添加column的所有句子也错了,修正为:
-- QUERY START:
create table tig_stats_log (
lid serial,
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
hostname varchar(2049) NOT NULL,
cpu_usage double precision not null default 0,
mem_usage double precision not null default 0,
uptime bigint not null default 0,
vhosts int not null default 0,
sm_packets bigint not null default 0,
muc_packets bigint not null default 0,
pubsub_packets bigint not null default 0,
c2s_packets bigint not null default 0,
s2s_packets bigint not null default 0,
ext_packets bigint not null default 0,
presences bigint not null default 0,
messages bigint not null default 0,
iqs bigint not null default 0,
registered bigint not null default 0,
c2s_conns int not null default 0,
s2s_conns int not null default 0,
bosh_conns int not null default 0,
primary key (ts, hostname)
);
-- QUERY END:
-- QUERY START:
do $$
begin
if not exists (select 1 from information_schema.columns where table_catalog = current_database() and table_schema = 'public' and table_name = 'tig_stats_log' and column_name = 'ws2s_conns') then
ALTER TABLE tig_stats_log ADD "ws2s_conns" INT not null default 0;
end if;
end$$;
-- QUERY END:
-- QUERY START:
do $$
begin
if not exists (select 1 from information_schema.columns where table_catalog = current_database() and table_schema = 'public' and table_name = 'tig_stats_log' and column_name = 'ws2s_packets') then
ALTER TABLE tig_stats_log ADD "ws2s_packets" INT not null default 0;
end if;
end$$;
-- QUERY END:
-- QUERY START:
do $$
begin
if not exists (select 1 from information_schema.columns where table_catalog = current_database() and table_schema = 'public' and table_name = 'tig_stats_log' and column_name = 'sm_sessions') then
ALTER TABLE tig_stats_log ADD "sm_sessions" INT not null default 0;
end if;
end$$;
-- QUERY END:
-- QUERY START:
do $$
begin
if not exists (select 1 from information_schema.columns where table_catalog = current_database() and table_schema = 'public' and table_name = 'tig_stats_log' and column_name = 'sm_connections') then
ALTER TABLE tig_stats_log ADD "sm_connections" INT not null default 0;
end if;
end$$;
-- QUERY END:
2、postgresql-installer-create-db.sql 文件不用执行,该文件是创建数据库以及数据库的管理员账号,我们这边自己创建完毕了。
3、postgresql-installer-post.sql 文件不用执行。
4、
postgresql-server-7.0.0.sql
的内容是:
\i database/postgresql-server-7.0.0-schema.sql
\i database/postgresql-server-7.0.0-sp.sql
\i database/postgresql-server-7.0.0-props.sql
分别执行这三个文件。
5、7.1.0,8.0都是这样套路,分别执行schema,sp以及props三个文件。
全部执行之后:
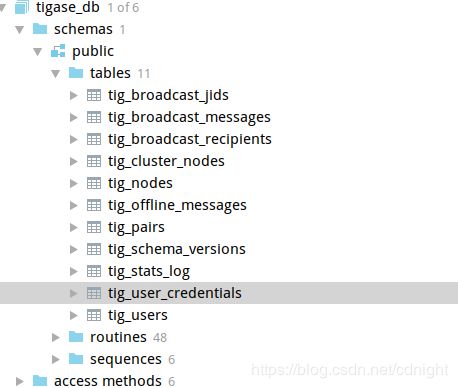
执行xmppserver
注意,主要入口是:
请先在build.gradle下面添加postgresql的依赖:
compile 'org.postgresql:postgresql:42.2.2'
然后在:
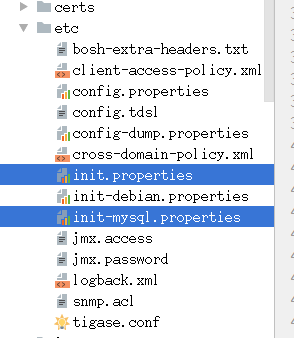
etc目录下面添加init.properties文件,内容复制init-mysql.properties即可。
例如:
# 新添加一个init properties
# Load standard set of the server components.
# Look at the http://www.tigase.org/configuration-wizards
# document for other possible values. Normally you don't
# need to change this line.
config-type=--gen-config-def
# List of administrator accounts, please replace them with
# administrator accounts in your installation
[email protected],admin@test-d
# The line says that the database used by the Tigase server is 'mysql'
# Look at the configuration wizards article for different options
# You can also put here a Java class name if you have a custom
# implementation for a database connector.
--user-db=postgresql
# The line contains the database connection string. This is database
# specific string and for each kind of database it may look differently.
# Below string is for MySQL database. Please modify it for your system.
# MySQL connector requires connection string in the following format:
# jdbc:mysql://[hostname]/[database name]?user=[user name]&password=[user password]
--user-db-uri=jdbc:postgresql://localhost:5432/tigase_db?user=dbuser&password=你的密码填写
# Virtual domains for your server installation, comma separated list of vhosts
--virt-hosts=devel.tigase.org,test-d
# Select what packages you want to have logging switched for
# The below setting is recommended for the initail setup and it is required
# when asking for help with setting the server up
--debug=server
# Activate HTTP API component for web based configuration and installation
--comp-name-1=http
--comp-class-1=tigase.http.HttpMessageReceiver
然后启动,错误:
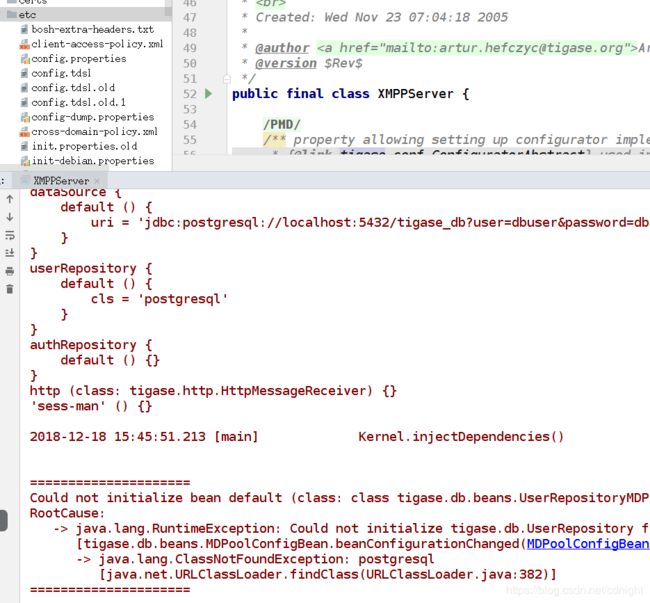
Could not initialize tigase.db.UserRepository for name 'default'
调试得到:
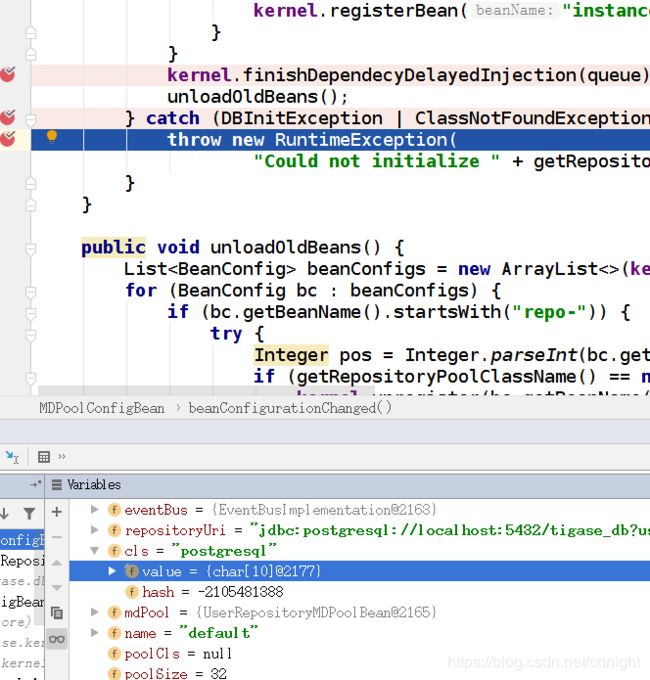
cls之中直接是postgresql 这个类。。额,应该不是吧。
后来查到文件说明:
init.properties的配置

use-db应该填的是pgsql。
然后继续运行
注意:
每次运行xmppserver,假如没有config.tds1的话,就将从init.properties上面生成config.tds1然后将init.properties改为init.properties.old,
。。。就是说,要将config.tds1这种删除然后将init.properties.old改回init.properties才能让配置生效。
运行结果:
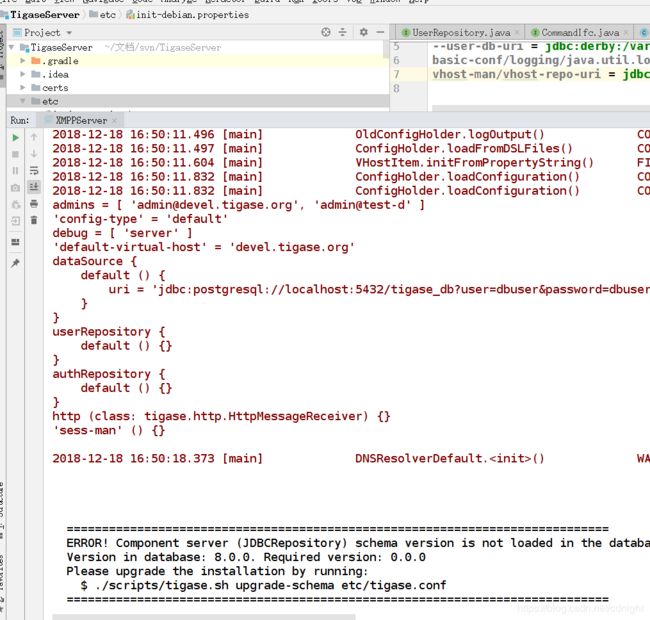
嗯,没有说postgresql找不到了。现在的问题是数据库版本的问题。。
直接找到关键字,调试一下看看:
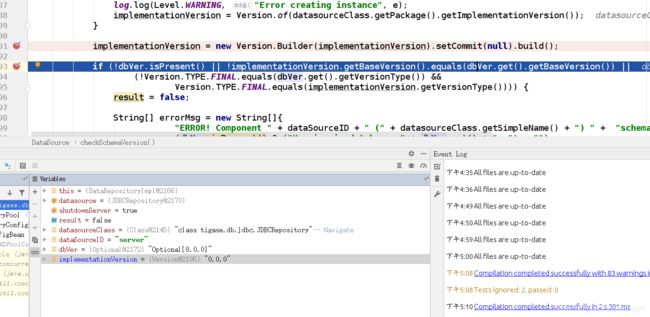
implementationVersion是0.0.0.。—这个就有点可疑了。。。
我们直接写代码检查一下:
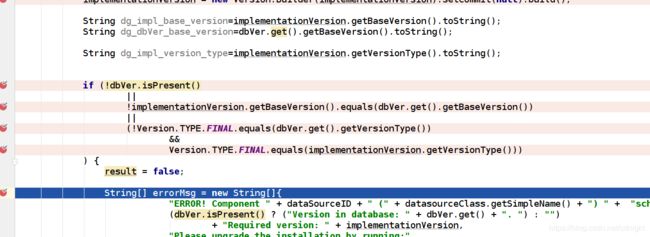
可以看到,implement version是0.0.0这是主因,检查这个数据在哪里来的:

可以追查到,获得schema version的时候已经是null,然后返回了零。
不过,package getImplemetationVersion到底是什么?
Package getImplementationVersion

哦。。。
这东西。。代码里面要获取 meta inf文件下面的版本号,如果没有版本号就报错---
现在是源代码开发,所以,版本号就免了吧?
好了,我的修复方式:

然后运行;

额。。。已经可以运行起来了。
资源下载
服务端项目源代码
xmpp之java服务端实现tigase整合项目源代码
注意,这个是idea以及gradle的项目,请用idea打开后自行设置project jdk以及 gradle的地址
这些开发环境每台机器不一样,我没办法预知所有人的环境的。
数据库端项目源代码
xmpp之java服务端实现tigase整合项目-数据库部分
是一个bak文件,postgresql导入数据库请参考:
注意,我执行tigase脚本时候用的数据库角色叫 dbuser,请你确保在恢复之前有dbuser这个数据库角色,没有的话自行创建一个dbuser角色。
postgresql数据库备份和恢复
PostgreSQL自带一个客户端pgAdmin,里面有个备份,恢复选项,也能对数据库进行备份 恢复(还原),但最近发现数据库慢慢庞大的时候,经常出错,备份的文件过程中出错的几率那是相当大,手动调节灰常有限。所以一直寻找完美的备份恢复方案。
梦里寻他千百度,伊人却在灯火阑珊处...其实PostgreSQL内置不少的工具,寻找的备份恢复方案就在其中:pg_dump,psql。这两个指令 在数据库的安装目录下,比如我自己本地安装的,路径形如:C:\Program Files\PostgreSQL\9.5\;然后进入到bin文件夹,会看到不少的exe文件,这就是PostgreSQL内置的工具了。里面会找到 pg_dump.exe,psql.exe两个文件。我们怎么用他们?
用法:
备份数据库,指令如下:
pg_dump -h 164.82.233.54 -U postgres databasename > C:\databasename.bak
开始-运行-cmd 弹出dos控制台;然后 在控制台里,进入PostgreSQL安装目录bin下:
cd C:\Program Files\PostgreSQL\9.0\bin
最后执行备份指令:
pg_dump -h 164.82.233.54 -U postgres databasename > C:\databasename.bak
指令解释:如上命令,pg_dump 是备份数据库指令,164.82.233.54是数据库的ip地址(必须保证数据库允许外部访问的权限哦~),当然本地的数据库ip写 localhost;postgres 是数据库的用户名;databasename 是数据库名。> 意思是导出到C:\databasename.bak文件里,如果没有写路径,单单写databasename.bak文件名,那么备份文件会保存在C: \Program Files\PostgreSQL\9.0\bin 文件夹里。
恢复数据库,指令如下:
psql -h localhost -U postgres -d databasename < C:\databasename.bak(测试没有成功)
pg_restore.exe --host localhost --port 5432 --username "postgres" --dbname "symbolmcnew" --no-password --verbose "databasename.backup"(测试成功)
指令解释:如上命令,psql是恢复数据库命令,localhost是要恢复到哪个数据库的地址,当然你可以写上ip地址,也就是说能远程恢复(必须保证 数据库允许外部访问的权限哦~);postgres 就是要恢复到哪个数据库的用户;databasename 是要恢复到哪个数据库。< 的意思是把C:\databasename.bak文件导入到指定的数据库里。
以上所有的是针对windows而言的,如果在linux下,会不会有效?
在linux里依然有效。有一个值得注意的是:如果直接进入PostgreSQL的安装目录bin下,执行命令,可能会出现 找不到pg_dump,psql的现象,我们在可以这样:
备份:
/opt/PostgreSQL/9.5/bin/pg_dump -h 164.82.233.54 -U postgres databasename > databasename.bak
恢复:
/opt/PostgreSQL/9.5/bin/psql -h localhost -U postgres -d databasename < databasename.bak