虚拟机(Centos 7)上配置hadoop&多台主机
安装ssh
使用 yum install ssh 会得到报错No package ssh available,修改为yum install openssh-server即可
查看主机名称
![]()
安装jdk
![]()
虚拟机初始并未安装JAVA,无需卸载初始版本
查看系统位数为64位
![]()
官网下载JDK,选择linux64位得到.tar.gz文件(未使用这种方法)
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
参考资料:https://blog.csdn.net/qq_32786873/article/details/78749384
选择 利用yum源安装jdk
yum -y list java*
yum -y install java-1.8.0-openjdk* 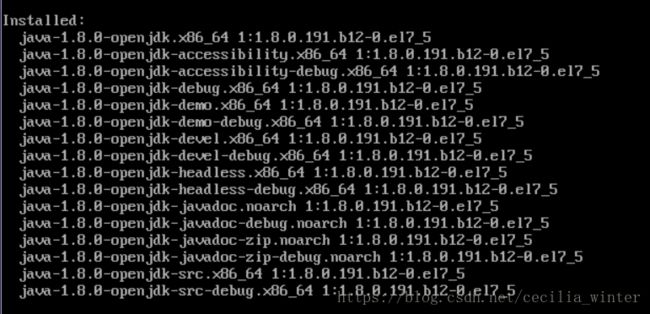
![]()
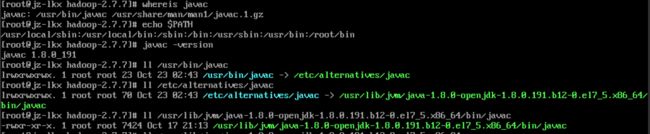
查看JAVA版本

安装成功,安装路径为 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.191.b12-0.el7_5.x86_64

配置jdk环境(yum安装不需要配置)
vi /etc/profile
ps查看java_home的方法
https://blog.csdn.net/renfufei/article/details/52621034
安装hadoop
下载hadoop
http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.7/
上载到跳板服务器
C:\Users\lingdong\Desktop\hadoop-2.7.7.tar.gz为文件路径
[email protected]为跳板服务器地址
scp -P 7798 C:\Users\lingdong\Desktop\hadoop-2.7.7.tar.gz [email protected]:(下载)
scp -P 7798 [email protected]:profile C:\Users\lingdong\Desktop![]()
从跳板服务器下载

在/下新建文件夹hadoop
mkdir hadoop
解压文件
tar -xvf hadoop-2.7.7.tar.gz -C /hadoop修改配置文件(同在ubuntu中)在hadoop文件下/etc/hadoop中
由于虚拟机不能复制粘贴所以在本机中修改完后上传到服务器中
![]()
覆盖之前的文件夹
来尝试启动namenode

失败了.......JAVA_HOME我真的改了哭嘤嘤,反正是水逆少女了那就撸起袖子继续改吧
虽然真的很不能理解可爱的空行哪里惹到他,可能是在本机编译的时候出了一些问题,找到原始文件重新修改上传了一下关于空格的报错消失了

现在找JAVA_HOME哪里出了问题
找到问题的一瞬间眼泪流下来
![]()
这个可爱的-0.el7_5,我看成了1,但他是个l,心疼的抱住眼神不好的自己(为什么当时不知道可以用Tab键自动补全)
但问题还是没有解决,出现了大概长这个样子的报错
exprot :''is not a valid identifier
是因为在配置JAVA_HOME的时候出现了空格,把邪恶的小空格删掉就就可以顺利的初始化namenode了
![]()
(但水逆本逆怎么会这么轻松就成功)
尝试start-all
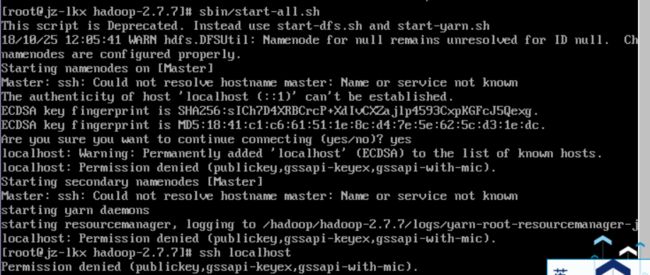
可以看到出了一些问题 ,输入ssh localhost可以看到被denied了
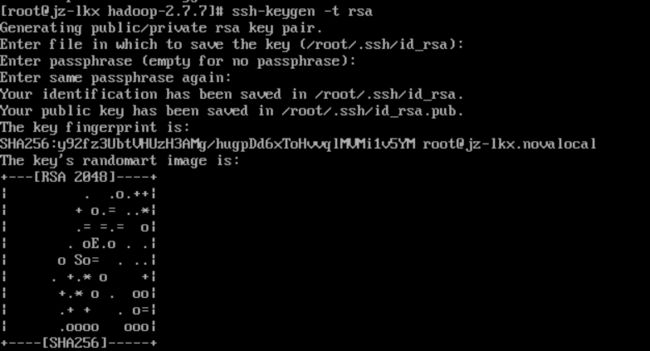
设置免密登陆
输入指令ssh-keygen -t rsa,开始疯狂空格
进入~/.ssh

拷贝公钥
cp id_dsa.pub authorized_keysfinish 哈哈哈哈哈哈哈
现在重新start-all一下,jps看一下整个世界都欢快了起来
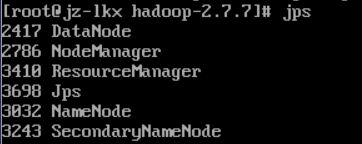
连通多台主机
查看一下自己的ip地址,使用ifconfig或者ip addr或者直接看都可以

修改/etc/hosts文件,将队友们的IP加进去

可以尝试ping IP一下看一下是否可以连接,现在连接是没有问题的
现在sshli接其他主机会出现permission senied
修改 /etc/ssh/sshd_config
将这一行的no改为yes
![]()
重启sshd
![]()
目前登陆是需要密码的
用ssh-copy-id复制一下对方的密码就可以免密登陆了
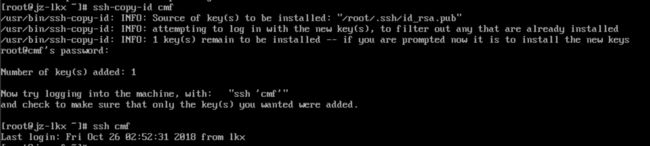
接下来要修改配置文件
修改/etc/hosts文件中的前两行均添加自己的名字lkx(后面仍要修改具体内容见配置文件部分)

将配置文件中的 localhost部分都改成自己的名字lkx
备份一份配置文件到主机防止覆盖出错(hadoop文件夹下/etc/haddop)
以下为主节点操作
将作为主结点的主机的配置文件修改,具体修改内容见下配置文件部分
slaves文件中添加子节点(目前只有一个子节点)
覆盖其他成员的配置文件
子节点操作
将hadoop文件夹与java_home文件夹都移动/复制到与主节点相同的位置,否则在主节点启动的时候会出现文件夹位置不同的问题
子节点关闭之前启动的namenode等
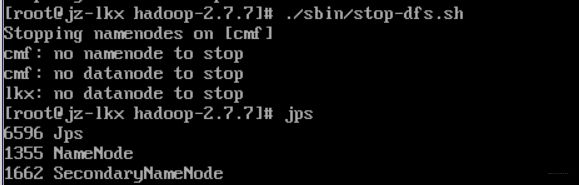
诶关不了,没关系没有什么事情是一次重启解决不了的
![]()
![]()
好的现在只有jps了
现在是见证奇迹的时刻
主节点操作:
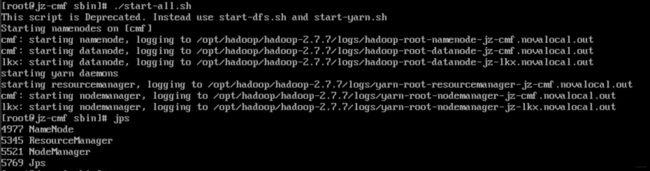
子节点jps一下:

成功five!
配置文件
配置文件 /etc/host
172.16.1.20 cmf
172.16.1.18 yzb
172.16.1.24 lyh
172.16.1.6 lkx配置文件core-site.xml
core-site.xml是hadoop的核心配置文件,hadoop.tmp.dir配置了hadoop的tmp目录的根位置为/opt/hadoop/tmp,fs.default.name配置了hadoop的HDFS系统的命名,指定namenode为cmf,端口为9000,
hadoop.tmp.dir
/opt/hadoop/tmp
Abase for other temporary directories.
fs.default.name
hdfs://cmf:9000
配置文件hdfs-site.xml
hdfs-site.xml是hdfs的配置文件,dfs.namenode.name.dir配置namenode数据存放位置为/opt/hadoop/data/nameNode,dfs.datanode.data.dir配置datanode数据存放位置为/opt/hadoop/data/dataNode,dfs.replication配置了文件块的副本数为2。
dfs.namenode.name.dir
/opt/hadoop/data/nameNode
dfs.datanode.data.dir
/opt/hadoop/data/dataNode
dfs.datanode.directoryscan.throttle.limit.ms.per.sec
1000
dfs.replication
2
配置文件yarn-site.xml
yarn-site.xml为yarn框架的配置,配置了任务的启动位置为cmf
yarn.acl.enable
0
yarn.resourcemanager.hostname
cmf
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.resource.memory-mb
8196
yarn.scheduler.maximum-allocation-mb
8196
yarn.scheduler.minimum-allocation-mb
128
yarn.nodemanager.vmem-check-enabled
false
配置文件mapred-site.xml
mapred-site.xml定义了关于mapreduce运行的一些参数,MapReduce依赖的框架为yarn,为每个map slot和Reduce task预留的内存均为4096MB,为每个子线程任务最多分配4096MB内存
mapreduce.framework.name
yarn
yarn.app.mapreduce.am.resource.mb
4096
mapreduce.map.memory.mb
4096
mapred.child.java.opts
-Xmx4096m
mapreduce.reduce.memory.mb
4096
slaves
包含3个子节点yzb、lyh、lkx
(如果在slaves未包含master,那么master启动时不应该出现datanode,如果包含了启动时应出现)
yzb
lyh
lkxhadoop-env.sh
在hadoop-env.sh中修改JAVA_HOME为本机JDK的安装位置
export JAVA_HOME=/opt/java/jdk1.8.0_191感谢世界上最可爱最善良最美丽的cmf小仙女提供的帮助
如果我不在这里夸一夸她大概会被打(逃
还有我的队友 yzb & lyh 的配置文件贡献