linux资源监控命令/工具(综合)
目录:
ps
pstree
pidof
top
free
uptime
ifuser
lsof
mpstat
vmstst
pidstat
iostat
iotop
watch
sar
1、ps
1)让系统报告详细的信息。
在使用ps命令时,如果不采用任何的可选项,则其显示的信息是非常有限的,而且往往只显示当前用户所运行的程序。当系统管理员需要知道应用程序更加详细的运行信息时,如想要知道这个应用程序内存、CPU的占用率情况时,那么就需要加入一些可选项。如系统管理员需要一并查看其它用户所执行的应用程序时,就需 要在这个命令后面采用可选项-al。如此的话,系统会列出系统中所有用户运行的所有程序。如想要知道某个程序CPU与内存的使用情况,而不是只简单的现实 其CPU的使用时间,那么就需要在这个命令后面加入参数-l ,即使用ps –l命令可以让系统显示出应用程序的详细运行信息。关于上面各个字段所代表的含义,大家若有兴趣的话可以查看相关的帮助。一般来说,系统管理员关心的只是 程序的PID号码、内存与CPU的使用率、命令的名字、用户采用的终端等等。其它的信息对于系统管理员来说价值不是很大。
2)查看后台运行的程序。
默认情况下,ps命令只显示前台运行的程序,而不会显示后台运行的程序。但是并非所有的程序都是在前台运行。正常情况下,隐藏在后台运行的程序数量要比前 台运行的程序多的多。如随着操作系统启动而启动的不少系统自带程序,其运行的方式都是后台运行。而且有时候,系统出现问题往往是由于后台程序所造成的。如 常见的木马等程序都是在后台所运行的。为此系统管理员相对来说,更加想要知道在后台运行着哪些程序。
如果要查看后台运行的程序,那就比较复杂一点。因为在不同版本的Linux操作系统中,要显示后台进程其所采用的可选项是不同的。如在红帽子 Linux操作系统中,其实采用参数的形式而不是可选项。即采用ps aux命令可以显示出所有的应用程序(包括前台与后台的)。参数与可选项的差异主要在前面又没有这个-符号。如果带有这个符号的就表示这是一个可选项。而如果不带的,就表示这事一个参数。这个符号一般情况下可不能够省。在该写的地方没写,或者不需要些的地方偏偏加上了,则系统都会提示错误信息,说找不到这 个命令。而在其它的Linux系统版本中,可能不能够识别这个aux参数。如在一些Linux操作系统版本中,需要采用-a可选项来完成这个任务。由于系 统版本之间的差异,给系统管理员带来了不少的麻烦。不过值得庆幸的是,各个操作系统版本中都有在线的帮助。如果系统管理员在使用一个新版本的操作系统时, 不知道要显示全部进程该使用哪个可选项时,可以利用ps --heip等命令来查看系统帮助。不过美中不足的是,系统在线帮助都是英文的,对系统管理员的英文水平是一个不小的考验。不过如果要作Linux系统管 理员,这点英文底子还是要有的。因为最新的Linux技术基本上都是先出来英文文档的。其实要掌握最先进的操作系统书籍,大部分的计算机书籍都是英文的。
3)对程序列表进行排序。
当运行的应用程序比较多时,系统管理员需要对应用程序进行排序。Ps命令的排序功能是比较强的。主要是因为这个命令有一个--sort参数(注意在这个参 数前面采用的是两个小横杆符号,各位读者不要以为是笔者写错了)。在这个参数后面加上系统管理员想要的排序字段,就可以进行排序了。如这个命令ps –A --sort cmd,就表示显示系统所有的应用程序,并根据程序命令来进行排序。在Linux操作系统参数中,还有一个比较麻烦的事情,就是参数大小写不同往往代表着不同的含义。如上面这个命令,将大写字母A换成是小写字符a,则结果就完全两样了。大写字符A表示所有的应用程序,而小写字符a则表示“all w/ tty except session leaders”。两者有本质的区别。通过这个差异可以用来过滤不同终端登陆帐户所运行的应用程序。
[root@linux ~]# ps aux
[root@linux ~]# ps -lA
[root@linux ~]# ps axjf
选项/参数:
-w 显示加宽可以显示较多的资讯
-au 显示较详细的资讯
-aux 显示所有包含其他使用者的行程
-A 显示所有进程(等价于-e)(utility)
-a 显示一个终端的所有进程,除了会话引线
-N 忽略选择。
-d 显示所有进程,但省略所有的会话引线(utility)
-x 显示没有控制终端的进程,同时显示各个命令的具体路径。dx不可合用。(utility)
-p pid 进程使用cpu的时间
-u uid or username 选择有效的用户id或者是用户名
-g gid or groupname 显示组的所有进程。
U username 显示该用户下的所有进程,且显示各个命令的详细路径。如:ps U zhang;(utility)
-f 全部列出,通常和其他选项联用。如:ps -fa or ps -fx and so on.
-l 长格式(有F,wchan,C 等字段)
-j 作业格式
-o 用户自定义格式。
v 以虚拟存储器格式显示
s 以信号格式显示
-m 显示所有的线程
-H 显示进程的层次(和其它的命令合用,如:ps -Ha)(utility)
e 命令之后显示环境(如:ps -d e; ps -a e)(utility)
h 不显示第一行
l 长格式输出;
u 按用户名和启动时间的顺序来显示进程;
j 用任务格式来显示进程;
f 用树形格式来显示进程;
a 显示所有用户的所有进程(包括其它用户);
x 显示无控制终端的进程;
r 显示运行中的进程;
ww 避免详细参数被截断;
ps命令常用用法(方便查看系统进程)
1)ps a 显示现行终端机下的所有程序,包括其他用户的程序。
2)ps -A 显示所有进程。
3)ps c 列出程序时,显示每个程序真正的指令名称,而不包含路径,参数或常驻服务的标示。
4)ps -e 此参数的效果和指定"A"参数相同。
5)ps e 列出程序时,显示每个程序所使用的环境变量。
6)ps f 用ASCII字符显示树状结构,表达程序间的相互关系。
7)ps -H 显示树状结构,表示程序间的相互关系。
8)ps -N 显示所有的程序,除了执行ps指令终端机下的程序之外。
9)ps s 采用程序信号的格式显示程序状况。
10)ps S 列出程序时,包括已中断的子程序资料。
11)ps -t<终端机编号> 指定终端机编号,并列出属于该终端机的程序的状况。
12)ps u 以用户为主的格式来显示程序状况。
13)ps x 显示所有程序,不以终端机来区分。
14)最常用的方法是ps -aux,然后再利用一个管道符号导向到grep去查找特定的进程,然后再对特定的进程进行操作。
特别说明:
由于ps能够支持的OS类型相当的多,所以他的参数多的离谱! 而且有没有加上-差很多!详细的用法应该要参考man ps喔!
范例一:将目前属于您自己这次登入的PID与相关信息列示出来(前台)
[root@linux ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
0 S 0 5881 5654 0 76 0 - 1303 wait pts/0 00:00:00 su
4 S 0 5882 5881 0 75 0 - 1349 wait pts/0 00:00:00 bash
4 R 0 6037 5882 0 76 0 - 1111 - pts/0 00:00:00 ps
上面这个信息其实很多喔!各相关信息的意义为:
F 代表这个程序的旗标(flag), 4 代表使用者为super user;
S 代表这个程序的状态(STAT);
PID 就是这个程序的ID啊!底下的PPID则上父程序的ID;
C CPU使用的资源百分比
PRI 这个是Priority(优先执行序)的缩写;
NI 这个是Nice值;
ADDR 这个是kernel function,指出该程序在内存的那个部分。如果是个running的程序,一般就是『 - 』的啦!
SZ 使用掉的内存大小;
WCHAN 目前这个程序是否正在运作当中,若为-表示正在运作;
TTY 登入者的终端机位置啰;
TIME 使用掉的CPU时间。
CMD 所下达的指令为何!?
仔细看到每一个程序的PID与PPID的相关性为何喔!上头列出的三个程序中,彼此间可是有相关性的吶!
范例二:列出目前所有的正在内存当中的程序:
[root@linux ~]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 1740 540 ? S Jul25 0:01 init [3]
root 2 0.0 0.0 0 0 ? SN Jul25 0:00 [ksoftirqd/0]
root 3 0.0 0.0 0 0 ? S< Jul25 0:00 [events/0]
.....中间省略.....
root 5881 0.0 0.3 5212 1204 pts/0 S 10:22 0:00 su
root 5882 0.0 0.3 5396 1524 pts/0 S 10:22 0:00 bash
root 6142 0.0 0.2 4488 916 pts/0 R+ 11:45 0:00 ps aux
各相关信息的意义为:
USER:该process属于那个使用者账号的?
PID :该process的号码。
%CPU:该process使用掉的CPU 资源百分比;
%MEM:该process所占用的物理内存百分比;
VSZ :该process使用掉的虚拟内存量(Kbytes)
RSS :该process占用的固定的内存量(Kbytes)
TTY :该process是在那个终端机上面运作,若与终端机无关,则显示?,另外tty1-tty6是本机上面的登入者程序,若为pts/0等的则表示为由网络连接进主机的程序。
STAT:该程序目前的状态,主要的状态有:
R :该程序目前正在运作,或者是可被运作;
S :该程序目前正在睡眠当中(可说是idle 状态啦!),但可被某些讯号(signal)唤醒。
T :该程序目前正在侦测或者是停止了;
Z :该程序应该已经终止,但是其父程序却无法正常的终止他,造成zombie(疆尸)程序的状态
I:空闲 Idle
D:不可中断 Uninterruptible sleep (ususally IO) 收到信号不唤醒和不可运行, 进程必须等待直到有中断发生。
T:终止 Terminate 进程收到SIGSTOP, SIGSTP, SIGTIN, SIGTOU信号后停止运行运行。
P:等待交换页
W:无驻留页 has no resident pages 没有足够的记忆体分页可分配。
X:死掉的进程
<:高优先级进程 高优先序的进程
N:低优先 级进程 低优先序的进程
L:内存锁页 Lock 有记忆体分页分配并缩在记忆体内
s:进程的领导者(在它之下有子进程);
l:多进程的(使用 CLONE_THREAD, 类似 NPTL pthreads)
+:位于后台的进程组
START:该process 被触发启动的时间;
TIME :该process 实际使用CPU 运作的时间。
COMMAND:该程序的实际指令为何?
范例三:以范例一的显示内容,显示出所有的程序:
[root@linux ~]# ps -lA
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 1 0 0 76 0 - 435 - ? 00:00:01 init
1 S 0 2 1 0 94 19 - 0 ksofti ? 00:00:00 ksoftirqd/0
1 S 0 3 1 0 70 -5 - 0 worker ? 00:00:00 events/0
.....以下省略.....
范例四:列出类似程序树的程序显示:
[root@linux ~]# ps -axjf
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
0 1 0 0 ? -1 S 0 0:01 init [3]
1 2 0 0 ? -1 SN 0 0:00 [ksoftirqd/0]
.....中间省略.....
1 5281 5281 5281 ? -1 Ss 0 0:00 /usr/sbin/sshd
5281 5651 5651 5651 ? -1 Ss 0 0:00 \_ sshd: dmtsai[priv]
5651 5653 5651 5651 ? -1 S 500 0:00 \_ sshd: dmtsai@pts/0
5653 5654 5654 5654 pts/0 6151 Ss 500 0:00 \_ -bash
5654 5881 5881 5654 pts/0 6151 S 0 0:00 \_ su
5881 5882 5882 5654 pts/0 6151 S 0 0:00 \_ bash
5882 6151 6151 5654 pts/0 6151 R+ 0 0:00 \_ ps -axjf
还可以使用pstree来达成这个程序树喔!
范例五:找出与cron与syslog这两个服务有关的PID号码?
[root@linux ~]# ps aux | egrep '(cron|syslog)'
root 1539 0.0 0.1 1616 616 ? Ss Jul25 0:03 syslogd -m 0
root 1676 0.0 0.2 4544 1128 ? Ss Jul25 0:00 crond
root 6157 0.0 0.1 3764 664 pts/0 R+ 12:10 0:00 egrep(cron|syslog)
所以号码是1539及1676这两个
2、pstree
[root@linux ~]# pstree [-Aup]
参数:
-A:各程序树之间的连接以ASCII字符来连接;
-p:并同时列出每个process的PID;
-u:并同时列出每个process的所属账号名称。
范例一:列出目前系统上面所有的程序树的相关性:
[root@linux ~]# pstree
范例二:承上题同时秀出PID与users
[root@linux ~]# pstree -aup
在括号()内的即是PID以及该程序的owner!不过,由于我是使用root的身份执行此一指令,所以属于root的可能就不会显示出来
3、pidof
[root@linux ~]# pidof [-sx] program_name
参数:
-s:仅列出一个PID而不列出所有的PID
-x:同时列出该 program name可能的PPID那个程序的PID
范例一:列出目前系统上面init以及syslogd这两个程序的PID
[root@linux ~]# pidof init syslogd
1 2546
理论上,应该会有两个PID才对。上面的显示也是出现了两个PID喔。分别是init及syslogd这两支程序的PID啦。
范例二:找出bash即以bash为PPID的几个主要的PID
[root@linux ~]# pidof -x bash
2961 2959 338
因为我的系统被我登入之后,我就会主动取得一个bash的程序,所以啰,很自然就会拥有一个PID啊。只要我再以底下的方式,就可以取得我所想要的PID内容。
[root@linux ~]# ps aux | egrep '(2961|2959|338)'
dmtsai 338 0.0 0.1 6024 1536 pts/0 Ss 16:43 0:00 -bash
kiki 2961 0.0 0.1 6025 1526 pts/0 Ss 17:43 0:00 -bash
.....以下省略......
4、top
实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器
[root@linux ~]# top [-d] | top [-bnp]
参数:
-d:后面可以接秒数,就是整个程序画面更新的秒数。预设是5秒;
-b:以批次的方式执行 top
通常会搭配数据流重导向来将批次的结果输出成为档案。
-n: 与-b搭配,意义是需要进行几次top的输出结果。
-p:指定某些个PID来进行观察监测
在top执行过程当中可以使用的按键指令:
?:显示在top当中可以输入的按键指令;
P:以CPU的使用资源排序显示;
M:以Memory的使用资源排序显示;
N:以PID来排序喔!
T:由该Process使用的CPU时间累积(TIME+)排序。
k:给予某个PID一个讯号(signal)
r:给予某个PID重新制订一个nice值。
范例一:每两秒钟更新一次top,观察整体信息:
[root@linux ~]# top -d 2
范例二:将top的信息进行2次,然后将结果输出到/tmp/top.txt
[root@linux ~]# top -b -n 2 > /tmp/top.txt
范例三:假设10604是一个已经存在的PID,仅观察该程序
[root@linux ~]# top -d 2 -p10604
范例四:承上题,上面的NI值是0,想要改成10的话? 在范例三的top画面当中直接按下r之后会出现如下的图样:
top - 13:53:00 up 51 days, 2:27, 1 user, load average: 0.00,0.00, 0.00
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0% us, 0.0% sy, 0.0% ni, 100.0% id, 0.0% wa, 0.0% hi, 0.0% si
Mem: 385676k total, 371760k used, 13916k free, 131164k buffers
Swap: 1020116k total, 880k used, 1019236k free, 95772k cached
PID to renice: 10604
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10604 root 16 0 5396 1544 1244 S 0.0 0.4 0:00.07 bash
之后,可以输入nice值了!
top - 13:53:00 up 51 days, 2:27, 1 user, load average: 0.00,0.00, 0.00
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0% us, 0.0% sy, 0.0% ni, 100.0% id, 0.0% wa, 0.0% hi, 0.0% si
Mem: 385676k total, 371760k used, 13916k free, 131164k buffers
Swap: 1020116k total, 880k used, 1019236k free, 95772k cached
Renice PID 10604 to value: 10
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10604 root 30 10 5396 1544 1244 S 0.0 0.4 0:00.07 bash
top输出解析:

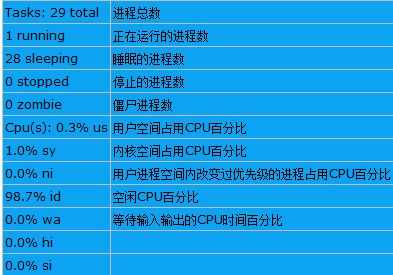
top主要分为两个画面,上面的画面为整个系统的资源使用状态,基本上总共有六行,显示的内容依序是:
第一行:显示系统已启动的时间、目前上线人数、系统整体的负载(load)。 比较需要注意的是系统的负载,三个数据分别代表1,5,10分钟的平均负载。一般来说,这个负载值应该不太可能超过1才对,除非您的系统很忙碌。如果持续高于5的话,那么.....仔细的看看到底是那个程序在影响整体系统吧

第二行:显示的是目前的观察程序数量,比较需要注意的是最后的zombie那个数值,如果不是0,好好看看到底是那个process变成疆尸了吧
第三行:显示的是CPU的整体负载,每个项目可使用?查阅。需要观察的是id (idle)的数值,一般来说,他应该要接近100%才好,表示系统很少资源被使用
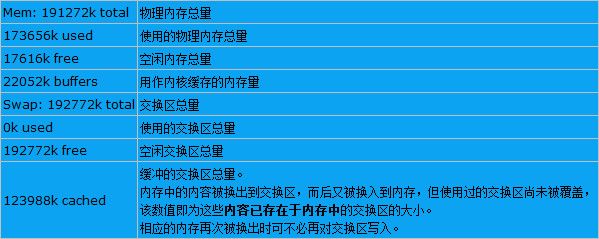
第四行与第五行:表示目前的物理内存与虚拟内存 (Mem/Swap) 的使用情况。
第六行以后:这个是当在top程序当中输入指令时,显示状态的地方。top底下的画面,则是每个process使用的资源情况。
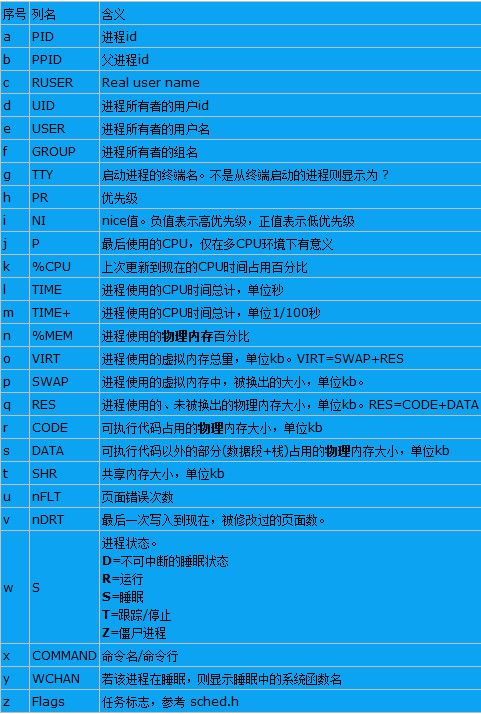
默认情况下仅显示比较重要的PID、USER、PR、NI、VIRT、RES、SHR、S、%CPU、%MEM、TIME+、COMMAND 列。可以通过下面的快捷键来更改显示内容。
更改显示内容:
1)通过 f 键可以选择显示的内容。按 f 键之后会显示列的列表,按 a-z 即可显示或隐藏对应的列,最后按回车键确定。
2)按 o 键可以改变列的显示顺序。按小写的 a-z 可以将相应的列向右移动,而大写的 A-Z 可以将相应的列向左移动。最后按回车键确定。
3)按大写的 F 或 O 键,然后按 a-z 可以将进程按照相应的列进行排序。而大写的 R 键可以将当前的排序倒转。
5、free
[root@linux ~]# free [-b|-k|-m|-g] [-t]
参数:
-b 以Byte为单位显示内存使用情况。
-k 以KB为单位显示内存使用情况。
-m 以MB为单位显示内存使用情况。
-g 以GB为单位显示内存使用情况。
-o 不显示缓冲区调节列。
-s<间隔秒数> 持续观察内存使用状况。
-t 显示内存总和列。
-V 显示版本信息。
范例一:显示目前系统的内存容量,以MB为单位
[root@linux ~]# free -m
total used free shared buffers cached
Mem: 376 366 10 0 129 94
-/+ buffers/cache: 141 235
Swap: 996 0 995
free输出解析:
Mem:表示物理内存统计

-/+ buffers/cache:表示物理内存的缓存统计

(注:系统当前真正可用的内存并不是第一行free1标记的值,它仅代表未被分配的内存。而应该是第二行free2标记的值)
Swap:表示硬盘上交换分区的使用情况,已使用、空闲的swap
1)buffers与cached的区别
A buffer is something that has yet to be “written” to disk. A cache is something that has been “read” from the disk and stored for later use
对于应用程序来说,buffers/cached是等于可用的,因为buffer/cached是为了提高文件读取的性能,当应用程序需在用到内存的时候,buffer/cached会很快地被回收。所以从应用程序的角度来说:可用内存 = 系统free memory + buffers + cached,即上面的free2的值。
buffers是指用来给块设备做的缓冲大小,他只记录文件系统的metadata以及tracking in-flight pages。cached是用来给文件做缓冲。那就是说:buffers是用来存储的,而cached是直接用来记忆我们打开的文件,如果你想知道他是不是真的生效,你可以试一下,先后执行两次命令#man X ,你就可以明显的感觉到第二次的开打的速度快很多。
2)简述swap
当可用内存少于额定值的时候,就会开始进行交换.
如何看额定值(RHEL4.0): #cat /proc/meminfo
交换将通过三个途径来减少系统中使用的物理页面的个数:
1)减少缓冲与页面cache的大小,
2)将系统V类型的内存页面交换出去,
3)换出或者丢弃页面。(Application 占用的内存页,也就是物理内存不足)。
少量地使用swap是不是影响到系统性能的。一般来说,swap最好不要被使用,尤其swap最好不要被使用超过20%或以上, 因为Swap的效率跟物理内存实在差很多,而系统会使用到swap,是因为物理内存不足了才会这样做。
3)使用free命令
将used的值减去buffer和cache的值就是你当前真实内存使用量。 buffer/cached是为了提高程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。 所以,以应用角度来看,以(-/+ buffers/cache)的free和used为主,所以我们看这个就好了。
另外一些常识,Linux为了提高磁盘和内存存取效率, Linux做了很多精心的设计, 除了对dentry进行缓存(用于VFS,加速文件路径名到inode的转换), 还采取了两种主要Cache方式:Buffer Cache和Page Cache。 前者针对磁盘块的读写,后者针对文件inode的读写。这些Cache能有效缩短了I/O系统调用(比如read,write,getdents)的时间。 记住内存是拿来用的,不是拿来看的。不象windows,无论你的真实物理内存有多少,他都要拿硬盘交换文件来读。这也就是windows为什么常常提示虚拟空间不足的原因.你们想想,多无聊,在内存还有大部分的时候,拿出一部分硬盘空间来充当内存。硬盘怎么会快过内存。所以我们看linux,只要不用swap的交换空间,就不用担心自己的内存太少。如果常常swap用很多,可能你就要考虑加物理内存了。这也是linux看内存是否够用的标准。
6、uptime
uptime可以显示出top画面的最上面一行!
[root@linux ~]# uptime
18:06:30 up 52 days, 6:40, 1 user, load average: 0.00, 0.00, 0.00
上面表示,目前是18:06 ,本系统已经开机52天又6:40 ,有1个使用者在在线,平均负载很低,所以都是0啊!
7、fuser
如果当我们要卸载某个装置时,他老是告诉我们device is busy , 那么到底是那个程序在使用这个装置呢?举例来说,当无法 umount /home时, 该怎么办?此时我们可以使用fuser来帮忙啦!
[root@linux ~]# fuser [-ki] [-signal] file/dir
参数:
-k :找出使用该档案/目录的PID ,并试图以SIGKILL这个讯号给予该PID;
-i :必须与-k配合,在删除PID之前会先询问使用者意愿!
-signal:例如-1 -15等等,若不加的话,预设是SIGKILL (-9)啰!
范例一:找出目前所在目录的使用PID为何?
[root@linux ~]# fuser .
.: 18852c
[root@linux ~]# ps aux | grep 18852
root 18852 0.0 0.4 5396 1588 pts/0 SN 10:12 0:00 bash
用这个方式就可以得到使用该目录的PID了。此外,为何使用fuser的输出当中,在PID后面会有c呢?他代表的意义为:
c:在当前的目录下;
e:可以被执行的;
f:是一个被开启的档案
r:代表root directory
范例二:找到/var底下属于FIFO类型的档案,并且找出存取该档案的程序
[root@linux ~]# find /var -type p
/var/spool/postfix/public/qmgr
/var/spool/postfix/public/pickup
[root@linux ~]# fuser /var/spool/postfix/public/qmgr
/var/spool/postfix/public/qmgr: 1666 1675
[root@linux ~]# ps aux | egrep '(1666|1675)'
root 1666 0.0 0.3 5640 1516 ? Ss Jul25 0:01 /usr/libexec/postfix/master
postfix 1675 0.0 0.4 5744 1604 ? S Jul25 0:00 qmgr -l -t fifo -u
范例三:同范例二,但试图删除该PID?
[root@linux ~]# fuser -ki /var/spool/postfix/public/qmgr
/var/spool/postfix/public/qmgr: 1666 1675
Kill process 1666 ? (y/N) n
Kill process 1675 ? (y/N) n
8、lsof
lsof [options] filename
列出当前系统打开文件的工具。在linux环境下,任何事物都以文件的形式存在,通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件。所以如传输控制协议 (TCP) 和用户数据报协议 (UDP) 套接字等,系统在后台都为该应用程序分配了一个文件描述符,无论这个文件的本质如何,该文件描述符为应用程序与基础操作系统之间的交互提供了通用接口。因为应用程序打开文件的描述符列表提供了大量关于这个应用程序本身的信息,因此通过lsof工具能够查看这个列表对系统监测以及排错将是很有帮助的。
如果说netcat是进行网络诊断的瑞士军刀,那么lsof就是Unix调试的瑞士军刀。Lsof是遵从Unix哲学的典范,它只做一件事情,并且做的相当完美—它可以列出某个进程打开的所有文件信息。打开的文件可能是普通的文件,目录,NFS文件,块文件,字符文件,共享库,常规管道,明明管道,符号链接,Socket流,网络Socket,UNIX域Socket,以及其它更多。因为Unix系统中几乎所有东西都是文件,你可以想象lsof该有多有用。
在终端下输入lsof即可显示系统打开的文件,因为lsof需要访问核心内存和各种文件,所以必须以root用户的身份运行它才能够充分地发挥其功能。
1)列出所有打开的文件
lsof
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
init 1 root cwd DIR 8,1 4096 2 /
init 1 root rtd DIR 8,1 4096 2 /
init 1 root txt REG 8,1 150584 654127 /sbin/init
udevd 415 root 0u CHR 1,3 0t0 6254 /dev/null
udevd 415 root 1u CHR 1,3 0t0 6254 /dev/null
udevd 415 root 2u CHR 1,3 0t0 6254 /dev/null
udevd 690 root mem REG 8,1 51736 302589 /lib/x86_64-linux-gnu/libnss_files-2.13.so
syslogd 1246 syslog 2w REG 8,1 10187 245418 /var/log/auth.log
syslogd 1246 syslog 3w REG 8,1 10118 245342 /var/log/syslog
dd 1271 root 0r REG 0,3 0 4026532038 /proc/kmsg
dd 1271 root 1w FIFO 0,15 0t0 409 /run/klogd/kmsg
dd 1271 root 2u CHR 1,3 0t0 6254 /dev/null
每行显示一个打开的文件,若不指定条件默认将显示所有进程打开的所有文件。lsof输出各列信息的意义如下:
COMMAND:进程的名称
PID:进程标识符
USER:进程所有者
FD:文件描述符,应用程序通过文件描述符识别该文件。如cwd、txt等
TYPE:文件类型,如DIR、REG等
DEVICE:指定磁盘的名称
SIZE:文件的大小
NODE:索引节点(文件在磁盘上的标识)
NAME:打开文件的确切名称
FD列中的文件描述符cwd值表示应用程序的当前工作目录,这是该应用程序启动的目录,除非它本身对这个目录进行更改,txt类型的文件是程序代码,如应用程序二进制文件本身或共享库,如上列表中显示的/sbin/init程序。其次数值表示应用程序的文件描述符,这是打开该文件时返回的一个整数。如上的最后一行文件/dev/initctl,其文件描述符为 10。u 表示该文件被打开并处于读取/写入模式,而不是只读 ? 或只写 (w) 模式。同时还有大写 的W 表示该应用程序具有对整个文件的写锁。该文件描述符用于确保每次只能打开一个应用程序实例。初始打开每个应用程序时,都具有三个文件描述符,从0到2,分别表示标准输入、输出和错误流。所以大多数应用程序所打开的文件的FD都是从3开始。
与FD列相比,Type列则比较直观。文件和目录分别称为REG和DIR。而CHR和BLK分别表示字符和块设备;或者UNIX、FIFO和IPv4,分别表示UNIX 域套接字、先进先出(FIFO)队列和网际协议(IP)套接字。
2)找出谁(进程)在使用某个文件
lsof /path/to/file
只需要执行文件的路径,lsof就会列出所有使用这个文件的进程,你也可以列出多个文件,lsof会列出所有使用这些文件的进程:lsof /path/to/file1 /path/to/file2
lsof /etc/passwd 哪个进程在占用/etc/passwd
lsof /dev/hda6 哪个进程在占用hda6
lsof /dev/cdrom 哪个进程在占用光驱
lsof `which httpd` 哪个进程在使用apache的可执行文件
3)递归查找某个目录中所有打开的文件
lsof +D /usr/lib
加上+D参数,lsof会对指定目录进行递归查找,注意这个参数要比grep版本慢:lsof|grep '/usr/lib',之所以慢是因为+D首先查找所有的文件,然后一次性输出。
4)列出某个用户打开的所有文件
lsof -u pkrumins
-u选项限定只列出所有被用户pkrumins打开的文件,你可以通过逗号指定多个用户:lsof -u rms,root,这条命令会列出所有rms和root用户打开的文件。你也可以像下面这样使用多个-u做同样的事情:lsof -u rms -u root
5)查找某个程序打开的所有文件
lsof -c apache
-c选项限定只列出以apache开头的进程打开的文件,所以你可以不用像下面这样写:lsof | grep foo,而使用下面这个更简短的版本:lsof -c foo
lsof -c sendmail 查看sendmail进程的文件使用情况
lsof -c courier -u ^zahn 显示出那些文件被以courier打头的进程打开,但是并不属于用户zahn
也可以只指定进程名称的开头:lsof -c apa 这会列出所有以apa开头的进程打开的文件,同样可以制定多个-c参数:lsof -c apache -c python,这会列出所有由apache和python打开的文件。
6)组合。列出所有由某个用户或某个进程打开的文件
lsof -u pkrumins -c apache
可以组合使用多个选项,这些选项默认进行或关联,也就是说上面的命令会输入由pkrumins用户或是apache进程打开的文件。
列出所有由一个用户与某个进程打开的文件:lsof -a -u pkrumins -c bash -a参数可以将多个选项的组合条件由或变为与,上面的命令会显示所有由pkrumins用户以及bash进程打开的文件。
7)列出除root用户外的所有用户打开的文件
lsof -u ^root
注意root前面的^符号,它执行取反操作,因此lsof会列出所有root用户之外的用户打开的文件。
8)取反。列出所有由某个PID对应的进程打开的文件
lsof -p 1
-p选项让你可以使用进程id来过滤输出。也可以用逗号来分离多个pid:lsof -p 450,980,333
列出所有进程打开的文件除了某个pid的:lsof -p ^1 同前面的用户一样,你也可以对-p选项使用^来进行取反。
9)网络连接
lsof -i 列出所有网络连接,lsof的-i选项可以列出所有打开了网络套接字(TCP和UDP)的进程。
lsof -i tcp 列出所有TCP网络连接
lsof -i udp 列出所有UDP网络连接
lsof -i :25 找到使用某个端口的进程,:25和-i选项组合可以让lsof列出占用TCP或UDP的25端口的进程。也可以使用/etc/services中制定的端口名称来代替端口号,比如:lsof -i :smtp
lsof -i udp:53 找到使用某个udp端口号的进程
lsof -a -u hacker -i 找到某个用户的所有网络连接
lsof -N 列出所有NFS(网络文件系统)文件
lsof -U 列出所有UNIX域Socket文件
lsof -g 1234 列出所有对应某个组id的进程
10)文件描述符
lsof -d 2 列出所有以描述符2打开的文件
lsof -d 0-2 列出所有描述符为0,1,2的文件。
lsof -d mem 列出所有内存映射文件,-d选项还支持其它很多特殊值
11)输出使用某些资源的进程pid
lsof -t -i -t选项输出进程的PID,你可以将它和-i选项组合输出使用某个端口的进程的PID,下面的命令将会杀掉所有使用网络的进程:kill -9 `lsof -t -i`
12)循环列出文件
lsof -r 1 -r选项让lsof可以循环列出文件直到被中断,参数1的意思是每秒钟重复打印一次,这个选项最好同某个范围比较小的查询组合使用,比如用来监测网络活动:lsof -r 1 -u john -i -a
9、mpstat
mpstat(Multiprocessor Statistics)是实时系统监控工具。报告与CPU的一些统计信息,这些信息存放在/proc/stat文件中。在多CPUs系统里,不但能查看所有CPU的平均状况信息,而且能够查看特定CPU的信息。mpstat最大的特点是:可以查看多核心cpu中每个计算核心的统计数据;而类似工具vmstat只能查看系统整体cpu情况。
mpstat [-P {|ALL}] [internal [count]]
参数:
-P {|ALL} 表示监控哪个CPU, cpu在[0,cpu个数-1]中取值
internal 相邻的两次采样的间隔时间、
count 采样的次数,count只能和delay一起使用
当没有参数时,mpstat则显示系统启动以后所有信息的平均值。有interval时,第一行的信息自系统启动以来的平均信息。从第二行开始,输出为前一个interval时间段的平均信息。
1)该命令将每隔2秒输出一次CPU的当前运行状况信息,一共输出5次,如果没有第二个数字参数,mpstat将每隔两秒执行一次,直到按CTRL+C退出。
mpstat 2 5
Linux 2.6.32-71.el6.i686 (Stephen-PC) 11/12/2011 _i686_ (1 CPU)
04:03:00 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
04:03:02 PM all 0.00 0.00 0.50 0.00 0.00 0.00 0.00 0.00 99.50
04:03:04 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
04:03:06 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
04:03:08 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
04:03:10 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
Average: all 0.00 0.00 0.10 0.00 0.00 0.00 0.00 0.00 99.90
第一行的末尾给出了当前系统中CPU的数量。后面的表格中则输出了系统当前CPU的使用状况,以下为每列的含义:
%user 在internal时间段里,用户态的CPU时间(%),不包含nice值为负进程(usr/total)*100
%nice 在internal时间段里,nice值为负进程的CPU时间(%) (nice/total)*100
%sys 在internal时间段里,内核时间(%) (system/total)*100
%iowait 在internal时间段里,硬盘IO等待时间(%) (iowait/total)*100
%irq 在internal时间段里,硬中断时间(%) (irq/total)*100
%soft 在internal时间段里,软中断时间(%) (softirq/total)*100
%idle 在internal时间段里,CPU除去等待磁盘IO操作外的因为任何原因而空闲的时间闲置时间(%) (idle/total)*100
计算公式如下:
total_cur=user+system+nice+idle+iowait+irq+softirq
total_pre=pre_user+ pre_system+ pre_nice+ pre_idle+ pre_iowait+ pre_irq+ pre_softirq
user=user_cur – user_pre
total=total_cur-total_pre
其中_cur 表示当前值,_pre表示interval时间前的值。上表中的所有值可取到两位小数点。
2)如果要看每个cpu核心的详细当前运行状况信息,输出如下:
mpstat -P ALL 2 3
-P ALL表示打印所有CPU的数据,这里也可以打印指定编号的CPU数据,如-P 0(CPU的编号是0开始的)
10、vmstat
用来获得UNIX系统有关进程、虚存、页面交换空间及CPU活动的信息。这些信息反映了系统的负载情况。vmstat首次运行时显示自系统启动开始的各项统计信息,之后运行vmstat将显示自上次运行该命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所需的统计信息。
1)每隔1秒输出一条信息,一共输出3条后退出
vmstat 1 3
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 531760 67284 231212 108 0 0 260 111 148 1 5 86 8 0
0 0 0 531752 67284 231212 0 0 0 0 33 57 0 1 99 0 0
0 0 0 531752 67284 231212 0 0 0 0 40 73 0 0 100 0 0
有关进程的信息有:(procs)
r: 在就绪状态等待的进程数,表示运行队列(就是说多少个进程真的分配到CPU),当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
b: 表示阻塞的进程。
1)有关内存的信息有:(memory)
swpd: 正在使用的swap大小,单位为KB。
free: 空闲的内存空间。
buff: 已使用的buff大小,对块设备的读写进行缓冲。
cache: 已使用的cache大小,文件系统的cache。
2)有关页面交换空间的信息有:(swap)
si: 交换内存使用,由磁盘调入内存,每秒传输的大小。
so: 交换内存使用,由内存调入磁盘,每秒传输的大小。
3)有关IO块设备的信息有:(io)
bi: 从块设备读入的数据总量(读磁盘) (KB/s)
bo: 写入到块设备的数据总理(写磁盘) (KB/s)
4)有关故障的信息有:(system)
in: 在指定时间内的每秒中断次数。
sy: 在指定时间内每秒系统调用次数。
cs: 在指定时间内每秒上下文切换的次数。 例如调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在 apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
5)有关CPU的信息有:(cpu)
us: 在指定时间间隔内CPU在用户态的利用率。
sy: 在指定时间间隔内CPU在核心态的利用率。
id: 在指定时间间隔内CPU空闲时间比。
wa: 在指定时间间隔内CPU因为等待I/O而空闲的时间比。
vmstat可以用来确定一个系统的工作是受限于CPU还是受限于内存:如果CPU的sy和us值相加的百分比接近100%,或者运行队列(r)中等待的进程数总是不等于0,且经常大于4,同时id也经常小于40,则该系统受限于CPU;如果bi、bo的值总是不等于0,则该系统受限于内存。
11、pidstat
主要用于监控全部或指定进程占用系统资源的情况,如CPU,内存、设备IO、任务切换、线程等。pidstat首次运行时显示自系统启动开始的各项统计信息,之后运行pidstat将显示自上次运行该命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所需的统计信息。
参数:
-l 显示该进程和CPU相关的信息(command列中可以显示命令的完整路径名和命令的参数)。
-d 显示该进程和设备IO相关的信息。
-r 显示该进程和内存相关的信息。
-w 显示该进程和任务时间片切换相关的信息。
-t 显示在该进程内正在运行的线程相关的信息。
-p 后面紧跟着带监控的进程id或ALL(表示所有进程),如不指定该选项,将监控当前系统正在运行的所有进程。
1)监控pid为1(init)的进程的CPU资源使用情况,其中每隔3秒刷新并输出一次,3次后程序退出
pidstat -p 1 2 3 -l
07:18:58 AM PID %usr %system %guest %CPU CPU Command
07:18:59 AM 1 0.00 0.00 0.00 0.00 0 /sbin/init
07:19:00 AM 1 0.00 0.00 0.00 0.00 0 /sbin/init
07:19:01 AM 1 0.00 0.00 0.00 0.00 0 /sbin/init
Average: 1 0.00 0.00 0.00 0.00 - /sbin/init
%usr: 该进程在用户态的CPU使用率。
%system: 该进程在内核态(系统级)的CPU使用率。
%CPU: 该进程的总CPU使用率,如果在SMP环境下,该值将除以CPU的数量,以表示每CPU的数据。
CPU: 该进程所依附的CPU编号(0表示第一个CPU)。
2)监控pid为1(init)的进程的设备IO资源负载情况,其中每隔2秒刷新并输出一次,3次后程序退出
pidstat -p 1 2 3 -d
07:24:49 AM PID kB_rd/s kB_wr/s kB_ccwr/s Command
07:24:51 AM 1 0.00 0.00 0.00 init
07:24:53 AM 1 0.00 0.00 0.00 init
07:24:55 AM 1 0.00 0.00 0.00 init
Average: 1 0.00 0.00 0.00 init
kB_rd/s: 该进程每秒的字节读取数量(KB)。
kB_wr/s: 该进程每秒的字节写出数量(KB)。
kB_ccwr/s: 该进程每秒取消磁盘写入的数量(KB)。
3)监控pid为1(init)的进程的内存使用情况,其中每隔2秒刷新并输出一次,3次后程序退出
pidstat -p 1 2 3 -r
07:29:56 AM PID minflt/s majflt/s VSZ RSS %MEM Command
07:29:58 AM 1 0.00 0.00 2828 1368 0.13 init
07:30:00 AM 1 0.00 0.00 2828 1368 0.13 init
07:30:02 AM 1 0.00 0.00 2828 1368 0.13 init
Average: 1 0.00 0.00 2828 1368 0.13 init
minflt/s: 每秒次缺页错误次数(minor page faults),次缺页错误次数意即虚拟内存地址映射成物理内存地址产生的page fault次数
majflt/s: 每秒主缺页错误次数(major page faults),当虚拟内存地址映射成物理内存地址时,相应的page在swap中,这样的page fault为major page fault,一般在内存使用紧张时产生
VSZ: 该进程使用的虚拟内存(以kB为单位)
RSS: 该进程使用的物理内存(以kB为单位)
%MEM: 该进程使用内存的百分比
Command: 拉起进程对应的命令
4)监控pid为1(init)的进程任务切换情况,其中每隔2秒刷新并输出一次,3次后程序退出。
pidstat -p 1 2 3 -w
07:32:15 AM PID cswch/s nvcswch/s Command
07:32:17 AM 1 0.00 0.00 init
07:32:19 AM 1 0.00 0.00 init
07:32:21 AM 1 0.00 0.00 init
Average: 1 0.00 0.00 init
cswch/s: 每秒任务主动(自愿的)切换上下文的次数。主动切换是指当某一任务处于阻塞等待时,将主动让出自己的CPU资源。
nvcswch/s: 每秒任务被动(不自愿的)切换上下文的次数。被动切换是指CPU分配给某一任务的时间片已经用完,因此将强迫该进程让出CPU的执行权。
5)监控pid为1(init)的进程及其内部线程的内存(r选项)使用情况,其中每隔2秒刷新并输出一次,3次后程序退出。需要说明的是,如果-t选项后面不加任何其他选项,缺省监控的为CPU资源
pidstat -p 1 2 3 -tr
Linux 2.6.32-71.el6.i686 (Stephen-PC) 11/16/2011 _i686_ (1 CPU)
07:37:04 AM TGID TID minflt/s majflt/s VSZ RSS %MEM Command
07:37:06 AM 1 - 0.00 0.00 2828 1368 0.13 init
07:37:06 AM - 1 0.00 0.00 2828 1368 0.13 |__init
07:37:06 AM TGID TID minflt/s majflt/s VSZ RSS %MEM Command
07:37:08 AM 1 - 0.00 0.00 2828 1368 0.13 init
07:37:08 AM - 1 0.00 0.00 2828 1368 0.13 |__init
07:37:08 AM TGID TID minflt/s majflt/s VSZ RSS %MEM Command
07:37:10 AM 1 - 0.00 0.00 2828 1368 0.13 init
07:37:10 AM - 1 0.00 0.00 2828 1368 0.13 |__init
Average: TGID TID minflt/s majflt/s VSZ RSS %MEM Command
Average: 1 - 0.00 0.00 2828 1368 0.13 init
Average: - 1 0.00 0.00 2828 1368 0.13 |__init
TGID: 线程组ID。
TID: 线程ID。
以上监控不同资源的选项可以同时存在,这样就将在一次输出中输出多种资源的使用情况,如:pidstat -p 1 -dr。
12、iostat
主要用于监控系统设备的IO负载情况,iostat首次运行时显示自系统启动开始的各项统计信息,之后运行iostat将显示自上次运行该命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所需的统计信息。iostat的数据的主要来源是/proc/partitions。
-c 只显示CPU行
-d 显示磁盘行
-k 以千字节为单位显示磁盘输出
-m 以M为单位显示磁盘输出
-t 在输出中包括时间戳
-x 在输出中包括扩展的磁盘指标
1)仅显示设备的IO负载,其中每隔1秒刷新并输出结果一次,输出3次后iostat退出
iostat -d 1 3
Linux 2.6.32-71.el6.i686 (Stephen-PC) 11/16/2011 _i686_ (1 CPU)
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 5.35 258.39 26.19 538210 54560
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 0.00 0.00 0.00 0 0
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 0.00 0.00 0.00 0 0
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 0.00 0.00 0.00 0 0
Blk_read/s 每秒块(扇区)读取的数量。
Blk_wrtn/s 每秒块(扇区)写入的数量。
Blk_read 总共块(扇区)读取的数量。
Blk_wrtn 总共块(扇区)写入的数量。
2)显示和io相关的扩展数据
iostat -dx 1 3
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sda 5.27 1.31 2.82 1.14 189.49 19.50 52.75 0.53 133.04 10.74 4.26
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
rrqm/s 队列中每秒钟合并的读请求数量
wrqm/s 队列中每秒钟合并的写请求数量
r/s 每秒钟完成的读请求数量
w/s 每秒钟完成的写请求数量
rsec/s 每秒钟读取的扇区数量
wsec/s 每秒钟写入的扇区数量
avgrq-sz 平均请求扇区的大小
avgqu-sz 平均请求队列的长度,队列长度越短越好。
await 平均每次请求的等待时间,这个时间包括了队列时间和服务时间,也就是说,一般情况下,await大于svctm,它们的差值越小,则说明队列时间越短,反之差值越大,队列时间越长说明系统出了问题。
util 设备的利用率。在统计时间内所有处理IO时间,除以总共统计时间。例如,如果统计间隔1秒,该设备有0.8秒在处理IO,而0.2秒闲置,那么该设备的%util = 0.8/1 = 80%,所以该参数暗示了设备的繁忙程度。一般地,如果该参数是100%表示设备已经接近满负荷运行了(当然如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈)。
13、iotop
用来监视磁盘I/O使用状况的top类工具。iotop具有与top相似的UI,其中包括PID、用户、I/O、进程等相关信息。
参数:
–version 查看版本信息
-h, –help 查看帮助信息
-o, –only 只显示在划硬盘的程序
-b, –batch 批量处理 用来记录日志
-n NUM 设定循环几次
-d SEC, –delay=SEC 设定显示时间间隔
iotop常用快捷键
左右箭头 --> 改变排序方式,默认是按IO排序
r --> 改变排序顺序
o --> 只显示有IO输出的进程
p --> 进程/线程的显示方式的切换
a --> 显示累积使用量
q --> 退出
1)直接运行iotop
Total DISK READ: 6.01 M/s | Total DISK WRITE: 3.85 K/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
20074 be/4 hadoop 6.01 M/s 0.00 B/s 0.00 % 4.54 % java -Dproc_datanode -Xmx8192m -server org.apache.hadoop.hdfs.server.datanode.DataNode
6371 be/4 hadoop 0.00 B/s 3.25 M/s 0.00 % 0.00 % java -Dproc_datanode -Xmx8192m -server org.apache.hadoop.hdfs.server.datanode.DataNode
8497 be/4 hadoop 0.00 B/s 3.67 M/s 0.00 % 0.00 % java -Dproc_datanode -Xmx8192m -server org.apache.hadoop.hdfs.server.datanode.DataNode
1 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % init
2 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kthreadd]
通过输出结果,我们可以清楚地知晓是什么程序在读写磁盘,速度以及命令行,pid 等信息。
14、watch
实时监测命令,watch是一个非常实用的命令,可以帮你实时监测一个命令的运行结果,省得一遍又一遍的手动运行。该命令最为常用的两个选项是-d和-n,其中-n表示间隔多少秒执行次"command",-d表示高亮发生变化的位置。
用法举例:
1)每隔一秒执行一次who命令,以监视服务器当前用户登录的状况
watch -d -n 1 'who'
2)watch可以同时运行多个命令,命令间用分号分隔。以下命令监控磁盘的使用状况,以及当前目录下文件的变化状况,包括文件的新增、删除和文件修改日期的更新等。
watch -d -n 1 'df -h; ls -l'
15、sar
yum安装:yum install sysstat (sar是后台进程sadc的前端显示工具,安装名为“sysstat”的包后,sadc就会自动从内核收集报告并保存)
sar(System Activity Reporter系统活动情况报告)是目前Linux上最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告,包括:文件的读写情况、系统调用的使用情况、磁盘I/O、CPU效率、内存使用状况、进程活动及IPC有关的活动等。
常用格式:
sar [options] [-A] [-o file] t [n]
其中:
t为采样间隔,n为采样次数,默认值是1;
-o file表示将命令结果以二进制格式存放在文件中,file 是文件名。
options 为命令行选项,sar命令常用选项如下:
-A:所有报告的总和
-u:输出CPU使用情况的统计信息
-v:输出inode、文件和其他内核表的统计信息
-d:输出每一个块设备的活动信息
-r:输出内存和交换空间的统计信息
-b:显示I/O和传送速率的统计信息
-a:文件读写情况
-c:输出进程统计信息,每秒创建的进程数
-R:输出内存页面的统计信息
-y:终端设备活动情况
-w:输出系统交换活动信息
1)CPU资源监控
每10秒采样一次,连续采样3次,观察CPU的使用情况,并将采样结果以二进制形式存入当前目录下的文件test中,需键入如下命令:
sar -u -o test 10 3
17:06:16 CPU %user %nice %system %iowait %steal %idle
17:06:26 all 0.00 0.00 0.20 0.00 0.00 99.80
17:06:36 all 0.00 0.00 0.20 0.00 0.00 99.80
17:06:46 all 0.00 0.00 0.10 0.00 0.00 99.90
Average: all 0.00 0.00 0.17 0.00 0.00 99.83
CPU:all 表示统计信息为所有 CPU 的平均值。
%user:显示在用户级别(application)运行使用 CPU 总时间的百分比。
%nice:显示在用户级别,用于nice操作,所占用 CPU 总时间的百分比。
%system:在核心级别(kernel)运行所使用 CPU 总时间的百分比。
%iowait:显示用于等待I/O操作占用 CPU 总时间的百分比。
%steal:管理程序(hypervisor)为另一个虚拟进程提供服务而等待虚拟 CPU 的百分比。
%idle:显示 CPU 空闲时间占用 CPU 总时间的百分比。
a、若%iowait的值过高,表示硬盘存在I/O瓶颈
b、若%idle的值高但系统响应慢时,有可能是 CPU 等待分配内存,此时应加大内存容量
c、若%idle的值持续低于1,则系统的 CPU 处理能力相对较低,表明系统中最需要解决的资源是 CPU 。
d、如果要查看二进制文件test中的内容,需键入如下sar命令:sar -u -f test
2)inode、文件和其他内核表监控
每10秒采样一次,连续采样3次,观察核心表的状态,需键入如下命令:
sar -v 10 3
17:10:49 dentunusd file-nr inode-nr pty-nr
17:10:59 6301 5664 12037 4
17:11:09 6301 5664 12037 4
17:11:19 6301 5664 12037 4
Average: 6301 5664 12037 4
dentunusd:目录高速缓存中未被使用的条目数量
file-nr:文件句柄(file handle)的使用数量
inode-nr:索引节点句柄(inode handle)的使用数量
pty-nr:使用的pty数量
3) 内存和交换空间监控
每10秒采样一次,连续采样3次,监控内存分页:
sar -r 10 3
kbmemfree:这个值和free命令中的free值基本一致,所以它不包括buffer和cache的空间.
kbmemused:这个值和free命令中的used值基本一致,所以它包括buffer和cache的空间.
%memused:这个值是kbmemused和内存总量(不包括swap)的一个百分比.
kbbuffers和kbcached:这两个值就是free命令中的buffer和cache.
kbcommit:保证当前系统所需要的内存,即为了确保不溢出而需要的内存(RAM+swap).
%commit:这个值是kbcommit与内存总量(包括swap)的一个百分比.
4)内存分页监控
每10秒采样一次,连续采样3次,监控内存分页:
sar -B 10 3
pgpgin/s:表示每秒从磁盘或SWAP置换到内存的字节数(KB)
pgpgout/s:表示每秒从内存置换到磁盘或SWAP的字节数(KB)
fault/s:每秒钟系统产生的缺页数,即主缺页与次缺页之和(major + minor)
majflt/s:每秒钟产生的主缺页数.
pgfree/s:每秒被放入空闲队列中的页个数
pgscank/s:每秒被kswapd扫描的页个数
pgscand/s:每秒直接被扫描的页个数
pgsteal/s:每秒钟从cache中被清除来满足内存需要的页个数
%vmeff:每秒清除的页(pgsteal)占总扫描页(pgscank+pgscand)的百分比
5)I/O和传送速率监控
每10秒采样一次,连续采样3次,报告缓冲区的使用情况,需键入如下命令:
sar -b 10 3
18:51:05 tps rtps wtps bread/s bwrtn/s
18:51:15 0.00 0.00 0.00 0.00 0.00
18:51:25 1.92 0.00 1.92 0.00 22.65
18:51:35 0.00 0.00 0.00 0.00 0.00
Average: 0.64 0.00 0.64 0.00 7.59
tps:每秒钟物理设备的 I/O 传输总量
rtps:每秒钟从物理设备读入的数据总量
wtps:每秒钟向物理设备写入的数据总量
bread/s:每秒钟从物理设备读入的数据量,单位为 块/s
bwrtn/s:每秒钟向物理设备写入的数据量,单位为 块/s
6)进程队列长度和平均负载状态监控
每10秒采样一次,连续采样3次,监控进程队列长度和平均负载状态:
sar -q 10 3
19:25:50 runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15
19:26:00 0 259 0.00 0.00 0.00
19:26:10 0 259 0.00 0.00 0.00
19:26:20 0 259 0.00 0.00 0.00
Average: 0 259 0.00 0.00 0.00
runq-sz:运行队列的长度(等待运行的进程数)
plist-sz:进程列表中进程(processes)和线程(threads)的数量
ldavg-1:最后1分钟的系统平均负载(System load average)
ldavg-5:过去5分钟的系统平均负载
ldavg-15:过去15分钟的系统平均负载
7)系统交换活动信息监控
每10秒采样一次,连续采样3次,监控系统交换活动信息:
sar - W 10 3
19:39:50 pswpin/s pswpout/s
19:40:00 0.00 0.00
19:40:10 0.00 0.00
19:40:20 0.00 0.00
Average: 0.00 0.00
pswpin/s:每秒系统换入的交换页面(swap page)数量
pswpout/s:每秒系统换出的交换页面(swap page)数量
8)设备使用情况监控
每10秒采样一次,连续采样3次,报告设备使用情况,需键入如下命令:
sar -d 10 3 -p
17:45:54 DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
17:46:04 scd0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
17:46:04 sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
17:46:04 vg_livedvd-lv_root 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
17:46:04 vg_livedvd-lv_swap 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
参数-p可以打印出sda,hdc等磁盘设备名称,如果不用参数-p,设备节点则有可能是dev8-0,dev22-0
tps:每秒从物理磁盘I/O的次数.多个逻辑请求会被合并为一个I/O磁盘请求,一次传输的大小是不确定的.
rd_sec/s:每秒读扇区的次数.
wr_sec/s:每秒写扇区的次数.
avgrq-sz:平均每次设备I/O操作的数据大小(扇区).
avgqu-sz:磁盘请求队列的平均长度,avgqu-sz的值较低时,设备的利用率较高
await:从请求磁盘操作到系统完成处理,每次请求的平均消耗时间,包括请求队列等待时间,单位是毫秒(1秒=1000毫秒).
svctm:系统处理每次请求的平均时间,不包括在请求队列中消耗的时间.
%util:I/O请求占CPU的百分比,比率越大,说明越饱和,当%util的值接近100%时,表示设备带宽已经占满。
9)要判断系统瓶颈问题,有时需几个 sar 命令选项结合起来
怀疑CPU存在瓶颈,可用 sar -u 和 sar -q 等来查看
怀疑内存存在瓶颈,可用 sar -B、sar -r 和 sar -W 等来查看
怀疑I/O存在瓶颈,可用 sar -b、sar -u 和 sar -d 等来查看
10)分析网卡流量
sar -n { DEV | EDEV | NFS | NFSD | SOCK | ALL }
sar提供六种不同的语法选项来显示网络信息。-n选项使用6个不同的开关:DEV | EDEV | NFS | NFSD | SOCK | ALL 。DEV显示网络接口信息,EDEV显示关于网络错误的统计数据,NFS统计活动的NFS客户端的信息,NFSD统计NFS服务器的信息,SOCK显示套接字信息,ALL显示所有5个开关。它们可以单独或者一起使用。
a)sar -n DEV 2 10
Linux 2.6.18-53.el5PAE (localhost.localdomain) 03/29/2009
01:39:40 AM IFACE rxpck/s txpck/s rxbyt/s txbyt/s rxcmp/s txcmp/s rxmcst/s
01:39:42 AM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
01:39:42 AM eth1 131.34 104.98 119704.48 36110.45 0.00 0.00 0.00
01:39:42 AM sit0 0.00 0.00 0.00 0.00 0.00 0.00 0.00
01:39:42 AM IFACE rxpck/s txpck/s rxbyt/s txbyt/s rxcmp/s txcmp/s rxmcst/s
01:39:44 AM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
01:39:44 AM eth1 168.00 165.50 114496.50 83938.50 0.00 0.00 0.00
01:39:44 AM sit0 0.00 0.00 0.00 0.00 0.00 0.00 0.00
IFACE:LAN接口
rxpck/s:每秒钟接收的数据包
txpck/s:每秒钟发送的数据包
rxbyt/s:每秒钟接收的字节数
txbyt/s:每秒钟发送的字节数
rxcmp/s:每秒钟接收的压缩数据包
txcmp/s:每秒钟发送的压缩数据包
rxmcst/s:每秒钟接收的多播数据包
b)sar -n EDEV 2 10
Linux 2.6.18-53.el5PAE (localhost.localdomain) 03/29/2009
01:42:18 AM IFACE rxerr/s txerr/s coll/s rxdrop/s txdrop/s txcarr/s rxfram/s rxfifo/s txfifo/s
01:42:20 AM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
01:42:20 AM eth1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
01:42:20 AM sit0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
IFACE:LAN接口
rxerr/s:每秒钟接收的坏数据包
txerr/s:每秒钟发送的坏数据包
coll/s:每秒冲突数
rxdrop/s:因为缓冲充满,每秒钟丢弃的已接收数据包数
txdrop/s:因为缓冲充满,每秒钟丢弃的已发送数据包数
txcarr/s:发送数据包时,每秒载波错误数
rxfram/s:每秒接收数据包的帧对齐错误数
rxfifo/s:接收的数据包每秒FIFO过速的错误数
txfifo/s:发送的数据包每秒FIFO过速的错误数
c)sar -n SOCK 2 10
Linux 2.6.18-53.el5PAE (localhost.localdomain) 03/29/2009
01:44:32 AM totsck tcpsck udpsck rawsck ip-frag
01:44:34 AM 243 9 8 0 0
01:44:36 AM 242 9 7 0 0
01:44:38 AM 238 9 7 0 0
01:44:40 AM 238 9 7 0 0
totsck:使用的套接字总数量
tcpsck:使用的TCP套接字数量
udpsck:使用的UDP套接字数量
rawsck:使用的raw套接字数量
ip-frag:使用的IP段数量