要想恢复误删除的文件,必须清楚数据在磁盘上究竟是如何存储的,以及如何定位并恢复数据。本文从数据恢复的角度,着重介绍了 ext2 文件系统中使用的一些基本概念和重要数据结构,并通过几个实例介绍了如何手工恢复已经删除的文件。最后针对 ext2 现有实现存在的大文件无法正常恢复的问题,通过修改内核中的实现,给出了一种解决方案。对于很多 Linux 的用户来说,可能有一个问题一直都非常头疼:对于那些不小心删除的数据来说,怎样才能恢复出来呢?大家知道,在 Windows 系统上,回收站中保存了最近使用资源管理器时删除的文件。即便是对于那些在命令行中删除的文件来说,也有很多工具(例如recover4all,FinalData Recovery)可以把这些已经删除的文件恢复出来。在Linux 下这一切是否可能呢?
实际上,为了方便用户的使用,现在 Linux 上流行的桌面管理工具(例如gnome和KDE)中都已经集成了回收站的功能。其基本思想是在桌面管理工具中捕获对文件的删除操作,将要删除的文件移动到用户根目录下的 .Trash 文件夹中,但却并不真正删除该文件。当然,像在 Windows 上一样,如果用户在删除文件的同时,按下了 Shift 键并确认删除该文件,那么这个文件就不会被移动到 .Trash 文件夹中,也就无从恢复了。此时,习惯了使用 Windows 上各种恢复工具的人就会顿足捶胸,抱怨 Linux 上工具的缺乏了。但是请稍等一下,难道按照这种方式删除的文件就真的无从恢复了么?或者换一个角度来看,使用 rm 命令删除的文件是否还有办法能够恢复出来呢?
背景知识
在开始真正进行实践之前,让我们首先来了解一下在 Linux 系统中,文件是如何进行存储和定位的,这对于理解如何恢复文件来说非常重要。我们知道,数据最终以数据块的形式保存在磁盘上,而操作系统是通过文件系统来管理这些数据的。ext2/ext3 是 Linux 上应用最为广泛的文件系统,本文将以 ext2 文件系统为例展开介绍。
我们知道,在操作系统中,文件系统是采用一种层次化的形式表示的,通常可以表示成一棵倒置的树。所有的文件和子目录都是通过查找其父目录项来定位的,目录项中通过匹配文件名可以找到对应的索引节点号(inode),通过查找索引节点表(inode table)就可以找到文件在磁盘上的位置,整个过程如图1所示。
图 1. 文件数据定位过程

对于 ext2 类型的文件系统来说,目录项是使用一个名为 ext2_dir_entry_2 的结构来表示的,该结构定义如下所示:
清单 1. ext2_dir_entry_2 结构定义
struct ext2_dir_entry_2 { __le32 inode; /* 索引节点号 */ __le16 rec_len; /* 目录项的长度 */ __u8 name_len; /* 文件名长度 */ __u8 file_type; /* 文件类型 */ char name[EXT2_NAME_LEN]; /* 文件名 */ };在 Unix/Linux 系统中,目录只是一种特殊的文件。目录和文件是通过 file_type 域来区分的,该值为 1 则表示是普通文件,该值为 2 则表示是目录。
对于每个 ext2 分区来说,其在物理磁盘上的布局如图 2 所示:
图 2. ext2 分区的布局
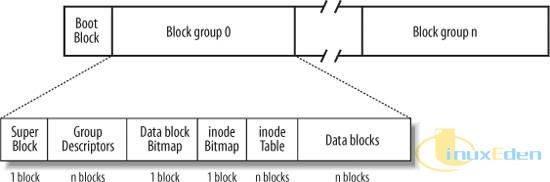
从图 2 中可以看到,对于 ext2 文件系统来说,磁盘被划分成一个个大小相同的数据块,每个块的大小可以是1024、2048 或 4096 个字节。其中,第一个块称为引导块,一般保留做引导扇区使用,因此 ext2 文件系统一般都是从第二个块开始的。剩余的块被划分为一个个的块组,ext2 文件系统会试图尽量将相同文件的数据块都保存在同一个块组中,并且尽量保证文件在磁盘上的连续性,从而提高文件读写时的性能。
至于一个分区中到底有多少个块组,这取决于两个因素:
- 分区大小。
- 块大小。
最终的计算公式如下:
分区中的块组数=分区大小/(块大小*8)
这是由于在每个块组中使用了一个数据块位图来标识数据块是否空闲,因此每个块组中最多可以有(块大小*8)个块;该值除上分区大小就是分区中总的块组数。
每个块组都包含以下内容:
- 超级块。存放文件系统超级块的一个拷贝。
- 组描述符。该块组的组描述符。
- 数据块位图。标识相应的数据块是否空闲。
- 索引节点位图。标识相应的索引节点是否空闲。
- 索引节点表。存放所有索引节点的数据。
- 数据块。该块组中用来保存实际数据的数据块。
在每个块组中都保存了超级块的一个拷贝,默认情况下,只有第一个块组中的超级块结构才会被系统内核使用;其他块组中的超级块可以在 e2fsck 之类的程序对磁盘上的文件系统进行一致性检查使用。在 ext2 文件系统中,超级块的结构会通过一个名为 ext2_super_block 的结构进行引用。该结构的一些重要域如下所示:
清单 2. ext2_super_block 结构定义
struct ext2_super_block { __le32 s_inodes_count; /* 索引节点总数 */ __le32 s_blocks_count; /* 块数,即文件系统以块为单位的大小 */ __le32 s_r_blocks_count; /* 系统预留的块数 */ __le32 s_free_blocks_count; /* 空闲块数 */ __le32 s_free_inodes_count; /* 空闲索引节点数 */ __le32 s_first_data_block; /* 第一个可用数据块的块号 */ __le32 s_log_block_size; /* 块大小 */ __le32 s_blocks_per_group; /* 每个块组中的块数 */ __le32 s_inodes_per_group; /* 每个块组中的索引节点个数 */ ... }每个块组都有自己的组描述符,在 ext2 文件系统中是通过一个名为 ext2_group_desc的结构进行引用的。该结构的定义如下:
清单 3. ext2_group_desc 结构定义
/* * Structure of a blocks group descriptor */ struct ext2_group_desc { __le32 bg_block_bitmap; /* 数据块位图的块号 */ __le32 bg_inode_bitmap; /* 索引节点位图的块号 */ __le32 bg_inode_table; /* 第一个索引节点表的块号 */ __le16 bg_free_blocks_count; /* 该组中空闲块数 */ __le16 bg_free_inodes_count; /* 该组中空闲索引节点数 */ __le16 bg_used_dirs_count; /* 该组中的目录项 */ __le16 bg_pad; __le32 bg_reserved[3]; };数据块位图和索引节点位图分别占用一个块的大小,其每一位描述了对应数据块或索引节点是否空闲,如果该位为0,则表示空闲;如果该位为1,则表示已经使用。
索引节点表存放在一系列连续的数据块中,每个数据块中可以包括若干个索引节点。每个索引节点在 ext2 文件系统中都通过一个名为 ext2_inode 的结构进行引用,该结构大小固定为 128 个字节,其中一些重要的域如下所示:
清单 4. ext2_inode 结构定义
/* * Structure of an inode on the disk */ struct ext2_inode { __le16 i_mode; /* 文件模式 */ __le16 i_uid; /* 文件所有者的 uid */ __le32 i_size; /* 以字节为单位的文件长度 */ __le32 i_atime; /* 最后一次访问该文件的时间 */ __le32 i_ctime; /* 索引节点最后改变的时间 */ __le32 i_mtime; /* 文件内容最后改变的时间 */ __le32 i_dtime; /* 文件删除的时间 */ __le16 i_gid; /* 文件所有者的 gid */ __le16 i_links_count; /* 硬链接数 */ __le32 i_blocks; /* 文件的数据块数 */ ... __le32 i_block[EXT2_N_BLOCKS];/* 指向数据块的指针 */ ... };第一个索引节点所在的块号保存在该块组描述符的 bg_inode_table 域中。请注意 i_block 域,其中就包含了保存数据的数据块的位置。有关如何对数据块进行寻址,请参看后文“数据块寻址方式”一节的内容。
需要知道的是,在普通的删除文件操作中,操作系统并不会逐一清空保存该文件的数据块的内容,而只会释放该文件所占用的索引节点和数据块,方法是将索引节点位图和数据块位图中的相应标识位设置为空闲状态。因此,如果我们可以找到文件对应的索引节点,由此查到相应的数据块,就可能从磁盘上将已经删除的文件恢复出来。
幸运的是,这一切都是可能的!本文将通过几个实验来了解一下如何从磁盘上恢复删除的文件。

数据块寻址方式
回想一下,ext2_inode 结构的 i_block 域是一个大小为 EXT2_N_BLOCKS 的数组,其中保存的就是真正存放文件数据的数据块的位置。通常来说,EXT2_N_BLOCKS 大小为 15。在 ext2 文件系统,采用了直接寻址和间接寻址两种方式来对数据块进行寻址,原理如图3 所示:
图 3. 数据块寻址方式
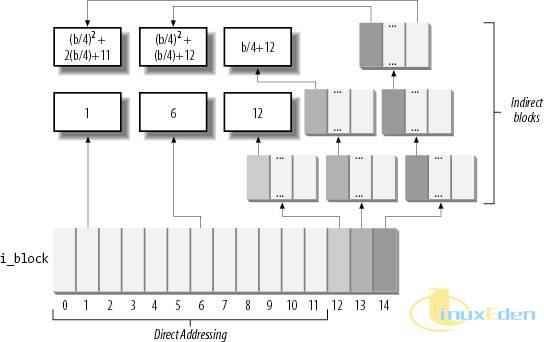
- 对于 i_block 的前 12 个元素(i_block[0]到i_block[11])来说,其中存放的就是实际的数据块号,即对应于文件的 0 到 11 块。这种方式称为直接寻址。
- 对于第13个元素(i_block[12])来说,其中存放的是另外一个数据块的逻辑块号;这个块中并不存放真正的数据,而是存放真正保存数据的数据块的块号。即 i_block[12] 指向一个二级数组,其每个元素都是对应数据块的逻辑块号。由于每个块号需要使用 4 个字节表示,因此这种寻址方式可以访问的对应文件的块号范围为 12 到 (块大小/4)+11。这种寻址方式称为间接寻址。
- 对于第14个元素(i_block[13])来说,其中存放也是另外一个数据块的逻辑块号。与间接寻址方式不同的是,i_block[13] 所指向的是一个数据块的逻辑块号的二级数组,而这个二级数组的每个元素又都指向一个三级数组,三级数组的每个元素都是对应数据块的逻辑块号。这种寻址方式称为二次间接寻址,对应文件块号的寻址范围为 (块大小/4)+12 到 (块大小/4)2+(块大小/4)+11。
- 对于第15个元素(i_block[14])来说,则利用了三级间接索引,其第四级数组中存放的才是逻辑块号对应的文件块号,其寻址范围从 (块大小/4)2+(块大小/4)+12 到 (块大小/4)3+ (块大小/4)2+(块大小/4)+11。
ext2 文件系统可以支持1024、2048和4096字节三种大小的块,对应的寻址能力如下表所示:
表 1. 各种数据块对应的文件寻址范围
块大小 直接寻址 间接寻址 二次间接寻址 三次间接寻址 1024 12KB 268KB 64.26MB 16.06GB 2048 24KB 1.02MB 513.02MB 265.5GB 4096 48KB 4.04MB 4GB ~ 4TB 掌握上面介绍的知识之后,我们就可以开始恢复文件的实验了。
准备文件系统
为了防止破坏已有系统,本文将采用一个新的分区进行恢复删除文件的实验。
首先让我们准备好一个新的分区,并在上面创建 ext2 格式的文件系统。下面的命令可以帮助创建一个 20GB 的分区:
清单 5. 新建磁盘分区
在笔者的机器上,这个分区是 /dev/sdb6。然后创建文件系统:
清单 6. 在新分区上创建 ext2 文件系统
并将其挂载到系统上来:
清单 7. 挂载创建的 ext2 文件系统
在真正使用这个文件系统之前,让我们首先使用系统提供的一个命令 dumpe2fs 来熟悉一下这个文件系统的一些具体参数:
清单 8. 使用 dumpe2fs 熟悉这个文件系统的参数
Last mounted on: Filesystem UUID: d8b10aa9-c065-4aa5-ab6f-96a9bcda52ce Filesystem magic number: 0xEF53 Filesystem revision #: 1 (dynamic) Filesystem features: ext_attr resize_inode dir_index filetype sparse_super large_file Default mount options: (none) Filesystem state: not clean Errors behavior: Continue Filesystem OS type: Linux Inode count: 2443200 Block count: 4885760 Reserved block count: 244288 Free blocks: 4797829 Free inodes: 2443189 First block: 0 Block size: 4096 Fragment size: 4096 Reserved GDT blocks: 1022 Blocks per group: 32768 Fragments per group: 32768 Inodes per group: 16288 Inode blocks per group: 509 Filesystem created: Mon Oct 29 20:04:16 2007 Last mount time: Mon Oct 29 20:06:52 2007 Last write time: Mon Oct 29 20:08:31 2007 Mount count: 1 Maximum mount count: 39 Last checked: Mon Oct 29 20:04:16 2007 Check interval: 15552000 (6 months) Next check after: Sat Apr 26 20:04:16 2008 Reserved blocks uid: 0 (user root) Reserved blocks gid: 0 (group root) First inode: 11 Inode size: 128 Default directory hash: tea Directory Hash Seed: d1432419-2def-4762-954a-1a26fef9d5e8 Group 0: (Blocks 0-32767) Primary superblock at 0, Group descriptors at 1-2 Reserved GDT blocks at 3-1024 Block bitmap at 1025 (+1025), Inode bitmap at 1026 (+1026) Inode table at 1027-1535 (+1027) 31224 free blocks, 16276 free inodes, 2 directories Free blocks: 1543-22535, 22537-32767 Free inodes: 12, 14-16288 ... Group 149: (Blocks 4882432-4885759) Block bitmap at 4882432 (+0), Inode bitmap at 4882433 (+1) Inode table at 4882434-4882942 (+2) 2817 free blocks, 16288 free inodes, 0 directories Free blocks: 4882943-4885759 Free inodes: 2426913-2443200 应用前面介绍的一些知识,我们可以看到,这个文件系统中,块大小(Block size)为4096字节,因此每个块组中的块数应该是4096*8=32768个(Blocks per group),每个块组的大小是 128MB,整个分区被划分成20GB/(4KB*32768)=160个。但是为什么我们只看到 150 个块组(0到149)呢?实际上,在 fdisk 中,我们虽然输入要创建的分区大小为 20GB,但实际上,真正分配的空间并不是严格的20GB,而是只有大约 20*109 个字节,准确地说,应该是 (4885760 * 4096) / (1024*1024*1024) = 18.64GB。这是由于不同程序的计数单位的不同造成的,在使用存储设备时经常遇到这种问题。因此,这个分区被划分成 150 个块组,前 149 个块组分别包含 32768 个块(即 128B),最后一个块组只包含 3328 个块。
另外,我们还可以看出,每个索引节点的大小是 128 字节,每个块组中包含 16288 个索引节点,在磁盘上使用 509 个块来存储(16288*128/4096),在第一个块组中,索引节点表保存在 1027 到 1535 块上。
数据块和索引节点是否空闲,是分别使用块位图和索引节点位图来标识的,在第一个块组中,块位图和索引节点位图分别保存在 1025 和 1026 块上。
dumpe2fs 的输出结果中还包含了其他一些信息,我们暂时先不用详细关心这些信息。
准备测试文件
现在请将附件中的 createfile.sh 文件下载到本地,并将其保存到 /tmp/test 目录中,这个脚本可以帮助我们创建一个特殊的文件,其中每行包含 1KB 字符,最开始的14个字符表示行号。之所以采用这种文件格式,是为了方便地确认所恢复出来的文件与原始文件之间的区别。这个脚本的用法如下:
清单 9. createfile.sh 脚本的用法
第 1 个参数表示所生成的文件大小,单位是 KB;第 2 个参数表示所生成文件的名字。
下面让我们创建几个测试文件:
清单 10. 准备测试文件
上面的命令新创建了大小为 35 KB 和 9000KB 的两个文件,并为它们各自保存了一个备份,备份文件的目的是为了方便使用 diff 之类的工具验证最终恢复出来的文件与原始文件完全一致。
ls 命令的 –i 选项可以查看有关保存文件使用的索引节点的信息:
清单11. 查看文件的索引节点号
第一列中的数字就是索引节点号。从上面的输出结果我们可以看出,索引节点号是按照我们创建文件的顺序而逐渐自增的,我们刚才创建的 35K 大小的文件的索引节点号为 13,10M 大小的文件的索引节点号为 14。debugfs 中提供了很多工具,可以帮助我们了解进一步的信息。现在执行下面的命令:
清单12. 查看索引节点 <13> 的详细信息
输出结果显示的就是索引节点 13 的详细信息,从中我们可以看到诸如文件大小(35840=35K)、权限(0644)等信息,尤其需要注意的是最后 3 行的信息,即该文件被保存到磁盘上的 4096 到 4104 总共 9 个数据块中。
下面再看一下索引节点 14 (即 testfile.10M 文件)的详细信息:
清单13. 查看索引节点 <14> 的详细信息
和索引节点 13 相比,二者之间最重要的区别在于 BLOCKS 的数据,testfile.10M 在磁盘上总共占用了 2564 个数据块,由于需要采用二级间接寻址模式进行访问,所以使用了4个块来存放间接寻址的信息,分别是24588、25613、25614和26639,其中25613块中存放的是二级间接寻址的信息。
恢复删除文件
现在将刚才创建的两个文件删除:
清单14. 删除测试文件
debugfs 的 lsdel 命令可以查看文件系统中删除的索引节点的信息:
清单15. 使用 lsdel 命令搜索已删除的文件
# echo "lsdel" | debugfs /dev/sdb6 debugfs 1.39 (29-May-2006) Inode Owner Mode Size Blocks Time deleted 13 0 100644 35840 9/9 Mon Oct 29 20:32:05 2007 14 0 100644 10485760 2564/2564 Mon Oct 29 20:32:05 2007 2 deleted inodes found.回想一下 inode 结构中有 4 个有关时间的域,分别是 i_atime、i_ctime、i_mtime和i_dtime,分别表示该索引节点的最近访问时间、创建时间、修改时间和删除时间。其中 i_dtime域只有在该索引节点对应的文件或目录被删除时才会被设置。dubugfs 的 lsdel 命令会去扫描磁盘上索引节点表中的所有索引节点,其中 i_dtime 不为空的项就被认为是已经删除的文件所对应的索引节点。
从上面的结果可以看到,刚才删除的两个文件都已经找到了,我们可以通过文件大小区分这两个文件,二者一个大小为35K,另外一个大小为10M,正式我们刚才删除的两个文件。debugfs 的 dump 命令可以帮助恢复文件:
清单16. 使用 dump 命令恢复已删除的文件
执行上面的命令之后,在 /tmp/recover 目录中会生成两个文件,比较这两个文件与我们前面备份的文件的内容就会发现,testfile.35K.dump 与 testfile.35K.orig 的内容完全相同,而 testfile.10M.dump 文件中则仅有前 48K 数据是对的,后面的数据全部为 0 了。这是否意味着删除文件时间已经把数据也同时删除了呢?实际上不是,我们还是有办法把数据全部恢复出来的。记得我们刚才使用 debugfs 的 stat 命令查看索引节点 14 时的 BLOCKS 的数据吗?这些数据记录了整个文件在磁盘上存储的位置,有了这些数据就可以把整个文件恢复出来了,请执行下面的命令:
清单 17. 使用 dd 命令手工恢复已删除的文件
比较一下最终的 testfile.10M.dd 文件和已经备份过的 testfile.10M.orig 文件就会发现,二者完全相同:
清单 18. 使用 diff 命令对恢复文件和原文件进行比较
数据明明存在,但是刚才我们为什么没法使用 debugfs 的 dump 命令将数据恢复出来呢?现在使用 debugfs 的 stat 命令再次查看一下索引节点 14 的信息:
清单 19. 再次查看索引节点 <14> 的详细信息
与前面的结果比较一下不难发现,BLOCKS后面的数据说明总块数为 14,而且也没有整个文件所占据的数据块的详细说明了。既然文件的数据全部都没有发生变化,那么间接寻址所使用的那些索引数据块会不会有问题呢?现在我们来查看一下 24588 这个间接索引块中的内容:
清单 20. 查看间接索引块 24588 中的内容
显然,这个数据块的内容被全部清零了。debugfs 的dump 命令按照原来的寻址方式试图恢复文件时,所访问到的实际上都是第0 个数据块(引导块)中的内容。这个分区不是可引导分区,因此这个数据块中没有写入任何数据,因此 dump 恢复出来的数据只有前48K是正确的,其后所有的数据全部为0。
实际上,ext2 是一种非常优秀的文件系统,在磁盘空间足够的情况下,它总是试图将数据写入到磁盘上的连续数据块中,因此我们可以假定数据是连续存放的,跳过间接索引所占据的 24588、25613、25614和26639,将从24576 开始的其余 2500 个数据块读出,就能将整个文件完整地恢复出来。但是在磁盘空间有限的情况下,这种假设并不成立,如果系统中磁盘碎片较多,或者同一个块组中已经没有足够大的空间来保存整个文件,那么文件势必会被保存到一些不连续的数据块中,此时上面的方法就无法正常工作了。
反之,如果在删除文件的时候能够将间接寻址使用的索引数据块中的信息保存下来,那么不管文件在磁盘上是否连续,就都可以将文件完整地恢复出来了,但是这样就需要修改 ext2 文件系统的实现了。在 ext2 的实现中,与之有关的有两个函数:ext2_free_data 和 ext2_free_branches(都在 fs/ext2/inode.c 中)。2.6 版本内核中这两个函数的实现如下:
清单 21. 内核中 ext2_free_data 和 ext2_free_branches 函数的实现
814 /** 815 * ext2_free_data - free a list of data blocks 816 * @inode: inode we are dealing with 817 * @p: array of block numbers 818 * @q: points immediately past the end of array 819 * 820 * We are freeing all blocks refered from that array (numbers are 821 * stored as little-endian 32-bit) and updating @inode->i_blocks 822 * appropriately. 823 */ 824 static inline void ext2_free_data(struct inode *inode, __le32 *p, __le32 *q) 825 { 826 unsigned long block_to_free = 0, count = 0; 827 unsigned long nr; 828 829 for ( ; p < q ; p++) { 830 nr = le32_to_cpu(*p); 831 if (nr) { 832 *p = 0; 833 /* accumulate blocks to free if they're contiguous */ 834 if (count == 0) 835 goto free_this; 836 else if (block_to_free == nr - count) 837 count++; 838 else { 839 mark_inode_dirty(inode); 840 ext2_free_blocks (inode, block_to_free, count); 841 free_this: 842 block_to_free = nr; 843 count = 1; 844 } 845 } 846 } 847 if (count > 0) { 848 mark_inode_dirty(inode); 849 ext2_free_blocks (inode, block_to_free, count); 850 } 851 } 852 853 /** 854 * ext2_free_branches - free an array of branches 855 * @inode: inode we are dealing with 856 * @p: array of block numbers 857 * @q: pointer immediately past the end of array 858 * @depth: depth of the branches to free 859 * 860 * We are freeing all blocks refered from these branches (numbers are 861 * stored as little-endian 32-bit) and updating @inode->i_blocks 862 * appropriately. 863 */ 864 static void ext2_free_branches(struct inode *inode, __le32 *p, __le32 *q, int depth) 865 { 866 struct buffer_head * bh; 867 unsigned long nr; 868 869 if (depth--) { 870 int addr_per_block = EXT2_ADDR_PER_BLOCK(inode->i_sb); 871 for ( ; p < q ; p++) { 872 nr = le32_to_cpu(*p); 873 if (!nr) 874 continue; 875 *p = 0; 876 bh = sb_bread(inode->i_sb, nr); 877 /* 878 * A read failure? Report error and clear slot 879 * (should be rare). 880 */ 881 if (!bh) { 882 ext2_error(inode->i_sb, "ext2_free_branches", 883 "Read failure, inode=%ld, block=%ld", 884 inode->i_ino, nr); 885 continue; 886 } 887 ext2_free_branches(inode, 888 (__le32*)bh->b_data, 889 (__le32*)bh->b_data + addr_per_block, 890 depth); 891 bforget(bh); 892 ext2_free_blocks(inode, nr, 1); 893 mark_inode_dirty(inode); 894 } 895 } else 896 ext2_free_data(inode, p, q); 897 }注意第 832 和 875 这两行就是用来将对应的索引项置为 0 的。将这两行代码注释掉(对于最新版本的内核 2.6.23 可以下载本文给的补丁)并重新编译 ext2 模块,然后重新加载新编译出来的模块,并重复上面的实验,就会发现利用 debugfs 的 dump 命令又可以完美地恢复出整个文件来了。
显然,这个补丁并不完善,因为这个补丁中的处理只是保留了索引数据块中的索引节点数据,但是还没有考虑数据块位图的处理,如果对应的数据块没有设置为正在使用的状态,并且刚好这些数据块被重用了,其中的索引节点数据就有可能会被覆盖掉了,这样就彻底没有办法再恢复文件了。感兴趣的读者可以沿用这个思路自行开发一个比较完善的补丁。
小结
本文介绍了 ext2 文件系统中的一些基本概念和重要数据结构,并通过几个实例介绍如何恢复已经删除的文件,最后通过修改内核中 ext2 文件系统的实现,解决了大文件无法正常恢复的问题。本系列的下一篇文章中,将介绍如何恢复 ext2 文件系统中的一些特殊文件,以及如何恢复整个目录等方面的问题。
除了普通文件之外,UNIX/Linux 中还存在一些特殊的文件,包括目录、字符设备、块设备、命名管道、socket 以及链接;另外还存在一些带有文件洞的文件,这些特殊文件的恢复是和其存储机制紧密联系在一起的,本文将从这些特殊文件的存储原理和机制入手,逐步介绍这些特殊文件的恢复方法。
在本系列文章的第一部分中,我们介绍了 ext2 文件系统中的一些基本概念和重要数据结构,并通过几个实例学习了如何恢复已经删除的文件,最后通过修改 2.6 版本内核中 ext2 文件系统的实现,解决了大文件无法正常恢复的问题。
通过第一部分的介绍,我们已经知道如何恢复系统中删除的普通文件了,但是系统中还存在一些特殊的文件,比如我们熟悉的符号链接等。回想一下在本系列文章的第一部分中,目录项是使用一个名为 ext2_dir_entry_2 的结构来表示的,该结构定义如下:
清单1. ext2_dir_entry_2 结构定义
struct ext2_dir_entry_2 {
__le32 inode; /* 索引节点号 */
__le16 rec_len; /* 目录项的长度 */
__u8 name_len; /* 文件名长度 */
__u8 file_type; /* 文件类型 */
char name[EXT2_NAME_LEN]; /* 文件名 */
};
|
其中 file_type 域就标识了每个文件的类型。ext2 文件系统中支持的文件类型定义如下表所示:
表 1. ext2 文件系统中支持的文件类型
| file_type | 宏定义 | 说明 |
| 1 | EXT2_FT_REG_FILE | 普通文件 |
| 2 | EXT2_FT_DIR | 目录 |
| 3 | EXT2_FT_CHRDEV | 字符设备 |
| 4 | EXT2_FT_BLKDEV | 块设备 |
| 5 | EXT2_FT_FIFO | 命名管道 |
| 6 | EXT2_FT_SOCK | socket |
| 7 | EXT2_FT_SYMLINK | 符号链接 |
对应的宏定义在 include/linux/ext2_fs.h 文件中。其中,命名管道和 socket 是进程间通信时所使用的两种特殊文件,它们都是在程序运行时创建和使用的;一旦程序退出,就会自动删除。另外,字符设备、块设备、命名管道和 socket 这 4 种类型的文件并不占用数据块,所有的信息全部保存在对应的目录项中。因此,对于数据恢复的目的来说,我们只需要重点关注普通文件、符号链接和目录这三种类型的文件即可。
文件洞
在数据库之类的应用程序中,可能会提前分配一个固定大小的文件,但是并不立即往其中写入数据;数据只有在真正需要的时候才会写入到文件中。如果为这些根本不包含数据的文件立即分配数据块,那就势必会造成磁盘空间的浪费。为了解决这个问题,传统的 Unix 系统中引入了文件洞的概念,文件洞就是普通文件中包含空字符的那部分内容,在磁盘上并不会使用任何数据块来保存这部分数据。也就是说,包含文件洞的普通文件被划分成两部分,一部分是真正包含数据的部分,这部分数据保存在磁盘上的数据块中;另外一部分就是这些文件洞。(在 Windows 操作系统上也存在类似的概念,不过并没有使用文件洞这个概念,而是称之为稀疏文件。)
ext2 文件系统也对文件洞有着很好的支持,其实现是建立在动态数据块分配原则之上的,也就是说,在 ext2 文件系统中,只有当进程需要向文件中写入数据时,才会真正为这个文件分配数据块。
细心的读者可能会发现,在本系列文章第一部分中介绍的 ext2_inode 结构中,有两个与文件大小有关的域:i_size 和 i_blocks,二者分别表示文件的实际大小和存储该文件时真正在磁盘上占用的数据块的个数,其单位分别是字节和块大小(512字节,磁盘每个数据块包含8个块)。通常来说,i_blocks 与块大小的乘积可能会大于或等于 i_size 的值,这是因为文件大小并不都是数据块大小的整数倍,因此分配给该文件的部分数据块可能并没有存满数据。但是在存在文件洞的文件中,i_blocks 与块大小的乘积反而可能会小于 i_size 的值。
下面我们通过几个例子来了解一下包含文件洞的文件在磁盘上究竟是如何存储的,以及这种文件应该如何恢复。
执行下面的命令就可以生成一个带有文件洞的文件:
清单2. 创建带有文件洞的文件
# echo -n "X" | dd of=/tmp/test/hole bs=1024 seek=7 # ls -li /tmp/test/hole 15 -rw-r--r-- 1 root root 7169 Nov 26 11:03 /tmp/test/hole # hexdump /tmp/test/hole 0000000 0000 0000 0000 0000 0000 0000 0000 0000 * 0001c00 0058 0001c01 |
第一个命令生成的 /tmp/test/hole 文件大小是 7169 字节,其前 7168 字节都为空,第 7169 字节的内容是字母 X。正常来讲,7169 字节的文件需要占用两个数据块来存储,第一个数据块全部为空,第二个数据块的第 3073 字节为字母 X,其余字节都为空。显然,第一个数据块就是一个文件洞,在这个数据块真正被写入数据之前,ext2 并不为其实际分配数据块,而是将 i_block 域的对应位(或间接寻址使用的索引数据块中的对应位)设置为0,表示这是一个文件洞。该文件的内容如下图所示:
图1. /tmp/test/hole 文件的存储方法 
file_hole.jpg
现在我们可以使用 debugfs 来查看一下这个文件的详细信息:
清单3. 带有文件洞的文件的 inode 信息
# echo "stat <15>" | debugfs /dev/sdb6 debugfs 1.39 (29-May-2006) debugfs: Inode: 15 Type: regular Mode: 0644 Flags: 0x0 Generation: 4118330634 User: 0 Group: 0 Size: 7169 File ACL: 1544 Directory ACL: 0 Links: 1 Blockcount: 16 Fragment: Address: 0 Number: 0 Size: 0 ctime: 0x474a379c -- Mon Nov 26 11:03:56 2007 atime: 0x474a379c -- Mon Nov 26 11:03:56 2007 mtime: 0x474a379c -- Mon Nov 26 11:03:56 2007 BLOCKS: (1):20480 TOTAL: 1 |
从输出结果中我们可以看出,这个文件的大小是 7169 字节(Size 值,即 ext2_inode 结构中 i_size 域的值),占用块数是 16(Blockcount 值,ext2_inode 结构中 i_blocks 域的值,每个块的大小是 512 字节,而每个数据块占据8个块,因此16个块的大小16×512字节相当于 2 个 512字节×8即4096字节的数据块),但是它的数据在磁盘上只是第一个数据块的内容保存在 20480 这个数据块中。使用下面的方法,我们就可以手工恢复整个文件:
清单4. 使用 dd 命令手工恢复带有文件洞的文件
# dd if=/dev/zero of=/tmp/recover/hole.part1 bs=4096 count=1 # dd if=/dev/sdb6 of=/tmp/recover/hole.part2 bs=4096 count=1 skip=20480 # cat /tmp/recover/hole.part1 /tmp/recover/hole.part2 > /tmp/recover/hole.full # split -d -b 7169 hole.full hole # mv hole00 hole # diff /tmp/test/hole /tmp/recover/hole |
注意第一个 dd 命令就是用来填充这个大小为 4096 字节的文件洞的,这是文件的第一部分;第二个 dd 命令从磁盘上读取出 20480 数据块的内容,其中包含了文件的第二部分。从合并之后的文件中提取出前 7169 字节的数据,就是最终恢复出来的文件。
接下来让我们看一个稍微大一些的带有文件洞的例子,使用下面的命令创建一个大小为57KB 的文件:
清单5. 创建 57K 大小的带有文件洞的文件
# echo -n "Y" | dd of=/tmp/test/hole.57K bs=1024 seek=57 # ls -li /tmp/test/hole.57K 17 -rw-r--r-- 1 root root 58369 Nov 26 12:53 /tmp/test/hole.57K # hexdump /tmp/test/hole.57K 0000000 0000 0000 0000 0000 0000 0000 0000 0000 * 000e400 0059 000e401 |
与上一个文件类似,这个文件的数据也只有一个字符,是 0x000e400(即第58369字节)为字符“Y”。我们真正关心的是这个文件的数据存储情况:
清单6. 使用间接寻址方式的带有文件洞的文件的 inode 信息
# echo "stat <17>" | debugfs /dev/sdb6 debugfs 1.39 (29-May-2006) debugfs: Inode: 17 Type: regular Mode: 0644 Flags: 0x0 Generation: 4261347083 User: 0 Group: 0 Size: 58369 File ACL: 1544 Directory ACL: 0 Links: 1 Blockcount: 24 Fragment: Address: 0 Number: 0 Size: 0 ctime: 0x474a5166 -- Mon Nov 26 12:53:58 2007 atime: 0x474a5187 -- Mon Nov 26 12:54:31 2007 mtime: 0x474a5166 -- Mon Nov 26 12:53:58 2007 BLOCKS: (IND):24576, (14):24577 TOTAL: 2 |
从结果中可以看出,该文件占用了两个数据块来存储数据,一个是间接寻址使用的索引块 24576,一个是真正存放数据的数据块24577。下面让我们来查看一下 24576 这个数据块中的内容:
清单7. 索引数据块中存储的数据
# dd if=/dev/sdb6 of=/tmp/recover/block.24576 bs=4096 count=1 skip=24576 # hexdump block.24576 0000000 0000 0000 0000 0000 6001 0000 0000 0000 0000010 0000 0000 0000 0000 0000 0000 0000 0000 * 0001000 |
正如预期的一样,其中只有第3个 32 位(每个数据块的地址占用32位)表示了真正存储数据的数据块的地址:0x6001,即十进制的 24577。现在恢复这个文件也就便得非常简单了:
清单8. 手工恢复带有文件洞的大文件
# dd if=/dev/zero of=/tmp/recover/hole.57K.part1 bs=4096 count=14
# dd if=/dev/sdb6 of=/tmp/recover/hole.57K.part2 bs=4096 count=1 skip=24577
# cat /tmp/recover/hole.57K.part1 /tmp/recover/hole.57K.part2 /
> /tmp/recover/hole.57K.full
# split -d -b 58369 hole.57K.full hole.57K
# mv hole.57K00 hole.57K
# diff /tmp/test/hole.57K /tmp/recover/hole.57K
|
幸运的是,debugfs 的 dump 命令可以很好地理解文件洞机制,所以可以与普通文件一样完美地恢复整个文件,详细介绍请参看本系列文章的第一部分。
目录
在 ext2 文件系统中,目录是一种特殊的文件,其索引节点的结构与普通文件没什么两样,唯一的区别是目录中的数据都是按照 ext2_dir_entry_2 结构存储在数据块中的(按照 4 字节对齐)。在开始尝试恢复目录之前,首先让我们详细了解一下目录数据块中的数据究竟是如何存储的。现在我们使用 debugfs 来查看一个已经准备好的目录的信息:
清单9. 用来测试的文件系统的信息
# debugfs /dev/sdb6
debugfs 1.39 (29-May-2006)
debugfs: ls -l
2 40755 (2) 0 0 4096 28-Nov-2007 16:57 .
2 40755 (2) 0 0 4096 28-Nov-2007 16:57 ..
11 40700 (2) 0 0 16384 28-Nov-2007 16:52 lost+found
12 100755 (1) 0 0 1406 28-Nov-2007 16:53 createfile.sh
13 100644 (1) 0 0 35840 28-Nov-2007 16:53 testfile.35K
14 100644 (1) 0 0 10485760 28-Nov-2007 16:54 testfile.10M
32577 40755 (2) 0 0 4096 28-Nov-2007 16:56 dir1
15 100644 (1) 0 0 35840 28-Nov-2007 16:56 testfile.35K.orig
16 100644 (1) 0 0 10485760 28-Nov-2007 16:57 testfile.10M.orig
debugfs: ls -l dir1
32577 40755 (2) 0 0 4096 28-Nov-2007 16:56 .
2 40755 (2) 0 0 4096 28-Nov-2007 16:57 ..
32578 100755 (1) 0 0 1406 28-Nov-2007 16:55 createfile.sh
32579 40755 (2) 0 0 4096 28-Nov-2007 16:55 subdir11
48865 40755 (2) 0 0 4096 28-Nov-2007 16:55 subdir12
32580 100644 (1) 0 0 35840 28-Nov-2007 16:56 testfile.35K
32581 100644 (1) 0 0 10485760 28-Nov-2007 16:56 testfile.10M
|
从输出结果中可以看出,每个目录结构中至少要包含两项:当前目录(.)和父目录(..)的信息。在一个文件系统中,会有一些特殊的索引节点是保留的,用户创建的文件无法使用这些索引节点。2 就是这样一个特殊的索引节点,表示根目录。结合上面的输出结果,当前目录(.)和父目录(..)对应的索引节点号都是2,表示这是该分区的根目录。特别地,在使用 mke2fs 命令创建一个 ext2 类型的文件系统时,会自动创建一个名为 lost+found 的目录,并为其预留 4 个数据块的大小(16KB),其用途稍后就会介绍。
我们在根目录下面创建了几个文件和一个名为 dir1(索引节点号为 32577)的目录,并在 dir1 中又创建了两个子目录(subdir1 和 subdir2)和几个文件。
要想完美地恢复目录,必须了解清楚在删除目录时究竟对系统进行了哪些操作,其中哪些是可以恢复的,哪些是无法恢复的,这样才能寻找适当的方式去尝试恢复数据。现在先让我们记录下这个文件系统目前的一些状态:
清单10. 根目录(索引节点 <2>)子目录 dir1的 inode 信息
debugfs: stat <2> Inode: 2 Type: directory Mode: 0755 Flags: 0x0 Generation: 0 User: 0 Group: 0 Size: 4096 File ACL: 0 Directory ACL: 0 Links: 4 Blockcount: 8 Fragment: Address: 0 Number: 0 Size: 0 ctime: 0x474d2d63 -- Wed Nov 28 16:57:07 2007 atime: 0x474d3203 -- Wed Nov 28 17:16:51 2007 mtime: 0x474d2d63 -- Wed Nov 28 16:57:07 2007 BLOCKS: (0):1536 TOTAL: 1 debugfs: stat <32577> Inode: 32577 Type: directory Mode: 0755 Flags: 0x0 Generation: 1695264350 User: 0 Group: 0 Size: 4096 File ACL: 1542 Directory ACL: 0 Links: 4 Blockcount: 16 Fragment: Address: 0 Number: 0 Size: 0 ctime: 0x474d2d2a -- Wed Nov 28 16:56:10 2007 atime: 0x474d3203 -- Wed Nov 28 17:16:51 2007 mtime: 0x474d2d2a -- Wed Nov 28 16:56:10 2007 BLOCKS: (0):88064 TOTAL: 1 |
以及根目录和 dir1 目录的数据块:
清单11. 备份根目录和子目录 dir1 的数据块
# dd if=/dev/sdb6 of=/tmp/recover/block.1536.orig bs=4096 count=1 skip=1536 # dd if=/dev/sdb6 of=/tmp/recover/block.88064.orig bs=4096 count=1 skip=88064 |
为了方便阅读目录数据块中的数据,我们编写了一个小程序,源代码如下所示:
清单12. read_dir_entry.c 源代码
#include |
这段程序的基本想法是要遍历目录对应的数据块的内容,并打印每个目录项的内容(一个 ext2_dir_entry_2 结构)。需要注意的是,在遍历整个文件时,我们并没有采用 rec_length 作为步长,而是采用了 name_length + sizeof(struct ext2_dir_entry_part) 作为步长,这是为了能够读取到其中被标识为删除的目录项的数据,大家稍后就会明白这一点。
将这段程序保存为 read_dir_entry.c,并编译成可执行程序:
清单13. 编译 read_dir_entry.c
# gcc –o read_dir_entry read_dir_entry.c |
并分析刚才得到的两个数据块的结果:
清单14. 分析原始目录项中的数据
# ./read_dir_entry block.1536.orig 4096
offset | inode number | rec_len | name_len | file_type | name
=================================================================
0: 2 12 1 2 .
12: 2 12 2 2 ..
24: 11 20 10 2 lost+found
44: 12 24 13 1 createfile.sh
68: 13 20 12 1 testfile.35K
88: 14 20 12 1 testfile.10M
108: 32577 12 4 2 dir1
120: 15 28 17 1 testfile.35K.orig
148: 16 3948 17 1 testfile.10M.orig
# ./read_dir_entry block.88064.orig 4096
offset | inode number | rec_len | name_len | file_type | name
=================================================================
0: 32577 12 1 2 .
12: 2 12 2 2 ..
24: 32578 24 13 1 createfile.sh
48: 32579 16 8 2 subdir11
64: 48865 16 8 2 subdir12
80: 32580 20 12 1 testfile.35K
100: 32581 3996 12 1 testfile.10M
|
这与上面在 debugfs 中使用 ls 命令看到的结果是完全吻合的。
现在删除 dir1 这个目录,然后卸载测试目录(这是为了确保删除文件操作会被同步到磁盘上的数据块中),然后重新读取我们关注的这两个数据块的内容:
清单15. 删除目录并重新备份目录项数据
# rm –rf /tmp/test/dir1 # cd / # umount /tmp/test # dd if=/dev/sdb6 of=/tmp/recover/block.1536.deleted bs=4096 count=1 skip=1536 # dd if=/dev/sdb6 of=/tmp/recover/block.88064. deleted bs=4096 count=1 skip=88064 |
现在再来查看一下这两个数据块中内容的变化:
清单16. 分析新目录项中的数据
# ./read_dir_entry block.1536.deleted 4096
offset | inode number | rec_len | name_len | file_type | name
=================================================================
0: 2 12 1 2 .
12: 2 12 2 2 ..
24: 11 20 10 2 lost+found
44: 12 24 13 1 createfile.sh
68: 13 20 12 1 testfile.35K
88: 14 32 12 1 testfile.10M
108: 0 12 4 2 dir1
120: 15 28 17 1 testfile.35K.orig
148: 16 3948 17 1 testfile.10M.orig
# ./read_dir_entry block.88064.deleted 4096
offset | inode number | rec_len | name_len | file_type | name
=================================================================
0: 32577 12 1 2 .
12: 2 12 2 2 ..
24: 32578 24 13 1 createfile.sh
48: 32579 16 8 2 subdir11
64: 48865 16 8 2 subdir12
80: 32580 20 12 1 testfile.35K
100: 32581 3996 12 1 testfile.10M
|
与前面的结果进行一下对比就会发现,dir1 目录的数据块并没有发生任何变化,而根目录的数据块中 dir1 以及之前的一项则变得不同了。实际上,在删除 dir1 目录时,所执行的操作是将 dir1 项中的索引节点号清空,并将这段空间合并到前一项上(即将 dir1 项的 rec_length 加到前一项的 rec_length上)。这也就是为什么我们编写的 read_dir_entry 程序没有采用 rec_length 作为步长来遍历数据的原因。
除了数据之外,索引节点信息也发生了一些变化,现在我们来了解一下最新的索引节点信息:
清单17. 删除子目录后索引节点信息的变化
# debugfs /dev/sdb6 debugfs 1.39 (29-May-2006) debugfs: stat <2> Inode: 2 Type: directory Mode: 0755 Flags: 0x0 Generation: 0 User: 0 Group: 0 Size: 4096 File ACL: 0 Directory ACL: 0 Links: 3 Blockcount: 8 Fragment: Address: 0 Number: 0 Size: 0 ctime: 0x474d3387 -- Wed Nov 28 17:23:19 2007 atime: 0x474d33c2 -- Wed Nov 28 17:24:18 2007 mtime: 0x474d3387 -- Wed Nov 28 17:23:19 2007 BLOCKS: (0):1536 TOTAL: 1 debugfs: stat <32577> Inode: 32577 Type: directory Mode: 0755 Flags: 0x0 Generation: 1695264350 User: 0 Group: 0 Size: 0 File ACL: 1542 Directory ACL: 0 Links: 0 Blockcount: 16 Fragment: Address: 0 Number: 0 Size: 0 ctime: 0x474d3387 -- Wed Nov 28 17:23:19 2007 atime: 0x474d3387 -- Wed Nov 28 17:23:19 2007 mtime: 0x474d3387 -- Wed Nov 28 17:23:19 2007 dtime: 0x474d3387 -- Wed Nov 28 17:23:19 2007 BLOCKS: (0):88064 TOTAL: 1 |
与删除之前的结果进行一下比较就会发现,主要区别包括:
- 将父目录的 Links 值减 1。
- 设置 dtime 时间,并更新其他时间字段。
- 由于目录只有在为空时才会被删除,因此其 Size 值会被设置为 0,Links 字段也被设置为 0。
通过了解数据块和索引节点的相应变化可以为恢复目录提供一个清晰的思路,其具体步骤如下:
- 确定删除目录所对应的索引节点号。
- 按照恢复文件的方法恢复索引节点对应的数据块。
- 遍历数据块内容,恢复其中包含的文件和子目录。
- 更新索引节点对应信息。
- 修改父目录的索引节点信息和数据块中对应目录项的内容。
实际上,步骤3并不是必须的,因为如果这个目录中包含文件或子目录,使用 debugfs 的 lsdel 命令(遍历索引节点表)也可以找到所删除的索引节点记录,采用本文中介绍的方法也可以将其逐一恢复出来。
debugfs 的 mi 命令可以用来直接修改索引节点的信息,下面我们就使用这个命令来修改 dir1 这个目录对应的索引节点的信息:
清单18. 使用 debugfs 的 mi 命令直接修改索引节点信息
# debugfs -w /dev/sdb6
debugfs 1.39 (29-May-2006)
debugfs: lsdel
Inode Owner Mode Size Blocks Time deleted
32577 0 40755 0 1/ 1 Wed Nov 28 17:23:19 2007
32578 0 100755 1406 1/ 1 Wed Nov 28 17:23:19 2007
32579 0 40755 0 1/ 1 Wed Nov 28 17:23:19 2007
32580 0 100644 35840 9/ 9 Wed Nov 28 17:23:19 2007
32581 0 100644 10485760 2564/2564 Wed Nov 28 17:23:19 2007
48865 0 40755 0 1/ 1 Wed Nov 28 17:23:19 2007
6 deleted inodes found.
debugfs: mi <32577>
Mode [040755]
User ID [0]
Group ID [0]
Size [0] 4096
Creation time [1196241799]
Modification time [1196241799]
Access time [1196241799]
Deletion time [1196241799] 0
Link count [0] 4
Block count [16]
File flags [0x0]
Generation [0x650bae5e]
File acl [1542]
Directory acl [0]
Fragment address [0]
Fragment number [0]
Fragment size [0]
Direct Block #0 [88064]
Direct Block #1 [0]
Direct Block #2 [0]
Direct Block #3 [0]
Direct Block #4 [0]
Direct Block #5 [0]
Direct Block #6 [0]
Direct Block #7 [0]
Direct Block #8 [0]
Direct Block #9 [0]
Direct Block #10 [0]
Direct Block #11 [0]
Indirect Block [0]
Double Indirect Block [0]
Triple Indirect Block [0]
debugfs: link <32577> dir1
debugfs: q
|
注意要使用 mi 命令直接修改索引节点的信息,在执行 debugfs 命令时必须加上 –w 选项,表示以可写方式打开该设备文件。在上面这个例子中,lsdel 命令找到 6 个已经删除的文件,其中 32577 就是 dir1 目录原来对应的索引节点。接下来使用 mi 命令修改这个索引节点的内容,将 Size 设置为 4096(Block count * 512),Deletion Time 设置为 0,Links count 设置为 4。最后又执行了一个 link 命令,为这个索引节点起名为 dir1(这样并不会修改父目录的 Links count 值)。
退出 debugfs 并重新挂载这个设备,就会发现 dir1 目录已经被找回来了,不过尽管该目录下面的目录结构都是正确的,但是这些文件和子目录的数据都是错误的:
清单19. 验证恢复结果
# mount /dev/sdb6 /tmp/test # ls -li /tmp/test total 20632 12 -rwxr-xr-x 1 root root 1406 Nov 28 16:53 createfile.sh 32577 drwxr-xr-x 4 root root 4096 Nov 28 17:23 dir1 11 drwx------ 2 root root 16384 Nov 28 16:52 lost+found 14 -rw-r--r-- 1 root root 10485760 Nov 28 16:54 testfile.10M 16 -rw-r--r-- 1 root root 10485760 Nov 28 16:57 testfile.10M.orig 13 -rw-r--r-- 1 root root 35840 Nov 28 16:53 testfile.35K 15 -rw-r--r-- 1 root root 35840 Nov 28 16:56 testfile.35K.orig # ls -li /tmp/test/dir1 total 0 ??--------- ? ? ? ? ? /tmp/test/dir1/createfile.sh ??--------- ? ? ? ? ? /tmp/test/dir1/subdir11 ??--------- ? ? ? ? ? /tmp/test/dir1/subdir12 ??--------- ? ? ? ? ? /tmp/test/dir1/testfile.10M ??--------- ? ? ? ? ? /tmp/test/dir1/testfile.35K |
其原因是 dir1 中所包含的另外两个子目录和三个文件都还没有恢复。可以想像,恢复一个删除的目录会是件非常复杂而繁琐的事情。幸运的是,e2fsck 这个工具可以很好地理解 ext2 文件系统的实现,它可以用来对文件系统进行检查,并自动修复诸如链接数不对等问题。现在请按照上面的方法使用 mi 命令将其他 5 个找到的索引节点 Deletion Time 设置为 0,并将 Link count 设置为 1。然后使用下面的命令,强制 e2fsck 对整个文件系统进行检查:
清单20. 使用 e2fsck 强制对文件系统进行一致性检查
# e2fsck -f -y /dev/sdb6 > e2fsck.out 2>&1 |
e2fsck 的结果保存在 e2fsck.out 文件中。查看这个文件就会发现,e2fsck要执行 4 个步骤的检查:
- 检查并修复索引节点、数据块和大小。比如已删除子目录的索引节点大小为0,则会根据所占用的块数(每个块为512字节)换算出来。
- 检查目录结构的问题。检查索引节点的父目录,如果不存在,就认为父目录就是根目录。对于目录节点,需要检查是否包含当前目录和父目录项。
- 检查目录结构的连通性。防止出现按照绝对路径无法访问文件的情况出现,将这些有问题的文件或目录放入 lost+found 目录中。
- 检查并修复引用计数。统计对索引节点的引用计数值。
- 检查并修复块组信息,包括块位图、索引节点位图,计算块组中的空闲块数、空闲索引节点数等。
现在重新挂载这个文件系统,会发现所有的文件已经全部恢复出来了。
符号链接
我们知道,在 ext2 文件系统中,链接可以分为两种:硬链接和符号链接(或称为软链接)。实际上,目录中的每个文件名都对应一个硬链接。硬链接的出现是为了解决使用不同的文件名来引用同一个文件的问题。如果没有硬链接,只能通过给现有文件新建一份拷贝才能通过另外一个名字来引用这个文件,这样做的问题是在文件内容发生变化的情况下,势必会造成引用这些文件的进程所访问到的数据不一致的情况出现。而虽然每个硬链接在文件目录项中都是作为一个单独的项存在的,但是其索引节点号完全相同,这就是说它们引用的是同一个索引节点,因此对应的文件数据也完全相同。下面让我们通过一个例子来验证一下:
清单21.硬链接采用相同的索引节点号
# ln testfile.10M hardlink.10M
# ls -li
total 20592
12 -rwxr-xr-x 1 root root 1406 Nov 29 19:19 createfile.sh
1205313 drwxr-xr-x 2 root root 4096 Nov 29 19:29 dir1
14 -rw-r--r-- 2 root root 10485760 Nov 29 19:21 hardlink.10M
11 drwx------ 2 root root 16384 Nov 29 19:19 lost+found
14 -rw-r--r-- 2 root root 10485760 Nov 29 19:21 testfile.10M
13 -rw-r--r-- 1 root root 35840 Nov 29 19:20 testfile.35K
|
我们可以看到,使用 ln 建立的硬链接 hardlink.10M 的索引节点号也是 14,这与 testfile.10M 的索引节点号完全相同,因此通过这两个名字所访问到的数据是完全一致的。
因此,硬链接的恢复与普通文件的恢复非常类似,唯一的区别在于如果索引节点指向的数据已经恢复出来了,现在就无需再恢复数据了,只需要恢复其父目录中的对应目录项即可,这可以通过 debugfs 的 link 命令实现。
硬件链接的出现虽然可以满足通过不同名字来引用相同文件的需要,但是也存在一些问题,包括:
- 不能对目录建立硬链接,否则就会引起循环引用的问题,从而导致最终正常路径的无法访问。
- 不能建立跨文件系统的硬链接,这是由于每个文件系统中的索引节点号都是单独进行编号的,跨文件系统就会导致索引节点号变得非常混乱。而这在现代 Linux/Unix 操作系统上恰恰是无法接受的,因为每个文件系统中都可能会有很多挂载点来挂载不同的文件系统。
为了解决上面的问题,符号链接就应运而生了。符号链接与硬链接的区别在于它要占用一个单独的索引节点来存储相关数据,但却并不存储链接指向的文件的数据,而是存储链接的路径名:如果这个路径名小于60个字符,就其存储在符号链接索引节点的 i_block 域中;如果超过 60 个字符,就使用一个单独的数据块来存储。下面让我们来看一个例子:
清单22. 符号链接采用不同的索引节点号
# ln -s testfile.10M softlink.10M
# ls -li
total 20596
12 -rwxr-xr-x 1 root root 1406 Nov 29 19:19 createfile.sh
1205313 drwxr-xr-x 2 root root 4096 Nov 29 19:29 dir1
14 -rw-r--r-- 2 root root 10485760 Nov 29 19:21 hardlink.10M
11 drwx------ 2 root root 16384 Nov 29 19:19 lost+found
15 lrwxrwxrwx 1 root root 12 Nov 29 19:41 softlink.10M -> testfile.10M
14 -rw-r--r-- 2 root root 10485760 Nov 29 19:21 testfile.10M
13 -rw-r--r-- 1 root root 35840 Nov 29 19:20 testfile.35K
# echo "stat <15>" | debugfs /dev/sdb6
debugfs 1.39 (29-May-2006)
debugfs: Inode: 15 Type: symlink Mode: 0777 Flags: 0x0 Generation: 2344716327
User: 0 Group: 0 Size: 12
File ACL: 1542 Directory ACL: 0
Links: 1 Blockcount: 8
Fragment: Address: 0 Number: 0 Size: 0
ctime: 0x474ea56f -- Thu Nov 29 19:41:35 2007
atime: 0x474ea571 -- Thu Nov 29 19:41:37 2007
mtime: 0x474ea56f -- Thu Nov 29 19:41:35 2007
Fast_link_dest: testfile.10M
|
ln 命令的 –s 参数就用来指定创建一个符号链接。从结果中可以看出,新创建的符号链接使用的索引节点号是 15,索引节点中的 i_block 中存储的值就是这个符号链接所指向的目标:testfile.10M(Fast_link_dest 的值)。
现在再来看一个指向长路径的符号链接的例子:
清单23. 长名符号链接
# touch abcdwfghijklmnopqrstuvwxyz0123456789abcdwfghijklmnopqrstuvwxyz0123456789.sh
# ln -s abcdwfghijklmnopqrstuvwxyz0123456789abcdwfghijklmnopqrstuvwxyz0123456789.sh /
longsoftlink.sh
# ls -li
total 20608
16 -rw-r--r-- 1 root root 0 Nov 29 19:52 /
abcdwfghijklmnopqrstuvwxyz0123456789abcdwfghijklmnopqrstuvwxyz0123456789.sh
12 -rwxr-xr-x 1 root root 1406 Nov 29 19:19 createfile.sh
1205313 drwxr-xr-x 2 root root 4096 Nov 29 19:29 dir1
14 -rw-r--r-- 2 root root 10485760 Nov 29 19:21 hardlink.10M
17 lrwxrwxrwx 1 root root 75 Nov 29 19:53 longsoftlink.sh -> /
abcdwfghijklmnopqrstuvwxyz0123456789abcdwfghijklmnopqrstuvwxyz0123456789.sh
11 drwx------ 2 root root 16384 Nov 29 19:19 lost+found
15 lrwxrwxrwx 1 root root 12 Nov 29 19:41 softlink.10M -> testfile.10M
14 -rw-r--r-- 2 root root 10485760 Nov 29 19:21 testfile.10M
13 -rw-r--r-- 1 root root 35840 Nov 29 19:20 testfile.35K
# echo "stat <17>" | debugfs /dev/sdb6
debugfs 1.39 (29-May-2006)
debugfs: Inode: 17 Type: symlink Mode: 0777 Flags: 0x0 Generation: 744523175
User: 0 Group: 0 Size: 75
File ACL: 1542 Directory ACL: 0
Links: 1 Blockcount: 16
Fragment: Address: 0 Number: 0 Size: 0
ctime: 0x474ea824 -- Thu Nov 29 19:53:08 2007
atime: 0x474ea826 -- Thu Nov 29 19:53:10 2007
mtime: 0x474ea824 -- Thu Nov 29 19:53:08 2007
BLOCKS:
(0):6144
TOTAL: 1
|
此处我们创建了一个名字长度为 75 个字符的文件,并建立一个符号链接(其索引节点号是 17)指向这个文件。由于链接指向的位置路径名超过了 60 个字符,因此还需要使用一个数据块(6144)来存储这个路径名。手工恢复方法如下:
清单24. 恢复长名符号链接
# dd if=/dev/sdb6 of=longsoftlink.6144 bs=4096 count=1 skip=6144 # xxd longsoftlink.6144 | more 0000000: 6162 6364 7766 6768 696a 6b6c 6d6e 6f70 abcdwfghijklmnop 0000010: 7172 7374 7576 7778 797a 3031 3233 3435 qrstuvwxyz012345 0000020: 3637 3839 6162 6364 7766 6768 696a 6b6c 6789abcdwfghijkl 0000030: 6d6e 6f70 7172 7374 7576 7778 797a 3031 mnopqrstuvwxyz01 0000040: 3233 3435 3637 3839 2e73 6800 0000 0000 23456789.sh..... 0000050: 0000 0000 0000 0000 0000 0000 0000 0000 ................ |
这样符号链接的数据就可以完整地恢复出来了。
需要注意的是,为了保证整个文件系统的完整性,在恢复硬链接时,还需要修改链接指向的索引节点的引用计数值,这可以使用 e2fsck 帮助完成,详细步骤请参看上一节目录的恢复。
小结
本文介绍了 ext2 文件系统中比较特殊的一些文件的存储和恢复机制,包括文件洞、目录和链接,并介绍了如何结合使用 debugfs 和 e2fsck 等工具完整恢复 ext2 文件系统的方法。在本系列的后续文章中,我们将介绍几个可以自动恢复 ext2 文件系统中已删除文件的工具,以及对 ext2 文件系统的后继者 ext3 和 ext4 文件系统的一些考虑。
恢复系统中删除的文件是一个非常繁琐的过程,而 e2undel 这个工具可以用来方便地恢复文件系统中已删除的文件。本文将首先讨论 e2undel 的工作原理和用法,并对之进行一些改进。然后讨论了文件系统故障、文件系统重建、磁盘物理损坏等情况下应该如何恢复数据。
在本系列文章的前两部分中,我们介绍了 ext2 文件系统中各种文件在磁盘上的存储结构,以及如何利用 debugfs 工具的辅助,手工恢复这些文件的详细过程。
通过这两部分的学习,我们可以看出恢复系统中删除的文件是一个非常繁琐的过程,需要非常仔细地考虑各种情况,并且要保持足够的细心,才可能把数据准确无误地恢复出来。稍有差错,就会造成数据丢失的情况。聪明的读者肯定会想,如果有一些好工具来自动或辅助完成数据的恢复过程,那简直就太好了。
幸运的是,已经有人开发了这样一些工具,来简化用户的数据恢复工作,e2undel 就是其中功能最为强大的一个。
自动恢复工具 e2undel
回想一下,在 ext2 文件系统中删除一个文件时,该文件本身的数据并没有被真正删除,实际执行的操作如下:
- 在块位图中将该文件所占用的数据块标识为可用状态。
- 在索引节点位图中将该文件所占用的索引节点标识为可用状态。
- 将该文件索引节点中的硬链接数目设置为 0。
- 将该文件索引节点中的删除时间设置为当前时间。
- 将父目录项中该文件对应项中的索引节点号设置为 0,并扩展前一项,使其包含该项所占用的空间。
而索引节点中的一些关键信息(或称为元数据,包括文件属主、访问权限、文件大小、该文件所占用的数据块等)都并没有发生任何变化。因此只要知道了索引节点号,就完全可以用本系列文章介绍的技术将文件完整地从磁盘上恢复出来了,这正是 e2undel 之类的工具赖以生存的基础。
然而,由于所删除的文件在目录项中对应的项中的索引节点号被清空了,因此我们就无法从索引节点中获得文件名的信息了。不过,由于文件大小、属主和删除时间信息依然能反映文件的原始信息,因此我们可以通过这些信息来帮助判断所删除的文件是哪个。
e2undel 是由Oliver Diedrich 开发的一个用来恢复 ext2 文件系统中已删除文件的工具,它会遍历所检测的文件系统的索引节点表,从中找出所有被标记为删除的索引节点,并按照属主和删除时间列出这些文件。另外,e2undel 还提供了文件大小信息,并试图按照 file 命令的方式来确定文件类型。如果您使用 rm –rf * 之类的命令一次删除了很多文件,这种信息就可以用来非常方便地帮助确定希望恢复的是哪些文件。在选择要恢复的文件之后,e2undel 会从磁盘上读取该文件占用的数据块(这些数据块的信息全部保存在索引节点中),并将其写入到一个新文件中。下面我们来看一下 e2undel 这个工具的详细用法。
首先请从 e2undel 的主页(http://e2undel.sourceforge.net/)上下载最新的源码包(截止到撰写本文为止,最新的版本是 0.82),并将其保存到本地文件系统中。不过这个源码包在最新的 Fedora Core 8 上编译时可能会有些问题,这是由于 ext2 文件系统内部实现中一些数据结构的变化引起来的,读者可以下载本文“下载”部分给出的补丁来修正这个问题(请下载这个补丁文件 e2undel-0.82.patch,并将其保存到与源码包相同的目录中)。要想编译 e2undel,系统中还必须安装 e2fsprogs 和 e2fsprogs-devel 这两个包,其中有编译 e2undel 所需要的一些头文件。Fedora Core 8 中自带的这两个包的版本号是 1.39-7:
清单1. 确认系统中已经安装了 e2fsprogs 和 e2fsprogs-devel
# rpm -qa | grep e2fsprogs e2fsprogs-libs-1.39-7 e2fsprogs-1.39-7 e2fsprogs-devel-1.39-7 |
现在就可以开始编译 e2undel 了:
清单2. 编译 e2undel
# tar -zxf e2undel-0.82.tgz # patch -p0 < e2undel-0.82.patch patching file e2undel-0.82/Makefile patching file e2undel-0.82/e2undel.h patching file e2undel-0.82.orig/libundel.c # cd e2undel-0.82 # make all |
编译之后会生成一个名为 e2undel 的可执行文件,其用法如下:
清单3. e2undel 的用法
# ./e2undel ./e2undel 0.82 usage: ./e2undel -d device -s path [-a] [-t] usage: ./e2undel -l '-d': file system where to look for deleted files '-s': directory where to save undeleted files '-a': work on all files, not only on those listed in undel log file '-t': try to determine type of deleted files w/o names, works only with '-a' '-l': just give a list of valid files in undel log file |
e2undel 实际上并没有像前面介绍的使用 e2fsck 那样的方法一样真正将已经删除的文件恢复到原来的文件系统中,因为它并不会修改磁盘上 ext2 使用的内部数据结构(例如索引节点、块位图和索引节点位图)。相反,它仅仅是将所删除文件的数据恢复出来并将这些数据保存到一个新文件中。因此,-s 参数指定是保存恢复出来的文件的目录,最好是在另外一个文件系统上,否则可能会覆盖磁盘上的原有数据。如果指定了 -t 参数,e2undel 会试图读取文件的前 1KB 数据,并试图从中确定该文件的类型,其原理与系统中的 file 命令非常类似,这些信息可以帮助判断正在恢复的是什么文件。
下面让我们来看一个使用 e2undel 恢复文件系统的实例。
清单4. 使用 e2undel 恢复文件的实例
# ./e2undel -a -t -d /dev/sda2 -s /tmp/recover/ ./e2undel 0.82 Trying to recover files on /dev/sda2, saving them on /tmp/recover/ |
/dev/sda2 opened for read-only access
/dev/sda2 was not cleanly unmounted.
Do you want wo continue (y/n)? y
489600 inodes (489583 free)
977956 blocks of 4096 bytes (941677 free)
last mounted on Fri Dec 28 16:21:50 2007
|
reading log file: opening log file: No such file or directory no entries for /dev/sda2 in log file searching for deleted inodes on /dev/sda2: |==================================================| 489600 inodes scanned, 26 deleted files found |
user name | 1 <12 h | 2 <48 h | 3 <7 d | 4 <30 d | 5 <1 y | 6 older
-------------+---------+---------+---------+---------+---------+--------
root | 0 | 0 | 0 | 2 | 0 | 0
phost | 24 | 0 | 0 | 0 | 0 | 0
Select user name from table or press enter to exit: root
Select time interval (1 to 6) or press enter to exit: 4
|
inode size deleted at name
-----------------------------------------------------------
13 35840 Dec 19 17:43 2007 * ASCII text
14 10485760 Dec 19 17:43 2007 * ASCII text
Select an inode listed above or press enter to go back: 13
35840 bytes written to /tmp/recover//inode-13-ASCII_text
Select an inode listed above or press enter to go back:
|
user name | 1 <12 h | 2 <48 h | 3 <7 d | 4 <30 d | 5 <1 y | 6 older
-------------+---------+---------+---------+---------+---------+--------
root | 0 | 0 | 0 | 2 | 0 | 0
phost | 24 | 0 | 0 | 0 | 0 | 0
Select user name from table or press enter to exit:
#
|
e2undel 是一个交互式的命令,命令执行过程中需要输入的内容已经使用黑体表示出来了。从输出结果中可以看出,e2undel 一共在这个文件系统中找到了 26 个文件,其中 root 用户删除的有两个。这些文件按照删除时间的先后顺序被划分到几类中。索引节点号 13 对应的是一个 ASCII 正文的文本文件,最终被恢复到 /tmp/recover//inode-13-ASCII_text 文件中。查看一下这个文件就会发现,正是我们在本系列前两部分中删除的那个 35KB 的测试文件。
利用 libundel 库完美恢复文件
尽管 e2undel 可以非常方便地简化恢复文件的过程,但是美中不足的是,其恢复出来的文件的文件名却丢失了,其原因是文件名是保存在父目录的目录项中的,而不是保存在索引节点中的。本系列文章第 2 部分中给出了一种通过遍历父目录的目录项来查找已删除文件的文件名的方法,但是由于索引节点会被重用,因此通过这种方式恢复出来的文件名也许并不总是正确的。另外,如果目录结构的非常复杂,就很难确定某个文件的父目录究竟是哪个,因此查找正确文件名的难度就会变得很大。如果能在删除文件时记录下索引节点号和文件名之间的对应关系,这个问题就能完美地解决了。
这个问题在 e2undel 中得到了完美的解决。实际上,所有删除命令,例如 rm、unlink 都是通过一些底层的系统调用(例如 unlink(2)、rmdir(2))来实现的。基于这一点,e2undel 又利用了Linux 系统中动态链接库加载时提供的一种便利:如果设置了环境变量 LD_PRELOAD,那么在加载动态链接库时,会优先从 $LD_PRELOAD 指向的动态链接库中查找符号表,然后才会在系统使用 ldconfig 配置的动态链接库中继续查找符号表。因此,我们可以在自己编写的库函数中实现一部分系统调用,并将这个库优先于系统库加载,这样就能欺骗系统使用我们自己定义的系统调用来执行原有的操作。具体到 e2undel 上来说,就是要在调用这些系统调用删除文件时,记录下文件名和索引节点号之间的对应关系。
在编译 e2undel 源代码之后,还会生成一个库文件 libundel.so.1.0,其中包含了删除文件时所使用的一些系统调用的钩子函数。e2undel官方主页上下载的源码包中仅仅包括了对 unlink(2) 和 remove(3) 这两个系统调用的钩子函数,但是从 2.6.16 版本的内核开始,引入了一系列新的系统调用,包括 faccessat(2), fchmodat(2), fchownat(2), fstatat(2), futimesat(2), linkat(2), mkdirat(2), mknodat(2), openat(2), readlinkat(2), renameat(2), symlinkat(2), unlinkat(2), mkfifoat(3) 等,尽管这些系统调用目前还没有成为POSIX标准的一部分,但是相信这个过程不会很久了。目前诸如 Fecora Core 8 之类的系统中自带的 rm 命令(属于 coreutils)包已经使用这些新的系统调用进行了改写,另外本文下载部分中的补丁文件中已经提供了对 rmdir 和 unlinkat 的钩子函数。部分源代码如下所示:
清单5. libundel.c 代码片断
void _init()
{
f = fopen("/var/e2undel/e2undel", "a");
if (!f)
fprintf(stderr, "libundel: can't open log file, undeletion disabled/n");
}
|
...... |
int rmdir(const char *pathname)
{
int err;
struct stat buf;
char pwd[PATH_MAX];
int (*rmdirp)(char *) = dlsym(RTLD_NEXT, "rmdir");
|
if (NULL != pathname)
{
if (__lxstat(3, pathname, &buf)) buf.st_ino = 0;
if (!realpath(pathname, pwd)) pwd[0] = '/0';
}
err = (*rmdirp)((char *) pathname);
if (err) return err; /* remove() did not succeed */
if (f)
{
if (!S_ISLNK(buf.st_mode)) /* !!! should we check for other file types? */
{ /* don't log deleted symlinks */
fprintf(f, "%ld,%ld::%ld::%s/n",
(long) (buf.st_dev & 0xff00) / 256,
(long) buf.st_dev & 0xff,
(long) buf.st_ino, pwd[0] ? pwd : pathname);
fflush(f);
}
} /* if (f) */
return err;
} /* rmdir() */
|
...... |
void _fini()
{
if (f) fclose(f);
}
|
_init 和 _fini 这两个函数分别在打开和关闭动态链接库时执行,分别用来打开和关闭日志文件。如果某个命令(例如 rm)执行了 rmdir 系统调用,就会被这个库接管。rmdir 的处理比较简单,它先搜索到真正的 rmdir 系统调用的符号表,然后使用同样的参数来执行这个系统调用,如果成功,就将有关索引节点和文件名之类的信息记录到日志中(默认是 /var/e2undel/ e2undel)。
这个库的使用非常简单,请执行下面的命令:
清单6. libundel 的设置
# cp libundel.so.1.0 /usr/local/lib # cd /usr/local/lib # ln -s libundel.so.1.0 libundel.so.1 # ln –s libundel.so.1.0 libundel.so |
# ldconfig # mkdir /var/e2undel # chmod 711 /var/e2undel # touch /var/e2undel/e2undel # chmod 622 /var/e2undel/e2undel |
上面的设置仅仅允许 root 用户可以恢复文件,如果希望让普通用户也能恢复文件,就需要修改对应文件的权限设置。
现在尝试以另外一个用户的身份来删除些文件:
清单7. 设置libundel之后删除文件
$ export LD_PRELOAD=/usr/local/lib/libundel.so $ rm -rf e2undel-0.82 |
要想记录所有用户的删除文件的操作,可以将 export LD_PRELOAD=/usr/local/lib/libundel.so 这行内容加入到 /etc/profile 文件中。
现在使用 e2undel 来恢复已删除的文件就变得简单多了,因为已经可以通过文件名来恢复文件了:
清单8. e2undel 利用 libundel 日志恢复删除文件
# ./e2undel -a -t -d /dev/sda2 -s /tmp/recover/ ./e2undel 0.82 Trying to recover files on /dev/sda2, saving them on /tmp/recover/ |
/dev/sda2 opened for read-only access
/dev/sda2 was not cleanly unmounted.
Do you want wo continue (y/n)? y
489600 inodes (489531 free)
977956 blocks of 4096 bytes (941559 free)
last mounted on Fri Dec 28 20:45:05 2007
|
reading log file: found 24 entries for /dev/sda2 in log file searching for deleted inodes on /dev/sda2: |==================================================| 489600 inodes scanned, 26 deleted files found checking names from log file for deleted files: 24 deleted files with names |
user name | 1 <12 h | 2 <48 h | 3 <7 d | 4 <30 d | 5 <1 y | 6 older
-------------+---------+---------+---------+---------+---------+--------
root | 0 | 0 | 0 | 2 | 0 | 0
phost | 24 | 0 | 0 | 0 | 0 | 0
Select user name from table or press enter to exit: phost
Select time interval (1 to 6) or press enter to exit: 1
|
inode size deleted at name ----------------------------------------------------------- 310083 0 Dec 29 17:23 2007 /tmp/test/undel/e2undel-0.82 310113 2792 Dec 29 17:23 2007 /tmp/test/undel/e2undel-0.82/BUGS 310115 3268 Dec 29 17:23 2007 /tmp/test/undel/e2undel-0.82/HISTORY 310116 1349 Dec 29 17:23 2007 /tmp/test/undel/e2undel-0.82/INSTALL 310117 1841 Dec 29 17:23 2007 /tmp/test/undel/e2undel-0.82/INSTALL.de 310118 2175 Dec 29 17:23 2007 /tmp/test/undel/e2undel-0.82/Makefile 310119 12247 Dec 29 17:23 2007 /tmp/test/undel/e2undel-0.82/README 310120 9545 Dec 29 17:23 2007 /tmp/test/undel/e2undel-0.82/README.de 310121 13690 Dec 29 17:23 2007 /tmp/test/undel/e2undel-0.82/apprentice.c 310122 19665 Dec 29 17:23 2007 /tmp/test/undel/e2undel-0.82/ascmagic.c 310123 221 Dec 29 17:23 2007 /tmp/test/undel/e2undel-0.82/common.h 310124 1036 Dec 29 17:23 2007 /tmp/test/undel/e2undel-0.82/compactlog.c 310125 30109 Dec 29 17:23 2007 /tmp/test/undel/e2undel-0.82/e2undel.c 310127 2447 Dec 29 17:23 2007 /tmp/test/undel/e2undel-0.82/e2undel.h 310128 1077 Dec 29 17:23 2007 /tmp/test/undel/e2undel-0.82/file.c 310129 2080 Dec 29 17:23 2007 /tmp/test/undel/e2undel-0.82/file.h 310130 4484 Dec 29 17:23 2007 /tmp/test/undel/e2undel-0.82/find_del.c 310131 2141 Dec 29 17:23 2007 /tmp/test/undel/e2undel-0.82/is_tar.c 310132 2373 Dec 29 17:23 2007 /tmp/test/undel/e2undel-0.82/libundel.c 310133 7655 Dec 29 17:23 2007 /tmp/test/undel/e2undel-0.82/log.c 310134 39600 Dec 29 17:23 2007 /tmp/test/undel/e2undel-0.82/magic.h 310135 4591 Dec 29 17:23 2007 /tmp/test/undel/e2undel-0.82/names.h 310136 13117 Dec 29 17:23 2007 /tmp/test/undel/e2undel-0.82/softmagic.c 310137 5183 Dec 29 17:23 2007 /tmp/test/undel/e2undel-0.82/tar.h |
如果对所有用户都打开这个功能,由于日志文件是单向增长的,随着时间的推移,可能会变得很大,不过 e2undel 中还提供了一个 compactlog 工具来删除日志文件中的重复项。
在学习本系列文章介绍的技术之后,利用 e2undel 之类的工具,并使用本系列文章第一部分中提供的补丁,恢复删除文件就变得非常简单了。但是在日常使用过程中,大家可能还会碰到一些意外的情况,比如文件系统发生问题,从而无法正常挂载;使用 mke2fs 之类的工具重做了文件系统;甚至磁盘上出现坏道。此时应该如何恢复系统中的文件呢,下面让我们来逐一看一下如何解决这些问题。
文件系统故障的恢复
回想一下,在超级块中保存了有关文件系统本身的一些数据,在 ext2 文件系统中,还使用块组描述符保存了有关块组的信息;另外,索引节点位图、块位图中分别保存了索引节点和磁盘上数据块的使用情况,而文件本身的索引节点信息(即文件的元数据)则保存在索引节点表中。这些数据对于文件系统来说都是至关重要的,它们是存取文件的基础。如果超级块和块组描述符的信息一旦出错,则会造成文件系统无法正常挂载的情况出现。造成这些信息出错的原因有:
- 系统管理员操作失误。
- 设备驱动程序或第三方软件(例如mke2fs之类的)有 bug。
- 电源意外断电。
- 内核有 bug。
如果出现这种问题,可能造成的后果有:
- 文件系统无法挂载。
- 操作系统挂起。
- 即使文件系统能够成功挂载,在系统重启时也可能会看到一些错误,或者目录列表中出现乱字符的情况等。
下面让我们来模拟一个出现这种错误的情况。我们知道,超级块信息就保存在分区中的第一个块中,现在我们来试验一下清空这个块中数据的后果:
清单9. 清空超级块信息的后果
# dd if=/dev/zero of=/dev/sda2 bs=4096 count=1 |
# mount /dev/sda2 /tmp/test -t ext2
mount: wrong fs type, bad option, bad superblock on /dev/sda2,
missing codepage or helper program, or other error
In some cases useful info is found in syslog - try
dmesg | tail or so
|
由于无法从磁盘上读取到有效的超级块信息,mount 命令已经无法挂载 /dev/sda2 设备上的文件系统了。
为了防止这个问题会造成严重的后果,ext2 文件系统会在每个块组中保存一份超级块的拷贝。当然,这会造成一定的空间浪费,因此在最新的 ext2 文件系统中,只是在特定的块组中保存一份超级块的拷贝。具体来说,是在第 0、1 个块组和第 3、5、7 的整数次幂个块组中保存一份超级块的拷贝,而其他块组中的空间都可以节省出来了。下面来看一个 20GB 大小的文件系统的实际例子:
清单10. ext2 文件系统中超级块拷贝的位置
# dumpe2fs /dev/sdb6 | grep -i superblock dumpe2fs 1.39 (29-May-2006) Primary superblock at 0, Group descriptors at 1-2 Backup superblock at 32768, Group descriptors at 32769-32770 Backup superblock at 98304, Group descriptors at 98305-98306 Backup superblock at 163840, Group descriptors at 163841-163842 Backup superblock at 229376, Group descriptors at 229377-229378 Backup superblock at 294912, Group descriptors at 294913-294914 Backup superblock at 819200, Group descriptors at 819201-819202 Backup superblock at 884736, Group descriptors at 884737-884738 Backup superblock at 1605632, Group descriptors at 1605633-1605634 Backup superblock at 2654208, Group descriptors at 2654209-2654210 Backup superblock at 4096000, Group descriptors at 4096001-4096002 |
这是一个 20GB 大的 ext2 文件系统,每个块组的大小是 32768 个块,超级块一共有 11 个拷贝,分别存储在第 0、1、3、5、7、9、25、27、49、81 和 125 个块组中。默认情况下,内核只会使用第一个超级块中的信息来对磁盘进行操作。在出现故障的情况下,就可以使用这些超级块的备份来恢复数据了。具体说来,有两种方法:首先 mount 命令可以使用 sb 选项指定备用超级块信息来挂载文件系统:
清单11. 使用超级块拷贝挂载文件系统
# mount -o sb=131072 /dev/sda2 /tmp/test -t ext2 |
需要注意的是,mount 命令中块大小是以 1024 字节为单位计算的,而这个文件系统则采用的是 4096 字节为单位的块,因此 sb 的值应该是 32768*4=131072。
尽管 mount 命令可以使用备用超级块来挂载文件系统,但却无法修复主超级块的问题,这需要使用 e2fsck 这个工具来完成:
清单12. 利用 e2fsck 工具修复 ext2 文件系统中主超级块的问题
# e2fsck /dev/sda2 e2fsck 1.40.2 (12-Jul-2007) Couldn't find ext2 superblock, trying backup blocks... /dev/sda2 was not cleanly unmounted, check forced. Pass 1: Checking inodes, blocks, and sizes Pass 2: Checking directory structure Pass 3: Checking directory connectivity Pass 4: Checking reference counts Pass 5: Checking group summary information /dev/sda2: ***** FILE SYSTEM WAS MODIFIED ***** /dev/sda2: 11/489600 files (9.1% non-contiguous), 17286/977956 blocks # mount /dev/sda2 /tmp/test -t ext2 |
e2fsck 工具可以检查出主超级块的问题,然后从其他超级块拷贝中读取数据,并使用它来恢复主超级块中的数据(在 ext2 文件系统中,超级块信息保存在一个 ext2_super_block 的数据结构中,详细信息请参考内核源代码)。修复主超级块的问题之后,mount 命令就可以成功挂载原来的文件系统了。
重建文件系统的解决办法
在日常使用过程中,可能碰到的另外一个问题是管理员可能错误地执行了某些命令,例如使用mke2fs 重建了文件系统,从而造成数据的丢失。实际上,在 mke2fs 创建文件系统的过程中,并不会真正去清空原有文件系统中存储的文件的数据,但却会重新生成超级块、块组描述符之类的信息,并清空索引节点位图和块位图中的数据,最为关键的是,它还会清空索引节点表中的数据。因此尽管文件数据依然存储在磁盘上,但是由于索引节点中存储的文件元数据已经丢失了,要想完整地恢复原有文件,已经变得非常困难了。
然而,这个问题也并非完全无法解决。在 e2fsprogs 包中还提供了一个名为 e2image 的工具,可以用来将 ext2 文件系统中的元数据保存到一个文件中,下面是一个例子:
清单13. 使用超级块拷贝挂载文件系统
# e2image -r /dev/sda2 sda2.e2image |
这会生成一个与文件系统大小相同的文件,其中包含了文件系统的元数据,包括索引节点中的间接块数据以及目录数据。另外,其中所有数据的位置均与磁盘上存储的位置完全相同,因此可以使用 debugfs、dumpe2fs 之类的工具直接查看:
清单14. 使用 debugfs 查看 e2image 映像文件的信息
# debugfs sda2.e2image.raw
debugfs 1.40.2 (12-Jul-2007)
debugfs: ls -l
2 40755 (2) 0 0 4096 31-Dec-2007 15:56 .
2 40755 (2) 0 0 4096 31-Dec-2007 15:56 ..
11 40700 (2) 0 0 16384 31-Dec-2007 15:54 lost+found
12 100644 (1) 0 0 10485760 31-Dec-2007 15:56 testfile.10M
13 100644 (1) 0 0 35840 31-Dec-2007 15:56 testfile.35K
|
为了节省空间,这些映像文件以稀疏文件的形式保存在磁盘上,在一个 4GB 的文件系统中,如果 55 万个索引节点中已经使用了 1 万 5 千个,使用 bizp2 压缩后的文件大概只有 3MB左右。
当然,这些映像文件中并没有包含实际文件的数据,不过文件数据依然保存在磁盘上,因此只要及时备份相关信息,在发生意外的情况下是有可能恢复大部分数据的。
磁盘坏道情况的处理
随着磁盘使用的时间越来越长,难免会出现磁盘上出现一些物理故障,比如产生物理坏道。根据物理损坏的严重程度,可能会造成文件丢失、文件系统无法加载甚至整个磁盘都无法识别的情况出现。因此要想将损失控制在最小范围内,除了经常备份数据,在发现问题的第一时间采取及时地应对措施也非常重要。
物理故障一旦出现,极有可能会有加剧趋势,因此应该在恢复数据的同时,尽量减少对磁盘的使用,dd 命令可以用来创建磁盘的完美映像。应该使用的命令如下:
清单15. 使用 dd 命令创建磁盘映像
# dd if=/dev/sdb of=/images/sdb.image bs=4096 conv=noerror,sync |
noerror 参数告诉 dd 在碰到读写错(可能是由于坏道引起的)时继续向下操作,而不是停止退出。sync 参数说明对于从源设备无法正常读取的块,就使用NULL填充。默认情况下,dd 使用 512 字节作为一个块的单位来读写 I/O 设备,指定 bs 为 4096 字节可以在一定程度上加速 I/O 操作,但同时也会造成一个问题:如果所读取的这个 4096 字节为单位的数据块中某一部分出现问题,则整个 4096 字节的就全部被清空了,这样会造成数据的丢失。为了解决这种问题,我们可以使用 dd_rescue 这个工具(可以从 http://www.garloff.de/kurt/linux/ddrescue/ 上下载),其用法如下:
清单16. 使用 dd_rescue 命令创建磁盘映像
# dd_rescue /dev/sdb /images/sdb.image –b 65536 –B 512 |
与 dd 相比,dd_rescue 强大之处在于在碰到错误时,可以以更小的数据块为单位重新读取这段数据,从而确保能够读出尽量多的数据。上面命令中的参数指明正常操作时以 64KB 为单位读取磁盘数据,一旦出错,则以 512 字节为单位重新读取这段数据,直至整个硬盘被完整读出为止。
获得磁盘映像之后,就可以将其当作普通磁盘一样进行操作了。应用本系列文章中介绍的技术,应该能从中恢复出尽可能多的数据。当然,对于那些刚好处于坏道位置的数据,那就实在回天乏力了。
恢复文件策略
截至到现在,本系列文章中介绍的都是在删除文件或出现意外情况之后如何恢复文件,实际上,对于保证数据可用性的目的来讲,这些方法都无非是亡羊补牢而已。制定恰当地数据备份策略,并及时备份重要数据才是真正的解决之道。
不过即使有良好的数据备份策略,也难免会出现有部分数据没有备份的情况。因此,一旦出现误删文件的情况,应该立即执行相应的对策,防止文件数据被覆盖:
- 断开所有对文件系统的访问。fuser 命令可以用来帮助查看和杀死相关进程,详细用法请参看 fuser 的手册。
- 如果业务无法停顿,就将文件系统以只读方式重新加载,命令格式为:mount -r -n -o remount mountpoint
- 应用本系列文章介绍的技术恢复文件。
当然,在进行数据备份的同时,也需要考虑本文中介绍的一些技术本身的要求,例如 e2image映像文件、e2undel 的日志文件等,都非常重要,值得及时备份。
小结
本文介绍了一个功能非常强大的工具 e2undel,可以用来方便地恢复已删除的文件。然后讨论了文件系统故障、文件系统重建、磁盘物理损坏等情况下应该如何恢复数据。随着文件系统的不断发展,Linux 上常用的文件系统也越来越多,例如 ext3/ext4/reiserfs/jfs 等,这些文件系统上删除的文件能否成功恢复呢?有哪些工具可以用来辅助恢复文件呢?本系列后续文章将继续探讨这个问题。
作为 ext2 文件系统的后继者,ext3 文件系统由于日志的存在,使其可用性大大增加。尽管 ext3 文件系统可以完全兼容 ext2 文件系统,但是由于关键的一点区别却使得在 ext3 上恢复删除文件变得异常困难。本文将逐渐探讨其中的原因,并给出了三种解决方案:正文匹配,元数据备份,以及修改 ext3 的实现。
本系列文章的前 3 部分详细介绍了 ext2 文件系统中文件的数据存储格式,并讨论了各种情况下数据恢复的问题。作为 ext2 文件系统的后继者,ext3 文件系统可以实现与 ext2 文件系统近乎完美的兼容。但是前文中介绍的各种技术在 ext3 文件系统中是否同样适用呢?ext3 文件系统中删除文件的恢复又有哪些特殊之处呢?本文将逐一探讨这些问题。
ext3:日志文件系统
由于具有很好的文件存取性能,ext2 文件系统自从 1993 年发布之后,已经迅速得到了用户的青睐,成为很多 Linux 发行版中缺省的文件系统,原因之一在于 ext2 文件系统采用了文件系统缓存的概念,可以加速文件的读写速度。然而,如果文件系统缓存中的数据尚未写入磁盘,机器就发生了掉电等意外状况,就会造成磁盘数据不一致的状态,这会损坏磁盘数据的完整性(文件数据与元数据不一致),严重情况下甚至会造成文件系统的崩溃。
为了确保数据的完整性,在系统引导时,会自动检查文件系统上次是否是正常卸载的。如果是非正常卸载,或者已经使用到一定的次数,就会自动运行 fsck 之类的程序强制进行一致性检查(具体例子请参看本系列文章的第 2 部分),并修复存在问题的地方,使 ext2 文件系统恢复到新的一致状态。
然而,随着硬盘技术的发展,磁盘容量变得越来越大,对磁盘进行一致性检查可能会占用很长时间,这对于一些关键应用来说是不可忍受的;于是日志文件系统(Journal File System)的概念也就应运而生了。
所谓日志文件系统,就是在文件系统中借用了数据库中“事务”(transaction)的概念,将文件的更新操作变成原子操作。具体来说,就是在修改文件系统内容的同时(或之前),将修改变化记录到日志中,这样就可以在意外发生的情况下,就可以根据日志将文件系统恢复到一致状态。这些操作完全可以在重新挂载文件系统时来完成,因此在重新启动机器时,并不需要对文件系统再进行一致性检查,这样可以大大提高系统的可用程度。
Linux 系统中目前已经出现了很多日志文件系统,例如 SGI 开发的 XFS、IBM 开发的 JFS 和 ReiserFS 以及 ext3 等。与其他日志文件系统相比,ext3 最大的特性在于它完全兼容 ext2 文件系统。用户可以在 ext2 和 ext3 文件系统之间无缝地进行变换,二者在磁盘上采用完全相同的的数据格式进行存储,因此大部分支持 ext2 文件系统的工具也都可以在 ext3 文件系统上使用。甚至为 ext2 开发的很多特性也都可以非常平滑地移植到 ext3 文件系统上来。ext3 文件系统的另外一个特性在于它提供了 3 种日志模式,可以满足各种不同用户的要求:
- data=journal:这会记录对所有文件系统数据和元数据的修改。这种模式可以将数据丢失的风险降至最低,但是速度也最慢。
- data=ordered:仅仅记录对文件系统元数据的修改,但是在修改相关文件系统元数据之前,需要将文件数据同步到磁盘上。
- data=writeback:仅仅记录对文件系统元数据的修改,对文件数据的修改按照标准文件系统的写操作过程进行处理。这种模式速度最快。
在重新挂载文件系统时,系统会自动检查日志项,将尚未提交到磁盘上的操作重新写入磁盘,从而确保文件系统的状态与最后一次操作的结果保持一致。
ext3 文件系统探索
下面让我们通过一个例子来了解一下 ext3 文件系统中有关日志的一些详细信息。
清单1. 创建 ext3 文件系统
# mkfs.ext3 /dev/sdb7
mke2fs 1.39 (29-May-2006)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
2443200 inodes, 4885760 blocks
244288 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=0
150 block groups
32768 blocks per group, 32768 fragments per group
16288 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000
Writing inode tables: done
Creating journal (32768
blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 27 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
|
在清单 1 中,我们使用 mkfs.ext3 创建了一个 ext3 类型的文件系统,与 ext2 文件系统相比,mkfs.ext3 命令额外在文件系统中使用 32768 个数据块创建了日志。实际上,ext2 文件系统可以使用 tune2fs 命令平滑地转换成 ext3 文件系统,用法如清单 2 所示。
清单2. 使用 tune2fs 将 ext2 文件系统转换成 ext3 文件系统 # tune2fs -j /dev/sdb6 tune2fs 1.39 (29-May-2006) Creating journal inode: done This filesystem will be automatically checked every 28 mounts or 180 days, whichever comes first. Use tune2fs -c or -i to override. |
类似地,dumpe2fs 命令也可以用来查看有关 ext3 文件系统的信息:
清单3. 使用 dumpe2fs 查看 ext3 文件系统的信息 # dumpe2fs /dev/sdb7 | grep "Group 0" -B 10 -A 21 dumpe2fs 1.39 (29-May-2006) Reserved blocks gid: 0 (group root) First inode: 11 Inode size: 128 Journal inode: 8 Default directory hash: tea Directory Hash Seed: 69de4e53-27fc-42db-a9ea-36debd6e68de Journal backup: inode blocks Journal size: 128M Group 0: (Blocks 0-32767) Primary superblock at 0, Group descriptors at 1-2 Reserved GDT blocks at 3-1024 Block bitmap at 1025 (+1025), Inode bitmap at 1026 (+1026) Inode table at 1027-1535 (+1027) 0 free blocks, 16277 free inodes, 2 directories Free blocks: Free inodes: 12-16288 Group 1: (Blocks 32768-65535) Backup superblock at 32768, Group descriptors at 32769-32770 Reserved GDT blocks at 32771-33792 Block bitmap at 33793 (+1025), Inode bitmap at 33794 (+1026) Inode table at 33795-34303 (+1027) 29656 free blocks, 16288 free inodes, 0 directories Free blocks: 35880-65535 Free inodes: 16289-32576 Group 2: (Blocks 65536-98303) Block bitmap at 65536 (+0), Inode bitmap at 65537 (+1) Inode table at 65538-66046 (+2) 32257 free blocks, 16288 free inodes, 0 directories Free blocks: 66047-98303 Free inodes: 32577-48864 |
从清单 3 中的输出结果可以看出,这个文件系统上的日志一共占用了 128MB 的空间,日志文件使用索引节点号为 8,块组 0 和块组 1 中空闲块比其他块组明显要少,这是因为日志文件主要就保存在这两个块组中了,这一点可以使用 debugfs 来验证:
清单4. 查看日志文件的信息 # debugfs /dev/sdb7 debugfs 1.39 (29-May-2006) debugfs: stat <8> Inode: 8 Type: regular Mode: 0600 Flags: 0x0 Generation: 0 User: 0 Group: 0 Size: 134217728 File ACL: 0 Directory ACL: 0 Links: 1 Blockcount: 262416 Fragment: Address: 0 Number: 0 Size: 0 ctime: 0x4795d200 -- Tue Jan 22 19:22:40 2008 atime: 0x00000000 -- Thu Jan 1 08:00:00 1970 mtime: 0x4795d200 -- Tue Jan 22 19:22:40 2008 BLOCKS: (0-11):1542-1553, (IND):1554, (12-1035):1555-2578, (DIND):2579, / (IND):2580, (1036-2059):2581-3604, (IND):3605, (2060-3083):3606-4629 , (IND):4630, (3084-4107):4631-5654, (IND):5655, (4108-5131):5656-6679, / (IND):6680, (5132-6155):6681-7704, (IND):7705, (6156-7179):7 706-8729, (IND):8730, (7180-8203):8731-9754, (IND):9755, (8204-9227):9756-10779, / (IND):10780, (9228-10251):10781-11804, (IND):11805, (10252-11275):11806-12829, (IND):12830, (11276-12299):12831-13854, / (IND):13855, (12300-13323):13856-14879, (IND):14880, (13324-1434 7):14881-15904, (IND):15905, (14348-15371):15906-16929, / (IND):16930, (15372-16395):16931-17954, (IND):17955, (16396-17419):17956-189 79, (IND):18980, (17420-18443):18981-20004, (IND):20005, (18444-19467):20006-21029, / (IND):21030, (19468-20491):21031-22054, (IND):22 055, (20492-21515):22056-23079, (IND):23080, (21516-22539):23081-24104, / (IND):24105, (22540-23563):24106-25129, (IND):25130, (23564- 24587):25131-26154, (IND):26155, (24588-25611):26156-27179, / (IND):27180, (25612-26635):27181-28204, (IND):28205, (26636-27659):28206 -29229, (IND):29230, (27660-28683):29231-30254, (IND):30255, / (28684-29707):30256-31279, (IND):31280, (29708-30731):31281-32304, (IND ):32305, (30732-31193):32306-32767, (31194-31755):34304-34865, / (IND):34866, (31756-32768):34867-35879 TOTAL: 32802 debugfs:. |
另外,ext3 的日志文件也可以单独存储到其他设备上。但是无论如何,这对于用户来说都是透明的,用户根本就觉察不到日志文件的存在,只是内核在挂载文件系统时会检查日志文件的内容,并采取相应的操作,使文件系统恢复到最后一次操作时的一致状态。
对于恢复删除文件的目的来说,我们并不需要关心日志文件,真正应该关心的是文件在磁盘上的存储格式。实际上,ext3 在这方面完全兼容 ext2,以存储目录项和索引节点使用的数据结构为例,ext3 使用的两个数据结构 ext3_dir_entry_2 和 ext3_inode 分别如清单 5 和清单 6 所示。与 ext2 的数据结构对比一下就会发现,二者并没有什么根本的区别,这正是 ext2 和 ext3 文件系统可以实现自由转换的基础。
清单5. ext3_dir_entry_2 结构
/*
* The new version of the directory entry. Since EXT3 structures are
* stored in intel byte order, and the name_len field could never be
* bigger than 255 chars, it's safe to reclaim the extra byte for the
* file_type field.
*/
struct ext3_dir_entry_2 {
__le32 inode; /* Inode number */
__le16 rec_len; /* Directory entry length */
__u8 name_len; /* Name length */
__u8 file_type;
char name[EXT3_NAME_LEN]; /* File name */
};
|
/*
* Structure of an inode on the disk
*/
struct ext3_inode {
__le16 i_mode; /* File mode */
__le16 i_uid; /* Low 16 bits of Owner Uid */
__le32 i_size; /* Size in bytes */
__le32 i_atime; /* Access time */
__le32 i_ctime; /* Creation time */
__le32 i_mtime; /* Modification time */
__le32 i_dtime; /* Deletion Time */
__le16 i_gid; /* Low 16 bits of Group Id */
__le16 i_links_count; /* Links count */
__le32 i_blocks; /* Blocks count */
__le32 i_flags; /* File flags */
...
__le32 i_block[EXT3_N_BLOCKS];/* Pointers to blocks */
...
};
|
既然 ext3 与 ext2 文件系统有这么好的兼容性和相似性,这是否就意味着本系列文章前 3 部分介绍的各种技术同样也适用于 ext3 文件系统呢?对于大部分情况来说,答案是肯定的。ext3 与 ext2 文件系统存储文件所采用的机制并没有什么不同,第 1 部分中介绍的原理以及后续介绍的 debugfs 等工具也完全适用于 ext3 文件系统。
然而,这并非就说 ext3 与 ext2 文件系统是完全相同的。让我们来看一个例子:清单 7 给出了在 ext3 文件系统中删除一个文件前后索引节点的变化。
清单7. ext3 文件系统中删除文件前后索引节点信息的变化 # debugfs /dev/sdb7 debugfs 1.39 (29-May-2006) debugfs: stat <48865> Inode: 48865 Type: regular Mode: 0644 Flags: 0x0 Generation: 3736765465 User: 0 Group: 0 Size: 61261 File ACL: 99840 Directory ACL: 0 Links: 1 Blockcount: 136 Fragment: Address: 0 Number: 0 Size: 0 ctime: 0x478618e1 -- Thu Jan 10 21:08:49 2008 atime: 0x478618e1 -- Thu Jan 10 21:08:49 2008 mtime: 0x478618e1 -- Thu Jan 10 21:08:49 2008 BLOCKS: (0-11):129024-129035, (IND):129036, (12-14):129037-129039 TOTAL: 16 debugfs: q # rm -f Home.html # sync # cd .. # umount test # debugfs /dev/sdb7 debugfs 1.39 (29-May-2006) debugfs: lsdel Inode Owner Mode Size Blocks Time deleted 0 deleted inodes found. debugfs: stat <48865> Inode: 48865 Type: regular Mode: 0644 Flags: 0x0 Generation: 3736765465 User: 0 Group: 0 Size: 0 File ACL: 99840 Directory ACL: 0 Links: 0 Blockcount: 0 Fragment: Address: 0 Number: 0 Size: 0 ctime: 0x47861900 -- Thu Jan 10 21:09:20 2008 atime: 0x478618e1 -- Thu Jan 10 21:08:49 2008 mtime: 0x47861900 -- Thu Jan 10 21:09:20 2008 dtime: 0x47861900 -- Thu Jan 10 21:09:20 2008 BLOCKS: debugfs: q |
仔细看一下结果就会发现,在删除文件之后,除了设置了删除时间 dtime 之外,还将文件大小(size)设置为 0,占用块数(Blockcount)也设置为 0,并清空了存储文件数据的数据(i_block 数组)。这正是 ext3 文件系统与 ext2 文件系统在删除文件时最重要的一点的区别:在删除文件时,对于 ext2 文件系统来说,操作系统只是简单地修改对应索引节点中的删除时间,并修改索引节点位图和数据块位图中的标志,表明它们已经处于空闲状态,可以被重新使用;而对于 ext3 文件系统来说,还清除了表明数据块存放位置的字段(i_block),并将索引节点中的文件大小信息设置为 0。然而,这点区别对于恢复被删除文件的用途来说却是至关重要的,因为缺少了文件大小和数据块位置的信息,尽管文件数据依然完好地保存在磁盘上,但却没有任何一条清晰的线索能够说明这个文件的数据块被存储到哪些磁盘块中,以及这些数据块的相互顺序如何,文件中间是否存在文件洞等信息,因此要想完整地恢复文件就变得非常困难了。这也正是使用 debugfs 的 dump 命令在 ext3 文件系统中并不能恢复已删除文件的原因。
不过,这是否就意味着 ext3 文件系统中删除的文件就无法恢复了呢?其实不然。基于这样一个事实:“在删除文件时,并不会将文件数据真正从磁盘上删除”,我们可以采用其他一些方法来尝试恢复数据。
ext3 文件系统中恢复删除文件的方法 1:正文匹配
我们知道,磁盘以及磁盘上的某个分区在系统中都以设备文件的形式存在,我们可以将这些设备文件当作普通文件一样来读取数据。不过,既然已经无法通过文件名来定位文件的数据块位置,现在要想恢复文件,就必须了解文件的数据,并通过正文匹配进行检索了。自然,grep 就是这样一个理想的工具:
清单8. 使用 grep 搜索磁盘上的文件 # ./creatfile.sh 35 testfile.35K # rm -f testfile.35K # cd .. # umount test # grep -A 1 -B 1 -a -n " 10:0" /dev/sdb7 > sdb7.testfile.35K grep: memory exhausted # cat sdb7.testfile.35K 545- 9:0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 546: 10:0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 547- 11:0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ, |
在清单 8 中的例子中,我们首先使用本系列文章第 1 部分中提供的脚本创建了一个测试文件,在删除该文件后,通过利用 grep 以“ 10:0”作为关键字对设备文件进行正文匹配,我们顺利地找到了测试文件中的第 10 行数据。需要注意的是,grep 命令中我们使用了几个参数,-a 参数表明将设备文件当作文本文件进行处理,-B 和 –A 参数分别说明同时打印匹配项的前/后几行的数据。同一关键字可能会在很多文件中多次出现,因此如何从中挑选出所需的数据就完全取决于对数据的熟悉程度了。
利用 grep 进行正文匹配也存在一个问题,由于打开的设备文件非常大,grep 会产生内存不足的问题,因此无法完成整个设备的正文匹配工作。解决这个问题的方法是使用 strings。strings 命令可以将文件中所有可打印字符全部打印出来,因此对于正文匹配的目的来说,它可以很好地实现文本数据的提取工作。
清单9. 使用 strings 提取设备文件中的可打印数据
# time strings /dev/sdb7 > sdb7.strings
real 12m42.386s
user 10m44.140s
sys 1m42.950s
# grep " 10:0" sdb7.strings
10:0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ,
0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ,
0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ,
0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ,
0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ,
0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ,
0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ,
0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ,
0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ,
0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ,
0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ,
0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ,
0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ,
0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ,
0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ,
0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ,
|
清单 9 中的例子使用 strings 将 /dev/sdb7 中的可打印字符提取出来,并重定向到一个文本文件中,此后就可以使用任何文本编辑工具或正文匹配工具从这个文件中寻找自己的数据了。不过扫描磁盘需要的时间可能会比较长,在上面这个例子中,扫描 20GB 的分区大概需要 13 分钟。
ext3 文件系统中恢复删除文件的方法 2:提前备份元数据
利用 grep 或 strings 对磁盘数据进行正文匹配,这种方法有一定的局限性:它只是对文本文件的恢复比较有用,这还要依赖于用户对数据的熟悉程度;而对于二进制文件来说,除非有其他备份,否则要通过这种正文匹配的方式来恢复文件,几乎是不可能完成的任务。然而,如果没有其他机制的辅助,在 ext3 文件系统中,这却几乎是唯一可以尝试用来恢复数据的方法了。究其原因是因为,这种方法仅仅是一种亡羊补牢的做法,而所需要的一些关键数据已经不存在了,因此恢复文件就变得愈发困难了。不过,索引节点中的这些关键信息在删除文件之前肯定是存在的。
受本系列文章介绍过的 debugfs 和 libundel 的启发,我们可以对 libundel 进行扩充,使其在删除文件的同时,除了记录文件名、磁盘设备、索引节点信息之外,把文件大小、数据块位置等重要信息也同时记录下来,这样就可以根据日志文件中的元数据信息完美地恢复文件了。
为了实现以上想法,我们需要对 libundel 的实现进行很大的调整,下面介绍所使用的几个关键的函数。
清单10. get_bmap 函数的实现
static unsigned long get_bmap(int fd, unsigned long block)
{
int ret;
unsigned int b;
b = block;
ret = ioctl(fd, FIBMAP, &b); /* FIBMAP takes a pointer to an integer */
if (ret < 0)
{
if (errno == EPERM)
{
if (f)
{
{ /* don't log deleted symlinks */
fprintf(f, "No permission to use FIBMAP ioctl./n");
fflush(f);
}
} /* if (f) */
return 0;
}
}
return b;
}
|
get_bmap 函数是整个改进的基础,其作用是返回磁盘上保存指定文件的某块数据使用的数据块的位置,这是通过 ioctl 的 FIBMAP 命令来实现的。ioctl 提供了一种在用户空间与内核进行交互的便捷机制,在内核中会通过调用 f_op->ioctl() 进行处理。对于 FIBMAP 命令来说,会由 VFS 调用 f_op->bmap() 获取指定数据块在磁盘上的块号,并将结果保存到第 3 个参数指向的地址中。
清单11. get_blocks 函数的实现
int get_blocks(const char *filename)
{
#ifdef HAVE_FSTAT64
struct stat64 fileinfo;
#else
struct stat fileinfo;
#endif
int bs;
long fd;
unsigned long block, last_block = 0, first_cblock = 0, numblocks, i;
long bpib; /* Blocks per indirect block */
char cblock_list[256];
char pwd[PATH_MAX];
if (NULL != filename)
{
if (__lxstat(3, filename, &fileinfo))
fileinfo.st_ino = 0;
if (!realpath(filename, pwd))
pwd[0] = '/0';
}
#ifdef HAVE_OPEN64
fd = open64(filename, O_RDONLY);
#else
fd = open(filename, O_RDONLY);
#endif
if (fd < 0) {
fprintf(stderr, "cannot open the file of %s/n", filename);
return -1;
}
if (ioctl(fd, FIGETBSZ, &bs) < 0) { /* FIGETBSZ takes an int */
perror("FIGETBSZ");
close(fd);
return -1;
}
bpib = bs / 4;
numblocks = (fileinfo.st_size + (bs-1)) / bs;
sprintf(block_list, "%ld,%ld::%ld::%ld::%ld::",
(long) (fileinfo.st_dev & 0xff00) / 256,
(long) fileinfo.st_dev & 0xff,
(long) fileinfo.st_ino,
(long) fileinfo.st_size, (long)bs);
for (i=0; i < numblocks; i++) {
block = get_bmap(fd, i);
if (last_block == 0) {
first_cblock = block;
}
if (last_block && (block != last_block +1) ) {
sprintf(cblock_list, "(%ld-%ld):%ld-%ld,",
i-(last_block-first_cblock)-1, i-1, first_cblock, last_block);
strcat(block_list, cblock_list);
first_cblock = block;
}
if (i == numblocks - 1 ) {
if (last_block == 0) {
sprintf(cblock_list, "(%ld-%ld):%ld-%ld", i, i, first_cblock, block);
}
else {
sprintf(cblock_list, "(%ld-%ld):%ld-%ld",
i-(last_block-first_cblock)-1, i, first_cblock, block);
}
strcat(block_list, cblock_list);
}
last_block = block;
}
sprintf(cblock_list, "::%s", pwd[0] ? pwd : filename);
strcat(block_list, cblock_list);
close(fd);
return 0;
}
|
get_blocks 函数的作用是遍历文件包含的每个数据块,获取它们在磁盘上保存的数据块位置。为了保证日志文件中的数据尽量精简,数据块位置会按照本身的连续情况被划分成一个个的连续块域,每个都记录为下面的形式:(文件中的起始块号-文件中的结束块号):磁盘上的起始数据块号-磁盘上的结束数据块号。
自然,get_blocks 函数应该是在用户调用删除文件的系统调用时被调用的,这些系统调用的实现也应该进行修改。清单 12 给出了 remove 库函数修改后的例子。
清单12. remove 库函数的实现
int remove(const char *pathname)
{
int err;
int (*removep)(char *) = dlsym(RTLD_NEXT, "remove");
err = get_blocks(pathname);
if (err < 0)
{
fprintf(stderr, "error while reading blocks from %s/n", pathname);
}
err = (*removep)((char *) pathname);
if (err) return err; /* remove() did not succeed */
if (f)
{
fprintf(f, "%s/n", block_list);
fflush(f);
} /* if (f) */
return err;
} /* remove() */
|
现在,记录元数据信息的日志文件 /var/e2undel/e2undel 如清单 13 所示:
清单13. 修改后的 /var/e2undel/e2undel 样例文件 8,23::48865::13690::4096::(0-3):106496-106499::/tmp/test/apprentice.c 8,23::48867::19665::4096::(0-4):106528-106532::/tmp/test/ascmagic.c 8,23::48872::1036::4096::(0-0):106545-106545::/tmp/test/compactlog.c 8,23::48875::31272::4096::(0-7):106596-106603::/tmp/test/e2undel.c 8,23::48878::1077::4096::(0-0):106616-106616::/tmp/test/file.c 8,23::48880::4462::4096::(0-1):106618-106619::/tmp/test/find_del.c 8,23::48885::2141::4096::(0-0):106628-106628::/tmp/test/is_tar.c 8,23::48887::6540::4096::(0-1):106631-106632::/tmp/test/libundel.c 8,23::48890::8983::4096::(0-2):106637-106639::/tmp/test/log.c 8,23::48897::13117::4096::(0-3):106663-106666::/tmp/test/softmagic.c 8,23::48866::10485760::4096::(0-11):108544-108555,(12-1035):108557-109580,/ (1036-2059):109583-110606,(2060-2559):110608-111107::/tmp/test/testfile.10M 8,23::48866::7169::4096::(1-1):129024-129024::/tmp/test/hole 8,23::48865::21505::4096::(1-1):129025-129025,(5-5):129026-129026::/tmp/test/hole2 |
文件名前所增加的 3 项分别为文件大小、块大小和数据块列表。
当然,为了能够利用 /var/e2undel/e2undel 中记录的信息恢复文件,e2undel 的对应实现也必须相应地进行修改。详细实现请参看本文下载部分给出的补丁,在此不再详述。修改后的 libundel 的用法与原来完全相同,详细介绍请参看本系列文章的第 3 部分。
ext3 文件系统中恢复删除文件的方法 3:修改 ext3 实现
利用 libundel 方法的确可以完美地恢复删除文件,但是这毕竟是一种治标不治本的方法,就像是本系列文章第 3 部分中所介绍的一样,这要依赖于环境变量 LD_PRELOAD 的设置。如果用户在删除文件之前,并没有正确设置这个环境变量,那么对应的删除操作就不会记录到日志文件 /var/e2undel/e2undel 中,因此也就无从恢复文件了。
还记得在本系列文章的第 2 部分中我们是如何通过修改 Linux 内核来支持大文件的删除的 吗?采用同样的思路,我们也可以修改 ext3 的实现,使其支持文件的恢复,这样本系列前面文章中介绍的工具就都可以在 ext3 文件系统上正常使用了。
总结一下,在删除文件时,内核中执行的操作至少包括:
- 在块位图中将该文件所占用的数据块标识为可用状态。
- 在索引节点位图中将该文件所占用的索引节点标识为可用状态。
- 将该文件索引节点中的硬链接数目设置为 0。
- 清空间接索引节点中的数据.
- 清空 i_block 数组中各个成员中的数据。
- 将索引节点中的文件大小(i_size)和占用块数(i_blocks)设置为 0。
- 将该文件索引节点中的删除时间设置为当前时间。
- 将父目录项中该文件对应项中的索引节点号设置为 0,并扩展前一项,使其包含该项所占用的空间。
其中步骤 5 和 6 只适用于 ext3 文件系统,在 ext2 文件系统中并不需要执行。在 ext3 文件系统的实现中,它们分别是由 fs/ext3/inode.c 中的 ext3_delete_inode 和 ext3_truncate 函数实现的:
清单14. ext3_delete_inode 函数实现
182 void ext3_delete_inode (struct inode * inode)
183 {
184 handle_t *handle;
185
186 truncate_inode_pages(&inode->i_data, 0);
187
188 if (is_bad_inode(inode))
189 goto no_delete;
190
191 handle = start_transaction(inode);
192 if (IS_ERR(handle)) {
193 /*
194 * If we're going to skip the normal cleanup, we still need to
195 * make sure that the in-core orphan linked list is properly
196 * cleaned up.
197 */
198 ext3_orphan_del(NULL, inode);
199 goto no_delete;
200 }
201
202 if (IS_SYNC(inode))
203 handle->h_sync = 1;
204 inode->i_size = 0;
205 if (inode->i_blocks)
206 ext3_truncate(inode);
207 /*
208 * Kill off the orphan record which ext3_truncate created.
209 * AKPM: I think this can be inside the above `if'.
210 * Note that ext3_orphan_del() has to be able to cope with the
211 * deletion of a non-existent orphan - this is because we don't
212 * know if ext3_truncate() actually created an orphan record.
213 * (Well, we could do this if we need to, but heck - it works)
214 */
215 ext3_orphan_del(handle, inode);
216 EXT3_I(inode)->i_dtime = get_seconds();
217
218 /*
219 * One subtle ordering requirement: if anything has gone wrong
220 * (transaction abort, IO errors, whatever), then we can still
221 * do these next steps (the fs will already have been marked as
222 * having errors), but we can't free the inode if the mark_dirty
223 * fails.
224 */
225 if (ext3_mark_inode_dirty(handle, inode))
226 /* If that failed, just do the required in-core inode clear. */
227 clear_inode(inode);
228 else
229 ext3_free_inode(handle, inode);
230 ext3_journal_stop(handle);
231 return;
232 no_delete:
233 clear_inode(inode); /* We must guarantee clearing of inode... */
234 }
|
2219 void ext3_truncate(struct inode *inode)
2220 {
2221 handle_t *handle;
2222 struct ext3_inode_info *ei = EXT3_I(inode);
2223 __le32 *i_data = ei->i_data;
2224 int addr_per_block = EXT3_ADDR_PER_BLOCK(inode->i_sb);
2225 struct address_space *mapping = inode->i_mapping;
2226 int offsets[4];
2227 Indirect chain[4];
2228 Indirect *partial;
2229 __le32 nr = 0;
2230 int n;
2231 long last_block;
2232 unsigned blocksize = inode->i_sb->s_blocksize;
2233 struct page *page;
2234
...
2247 if ((inode->i_size & (blocksize - 1)) == 0) {
2248 /* Block boundary? Nothing to do */
2249 page = NULL;
2250 } else {
2251 page = grab_cache_page(mapping,
2252 inode->i_size >> PAGE_CACHE_SHIFT);
2253 if (!page)
2254 return;
2255 }
2256
2257 handle = start_transaction(inode);
2258 if (IS_ERR(handle)) {
2259 if (page) {
2260 clear_highpage(page);
2261 flush_dcache_page(page);
2262 unlock_page(page);
2263 page_cache_release(page);
2264 }
2265 return; /* AKPM: return what? */
2266 }
2267
2268 last_block = (inode->i_size + blocksize-1)
2269 >> EXT3_BLOCK_SIZE_BITS(inode->i_sb);
2270
2271 if (page)
2272 ext3_block_truncate_page(handle, page, mapping, inode->i_size);
2273
2274 n = ext3_block_to_path(inode, last_block, offsets, NULL);
2275 if (n == 0)
2276 goto out_stop; /* error */
...
2287 if (ext3_orphan_add(handle, inode))
2288 goto out_stop;
2289
...
2297 ei->i_disksize = inode->i_size;
...
2303 mutex_lock(&ei->truncate_mutex);
2304
2305 if (n == 1) { /* direct blocks */
2306 ext3_free_data(handle, inode, NULL, i_data+offsets[0],
2307 i_data + EXT3_NDIR_BLOCKS);
2308 goto do_indirects;
2309 }
2310
2311 partial = ext3_find_shared(inode, n, offsets, chain, &nr);
2312 /* Kill the top of shared branch (not detached) */
2313 if (nr) {
2314 if (partial == chain) {
2315 /* Shared branch grows from the inode */
2316 ext3_free_branches(handle, inode, NULL,
2317 &nr, &nr+1, (chain+n-1) - partial);
2318 *partial->p = 0;
2319 /*
2320 * We mark the inode dirty prior to restart,
2321 * and prior to stop. No need for it here.
2322 */
2323 } else {
2324 /* Shared branch grows from an indirect block */
2325 BUFFER_TRACE(partial->bh, "get_write_access");
2326 ext3_free_branches(handle, inode, partial->bh,
2327 partial->p,
2328 partial->p+1, (chain+n-1) - partial);
2329 }
2330 }
2331 /* Clear the ends of indirect blocks on the shared branch */
2332 while (partial > chain) {
2333 ext3_free_branches(handle, inode, partial->bh, partial->p + 1,
2334 (__le32*)partial->bh->b_data+addr_per_block,
2335 (chain+n-1) - partial);
2336 BUFFER_TRACE(partial->bh, "call brelse");
2337 brelse (partial->bh);
2338 partial--;
2339 }
2340 do_indirects:
2341 /* Kill the remaining (whole) subtrees */
2342 switch (offsets[0]) {
2343 default:
2344 nr = i_data[EXT3_IND_BLOCK];
2345 if (nr) {
2346 ext3_free_branches(handle, inode, NULL, &nr, &nr+1, 1);
2347 i_data[EXT3_IND_BLOCK] = 0;
2348 }
2349 case EXT3_IND_BLOCK:
2350 nr = i_data[EXT3_DIND_BLOCK];
2351 if (nr) {
2352 ext3_free_branches(handle, inode, NULL, &nr, &nr+1, 2);
2353 i_data[EXT3_DIND_BLOCK] = 0;
2354 }
2355 case EXT3_DIND_BLOCK:
2356 nr = i_data[EXT3_TIND_BLOCK];
2357 if (nr) {
2358 ext3_free_branches(handle, inode, NULL, &nr, &nr+1, 3);
2359 i_data[EXT3_TIND_BLOCK] = 0;
2360 }
2361 case EXT3_TIND_BLOCK:
2362 ;
2363 }
2364
2365 ext3_discard_reservation(inode);
2366
2367 mutex_unlock(&ei->truncate_mutex);
2368 inode->i_mtime = inode->i_ctime = CURRENT_TIME_SEC;
2369 ext3_mark_inode_dirty(handle, inode);
2370
2371 /*
2372 * In a multi-transaction truncate, we only make the final transaction
2373 * synchronous
2374 */
2375 if (IS_SYNC(inode))
2376 handle->h_sync = 1;
2377 out_stop:
2378 /*
2379 * If this was a simple ftruncate(), and the file will remain alive
2380 * then we need to clear up the orphan record which we created above.
2381 * However, if this was a real unlink then we were called by
2382 * ext3_delete_inode(), and we allow that function to clean up the
2383 * orphan info for us.
2384 */
2385 if (inode->i_nlink)
2386 ext3_orphan_del(handle, inode);
2387
2388 ext3_journal_stop(handle);
2389 }
|
清单 14 和 15 列出的 ext3_delete_inode 和 ext3_truncate 函数实现中,使用黑体标出了与前面提到的问题相关的部分代码。本文下载部分给出的针对 ext3 文件系统的补丁中,包括了对这些问题的一些修改。清单 16 给出了使用这个补丁之后在 ext3 文件系统中删除文件的一个例子。
清单16. 利用 debugfs 工具查看删除文件的信息 # ./creatfile.sh 90 testfile.90K # ls -li total 116 12 -rwxr-xr-x 1 root root 1407 2008-01-23 07:25 creatfile.sh 11 drwx------ 2 root root 16384 2008-01-23 07:23 lost+found 13 -rw-r--r-- 1 root root 92160 2008-01-23 07:25 testfile.90K # rm -f testfile.90K # cd .. # umount /tmp/test # debugfs /dev/sda3 debugfs 1.40.2 (12-Jul-2007) debugfs: lsdel Inode Owner Mode Size Blocks Time deleted 0 deleted inodes found. debugfs: stat <13> Inode: 13 Type: regular Mode: 0644 Flags: 0x0 Generation: 3438957668 User: 0 Group: 0 Size: 92160 File ACL: 0 Directory ACL: 0 Links: 1 Blockcount: 192 Fragment: Address: 0 Number: 0 Size: 0 ctime: 0x47967b69 -- Wed Jan 23 07:25:29 2008 atime: 0x47967b68 -- Wed Jan 23 07:25:28 2008 mtime: 0x47967b69 -- Wed Jan 23 07:25:29 2008 BLOCKS: (0-11):22528-22539, (IND):22540, (12-22):22541-22551 TOTAL: 24 debugfs: |
在清单 16 中,我们首先创建了一个大小为 90KB 的测试文件,删除该文件并使用 debugfs 查看对应的设备文件时,stat <13> 显示的信息说明数据块的位置信息都仍然保存在了索引节点中,不过 lsdel 命令并未找到这个索引节点。因此下载部分中给出的补丁尚不完善,感兴趣的读者可以自行开发出更加完善的补丁。
小结
本文首先介绍了 ext3 文件系统作为一种日志文件系统的一些特性,然后针对这些特性介绍了 3 种恢复删除文件的方法:正文匹配、利用 libundel 和修改内核中 ext3 文件系统的实现,并给出了对 libundel 和 ext3 文件系统实现的补丁程序。应用本文介绍的方法,读者可以最大程度地恢复 ext3 文件系统中删除的文件。本系列的后续文章将继续探讨在其他文件系统上如何恢复已删除的文件,并着手设计更加通用的文件备份方法。
为了支持更大的文件系统,ext4 对 ext3 的现有实现进行了一系列扩充,使用 48 位的块号来增大块号寻址范围,并采用 extent 的设计来简化对数据块的索引,这势必会影响到磁盘数据结构的变化,以及删除文件的恢复。本文将逐一介绍 ext4 在对大文件系统支持方面所采用的全新设计,并探讨 ext4 文件系统中文件的删除和恢复的相关技术。
ext3 自从诞生之日起,就由于其可靠性好、特性丰富、性能高、版本间兼容性好等优势而迅速成为 Linux 上非常流行的文件系统,诸如 Redhat 等发行版都将 ext3 作为默认的文件系统格式。为了尽量保持与 ext2 文件系统实现更好的兼容性,ext3 在设计时采用了很多保守的做法,这些保守的设计为 ext3 赢得了稳定、健壮的声誉,迅速得到了 Linux 用户(尤其是原有的 ext2 文件系统的用户)的青睐,但同时这也限制了它的可扩展能力,无法支持特别大的文件系统。
随着硬盘存储容量越来越大(硬盘容量每年几乎都会翻一倍,现在市面上已经有 1TB 的硬盘出售,很快桌面用户也可以享用这么大容量的存储空间了),企业应用所需要和产生的数据越来越多(Lawrence Livermore National Labs 使用的 BlueGene/L 系统上所使用的数据早已超过了 1PB),以及在线重新调整大小特性的支持,ext3 所面临的可扩充性问题和性能方面的压力也越来越大。在 ext3 文件系统中,如果使用 4KB 大小的数据块,所支持的最大文件系统上限为16TB,这是由于它使用了 32 位的块号所决定的(232 * 212 B = 244 B = 16 TB)。为了解决这些限制,从 2006 年 8 月开始,陆续有很多为 ext3 设计的补丁发布出来,这些补丁主要是扩充了两个特性:针对大文件系统支持的设计和 extent 映射技术。不过要想支持更大的文件系统,就必须对磁盘上的存储格式进行修改,这会破坏向前兼容性。因此为了为庞大的 ext3 用户群维护更好的稳定性,设计人员决定从 ext3 中另辟一支,设计下一代 Linux 上的文件系统,即 ext4。
ext4 的主要目标是解决 ext3 所面临的可扩展性、性能和可靠性问题。从 2.6.19 版本的内核开始,ext4 已经正式进入内核源代码中,不过它被标记为正在开发过程中,即 ext4dev。本文将介绍 ext4 为了支持更好的可扩展性方面所采用的设计,并探讨由此而引起的磁盘数据格式的变化,以及对恢复删除文件所带来的影响。
可扩展性
为了支持更大的文件系统,ext4 决定采用 48 位的块号取代 ext3 原来的 32 位块号,并采用 extent 映射来取代 ext3 所采用的间接数据块映射的方法。这样既可以增大文件系统的容量,又可以改进大文件的访问效率。在使用 4KB 大小的数据块时,ext4 可以支持最大 248 * 212 = 260 B(1 EB)的文件系统。之所以采用 48 位的块号而不是直接将其扩展到 64 位是因为,ext4 的开发者认为 1 EB 大小的文件系统对未来很多年都足够了(实际上,按照目前的速度,要对 1 EB 大小的文件系统执行一次完整的 fsck 检查,大约需要 119 年的时间),与其耗费心机去完全支持 64 位的文件系统,还不如先花些精力来解决更加棘手的可靠性问题。
将块号从 32 位修改为 48 位之后,存储元数据的结构都必须相应地发生变化,主要包括超级块、组描述符和日志。下面给出了 ext4 中所使用的新结构的部分代码。
清单1. ext4_super_block 结构定义
520 /*
521 * Structure of the super block
522 */
523 struct ext4_super_block {
524 /*00*/ __le32 s_inodes_count; /* Inodes count */
525 __le32 s_blocks_count; /* Blocks count */
526 __le32 s_r_blocks_count; /* Reserved blocks count */
527 __le32 s_free_blocks_count; /* Free blocks count */
528 /*10*/ __le32 s_free_inodes_count; /* Free inodes count */
529 __le32 s_first_data_block; /* First Data Block */
530 __le32 s_log_block_size; /* Block size */
…
594 /* 64bit support valid if EXT4_FEATURE_COMPAT_64BIT */
595 /*150*/ __le32 s_blocks_count_hi; /* Blocks count */
596 __le32 s_r_blocks_count_hi; /* Reserved blocks count */
597 __le32 s_free_blocks_count_hi; /* Free blocks count */
…
606 };
|
在 ext4_super_block 结构中,增加了 3 个与此相关的字段:s_blocks_count_hi、s_r_blocks_count_hi、s_free_blocks_count_hi,它们分别表示 s_blocks_count、s_r_blocks_count、s_free_blocks_count 高 32 位的值,将它们扩充到 64 位。
清单2. ext4_group_desc 结构定义
121 /*
122 * Structure of a blocks group descriptor
123 */
124 struct ext4_group_desc
125 {
126 __le32 bg_block_bitmap; /* Blocks bitmap block */
127 __le32 bg_inode_bitmap; /* Inodes bitmap block */
128 __le32 bg_inode_table; /* Inodes table block */
129 __le16 bg_free_blocks_count; /* Free blocks count */
130 __le16 bg_free_inodes_count; /* Free inodes count */
131 __le16 bg_used_dirs_count; /* Directories count */
132 __u16 bg_flags;
133 __u32 bg_reserved[3];
134 __le32 bg_block_bitmap_hi; /* Blocks bitmap block MSB */
135 __le32 bg_inode_bitmap_hi; /* Inodes bitmap block MSB */
136 __le32 bg_inode_table_hi; /* Inodes table block MSB */
137 };
|
类似地,在 ext4_group_desc 中引入了另外 3 个字段:bg_block_bitmap_hi、bg_inode_bitmap_hi、bg_inode_table_hi,分别表示 bg_block_bitmap、bg_inode_bitmap、bg_inode_table 的高 32 位。
另外,由于日志中要记录所修改数据块的块号,因此 JBD也需要相应地支持 48 位的块号。同样是为了为 ext3 广大的用户群维护更好的稳定性,JBD2 也从 JBD 中分离出来,详细实现请参看内核源代码。
采用 48 位块号取代原有的 32 位块号之后,文件系统的最大值还受文件系统中最多块数的制约,这是由于 ext3 原来采用的结构决定的。回想一下,对于 ext3 类型的分区来说,在每个分区的开头,都有一个引导块,用来保存引导信息;文件系统的数据一般从第 2 个数据块开始(更确切地说,文件系统数据都是从 1KB 之后开始的,对于 1024 字节大小的数据块来说,就是从第 2 个数据块开始;对于超过 1KB 大小的数据块,引导块与后面的超级块等信息共同保存在第 1 个数据块中,超级块从 1KB 之后的位置开始)。为了管理方便,文件系统将剩余磁盘划分为一个个块组。块组前面存储了超级块、块组描述符、数据块位图、索引节点位图、索引节点表,然后才是数据块。通过有效的管理,ext2/ext3 可以尽量将文件的数据放入同一个块组中,从而实现文件数据在磁盘上的最大连续性。
在 ext3 中,为了安全性方面的考虑,所有的块描述符信息全部被保存到第一个块组中,因此以缺省的 128MB (227 B)大小的块组为例,最多能够支持 227 / 32 = 222 个块组,最大支持的文件系统大小为 222 * 227 = 249 B= 512 TB。而ext4_group_desc 目前的大小为 44 字节,以后会扩充到 64 字节,所能够支持的文件系统最大只有 256 TB。
为了解决这个问题,ext4 中采用了元块组(metablock group)的概念。所谓元块组就是指块组描述符可以存储在一个数据块中的一些连续块组。仍然以 128MB 的块组(数据块为 4KB)为例,ext4 中每个元块组可以包括 4096 / 64 = 64 个块组,即每个元块组的大小是 64 * 128 MB = 8 GB。
采用元块组的概念之后,每个元块组中的块组描述符都变成定长的,这对于文件系统的扩展非常有利。原来在 ext3 中,要想扩大文件系统的大小,只能在第一个块组中增加更多块描述符,通常这都需要重新格式化文件系统,无法实现在线扩容;另外一种可能的解决方案是为块组描述符预留一部分空间,在增加数据块时,使用这部分空间来存储对应的块组描述符;但是这样也会受到前面介绍的最大容量的限制。而采用元块组概念之后,如果需要扩充文件系统的大小,可以在现有数据块之后新添加磁盘数据块,并将这些数据块也按照元块组的方式进行管理即可,这样就可以突破文件系统大小原有的限制了。当然,为了使用这些新增加的空间,在 superblock 结构中需要增加一些字段来记录相关信息。(ext4_super_block 结构中增加了一个 s_first_meta_bg 字段用来引用第一个元块组的位置,这样还可以解决原有块组和新的元块组共存的问题。)下图给出了 ext3 为块组描述符预留空间和在 ext4 中采用元块组后的磁盘布局。
图 1. ext3 与 ext4 磁盘布局对比 
extent
ext2/ext3 文件系统与大部分经典的 UNIX/Linux 文件系统一样,都使用了直接、间接、二级间接和三级间接块的形式来定位磁盘中的数据块。对于小文件或稀疏文件来说,这非常有效(以 4KB 大小的数据块为例,小于 48KB 的文件只需要通过索引节点中 i_block 数组的前 12 个元素一次定位即可),但是对于大文件来说,需要经过几级间接索引,这会导致在这些文件系统上大文件的性能较差。
测试表明,在生产环境中,数据不连续的情况不会超过10%。因此,在 ext4 中引入了 extent 的概念来表示文件数据所在的位置。所谓 extent 就是描述保存文件数据使用的连续物理块的一段范围。每个 extent 都是一个 ext4_extent 类型的结构,大小为 12 字节。定义如下所示:
清单3. ext4 文件系统中有关 extent 的结构定义
69 /*
70 * This is the extent on-disk structure.
71 * It's used at the bottom of the tree.
72 */
73 struct ext4_extent {
74 __le32 ee_block; /* first logical block extent covers */
75 __le16 ee_len; /* number of blocks covered by extent */
76 __le16 ee_start_hi; /* high 16 bits of physical block */
77 __le32 ee_start; /* low 32 bits of physical block */
78 };
79
80 /*
81 * This is index on-disk structure.
82 * It's used at all the levels except the bottom.
83 */
84 struct ext4_extent_idx {
85 __le32 ei_block; /* index covers logical blocks from 'block' */
86 __le32 ei_leaf; /* pointer to the physical block of the next *
87 * level. leaf or next index could be there */
88 __le16 ei_leaf_hi; /* high 16 bits of physical block */
89 __u16 ei_unused;
90 };
91
92 /*
93 * Each block (leaves and indexes), even inode-stored has header.
94 */
95 struct ext4_extent_header {
96 __le16 eh_magic; /* probably will support different formats */
97 __le16 eh_entries; /* number of valid entries */
98 __le16 eh_max; /* capacity of store in entries */
99 __le16 eh_depth; /* has tree real underlying blocks? */
100 __le32 eh_generation; /* generation of the tree */
101 };
102
103 #define EXT4_EXT_MAGIC cpu_to_le16(0xf30a)
|
每个 ext4_extent 结构可以表示该文件从 ee_block 开始的 ee_len 个数据块,它们在磁盘上的位置是从 ee_start_hi<<32 + ee_start 开始,到 ee_start_hi<<32 + ee_start + ee_len – 1 结束,全部都是连续的。尽管 ee_len 是一个 16 位的无符号整数,但是其最高位被在预分配特性中用来标识这个 extent 是否被初始化过了,因此可以一个 extent 可以表示 215 个连续的数据块,如果采用 4KB 大小的数据块,就相当于 128MB。
如果文件大小超过了一个 ext4_extent 结构能够表示的范围,或者其中有不连续的数据块,就需要使用多个 ext4_extent 结构来表示了。为了解决这个问题,ext4 文件系统的设计者们采用了一棵 extent 树结构,它是一棵高度固定的树,其布局如下图所示:
图 2. ext4 中 extent 树的布局结构 
在 extent 树中,节点一共有两类:叶子节点和索引节点。保存文件数据的磁盘块信息全部记录在叶子节点中;而索引节点中则存储了叶子节点的位置和相对顺序。不管是叶子节点还是索引节点,最开始的 12 个字节总是一个 ext4_extent_header 结构,用来标识该数据块中有效项(ext4_extent 或 ext4_extent_idx 结构)的个数(eh_entries 域的值),其中 eh_depth 域用来表示它在 extent 树中的位置:对于叶子节点来说,该值为 0,之上每层索引节点依次加 1。extent 树的根节点保存在索引节点结构中的 i_block 域中,我们知道它是一个大小为 60 字节的数组,最多可以保存一个 ext4_extent_header 结构以及 4 个 ext4_extent 结构。对于小文件来说,只需要一次寻址就可以获得保存文件数据块的位置;而超出此限制的文件(例如很大的文件、碎片非常多的文件以及稀疏文件)只能通过遍历 extent 树来获得数据块的位置。
索引节点
索引节点是 ext2/ext3/ext4 文件系统中最为基本的一个概念,它是文件语义与数据之间关联的桥梁。为了最大程度地实现向后兼容性,ext4 尽量保持索引节点不会发生太大变化。ext4_inode 结构定义如下所示:
清单4. ext4_inode 结构定义
284 /*
285 * Structure of an inode on the disk
286 */
287 struct ext4_inode {
288 __le16 i_mode; /* File mode */
289 __le16 i_uid; /* Low 16 bits of Owner Uid */
290 __le32 i_size; /* Size in bytes */
291 __le32 i_atime; /* Access time */
292 __le32 i_ctime; /* Inode Change time */
293 __le32 i_mtime; /* Modification time */
294 __le32 i_dtime; /* Deletion Time */
295 __le16 i_gid; /* Low 16 bits of Group Id */
296 __le16 i_links_count; /* Links count */
297 __le32 i_blocks; /* Blocks count */
298 __le32 i_flags; /* File flags */
…
310 __le32 i_block[EXT4_N_BLOCKS];/* Pointers to blocks */
311 __le32 i_generation; /* File version (for NFS) */
312 __le32 i_file_acl; /* File ACL */
313 __le32 i_dir_acl; /* Directory ACL */
314 __le32 i_faddr; /* Fragment address */
…
339 __le16 i_extra_isize;
340 __le16 i_pad1;
341 __le32 i_ctime_extra; /* extra Change time (nsec << 2 | epoch) */
342 __le32 i_mtime_extra; /* extra Modification time(nsec << 2 | epoch) */
343 __le32 i_atime_extra; /* extra Access time (nsec << 2 | epoch) */
344 __le32 i_crtime; /* File Creation time */
345 __le32 i_crtime_extra; /* extra FileCreationtime (nsec << 2 | epoch) */
346 };
|
与 ext3 文件系统中使用的 ext3_inode 结构对比一下可知,索引节点结构并没有发生太大变化,不同之处在于最后添加了 5 个与时间有关的字段,这是为了提高时间戳的精度。在 ext2/ext3 文件系统中,时间戳的精度只能达到秒级。随着硬件性能的提升,这种精度已经无法区分在同一秒中创建的文件的时间戳差异,这对于对精度要求很高的程序来说是无法接受的。在 ext4 文件系统中,通过扩充索引节点结构解决了这个问题,可以实现纳秒级的精度。最后两个新增字段 i_crtime 和 i_crtime_extra 用来表示文件的创建时间,这可以用来满足某些应用程序的需求。
前面已经介绍过,尽管索引节点中的 i_block 字段保持不变,但是由于 extent 概念的引入,对于这个数组的使用方式已经改变了,其前 3 个元素一定是一个 ext4_extent_header 结构,后续每 3 个元素可能是一个 ext4_extent 或 ext4_extent_idx 结构,这取决于所表示的文件的大小。这种设计可以有效地表示连续存放的大文件,但是对于包含碎片非常多的文件或者稀疏文件来说,就不是那么有效了。为了解决这个问题,ext4 的设计者们正在讨论设计一种新型的 extent 来表示这种特殊文件,它将在叶子节点中采用类似于 ext3 所采用的间接索引块的形式来保存为该文件分配的数据块位置。该类型的 ext4_extent_header 结构中的 eh_magic 字段将采用一个新值,以便与目前的 extent 区别开来。
采用这种结构的索引节点还存在一个问题:我们知道,在 ext3 中 i_blocks 是以扇区(即 512 字节)为单位的,因此单个文件的最大限制是 232 * 512 B = 2 TB。为了支持更大的文件,ext4 的 i_blocks 可以以数据块大小为单位(这需要 HUGE_FILE 特性的支持),因此文件上限可以扩充到 16TB(数据块大小为 4KB)。同时为了避免需要对整个文件系统都需要进行类似转换,还引入了一个 EXT4_HUGE_FILE_FL 标志,i_flags 中不包含这个标志的索引节点的 i_blocks 依然以 512 字节为单位。当文件所占用的磁盘空间大小增大到不能够用以512字节为单位的i_blocks来表示时,ext4自动激活EXT4_HUGE_FILE_FL标志,以数据块为单位重新计算i_blocks的值。该转换是自动进行的,对用户透明。
目录项
ext4 文件系统中使用的目录项与 ext2/ext3 并没有太大的区别。所使用的结构定义如下所示:
清单5. 目录项结构定义
737 /*
738 * Structure of a directory entry
739 */
740 #define EXT4_NAME_LEN 255
741
742 struct ext4_dir_entry {
743 __le32 inode; /* Inode number */
744 __le16 rec_len; /* Directory entry length */
745 __le16 name_len; /* Name length */
746 char name[EXT4_NAME_LEN]; /* File name */
747 };
748
749 /*
750 * The new version of the directory entry. Since EXT4 structures are
751 * stored in intel byte order, and the name_len field could never be
752 * bigger than 255 chars, it's safe to reclaim the extra byte for the
753 * file_type field.
754 */
755 struct ext4_dir_entry_2 {
756 __le32 inode; /* Inode number */
757 __le16 rec_len; /* Directory entry length */
758 __u8 name_len; /* Name length */
759 __u8 file_type;
760 char name[EXT4_NAME_LEN]; /* File name */
761 };
|
与 ext2/ext3 类似,当目录项被删除时,也会将该目录项的空间合并到上一个目录项中。与 ext2/ext3 不同的地方在于,在删除目录项时,该目录项中的索引节点号并没有被清空,而是得以保留了下来,这使得在恢复删除文件时,文件名就可以通过查找目录项中匹配的索引节点号得以正确恢复。详细数据如下所示:
清单6. 删除文件前后目录项的变化
[root@vmfc8 ext4]# ./read_dir_entry root.block.547.orig 4096
offset | inode number | rec_len | name_len | file_type | name
=================================================================
0: 2 12 1 2 .
12: 2 12 2 2 ..
24: 11 20 10 2 lost+found
44: 12 16 5 1 hello
60: 13 32 12 1 testfile.35K
80: 14 12 4 1 hole
92: 15 4004 4 1 home
[root@vmfc8 ext4]# ./read_dir_entry root.block.547.deleted 4096
offset | inode number | rec_len | name_len | file_type | name
=================================================================
0: 2 12 1 2 .
12: 2 12 2 2 ..
24: 11 36 10 2 lost+found
44: 12 16 5 1 hello
60: 13 32 12 1 testfile.35K
80: 14 12 4 1 hole
92: 15 4004 4 1 home
|
上面给出了保存根目录的数据块(547)在删除 hello 文件前后的变化,从中我们可以看出,唯一的区别在于 hello 所使用的 16 个字节的空间后来被合并到 lost+found 目录项所使用的空间中了,而索引节点号等信息都得以完整地保留了下来。清单中使用的 read_dir_entry 程序用来显示目录项中的数据,其源码可以在本文下载部分中获得。有关如何抓取保存目录数据的数据块的方法,请参看本系列文章第 2 部分的介绍。
在 ext2/3 文件系统中,一个目录下面最多可以包含 32,000 个子目录,这对于大型的企业应用来说显然是不够的。ext4 决定将其上限扩充到可以支持任意多个子目录。然而对于这种链表式的存储结构来说,目录项的查找和删除需要遍历整个目录的所有目录项,效率显然是相当低的。实际上,从 ext2 开始,文件系统的设计者引入了一棵 H-树来对目录项的 hash 值进行索引,速度可以提高 50 - 100 倍。相关内容已经超出了本文的范围,感兴趣的读者可自行参考 Linux 内核源代码中的相关实现。
ext4 文件系统的使用
目前,ext4 文件系统仍然处于非常活跃的状态,因此内核在相应的地方都加上了 DEV 标志。在编译内核时,需要在内核的 .config 文件中启用 EXT4DEV_FS 选项才能编译出最终使用的内核模块 ext4dev.ko。
由于 ext4 内部采用的关键数据结构与 ext3 并没有什么关键区别,因此在创建文件系统时依然是使用 mkfs.ext3 命令,如下所示:
清单7. 创建 ext4 文件系统,目前与创建 ext3 文件系统没什么两样
[root@vmfc8 ~]# mkfs.ext3 /dev/sda3 |
为了保持向前兼容性,现有的 ext3 文件系统也可以当作 ext4 文件系统进行加载,命令如下所示:
清单8. 挂载 ext4 文件系统
[root@vmfc8 ~]# mount -t ext4dev -o extents /dev/sda3 /tmp/test
-o extents 选项就是指定要启用 extent 特性。如果不在这个文件系统中执行任何写入操作,以后这个文件系统也依然可以按照 ext3 或 ext4 格式正常挂载。但是一旦在这个文件系统中写入文件之后,文件系统所使用的特性中就包含了 extent 特性,因此以后再也不能按照 ext3 格式进行挂载了,如下所示:
清单9. 写入文件前后 ext4 文件系统特性的变化据
[root@vmfc8 ext4]# umount /tmp/test; mount -t ext4dev -o extents /dev/sda3 /tmp/test; /
dumpe2fs /dev/sda3 > sda3.ext4_1
[root@vmfc8 ext4]# umount /tmp/test; mount -t ext4dev -o extents /dev/sda3 /tmp/test; /
echo hello > /tmp/test/hello; dumpe2fs /dev/sda3 > sda3.ext4_2
[root@vmfc8 ext4]# diff sda3.ext4_1 sda3.ext4_2
6c6
< Filesystem features: has_journal resize_inode dir_index filetype /
needs_recovery sparse_super large_file
---
> Filesystem features: has_journal resize_inode dir_index filetype /
needs_recovery extents sparse_super large_file
…
[root@vmfc8 ext4]# umount /tmp/test; mount -t ext3 /dev/sda3 /tmp/test
mount: wrong fs type, bad option, bad superblock on /dev/sda3,
missing codepage or helper program, or other error
In some cases useful info is found in syslog - try
dmesg | tail or so
|
e2fsprogs 工具的支持
在本系列前面的文章中,我们已经初步体验了 e2fsprogs 包中提供的诸如 debugfs、dumpe2fs 之类的工具对于深入理解文件系统和磁盘数据来说是如何方便。作为一种新生的文件系统,ext4 文件系统要想得到广泛应用,相关工具的支持也非常重要。从 1.39 版本开始,e2fsprogs 已经逐渐开始加入对 ext4 文件系统的支持,例如创建文件系统使用的 mkfs.ext3 命令以后会被一个新的命令 mkfs.ext4 所取代。但是截止到本文撰写时为止,e2fsprogs 的最新版本(1.40.7)对于 ext4 的支持尚不完善,下面的例子给出了 debugfs 查看 hello 文件时的结果:
清单10. debugfs 命令对 ext4 文件系统的支持尚不完善
[root@vmfc8 ext4]# echo "hello world" > /tmp/test/hello [root@vmfc8 ext4]# debugfs /dev/sda3 debugfs 1.40.2 (12-Jul-2007) debugfs: stat hello Inode: 12 Type: regular Mode: 0644 Flags: 0x80000 Generation: 827135866 User: 0 Group: 0 Size: 12 File ACL: 0 Directory ACL: 0 Links: 1 Blockcount: 8 Fragment: Address: 0 Number: 0 Size: 0 ctime: 0x47ced460 -- Thu Mar 6 01:12:00 2008 atime: 0x47ced460 -- Thu Mar 6 01:12:00 2008 mtime: 0x47ced460 -- Thu Mar 6 01:12:00 2008 BLOCKS: (0):127754, (1):4, (4):1, (5):28672 TOTAL: 4 |
从上面的输出结果中我们可以看出,尽管这个索引节点的 i_flags 字段值为 0x80000,表示使用 extent 方式来存储数据,而不是原有的直接/间接索引模式来存储数据(此时 i_flags 字段值为 0),但是对 i_block 数组中内容的显示却依然沿用了原有的模式。如果文件占用多个 extent 进行存储,会发现 debugfs 依然尝试将 i_block[12]、i_block[13]、i_block[14] 分别作为一级、二级和三级间接索引使用,显然从中读出的数据也是毫无意义的。
索引节点中使用的 i_flags 值是在内核源代码的 /include/linux/ext4_fs.h 中定义的,如下所示:
清单11. i_flags 值定义节选
#define EXT4_EXTENTS_FL 0x00080000 /* Inode uses extents */ |
ext4 文件系统中文件的删除与恢复
在 ext4 文件系统中删除文件时,所执行的操作与在 ext2/ext3 文件系统中非常类似,也不会真正修改存储文件数据所使用的磁盘数据块的内容,而是仅仅删除或修改了相关的元数据信息,使文件数据无法正常索引,从而实现删除文件的目的。因此,在 ext4 文件系统中恢复删除文件也完全是可能的。
前文中已经介绍过,在 ext4 文件系统中删除文件时,并没有将目录项中的索引节点号清空,因此通过遍历目录项的方式完全可以完整地恢复出文件名来。
对于文件数据来说,实际数据块中的数据在文件删除前后也没有任何变化,这可以利用本系列文章第一部分中介绍的直接比较数据块的方法进行验证。然而由于 extent 的引入,在 ext4 中删除文件与 ext3 也有所区别。下面让我们通过一个实例来验证一下。
在下面的例子中,我们要创建一个非常特殊的文件,它每 7KB 之后的都是一个数字(7 的倍数),其他地方数据全部为 0。
清单12. 创建测试文件
[root@vmfc8 ext4]# cat -n create_extents.sh
1 #!/bin/bash
2
3 if [ $# -ne 2 ]
4 then
5 echo "$0 [filename] [size in kb]"
6 exit 1
7 fi
8
9 filename=$1
10 size=$2
11 i=0
12
13 while [ $i -lt $size ]
14 do
15 i=`expr $i + 7`
16 echo -n "$i" | dd of=$1 bs=1024 seek=$i
17 dones
[root@vmfc8 ext4]# ./create_extents.sh /tmp/test/sparsefile.70K 70
[root@vmfc8 ext4]# ls -li /tmp/test/sparsefile.70K
13 -rw-r--r-- 1 root root 71682 2008-03-06 10:49 /tmp/test/sparsefile.70K
[root@vmfc8 ext4]# hexdump -C /tmp/test/sparsefile.70K
00000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00001c00 37 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |7...............|
00001c10 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00003800 31 34 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |14..............|
00003810 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00005400 32 31 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |21..............|
00005410 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00007000 32 38 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |28..............|
00007010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00008c00 33 35 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |35..............|
00008c10 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
0000a800 34 32 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |42..............|
0000a810 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
0000c400 34 39 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |49..............|
0000c410 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
0000e000 35 36 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |56..............|
0000e010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
0000fc00 36 33 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |63..............|
0000fc10 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00011800 37 30 |70|
00011802
|
之所以要使用这个文件当作测试文件,完全为了回避 extent 的优点,否则在 4KB 大小数据块的 ext4 文件系统中,一个 extent 就可以表示 128MB 的空间,因此要想测试 extent 树的变化情况就必须创建非常大的文件才行。
由于 debugfs 对 ext4 的支持尚不完善,我们自己编写了一个小程序(list_extents)来遍历 extent 树的内容,并显示索引节点和叶子节点的数据块的位置。该程序的源代码可以在本文下载部分中获得,其用法如下:
清单13. 查看测试文件使用的 extent 树信息
[root@vmfc8 ext4]# ./list_extents /dev/sda3 13 root node: depth of the tree: 1, 1 entries in root level idx: logical block: 1, block: 20491 - logical block: 1 - 1, physical block: 20481 - 20481 - logical block: 3 - 3, physical block: 20483 - 20483 - logical block: 5 - 5, physical block: 20485 - 20485 - logical block: 7 - 8, physical block: 20487 - 20488 - logical block: 10 - 10, physical block: 20490 - 20490 - logical block: 12 - 12, physical block: 20492 - 20492 - logical block: 14 - 15, physical block: 20494 - 20495 - logical block: 17 - 17, physical block: 20497 - 20497 |
list_extents 程序会对指定磁盘进行搜索,从其中的索引节点表中寻找搜索指定的索引节点号(13)所对应的项,并将其 i_block 数组当作一棵 extent 树进行遍历。从输出结果中我们可以看出,这棵 extent 树包括 1 个索引节点和 1个包含了8个 ext4_extent 结构的叶子节点,其中索引节点保存 i_block 数组中,而叶子节点则保存在20491 这个数据块中。下面让我们来看一下该文件的索引节点在删除文件前后的变化:
清单14. ext4 文件系统中删除文件前后文件索引节点的变化
[root@vmfc8 ext4]# echo "stat <13>" | debugfs /dev/sda3 debugfs 1.40.2 (12-Jul-2007) debugfs: Inode: 13 Type: regular Mode: 0644 Flags: 0x80000 Generation: 2866260918 User: 0 Group: 0 Size: 71682 File ACL: 0 Directory ACL: 0 Links: 1 Blockcount: 88 Fragment: Address: 0 Number: 0 Size: 0 ctime: 0x47cf5bb1 -- Thu Mar 6 10:49:21 2008 atime: 0x47cf5bb0 -- Thu Mar 6 10:49:20 2008 mtime: 0x47cf5bb1 -- Thu Mar 6 10:49:21 2008 BLOCKS: (0):127754, (1):65540, (3):1, (4):20491, (6):3, (7):1, (8):20483, (9):5, (10):1, (11):20485, (IND):7, (12):32775, (13):98311, (14):163847, (15):229383, (DIND):2, (IND):32770, (IND):98306, (IND):163842, (IND):229378, (TIND):20487, (DIND):14386 TOTAL: 22 [root@vmfc8 ext4]# rm -f /tmp/test/sparsefile.70K [root@vmfc8 ext4]# sync [root@vmfc8 ext4]# echo "stat <13>" | debugfs /dev/sda3 debugfs 1.40.2 (12-Jul-2007) debugfs: Inode: 13 Type: regular Mode: 0644 Flags: 0x80000 Generation: 2866260918 User: 0 Group: 0 Size: 0 File ACL: 0 Directory ACL: 0 Links: 0 Blockcount: 0 Fragment: Address: 0 Number: 0 Size: 0 ctime: 0x47cf5ebc -- Thu Mar 6 11:02:20 2008 atime: 0x47cf5bb0 -- Thu Mar 6 10:49:20 2008 mtime: 0x47cf5bb1 -- Thu Mar 6 10:49:21 2008 dtime: 0x47cf5ebc -- Thu Mar 6 11:02:20 2008 BLOCKS: (0):62218, (1):4, (3):1, (4):20491, (6):3, (7):1, (8):20483, (9):5, (10):1, (11):20485, (IND):7, (12):32775, (13):98311, (14):163847, (15):229383, (DIND):2, (IND):32770, (IND):98306, (IND):163842, (IND):229378, (TIND):20487, (DIND):14386 TOTAL: 22 |
首先需要注意的一点是,对于上面这棵 extent 树来说,只需要使用 i_block 数组的前 6 个元素就可以存储一个 ext4_extent_header 和一个 ext4_extent_idx 结构了,而 i_block 数组中的所有元素却都是有数据的。之所以出现这种情况是因为在创建这个特殊的测试文件的过程中,我们是不断创建一个文件并在此文件尾部追加数据从而生成新文件的。当该文件使用的 extent 超过 4 个时,便扩充成一棵 extent 树,但是剩余 3 个 extent 的内容(i_block 数组的后 9 个元素)并没有被清空。
对比删除文件前后的变化会发现,ext4 与 ext3 非常类似,也都将文件大小设置为 0,这使得 debugfs 的 dump 命令也无从正常工作了。不过与 ext3 不同的是,ext4 并没有将 i_block 数组的元素全部清空,而是将 ext4_extent_header 结构中有效项数设置为 0,这样就将 extent 树破坏掉了。另外,比较叶子节点(数据块 20491)中的数据变化会发现,下面这些域在删除文件时也都被清除了:
- ext4_extent_header 结构中的 eh_entries。
- ext4_extent 结构中的 ee_len、ee_start_hi 以及 ee_start。
图3. 删除文件前后 extent 树中叶子节点数据块的变化 
了解清楚这些变化之后,我们会发现在 ext4 中恢复删除文件的方法与 ext3 基本类似,也可以使用全文匹配、提前备份元数据和修改内核实现 3 种方法。
正如前面介绍的一样,由于 ext4 文件系统中采用了 extent 的设计,试图最大程度地确保文件数据会被保存到连续的数据块中,因此在 ext2/ext3 恢复删除文件时所介绍的正文匹配方法也完全适用,正常情况下采用这种方式恢复出来的数据会比 ext2/ext3 中更多。详细内容请参看本系列文章第 4 部分的介绍,本文中不再赘述。
尽管 ext4 是基于 extent 来管理空间的,但是在 ext3 中备份数据块位置的方法依然完全适用,下面给出了一个例子。
清单15. 备份文件数据块位置
[root@vmfc8 ext4]# export LD_PRELOAD=/usr/local/lib/libundel.so [root@vmfc8 ext4]# rm -f /tmp/test/sparsefile.70K [root@vmfc8 ext4]# tail -n 1 /var/e2undel/e2undel 8,3::13::71682::4096::(1-1): 20481-20481,(3-3): 20483-20483, (5-5): 20485-20485,(7-8): 20487-20488,(10-10): 20490-20490, (12-12): 20492-20492,(14-15): 20494-20495, (17-17): 20497-20497::/tmp/test/sparsefile.70K |
当然,如果内核实现中可以在删除文件时,extent树(其中包括i_block数组,其他extent索引节点和叶子节点)中的数据保留下来,那自然恢复起来就更加容易了。由于 ext4 的开发依然正在非常活跃地进行中,相关代码可能会频繁地发生变化,本文就不再深入探讨这个话题了,感兴趣的读者可以自行尝试。
小结
本文从 ext3 的在支持大文件系统方面的缺陷入手,逐渐介绍了 ext4 为了支持大文件系统而引入的一些设计特性,并探讨了这些特性对磁盘数据格式引起的变化,以及对恢复删除文件所带来的影响,最终讨论了在 ext4 文件系统中如何恢复删除文件的问题。在本系列的下一篇文章中,我们将开始讨论另外一个设计非常精巧的文件系统 reiserfs 上的相关问题。
reiserfs 对于小文件的存取速度非常高,这取决于它所采用的精美的设计:reiserfs 文件系统就是一棵动态的 B+ 树,小文件和大文件的尾部数据都可以通过保存到叶子节点中而加快存取速度。本文将探讨 reiserfs 的设计和实现内幕,并从中探讨恢复删除文件的可能性。
reiserfs 是由 namesys 公司的 Hans Reiser 设计并开发的一种通用日志文件系统,它是第一个进入 Linux 标准内核日志文件系统。从诞生之日起,reiserfs 就由于其诸多非常有吸引力的特性而受到很多用户的青睐,迅速成为 Slackware 等发行版的默认文件系统。它也一度也是 SUSE Linux Enterprise 发行版上的默认文件系统,直到 2006 年 10 月 12 日 Novell 公司决定将默认文件系统转换到 ext3 为止。尽管其主要设计人员 Hans Reiser 由于涉嫌杀害妻子遭到指控而入狱,从而导致他不得不试图出售 namesys 公司来支付庞大的诉讼费用,但是 reiserfs 已经受到广大社区开发人员和用户的极大关注,有很多志愿者已经投入到新的 reiserfs 4 的开发工作中来。本文中的介绍都是基于最新的稳定版本 3.6 版本的,所引用的代码都基于 2.6.23 版本的内核。
reiserfs 最初的设计目标是为了改进 ext2 文件系统的性能,提高文件系统的利用率,并增强对包含大量文件的目录的处理能力(ext2/ext3 文件系统中一个目录下可以包含的子目录最多只能有 31998 个)。传统的 ext2 和 ufs 文件系统都采用了将文件数据和文件元数据分离开保存的形式,将元数据保存到索引节点中,将文件数据保存到单独的磁盘块中,并通过索引节点中的 i_block 数组利用直接索引和间接索引的形式在磁盘上定位文件数据。这种设计非常适合存储较大的文件(比如20KB以上),但是对于具有大量小文件的系统来说就存在一些问题。首先在于文件系统的利用率,由于 ext2 会将文件数据以数据块为单位(默认为 4KB)进行存储,因此对于存储只有几十个字节的文件来说,会造成空间的极大浪费。另外由于在读取文件时需要分别读取文件元数据和文件数据,加上多读取数据块的开销,ext2 文件系统在处理大量小文件时,性能会比较差。为了获取最好的性能和最大程度地利用磁盘空间,很多用户会在文件系统之上采用数据库之类的解决方案来存储这些小文件,因此会导致上层应用程序的接口极不统一。
为了解决上面提到的问题,reiserfs 为每个文件系统采用一棵经过专门优化的 B+ 树来组织所有的文件数据,并实现了很多新特性,例如元数据日志。为了提高文件系统的利用率,reiserfs 中采用了所谓的尾部封装(tail packing)设计,可以充分利用已分配磁盘块中的剩余空间来存储小文件。实际上,reiserfs 文件系统中存储的文件会比 ext2/ext3 大 5% - 6% 以上。下面让我们来探索一下 reiserfs 文件系统中数据在磁盘上究竟是如何存储的。
磁盘布局
与 ext2/ext3 类似,reiserfs 文件系统在创建时,也会将磁盘空间划分成固定大小的数据块。数据块从 0 开始编号,最多可以有 232 个数据块。因此如果采用默认的 4KB 大小的数据块,单个 reiserfs 文件系统的上限是 16TB。reiserfs 分区的前 64KB 保留给引导扇区、磁盘标签等使用。超级块(super block)从 64KB 开始,会占用一个数据块;之后是一个数据块位图,用来标识对应的数据块是否处于空闲状态。如果一个数据块位图可以标识 n 个数据块,那么 reiserfs 分区中的第 n 个数据块也都是这样一个数据块,用来标识此后(包括自己)n 的数据块的状态。reiserfs 文件系统的磁盘结构如图 1 所示。
图 1. reiserfs 分区磁盘布局 
与 ext2/ext3 类似,reiserfs 文件系统的一些关键信息也保存超级块中。reiserfs 的超级块使用一个 reiserfs_super_block 结构来表示,其定义如清单1 所示:
清单1. reiserfs_super_block 结构定义
135 struct reiserfs_super_block_v1 {
136 __le32 s_block_count; /* blocks count */
137 __le32 s_free_blocks; /* free blocks count */
138 __le32 s_root_block; /* root block number */
139 struct journal_params s_journal;
140 __le16 s_blocksize; /* block size */
141 __le16 s_oid_maxsize; /* max size of object id array, see
142 * get_objectid() commentary */
143 __le16 s_oid_cursize; /* current size of object id array */
144 __le16 s_umount_state; /* this is set to 1 when filesystem was
145 * umounted, to 2 - when not */
146 char s_magic[10]; /* reiserfs magic string indicates that
147 * file system is reiserfs:
148 * "ReIsErFs" or "ReIsEr2Fs" or "ReIsEr3Fs" */
149 __le16 s_fs_state; /* it is set to used by fsck to mark which
150 * phase of rebuilding is done */
151 __le32 s_hash_function_code; /* indicate, what hash function is being use
152 * to sort names in a directory*/
153 __le16 s_tree_height; /* height of disk tree */
154 __le16 s_bmap_nr; /* amount of bitmap blocks needed to address
155 * each block of file system */
156 __le16 s_version; /* this field is only reliable on filesystem
157 * with non-standard journal */
158 __le16 s_reserved_for_journal; /* size in blocks of journal area on main
159 * device, we need to keep after
160 * making fs with non-standard journal */
161 } __attribute__ ((__packed__));
162
163 #define SB_SIZE_V1 (sizeof(struct reiserfs_super_block_v1))
164
165 /* this is the on disk super block */
166 struct reiserfs_super_block {
167 struct reiserfs_super_block_v1 s_v1;
168 __le32 s_inode_generation;
169 __le32 s_flags; /* Right now used only by inode-attributes, if enabled */
170 unsigned char s_uuid[16]; /* filesystem unique identifier */
171 unsigned char s_label[16]; /* filesystem volume label */
172 char s_unused[88]; /* zero filled by mkreiserfs and
173 * reiserfs_convert_objectid_map_v1()
174 * so any additions must be updated
175 * there as well. */
176 } __attribute__ ((__packed__));
|
该结构定义中还包含了其他结构的定义,例如 journal_params,这是有关日志的一个结构,并非本文关注的重点,读者可以自行参考内核源代码中的 include/linux/ reiserfs_fs.h 文件。
实际上,超级块并不需要一个完整的数据块来存储,这个数据块中剩余的空间用来解决文件对象 id 的重用问题,详细内容请参看本系列文章下一部分的介绍。
B+ 树
与 ext2/ext3 的超级块比较一下会发现,reiserfs 的超级块中并没有索引节点表的信息,这是由于 reiserfs 并没有使用索引节点表,而是采用了 B+ 树来组织数据(在 reiserfs 的文档中也称为是 S+ 树)。图 2 中给出了一棵典型的 2 阶 B+ 树,其深度为 4。
图 2. 2 阶 B+ 树 
一棵 B+ 树有唯一一个根节点,其位置保存在超级块的 root_block 字段中。包含子树的节点都是中间节点(internal node),不包含子树的节点称为叶子节点(leaf node)。按照是否包含 B+ 树本身需要的信息,节点又可以分为两类,一类节点包含 B+ 树所需要的信息(例如指向数据块位置的指针,同时也包括文件数据),称为格式化节点(formatted node);另外一类只包含文件数据,而不包含格式化信息,称为未格式化节点(unformatted node 或 unfleaf)。因此,所有的中间节点都必须是格式化节点。一个格式化的叶子节点中可以包含多个条目(item,也称为项),所谓条目是一个数据容器,其内容可以保存到一个数据块中,也就是说,一个条目只能隶属于一个数据块,它是节点管理空间的基本单位。
为了方便理解起见,我们可以认为对于 B+ 树来说,一共包含 3 类节点:中间节点(其中保存了对叶子节点的索引信息)、叶子节点(包含一个或多个条目项)和数据节点(仅仅用来存放文件数据)。
熟悉数据结构的读者都会清楚,B+ 树是一棵平衡树,从根节点到达每个叶子节点的深度都是相同的。与 B- 树相比,B+ 树的好处是可以将数据全部保存到叶子节点中,而中间节点中并不存放真正的数据,仅仅用作对叶子节点的索引。为了方便起见,树的深度从叶子节点开始计算,叶子节点的深度为 1,之上的中间节点逐层加 1。在 B+ 树中查找匹配项首先要对关键字进行比较并沿对应指针进行遍历,直至搜索到叶子节点为止;而叶子节点也是按照关键字从小到大的顺序进行排列的。也正是由于这种结构,使得 B+ 树非常适合用来存储文件系统结构。
关键字
reiferfs 中采用的关键字包含 4 个部分,形式如下:
( directory-id, object-id, offset, type ) |
这 4 个部分分别表示父目录的 id、本对象的 id、本对象在整个对象(文件)中的偏移量以及类型。关键字的比较就是按照这 4 个部分逐一进行的。读者可能会好奇为什么不简单地采用对象 id 作为关键字。实际上,这种设计是有很多考虑的,采用 directory-id作为关键字的一部分,可以将相同目录中的文件和子目录组织在一起,加快对目录项的存取。offset 的出现是为了支持大文件,一个间接条目(后文中会介绍)最多能指向 (数据块大小-48)/4 个数据块来存放文件数据,在默认的 4KB 数据块中最大只能支持 4048KB 的文件。因此使用 offset 就可以表明该对象在文件中所处的偏移量。type 可以用来区分对象的类型。目目前reiserfs 支持四种类型,TYPE_STAT_DATA、TYPE_INDIRECT 1、TYPE_DIRECT 2、 TYPE_DIRENTRY,解释见后文的条目头部分。
在 3.5 之前的版本中,这 4 部分都是 32 位的整数,这样造成的问题是最大只能支持大约 232=4GB 的文件。从 3.6 版本开始,设计人员将 offset 扩充至 60 位,将 type 压缩至 4 位。这样理论上能够支持的最大文件就达到了 260 字节,但是由于其他一些限制,reiserfs 中可以支持的文件上限是 8TB。正是由于这个原因,reiserfs 中有两个版本的关键字,相关定义如清单 2 所示。
清单2. reiserfs 中与关键字有关的定义
363 struct offset_v1 {
364 __le32 k_offset;
365 __le32 k_uniqueness;
366 } __attribute__ ((__packed__));
367
368 struct offset_v2 {
369 __le64 v;
370 } __attribute__ ((__packed__));
371
372 static inline __u16 offset_v2_k_type(const struct offset_v2 *v2)
373 {
374 __u8 type = le64_to_cpu(v2->v) >> 60;
375 return (type <= TYPE_MAXTYPE) ? type : TYPE_ANY;
376 }
377
378 static inline void set_offset_v2_k_type(struct offset_v2 *v2, int type)
379 {
380 v2->v =
381 (v2->v & cpu_to_le64(~0ULL >> 4)) | cpu_to_le64((__u64) type << 60);
382 }
383
384 static inline loff_t offset_v2_k_offset(const struct offset_v2 *v2)
385 {
386 return le64_to_cpu(v2->v) & (~0ULL >> 4);
387 }
388
389 static inline void set_offset_v2_k_offset(struct offset_v2 *v2, loff_t offset)
390 {
391 offset &= (~0ULL >> 4);
392 v2->v = (v2->v & cpu_to_le64(15ULL << 60)) | cpu_to_le64(offset);
393 }
394
395 /* Key of an item determines its location in the S+tree, and
396 is composed of 4 components */
397 struct reiserfs_key {
398 __le32 k_dir_id; /* packing locality: by default parent
399 directory object id */
400 __le32 k_objectid; /* object identifier */
401 union {
402 struct offset_v1 k_offset_v1;
403 struct offset_v2 k_offset_v2;
404 } __attribute__ ((__packed__)) u;
405 } __attribute__ ((__packed__));
406
|
尽管结构定义中并没有显式地声明 offset 和 type 分别是 60 位和 4 位长,但是从几个相关函数中可以清楚地看到这一点。
数据块头
在图 2 中我们曾经介绍过,b+ 树中的节点可以分为格式化节点和未格式化节点两种。未格式化节点中保存的全部是文件数据,而格式化节点中包含了 b+ 树本身需要的一些信息。为了与未格式化节点区分开来,每个格式化节点所占用的数据块最开头都使用一个数据块头来表示。数据块头大小为 24 个字节,定义如清单 3 所示。
清单3. block_head 结构定义
698 /* Header of a disk block. More precisely, header of a formatted leaf
699 or internal node, and not the header of an unformatted node. */
700 struct block_head {
701 __le16 blk_level; /* Level of a block in the tree. */
702 __le16 blk_nr_item; /* Number of keys/items in a block. */
703 __le16 blk_free_space; /* Block free space in bytes. */
704 __le16 blk_reserved;
705 /* dump this in v4/planA */
706 struct reiserfs_key blk_right_delim_key; /* kept only for compatibility */
707 };
|
block_head 结构中的 blk_level 表示该节点在 B+ 树中的层次,对于叶子节点来说,该值为 1;blk_nr_item 表示这个数据块中条目的个数;blk_free_space 表示这个数据块中的空闲磁盘空间。
格式化节点可以分为中间节点和叶子节点两类,它们所采用的存储结构是不同的。
中间节点
中间节点由数据块头、关键字和指针数组构成。中间节点中的关键字和指针数组都是按照从小到大的顺序依次存放的,它们在磁盘上的布局如图 3 所示。
图 3. 中间节点的布局 ![]()
每个关键字就是一个 16 字节的 reiserfs_key 结构,而指针则是一个 disk_child 结构,其大小为 8 个字节,定义如清单 4 所示。
清单4. disk_child 结构定义
1086 /* Disk child pointer: The pointer from an internal node of the tree
1087 to a node that is on disk. */
1088 struct disk_child {
1089 __le32 dc_block_number; /* Disk child's block number. */
1090 __le16 dc_size; /* Disk child's used space. */
1091 __le16 dc_reserved;
1092 };
|
其中 dc_block_number 字段是所指向子节点所在的数据块块号,dc_size 表示这个数据块中已用空间的大小。对于一共有 n 个关键字的中间节点来说,第 i 个关键字位于 24+i*16 字节处,对应的指针位于 24+16*n+8*i 字节处。
需要注意的是,对于中间节点来说,数据块头的 blk_nr_item 字段表示的是关键字的个数,而指针数总是比关键字个数多 1,这是由 B+ 树的结构所决定的,小于 Key 0 的关键字可以在 Pointer 0 指针指向的数据块(下一层中间节点或叶子节点)中找到,而介于 Key 0 和 Key 1 之间的关键字则保存在 Pointer 1 指向的数据块中,依此类推。大于Key n的关键字可以在Pointer n+1中找到。
叶子节点
格式化叶子节点的结构比中间节点的结构稍微复杂一点。为了能够在一个格式化叶子节点中保存多个条目,reiserfs 采用了如图 4 所示的布局结构。
图 4. 格式化叶子节点的布局 
从图中可以看出,每个格式化叶子节点都以一个数据块头开始,然后是从两端向中间伸展的条目头和条目数据的数组,空闲空间保留在中间,这种设计是为了扩充方便。
所谓条目(item,或称为项)就是可以存储在单个节点中的一个数据容器,我们可以认为条目是由条目头和条目数据体组成的。
清单5. item_head 结构定义
460 /* Everything in the filesystem is stored as a set of items. The
461 item head contains the key of the item, its free space (for
462 indirect items) and specifies the location of the item itself
463 within the block. */
464
465 struct item_head {
466 /* Everything in the tree is found by searching for it based on
467 * its key.*/
468 struct reiserfs_key ih_key;
469 union {
470 /* The free space in the last unformatted node of an
471 indirect item if this is an indirect item. This
472 equals 0xFFFF iff this is a direct item or stat data
473 item. Note that the key, not this field, is used to
474 determine the item type, and thus which field this
475 union contains. */
476 __le16 ih_free_space_reserved;
477 /* Iff this is a directory item, this field equals the
478 number of directory entries in the directory item. */
479 __le16 ih_entry_count;
480 } __attribute__ ((__packed__)) u;
481 __le16 ih_item_len; /* total size of the item body */
482 __le16 ih_item_location; /* an offset to the item body
483 * within the block */
484 __le16 ih_version; /* 0 for all old items, 2 for new
485 ones. Highest bit is set by fsck
486 temporary, cleaned after all
487 done */
488 } __attribute__ ((__packed__));
|
从 item_head 结构定义中可以看出,关键字已经包含在其中了。ih_item_len 和 ih_item_location 分别表示对应条目的数据体的长度和在本块中的偏移量。请注意该结构的第 17、18 个字节是一个联合结构,对于不同类型的条目来说,该值的意义不同:对于 stat 数据条目(TYPE_STAT_DATA)或直接数据条目(TYPE_DIRECT),该值为 15;对于间接数据条目(TYPE_INDIRECT),该值表示最后一个未格式化数据块中的空闲空间;对于目录条目(TYPE_DIRENTRY),该值表示目录条目中目录项的个数。
目前 reiserfs 支持的条目类型有 4 种,它们是依靠关键字中的 type 字段来区分的;而在旧版本的关键字中,则是通过 uniqueness 字段来标识条目类型的,其定义如清单 6 所示。
清单6. reiserfs 支持的条目类型
346 // 347 // there are 5 item types currently 348 // 349 #define TYPE_STAT_DATA 0 350 #define TYPE_INDIRECT 1 351 #define TYPE_DIRECT 2 352 #define TYPE_DIRENTRY 3 353 #define TYPE_MAXTYPE 3 354 #define TYPE_ANY 15 // FIXME: comment is required 355 … 509 // 510 // in old version uniqueness field shows key type 511 // 512 #define V1_SD_UNIQUENESS 0 513 #define V1_INDIRECT_UNIQUENESS 0xfffffffe 514 #define V1_DIRECT_UNIQUENESS 0xffffffff 515 #define V1_DIRENTRY_UNIQUENESS 500 516 #define V1_ANY_UNIQUENESS 555 // FIXME: comment is required 517 |
下面让我们逐一来了解一下各种条目的存储结构。
STAT 条目
stat 数据(TYPE_STAT_DATA)非常类似于 ext2 中的索引节点,其中保存了诸如文件权限、MAC(modified、accessed、changed)时间信息等数据。在3.6 版本的 reiserfs 中,stat 数据使用一个stat_data 结构表示,该结构大小为 44 字节,其定义如清单 7 所示:
清单7. stat_data 结构定义
835 /* Stat Data on disk (reiserfs version of UFS disk inode minus the
836 address blocks) */
837 struct stat_data {
838 __le16 sd_mode; /* file type, permissions */
839 __le16 sd_attrs; /* persistent inode flags */
840 __le32 sd_nlink; /* number of hard links */
841 __le64 sd_size; /* file size */
842 __le32 sd_uid; /* owner */
843 __le32 sd_gid; /* group */
844 __le32 sd_atime; /* time of last access */
845 __le32 sd_mtime; /* time file was last modified */
846 __le32 sd_ctime; /* time inode (stat data) was last changed */
/* (except changes to sd_atime and sd_mtime) */
847 __le32 sd_blocks;
848 union {
849 __le32 sd_rdev;
850 __le32 sd_generation;
851 //__le32 sd_first_direct_byte;
852 /* first byte of file which is stored in a
853 direct item: except that if it equals 1
854 it is a symlink and if it equals
855 ~(__u32)0 there is no direct item. The
856 existence of this field really grates
857 on me. Let's replace it with a macro
858 based on sd_size and our tail
859 suppression policy? */
860 } __attribute__ ((__packed__)) u;
861 } __attribute__ ((__packed__));
862 //
863 // this is 44 bytes long
864 //
|
stat_data 条目使用的关键字中,offset 和 type 的值总是 0,这样就能确保 stat 数据是相同对象(object-id)中的第一个条目,从而能够加快访问速度。
与 ext2 的 ext2_indoe 结构对比一下就会发现,stat_data 中既没有记录数据块位置的地方,也没有记录删除时间,而这正是我们在 ext2/ext3 中恢复删除文件的基础,因此可以猜测得到,在reiserfs 文件系统中要想恢复已经删除的文件,难度会变得更大。
目录条目
目录条目中记录了目录项信息。目录条目由目录头和目录项数据(即文件或子目录名)组成。如果一个目录中包含的目录项太多,可以扩充到多个目录条目中存储。为了方便管理某个目录中子目录或文件的增减,目录条目也采用了与条目头类似的设计:从两端向中间扩充,其布局结构如图 5 所示。
图 5. 目录条目存储结构 
目录头是一个 reiserfs_de_head 结构,大小为 16 字节,其定义如清单 8 所示。
清单8. reiserfs_de_head 结构定义
920 /*
921 Q: How to get key of object pointed to by entry from entry?
922
923 A: Each directory entry has its header. This header has
deh_dir_id and deh_objectid fields, those are key
924 of object, entry points to */
925
926 /* NOT IMPLEMENTED:
927 Directory will someday contain stat data of object */
928
929 struct reiserfs_de_head {
930 __le32 deh_offset; /* third component of the directory entry key */
931 __le32 deh_dir_id; /* objectid of the parent directory of the object,
932 that is referenced by directory entry */
933 __le32 deh_objectid; /* objectid of the object, that is referenced */
/* by directory entry */
934 __le16 deh_location; /* offset of name in the whole item */
935 __le16 deh_state; /* whether 1) entry contains stat data (for future),
936 and 2) whether entry is hidden (unlinked) */
937 } __attribute__ ((__packed__));
|
reiserfs_de_head 结构中包含了 deh_dir_id 和 deh_objectid fields 这两个字段,它们就是其父目录关键字中对应的两个字段。deh_offset 的 7 到 30 位是文件名的 hash 值,0 到 6 位用来解决 hash 冲突的问题(reiserfs 中可以使用 3 种 hash 函数:tea、rupasov 和 r5,默认为 r5)。文件名的位置保存在 deh_location 字段中,而 deh_state 的第 2 位表示该目录条目是否是可见的(该位为 1 则表示该目录条目是可见的,为 0 表示不可见)。文件名是一个字符串,以空字符结束,按照 8 字节对齐。
直接条目与间接条目
在 reiserfs 中,文件数据可以通过两种方式进行存取:直接条目(direct item)和间接条目(indirect item)。对于小文件来说,文件数据本身和 stat 数据可以一起存储到叶子节点中,这种条目就称为直接条目。直接条目就采用图 4 所示的存储结构,不过每个条目数据体就是文件数据本身。对于大文件来说,单个叶子节点无法存储下所有数据,因此会将部分数据存储到未格式化数据块中,并通过间接条目中存储的指针来访问这些数据块。未格式化数据块都是整块使用的,最后一个未格式化数据块中可能会遗留一部分剩余空间,大小是由对应条目头的 ih_free_space_reserved 字段指定的。图 6 给出了间接条目的存储结构。
图 6. 间接条目存储结构 
对于缺省的 4096 字节的数据块来说,一个间接条目所能存储的数据最大可达 4048 KB(4096*(4096-48)/4 字节),更大的文件需要使用多个间接条目进行存储,它们之间的顺序是通过关键字中的 offset 进行标识的。
另外,文件末尾不足一个数据块的部分也可以像小文件一样存储到直接条目中,这种技术就称为尾部封装(tail packing)。在这种情况下,存储一个文件至少需要使用一个间接条目和一个直接条目。
实例分析
下面让我们来看一个实际的例子,以便了解 reiserfs 中的实际情况是什么样子。首先让我们来创建一个 reiserfs 文件系统,这需要在系统中安装 reiserfs-utils 包,其中包含的内容如清单 9 所示。
清单9. reiserfs-utils 包中包含的文件
[root@vmfc8 reiserfs]# rpm -ql reiserfs-utils /sbin/debugreiserfs /sbin/fsck.reiserfs /sbin/mkfs.reiserfs /sbin/mkreiserfs /sbin/reiserfsck /sbin/reiserfstune /sbin/resize_reiserfs /usr/share/doc/reiserfs-utils-3.6.19 /usr/share/doc/reiserfs-utils-3.6.19/README /usr/share/man/man8/debugreiserfs.8.gz /usr/share/man/man8/mkreiserfs.8.gz /usr/share/man/man8/reiserfsck.8.gz /usr/share/man/man8/reiserfstune.8.gz /usr/share/man/man8/resize_reiserfs.8.gz |
mkreiserfs 命令用来创建 reiserfs 文件系统,debugreiserfs 用来查看 reiserfs 文件系统的详细信息,如清单 10 所示。
清单10. 创建 reiserfs 文件系统
[root@ vmfc8 reiserfs]# echo y | mkreiserfs /dev/sda2
[root@vmfc8 reiserfs]# debugreiserfs -m /dev/sda2
debugreiserfs 3.6.19 (2003 www.namesys.com)
Filesystem state: consistent
Reiserfs super block in block 16 on 0x802 of format 3.6 with standard journal
Count of blocks on the device: 977952
Number of bitmaps: 30
Blocksize: 4096
Free blocks (count of blocks - used [journal, bitmaps, data, reserved] blocks): 969711
Root block: 8211
Filesystem is clean
Tree height: 2
Hash function used to sort names: "r5"
Objectid map size 2, max 972
Journal parameters:
Device [0x0]
Magic [0x28ec4899]
Size 8193 blocks (including 1 for journal header) (first block 18)
Max transaction length 1024 blocks
Max batch size 900 blocks
Max commit age 30
Blocks reserved by journal: 0
Fs state field: 0x0:
sb_version: 2
inode generation number: 0
UUID: 02e4b98a-bdf3-4654-9cae-89e38970f43c
LABEL:
Set flags in SB:
ATTRIBUTES CLEAN
Bitmap blocks are:
#0: block 17: Busy (0-8211) Free(8212-32767)
used 8212, free 24556
#1: block 32768: Busy (32768-32768) Free(32769-65535)
used 1, free 32767
…
#29: block 950272: Busy (950272-950272) Free(950273-977951) Busy(977952-983039)
used 5089, free 27679
|
从输出结果中可以看出,这是大约是一个 4GB 的分区,总共划分成 977952 个 4096B 大小的数据块;而超级块是第 16 个数据块(从 0 开始计算)。格式化过程中占用了其中的 8241 个数据块,其中从第 18 个数据块开始的 8193 个数据块用于日志(第 8210 数据块供日志头使用)。这个 B+ 树的根节点保存在该分区的第 8211 个数据块中。另外,数据块位图总共占用了 30 个数据块,-m 参数给出了这些数据块位图所占用的数据块的具体位置,这与前文中的介绍是完全吻合的。
我们真正关心的是存储实际数据的部分,从中可以了解在 reiserfs 中是如何对文件进行访问的。下面让我们来看一个实际文件系统的例子。
清单11. 分析 8211 数据块的内容
[root@vmfc8 reiserfs]# mount /dev/sda2 /tmp/test [root@vmfc8 reiserfs]# dd if=/dev/sda2 of=block.8211 bs=4096 count=1 skip=8211 [root@vmfc8 reiserfs]# hexdump –C block.8211.hex |
block.8211.hex 文件中就是根节点中的实际数据,图 7 给出了一个更为清晰的分析结果。
图 7. 新文件系统根节点的数据分析 
从图 7 中可以清楚地看出,这是一个格式化叶子节点(深度为 1),其中包含 4 个条目:两个是 STAT 条目,另外两个是目录条目。实际上,它们分别是当前目录和其父目录。继续分析就会发现,当前目录中只包含两个目录项:当前目录及其父目录,因此这是一个空目录。
小结
总体来说,reiserfs 所采用的设计很多都是专门针对如何充分提高空间利用率和改进小文件的访问速度。与 ext2/ext3 不同,reiserfs 并不以固定大小的块为单位给文件分配存储空间。相反,它会恰好分配文件大小的磁盘空间。另外,reiserfs 还包括了围绕文件末尾而专门设计的尾部封装方案,将文件名和文件数据(或部分数据)共同保存在 B+ 树的叶子节点中,而不会像 ext2 那样将数据单独保存在一个磁盘上的数据块中,然后使用一个指针指向这个数据块的位置。
这种设计会带来两个优点。首先,它可以极大地改进小文件的性能。由于文件数据和 stat_data(对应于 ext2 中的 inode)信息都是紧邻保存的,只需要一次磁盘 I/O 就可以将这些数据全部读出。其次,可以有效提高对磁盘空间的利用率。统计表明,reiserfs 采用这种设计之后,可以比相应的 ext2 文件系统多存储超过 6% 的数据。
不过,尾部封装的设计可能会对性能稍有影响,因为它每次文件发生修改时,都需要重新对尾部数据进行封装。由于这个原因,reiserfs 的尾部封装特性被设计为可以关闭的,这样就为管理员在性能和存储效率之间可以提供一个选择。对于性能非常关键的应用程序来说,管理员可以使用 notail 选项禁用这个特性,从而牺牲一部分磁盘空间来获得更好的性能。
与 ext2/ext3 相比,在处理小于 4KB 的文件时,reiserfs 的速度通常会快 10 到 15 倍。这对于新闻组、HTTP 缓存、邮件发送系统以及其他一些小文件性能非常重要的应用程序来说是非常有益的。
(责任编辑:A6)
本站文章仅代表作者观点,本站仅传递信息,并不表示赞同或反对.转载本站点内容时请注明来自www.linuxeden.com-Linux伊甸园。如不注明,www.linuxeden.com将根据《互联网著作权行政保护办法》追究其相应法律责任。