Social Recommendation with Strong and Weak Ties 学习笔记
Social Recommendation with Strong and Weak Ties 学习笔记ing
- 摘要
- 介绍
- 2 相关工作
- 3 强弱联系
- 4、TBPR模型:有强弱联系的BPR模型
- 4.1 物品分类
- 4.2 对物品排序
- 4.3 TBPR两种变形形式
- 5. 参数学习策略
- 5.1 优化目标
- 6 实验评估
- 6.1 实验设置
困惑1:对joint物品的排序顺序,为什么在最前面?
摘要
随着在线社交网络的爆炸式增长,人们已经广泛的意识到社交信息对推荐系统是非常有用的。社交推荐方法能够很好的应对冷启动问题,因此可以大幅度提升预测准确性。凭借直觉,我们还可以得知,在社交关系的影响下,用户很容易和他们朋友消费过的东西建立联系。尽管已经有很多人研究社交推荐,但是很少有人把注意力放在强联系和弱联系上,这两个是社交科学中被充分证明的两个概念。在这篇文章中,我们判别社交推荐中强弱联系的影响,我们使用邻居重复数去估计联系的强度,并且结合BPR模型去判别联系的强弱。我们提出了一种基于EM模型的判别社交网络中的强弱联系算法根据最优推荐准确率去学习用户和物品的潜在特征向量。我们在真实数据集上进行实验,并且发现我们提出的方法比现有模型在准确性上有了显著的提升。
介绍
首先介绍了一些常用的社交推荐方法,比如显式反馈中使用CF协同过滤算法,在隐式反馈中pariwise排序算法效果更好。这种算法主要学习用户喜好中物品的排序。BPR(Bayesian Personalized Ranking)框架结构是一种非常基础的pairwise排序方法。一言以蔽之,算法的核心思想就是根据用户比起没有观察结果的物品更喜欢有观察结果的物品这个基本假设然后去学习一个个性化排序。这里,一个被观察的物品代表着用户消费了这个物品,所以我们在文中交替使用这两个词,在论文1中作者证明了很多评分方法都可以融入BPR模型去学习排序方法,包括矩阵分解。
推荐系统中一个经常需要面对的问题就是数据稀疏,因为物品很多,但是用户通常只会消费很少的一部分。一个更困难的问题就是当新用户加入系统时,因为没有历史信息所以要面临冷启动问题。其中zhao等人剔除出了Social BPR(SBPR)模型,去假设在所有没有观察数据的物品中,用户更喜欢和他们有社交联系的人消费过的物品。Q&A场景中社交联系的强弱,但是据我们所知,还没有人在推荐系统中研究社交联系的强弱,但是社交联系的强弱会严重影响推荐质量。在 Granovetter 非常有影响力的一篇文章2中,他介绍了不同的社交联系,强联系、弱联系、缺失联系,并且得出弱联系是新信息在社交网络传播的主要原因的结论。在接下来的访查[^22]中他又发现很多人找到工作的信息其实来源于他的弱联系而不是强联系。
这些现象让我们想去探究在社交推荐中区分强弱联系是不是能对推荐结果进行改善。但是我们面临着两个主要问题:1、怎么在给定的社交网络中去区别强弱联系。社交领域中有这么一个双值定义:强联系是仅仅由两个人之间的交互关系决定,和剩余网络部分无关,比如Granovetter用联系的频率去区分强弱联系,这是简单又符合直觉的,但是这个需要用户的活跃数据,但是因为安全和因素保护的问题,这个数据很难在在线社交网络中获取。 2、假定我们分类正确,我们怎么把这个关系融入现有的排序方法中去改善推荐准确性。
本文中我们直面这些困难,我们首先采用了一个网络拓扑结构中固有的一个特征Jaccard系数来计算连接强度。直觉的,Jaccard系数捕捉了用户朋友圈中的重合度。我们的选择被一个大型移动电话图同意,我们认为当联系大于一个判决门限时就是强联系,否则就是弱联系。
接下来我们拓展了BPR模型,并且提出了一个统一的学习框架结果,最终完成了两个任务(1)根据最优推荐准确性分类强弱联系(2)利用强弱联系建立了一个排序模型。我们采用Expectation-Maximization algorithm(EM算法)去学习社交联系和其他参数模型包括用户和物品的隐藏特征向量。我们在是个真实数据集上的实验证明了我们的方法的优越性。
总体来说,我们做了以下贡献:
-
我们意识到强弱联系在社交领域的作用,并且提出应该把这个重要概念融入社交推荐中。
-
根据强弱联系我们在BPR模型中提出了一个更细粒度的分类方法。
-
我们使用EM算法去学习最优判决门限和其余参数在我们的扩展的BPR模型中。
-
我们在实际数据集中验证了我们的方法,在预测准确率和召回率上都优于其他模型。
在我们的认知中,这是第一篇在社交推荐中明显区别了强弱联系并把他们融进去提升推荐结果的文章。
我们先来定义一下本文研究的问题,在一个推荐系统中,用户集合 U U U,物品集合 I I I,并且有一个用户之间的社交网络,是一个无向图 G = ( u , e ) G = (u,e) G=(u,e),其中 u ∈ U u \in U u∈U代表每个独立的用户,边 ( u , v ) ∈ e (u,v) \in e (u,v)∈e代表了用户 u u u和用户 v v v之间的连接,我们知道每个用户 u u u的消费的物品的集合,我们的任务就是去生成一个个性化推荐列表(是所有物品的排序之和)。
2 相关工作
社交媒体中的社交联系:
在社交科学中社交联系已经被广泛研究了。上述研究中没有人把社交联系引入推荐系统,换句话说,已存的社交推荐中,并没有人考虑了不同的社交联系。
社交推荐:
简言之,社交推荐的目的就是应用信任和影响去解决冷启动问题,新用户因为没有反馈数据所以没有办法采用传统CF模型进行推荐的原因。Jamali 等人发现在Epinions数据集中,大约50%的数据都是冷启动用户(评分物品少于5个)。但是大多数方法都是针对显式反馈系统,但是收效甚微。
最近,Zhao等人扩展了BPR模型3,通过假定对于所有未观察过的物品,相对于其它物品一个用户会更喜欢和他有社交联系的人消费过的物品(在后文中我们称之为社交物品)。在他们的SBPR模型中,对于每一个用户 u u u,对于每一个自己消费过的物品 i i i和社交物品 j j j之间的相对喜好是被消费商品 j j j的用户 u u u的链接数量衰减的。也就是说,越多联系消费了 j j j商品,在用户 u u u的眼里,商品 i i i和 j j j之间的差别越小。他们同样讨论了替代情况,相反的假设是社交商品比起非社交商品能够收到更多负面信息。他们的实验证明这种替代的SBPR模型和前一种SBPR模型相比,效果并不是那么好。我们和SBPR模型不同的是我们通过添加正交的社交意识进入BPR模型。特别的,我们意识到区分强弱联系的重要性,并且通过引入这种区分扩展了BPR模型。主要的不同点在于对于社交物品的排序上。在SBPR模型中,社交物品是通过消费的人的数量进行排序的,但是在我们的模型中,排序是给予联系种类的。我们的实验结果表明我们的新模型比SBPR模型和vanilla BPR模型在预测准确率上更好。
3 强弱联系
强弱联系的理论第一次被Granovetter2提出,在人际交往中,强联系意味着亲密的朋友之间会有更高频率的交互行为,但是弱联系就意味着泛泛之交。在网络结构中,强联系通常会在一个密集的子图中聚集(比如图1之中的 ( u , v , w ) (u,v,w) (u,v,w)和 ( x , y , z ) (x,y,z) (x,y,z)),弱联系通常是连接两个不同部分的桥(比如图1中的(u,x))。
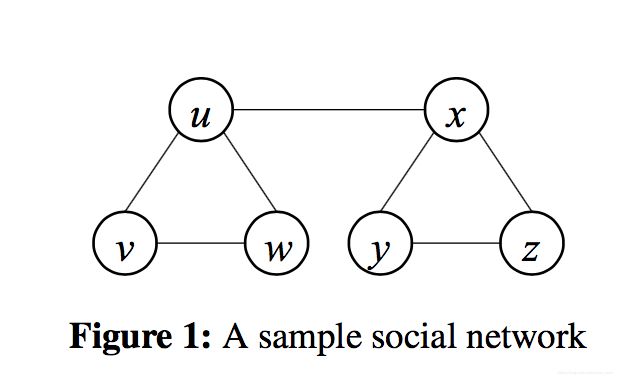
首先,我们认为节点 u u u如果不违背以下条件:用户 u u u有两个强联系 v v v和 w w w,但是 v v v和 w w w之间没有边连接,则满足强三元闭包性质。进而,如果一个节点 u u u满足这个性质并且有至少两个强联系,那么本地桥一定是个弱连接。【本地桥定义:如果删除 ( u , v ) (u,v) (u,v)这条边回导致 u , v u,v u,v之间的路径距离一定大于等于3.】
因为弱联系不属于同一个社交圈是非常容易理解的,因为他们有不同的信息源,因此信息交互回包含更多的信息。把这个观点应用到社交推荐中,我们的观点就是被弱联系朋友消费的物品对这个用户会更有吸引力。比如,一个研究用很难从他亲密的合作伙伴中发现新的有趣的论文,因为他们通常专注于同样的话题,并且会看差不多类型的论文。相反的他会从更少合作的伙伴中引用的论文中发现更有趣的东西。
为了把强弱联系应用到社交推荐中,我们首先需要定义怎么去计算联系的强度,然后去分类联系。这里存在很多的可能性,首先就像第一部分提到的,社会学家使用动态评估法比如交互的频率,但是由于我们缺乏必要的数据,这个方法没办法实施。
我们从社区发现中寻找到了可替代的方法。首先先采用社区发现算法去把网络图 G = ( u , e ) G = (u,e) G=(u,e)划分成不同的子图。然后对于每一个边 ( u , v ) ∈ e (u,v)\in e (u,v)∈e,如果 u u u和 v v v属于同一个子图,这个连接就被定义为强连接,否则就定义为一个弱连接。但是还是存在一个关键性问题,尽管已经有了很多社区发现算法,但是并没有一个公认的黄金准则。也就是说,如果这个划分是一个不好的,社交系统很难判断这是一个不好的输入,也就是说推荐质量会依赖于一个外来的社区发现算法,并且这个算法推荐系统没办法控制,所以说这种方法是不受欢迎的。
考虑到上述所有事实,我们求助于节点相似矩阵,衡量两个节点在网络中邻居的重叠数。Onnela等人的研究4用实验证明了这个基本假设是正确的。他们发现(1)本地网络结构在一定程度上决定了联系的强度。(2)两个用户的联系越强,他们共同的朋友越多。此外,和交互交互不同,节点相似性是网络结构固有属性,不需要其它数据去计算。此外,和基于社交发现的算法不同的是,我们仍然可以选择对推荐系统最有用的联系分类方法。
更具体的说,我们采用了Jaccard系数,一种简单的评估方法,有效的捕捉了用户之间的重叠性。用 s t r e n g t h ( u , v ) strength(u,v) strength(u,v)代表每一个 ( u , v ) ∈ e (u,v)\in e (u,v)∈e的链接强度,我们有
(1) s t r e n g t h ( u , v ) = ∣ N u ∩ N v ∣ ∣ N u ∪ N v ∣ ( J a c c a r d ) strength(u,v)= \frac{|N_u\cap N_v|}{|N_u\cup N_v|}(Jaccard) \tag 1 strength(u,v)=∣Nu∪Nv∣∣Nu∩Nv∣(Jaccard)(1)
其中 N u ⊆ u N_u\subseteq u Nu⊆u代表着用户 U U U的联系集合,同理 v v v。如果 N u = N v = ϕ N_u=N_v=\phi Nu=Nv=ϕ,也就是说用户 u u u和用户 v v v都是孤立点,那么定义 s t r e n g t h ( u , v ) = 0 strength(u,v)=0 strength(u,v)=0.通过定义所有的联系强度都会落在[0,1]的区间内,这个定义有现实意义,随意给定两个用户 u u u和 v v v,他们的Jaccard系数和随机选择从 u , v u,v u,v的连接用户中选择一个用户,既是 u u u的邻居,又是 v v v的邻居的概率。
门限:
为了区分强弱联系,我们采用了一个简单的判决门限,对于一个给定的社交网络 G , θ G ∈ [ 0 , 1 ) , θ G G,\theta_G \in [0,1),\theta_G G,θG∈[0,1),θG代表了联系强度的判决门限。
( u , v ) i s { s t r o n g , if s t r e n g t h ( u , v ) > θ G w e a k , if s t r e n g t h ( u , v ) ≤ θ G (u,v) is \begin{cases}strong,&\text{if $strength(u,v)>\theta_G $}\\weak,&\text{if $strength(u,v)\leq \theta_G $}\end{cases} (u,v)is{strong,weak,if strength(u,v)>θGif strength(u,v)≤θG
定义 W u W_u Wu为用户 u u u所有弱联系的集合, W u = { v ∈ U : ( u , v ) ∈ e ∧ s t r e n g t h ( u , v ) ≤ θ G } W_u = \{v\in U: (u,v) \in e \wedge strength(u,v)\leq \theta_G\} Wu={v∈U:(u,v)∈e∧strength(u,v)≤θG}。相似的, S u S_u Su为用户 u u u所有强联系的集合, S u = { v ∈ U : ( u , v ) ∈ e ∧ s t r e n g t h ( u , v ) > θ G } S_u = \{v\in U: (u,v) \in e \wedge strength(u,v)>\theta_G\} Su={v∈U:(u,v)∈e∧strength(u,v)>θG}。并且 W u ∩ S u = ϕ W_u\cap S_u = \phi Wu∩Su=ϕ, W u ∪ S u = N u W_u\cup S_u = N_u Wu∪Su=Nu.
在我们的体系中, θ G \theta_G θG的值并不固定,而是需要我们模型学习的一个参数,所以说,在 G G G的强弱联系的分类结果和模型其它的参数一起学习,会导致最优的推荐准确率。
最终,我们发现其它的节点相似矩阵也可以用来定义联系强度,比如Adamic-Adar以及Katz score。但是我们认为节点相似矩阵的选择并不是我们这篇文章的重点,并且和我们提出的学习框架是无关的。
4、TBPR模型:有强弱联系的BPR模型
在这个部分,我们提出了我们的TBPR模型(BPR with Strong and weak Ties)。这个模型在BPR的基础上融入了强弱联系的区分,并且根据联系类型对社交物体进行排序。
4.1 物品分类
在定义完强弱联系之后,我们现在要去准备好TPBR模型中的一个关键要素:对于每一个用户我们需要把物品根据强弱联系分成五个类别,这些类别我们将在TBPR模型中用到。这里我们对没有被观测到的物品做了一个细粒度的划分,特别是社交物品,通过融入从网络图 G G G中获得的强弱联系信息,分类标准如下:
1.** 消费过的物品consumed items** 对于所有的用户 u ∈ U u\in U u∈U,用 C u s e l f ⊆ I C_u^{self} \subseteq I Cuself⊆I代表用户 u u u自己消费的物品集合。
2. 混合联系消费过的物品joint-tie-consumed(JTC) items 对于任意物品 i ∈ I − C u s e l f i \in I - C_u^{self} i∈I−Cuself至少被 u u u的一个强联系用户和一个弱联系用户消费过了,用 C u j o i n t C_u^{joint} Cujoint表示。
3. 强联系消费过的物品strong-tie-consumed(STC) items 用户没消费过的物品只被强联系用户消费过,用 C u s t r o n g C_u^{strong} Custrong表示。
4. 弱联系消费过的物品weak-tie-consumed(WTC) items 用户没消费过的物品只被强联系用户消费过,用 C u w e a k C_u^{weak} Cuweak表示。
5. 无消费关系的物品 non-consumed items没有联系用户消费过这个商品,用 C u n o n e C_u^{none} Cunone表示。
很显然, C u s e l f ∪ C u j o i n t ∪ C u s t r o n g ∪ C u w e a k ∪ C u n o n e = I C_u^{self}\cup C_u^{joint}\cup C_u^{strong} \cup C_u^{weak} \cup C_u^{none} = I Cuself∪Cujoint∪Custrong∪Cuweak∪Cunone=I,并且两两不相交,并且JTC,STC,WTC是用户 u u u的所有社交物品。
4.2 对物品排序
和原始的BPR模型相同,我们假定没有特殊的物品评分方法。为了展现结果和有效性,我们使用降维矩阵分解,这是一种协同过滤的最优算法。
假定系统中的每一个用户和物品都可以用d维潜在因子向量表示,分别为 P u ∈ R d P_u \in \mathbb{R}^d Pu∈Rd和 Q v ∈ R d Q_v \in \mathbb{R}^d Qv∈Rd.d代表潜在特征的数量。用户特征向量和物品特征向量的内积就评估了用户对这个物品的喜好。 r ^ u i = < P u , Q i > \hat{r}_{ui} = <P_u,Q_i> r^ui=<Pu,Qi>.因为这本文中我们处理的是二元反馈,所以对于所有的 u , i u,i u,i都存在 r ^ u i ∈ [ 0 , 1 ] \hat{r}_{ui} \in [0,1] r^ui∈[0,1].
在本文中,TBPR模型对这五个类型的物品根据用户喜好进行一个总体排序。受到BPR及其变种模型的优良效果的启发,我们同样假定用户相对于其它物品更喜欢消费过的物品。因此,消费物品的排序是最悠闲的,接下来就就是一个开放性的问题,用户是更喜欢WTC还是STC。尽管在第一部分我们提到社交领域中弱连接意味着更多新颖信息的传播,但是这个并不代表喜好。
为了解决上述问题,我们做了通过从DBLP上抽取的共同作者引用数据做了一个实验,DBLP和其它三分数据集(Epinions Douban Ciao)将会一起被使用去验证不同的方法的表现效果。
网络 g = ( U , e ) g = (U,e) g=(U,e)将按照以下步骤构建。首先,每个节点 v ∈ U v\in U v∈U要满足下述两个条件:(1)在至少十篇论文中是共同作者,(2)至少有一篇2009年之后发表的文章。如果两个作者 u , v u,v u,v。如果两个作者 u , v u,v u,v在2009年之前合作过至少一片论文,这里就会有一个无向边 ( u , v ) ∈ e (u,v)\in e (u,v)∈e最后留下13.6k的节点,107k条边。
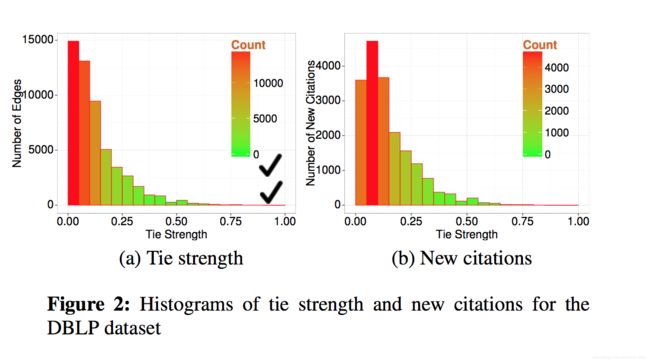
图2(a)展现了通过公示(1)计算出来的连接强度的分布。通过定义,两个作者 u , v u,v u,v有一个强联系,如果他们的合作伙伴中肯定有很大一部分重叠性。
接下来,我们要分析引用数据,去探究用户更喜欢弱连接用户还是强连接用户,我们对follow-up的引用场景更感兴趣。比如对于任意 ( u , v ) ∈ e (u,v) \in e (u,v)∈e,如果在2009年之前从在一篇论文只被 v v v引用,但没有被 u u u引用,但是 u u u在2009年之后引用了这篇文章,我们就认为 u u u用户follow v v v用户的引用,需要注意的是,这个定义删除了所用 u u u和 v v v的共同作者。图2b根据联系强度画出了follow-up的数量。我们可以看出这个分布非常偏向弱连接,这个暗示我们,但从数值上看,研究者更倾向于引用弱连接引用的论文。
结合其它作者的研究有以下结论,弱连接因为数量多所以整体很重要,强连接因为质量高所以个体很重要。
这个现象在我们的模型中,我们可以说WTC集合中的物品比STC集合中的物品更有用,但是针对于单个物品STC集合中的比WTC中的更有用。因此增加WTC物品的曝光度可以发现用户的潜在喜好,我们同样探究了如果把STC五片排在WTC物品之前。综上,我们尝试了所有的排序策略,所以我们将展示TBPR的两种推荐结果。
4.3 TBPR两种变形形式
我们现在对两种TBPR的变形形式进行定义,这两个之间的差别就在于WTC和STC物品的喜好排序。
TBPR-W(更喜欢弱联系):
喜好排序:
C u s e l f > C u j o i n t > C u s t r o n g > C u w e a k > C u n o n e C_u^{self} > C_u^{joint} > C_u^{strong} > C_u^{weak} > C_u^{none} Cuself>Cujoint>Custrong>Cuweak>Cunone
TBPR-S(更喜欢强联系):
喜好排序:
C u s e l f > C u j o i n t > C u w e a k > C u s t r o n g > C u n o n e C_u^{self} > C_u^{joint} > C_u^{weak} > C_u^{strong}> C_u^{none} Cuself>Cujoint>Cuweak>Custrong>Cunone
5. 参数学习策略
在这个部分,我们将展现如何使用EM算法对我们TBPR模型中参数进行优化。我们将在TBPR-W模型上进行展示,因为TBPR-S优化方法相同,所以我们删去了。
5.1 优化目标
使用 Θ \Theta Θ表示所有的参数集合,集合中包括强度判决门限 θ G \theta_G θG潜在特征向量 P u 和 Q i P_u和Q_i Pu和Qi,似然函数可以表示为:
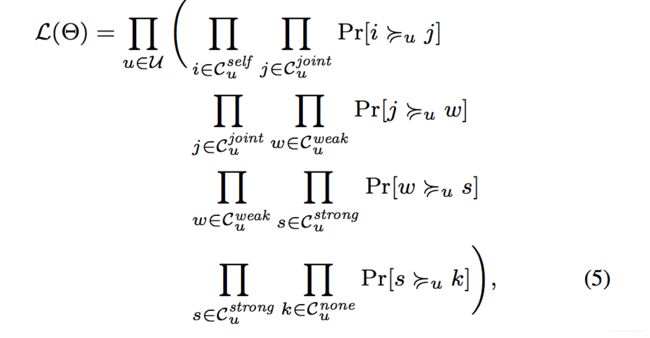
其中概率用sigmoid激活函数表示: δ ( x ) = 1 1 + e x p ( − x ) \delta(x) = \frac{1}{1+exp(-x)} δ(x)=1+exp(−x)1
比如,比起JTC物品,更喜欢消费过的商品的概率
KaTeX parse error: Expected 'EOF', got '&' at position 63: …at{x}_{uj}) \\ &̲=\frac{1}{1+exp…
其它概率定义方法类似。
结合强度判决门限
给定一个判决门限 θ G \theta_G θG强弱联系的区分度可以用下面的公式计算 g ( θ G ) = ( t ˉ s − θ G ) ( θ G − t ˉ w ) g(\theta_G) = (\bar{t}_s - \theta_G)(\theta_G-\bar{t}_w) g(θG)=(tˉs−θG)(θG−tˉw)
其中 t ˉ s \bar{t}_s tˉs是所有强联系的平均强度,同理 t ˉ w \bar{t}_w tˉw是弱联系的平均强度。
判决门限 θ G \theta_G θG一定要使分离度 g ( θ G ) g(\theta_G) g(θG)比较大,为了把判决门限囊括进我们的目标函数,我们添加了相对于STC物品更喜欢WTC物品的概率参数 1 g ( θ G ) \frac{1}{g(\theta_G)} g(θG)1进入目标函数。
6 实验评估
这个部分,我们在四个数据集上评估了TBPR-W和TBPR-S的质量
6.1 实验设置
数据集:DBLP、Ciao、Douban、Epinions
模型比较:TBPR-W、TBPR-S、BPR、SBPR、SBPR-N、Implicit MF (WRMF)、Random、MostPopular
评估指标:
recall@k、Precision@K、Area Under the Curve、Mean Average Precision、Mean Reciprocal Rank (MRR).Normalized Discounted Cumulative Gain (NDCG
S. Rendle et al., BPR: Bayesian personalized ranking from implicit feedback. In UAI, 2009. ↩︎
M. S. Granovetter. The strength of weak ties. American journal of sociology, pages 1360–1380, 1973. ↩︎ ↩︎
T.Zhao,J.McAuley,andI.King.Leveraging social connections to improve personalized ranking for collaborative filtering. In CIKM, pages 261–270, 2014. ↩︎
J.P.Onnelaetal.,Structureandtiestrengthsinmobilecommunication networks. Proceedings of the National Academy of Sciences, 104(18):7332–7336, 2007. ↩︎