java8新特性lambda和stream的学习和使用
一 java8 lambda表达式用法
1 什么是lambda表达式
Lambda表达式有两个特点:一是匿名函数,二是可传递。
匿名函数的应用场景是:
通常是在需要一个函数,但是又不想费神去命名一个函数的场合下使用Lambda表达式。lambda表达式所表示的匿名函数的内容应该是很简单的,如果复杂的话,干脆就重新定义一个函数了,使用lambda就有点过于执拗了。
可传递使用场景是:
就是将Lambda表达式传递给其他的函数,它当做参数,Lambda作为一种更紧凑的代码风格,使Java的语言表达能力得到提升。
2 lambda表达式语法
Lambda表达式在Java语言中引入了一个新的语法元素和操作符。这个操作符为"->",该操作符被称为Lambda操作符或箭头操作符,它将Lambda分为两个部分:
左侧:指定了Lambda表达式所需要的所有参数
右侧:指定了Lambda体,即Lambda表达式所要执行的功能。
在函数式编程语言中,Lambda表达式的类型是函数。而在Java中,Lambda表达式是对象,它们必须依附于一类特别的对象类型——函数式接口(Functional Interface)。
常见的语法格式:
语法格式一:无参,无返回值,Lambda体只需要一条语句。
Runnable r = () -> System.out.println("Hello Lambda!");
语法格式二:Lambda需要一个参数
Consumer con = (x) -> System.out.println(x);
语法格式三:Lambda只需要一个参数时,参数的小括号可以省略
Consumer con = x -> System.out.println(x);
语法格式四:Lambda需要两个参数,并且有返回值
Comparator com = (x, y) -> {
System.out.println("函数式接口");
return Integer.compare(x, y);
};
语法格式五:当Lambda体只有一条语句时,return与大括号可以省略
Comparator com = (x, y) -> Integer.compare(x, y);
语法格式六:数据类型可以省略,因为可由编译器推断得出,称为类型推断
BinaryOperator operator = (Long x, Long y) -> {
System.out.println("实现函数接口方法");
return x + y;
};
二 函数式接口
如果一个接口中,有且只有一个抽象的方法(Object类中的方法不包括在内),那这个接口就可以被看做是函数式接口。例如Runnable接口就是一个函数式接口:
@FunctionalInterface
public interface Runnable {
public abstract void run();
}
另外,如下接口:
@FunctionalInterface
public interface MyInterface {
void test();
String toString();
}
MyInterface这也是一个函数式接口,因为toString()是Object类中的方法,只是在这里进行了复写,不会增加接口中抽象方法的数量。
函数式接口实例的创建可以有三种方式:
1.lambda表达式
如果使用lambda表达式来创建一个函数式接口实例,那这个lambda表达式的入参和返回必须符合这个函数式接口中唯一的抽象方法的定义
list.forEach(item -> System.out.println(item));
2.方法引用
list.forEach(System.out::println);
方法引用的语法是 对象::方法名
3.构造方法引用
list.forEach(Test1::new);
Test1(Integer i){
System.out.println(i);
}
构造方法引用的语法是:类名::new
我们给Test1新添加了一个构造方法,该构造方法接收一个参数,不返回值
例如,java8以前,创建一个线程执行Runnable接口的方式一般如下:
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("线程执行");
}
}).start();
使用函数式编程即可使用如下方式:
new Thread(() -> System.out.println("线程执行")).start();
java8提供了一系列常见的函数式接口,最常用的如下几个:
Function:提供任意一种类型的参数,返回另外一个任意类型返回值。 R apply(T t);
Consumer:提供任意一种类型的参数,返回空值。 void accept(T t);
Supplier:参数为空,得到任意一种类型的返回值。T get();
Predicate:提供任意一种类型的参数,返回boolean返回值。boolean test(T t);
三 java8 stream用法
1 初步认识

举个例子:
@Before
public void init() {
random = new Random();
stuList = new ArrayList() {
{
for (int i = 0; i < 100; i++) {
add(new Student("student" + i, random.nextInt(50) + 50));
}
}
};
}
public class Student {
private String name;
private Integer score;
//-----getters and setters-----
}
//1列出班上超过85分的学生姓名,并按照分数降序输出用户名字
@Test
public void test1() {
List studentList = stuList.stream()
.filter(x->x.getScore()>85)
.sorted(Comparator.comparing(Student::getScore).reversed())
.map(Student::getName)
.collect(Collectors.toList());
System.out.println(studentList);
}
复制代码
列出班上分数超过85分的学生姓名,并按照分数降序输出用户名字,在java8之前我们需要三个步骤:
1)新建一个List newList,在for循环中遍历stuList,将分数超过85分的学生装入新的集合中
2)对于新的集合newList进行排序操作
3)遍历打印newList
这三个步骤在java8中只需要两条语句,如果仅仅需要打印,不需要保存新生产list的话实际上只需要一条,是不是非常方便。
2 stream的特性
stream主要具有如下三点特性,在之后我们会对照着详细说明
(1)stream不存储数据
(2)stream不改变源数据
(3)stream的延迟执行特性
通常我们在数组或集合的基础上创建stream,stream不会专门存储数据,对stream的操作也不会影响到创建它的数组和集合,对于stream的聚合、消费或收集操作只能进行一次,再次操作会报错,如下代码:
@Test
public void test1(){
Stream stream = Stream.generate(()->"user").limit(3);
stream.forEach(System.out::println);
stream.forEach(System.out::println);
}
输出结果如下:
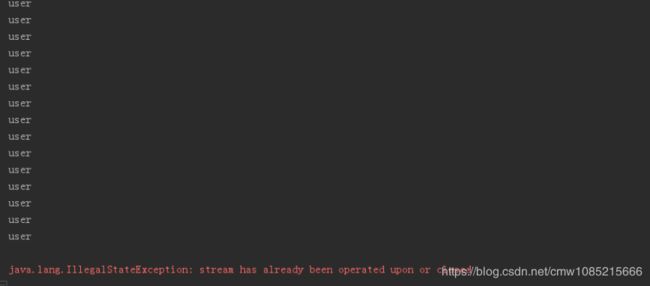
程序在正常完成一次打印工作后报错。
stream的操作是延迟执行的,在列出班上超过85分的学生姓名例子中,在collect方法执行之前,filter、sorted、map方法还未执行,只有当collect方法执行时才会触发之前转换操作
看如下代码:
public boolean filter(Student s) {
System.out.println("begin compare");
return s.getScore() > 85;
}
@Test
public void test() {
Stream stream = stuList.stream().filter(this::filter);
System.out.println("split-------------------------------------");
List studentList = stream.collect(toList());
System.out.println(studentList);
}
打印结果如下:
split-------------------------------------
begin compare
begin compare
begin compare
begin compare
begin compare
begin compare
begin compare
由此可以看出,在执行完filter时,没有实际执行filter中的方法,而是等到执行collect时才会执行,即是延迟执行的。
TIP:
当我们操作一个流的时候,并不会修改流底层的集合(即使集合是线程安全的),如果想要修改原有的集合,就无法定义流操作的输出。
由于stream的延迟执行特性,在聚合操作执行前修改数据源是允许的。
List wordList;
@Before
public void init() {
wordList = new ArrayList() {
{
add("a");
add("b");
add("c");
add("d");
add("e");
add("f");
add("g");
}
};
}
/**
* 延迟执行特性,在聚合操作之前都可以添加相应元素
*/
@Test
public void test() {
Stream words = wordList.stream();
wordList.add("END");
long n = words.distinct().count();
System.out.println(n);
}
最后打印的结果是8。如下代码是错误的:
/**
* 延迟执行特性,会产生干扰
* nullPointException
*/
@Test
public void test2(){
Stream words1 = wordList.stream();
words1.forEach(s -> {
System.out.println("s->"+s);
if (s.length() < 4) {
System.out.println("select->"+s);
wordList.remove(s);
System.out.println(wordList);
}
});
}
结果会报NPE空指针异常。
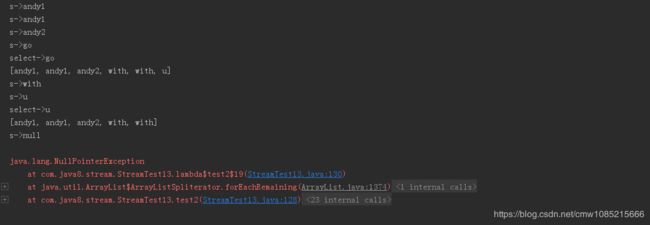
3 创建Stream
(1)通过数组创建
/**
* 通过数组创建流
*/
@Test
public void testArrayStream(){
//1.通过Arrays.stream
//1.1基本类型
int[] arr = new int[]{1,2,34,5};
IntStream intStream = Arrays.stream(arr);
//1.2引用类型
Student[] studentArr = new Student[]{new Student("s1",29),new Student("s2",27)};
Stream studentStream = Arrays.stream(studentArr);
//2.通过Stream.of
Stream stream1 = Stream.of(1,2,34,5,65);
//注意生成的是int[]的流
Stream stream2 = Stream.of(arr,arr);
stream2.forEach(System.out::println);
}
(2)通过集合创建流
/**
* 通过集合创建流
*/
@Test
public void testCollectionStream(){
List strs = Arrays.asList("11212","dfd","2323","dfhgf");
//创建普通流
Stream stream = strs.stream();
//创建并行流(即多个线程处理)
Stream stream1 = strs.parallelStream();
}
(3)创建空的流
@Test
public void testEmptyStream(){
//创建一个空的stream
Stream stream = Stream.empty();
}
(4)创建无限流
@Test
public void testUnlimitStream(){
//创建无限流,通过limit提取指定大小
Stream.generate(()->"number"+new Random().nextInt()).limit(100).forEach(System.out::println);
Stream.generate(()->new Student("name",10)).limit(20).forEach(System.out::println);
}
(5)创建规律的无限流
/**
* 产生规律的数据
*/
@Test
public void testUnlimitStream1(){
Stream.iterate(0,x->x+1).limit(10).forEach(System.out::println);
Stream.iterate(0,x->x).limit(10).forEach(System.out::println);
//Stream.iterate(0,x->x).limit(10).forEach(System.out::println);与如下代码意思是一样的
Stream.iterate(0, UnaryOperator.identity()).limit(10).forEach(System.out::println);
}
4 对stream的操作
(1)map:转换流,将一种类型的流转换为另外一种流
/**
* map把一种类型的流转换为另外一种类型的流
* 将String数组中字母转换为大写
*/
@Test
public void testMap() {
String[] arr = new String[]{"yes", "YES", "no", "NO"};
Arrays.stream(arr).map(x -> x.toLowerCase()).forEach(System.out::println);
}
将所有的子串转换为小写字符串并打印。map接收一个Function
(2) filter:过滤流,过滤流中的元素
@Test
public void testFilter(){
Integer[] arr = new Integer[]{1,2,3,4,5,6,7,8,9,10};
Arrays.stream(arr).filter(x->x>3&&x<8).forEach(System.out::println);
}
filter接收一个Predicate函数接口参数,boolean test(T t);即接收一个参数,返回boolean类型。
(3)flapMap:拆解流,将流中每一个元素拆解成一个流
/**
* flapMap:拆解流
*/
@Test
public void testFlapMap1() {
String[] arr1 = {"a", "b", "c", "d"};
String[] arr2 = {"e", "f", "c", "d"};
String[] arr3 = {"h", "j", "c", "d"};
// Stream.of(arr1, arr2, arr3).flatMap(x -> Arrays.stream(x)).forEach(System.out::println);
Stream.of(arr1, arr2, arr3).flatMap(Arrays::stream).forEach(System.out::println);
}
flatMap接收一个Function
(4)sorted:对流进行排序
String[] arr1 = {"abc","a","bc","abcd"};
/**
* Comparator.comparing是一个键提取的功能
* 以下两个语句表示相同意义
*/
@Test
public void testSorted1_(){
/**
* 按照字符长度排序
*/
Arrays.stream(arr1).sorted((x,y)->{
if (x.length()>y.length())
return 1;
else if (x.length()(5)提取流和组合流
@Before
public void init(){
arr1 = new String[]{"a","b","c","d"};
arr2 = new String[]{"d","e","f","g"};
arr3 = new String[]{"i","j","k","l"};
}
/**
* limit,限制从流中获得前n个数据
*/
@Test
public void testLimit(){
Stream.iterate(1,x->x+2).limit(10).forEach(System.out::println);
}
/**
* skip,跳过前n个数据
*/
@Test
public void testSkip(){
// Stream.of(arr1).skip(2).limit(2).forEach(System.out::println);
Stream.iterate(1,x->x+2).skip(1).limit(5).forEach(System.out::println);
}
/**
* 可以把两个stream合并成一个stream(合并的stream类型必须相同)
* 只能两两合并
*/
@Test
public void testConcat(){
Stream stream1 = Stream.of(arr1);
Stream stream2 = Stream.of(arr2);
Stream.concat(stream1,stream2).distinct().forEach(System.out::println);
}
(6)聚合操作
@Before
public void init(){
arr = new String[]{"b","ab","abc","abcd","abcde"};
}
/**
* max、min
* 最大最小值
*/
@Test
public void testMaxAndMin(){
Stream.of(arr).max(Comparator.comparing(String::length)).ifPresent(System.out::println);
Stream.of(arr).min(Comparator.comparing(String::length)).ifPresent(System.out::println);
}
/**
* count
* 计算数量
*/
@Test
public void testCount(){
long count = Stream.of(arr).count();
System.out.println(count);
}
/**
* findFirst
* 查找第一个
*/
@Test
public void testFindFirst(){
String str = Stream.of(arr).parallel().filter(x->x.length()>3).findFirst().orElse("noghing");
System.out.println(str);
}
/**
* findAny
* 找到所有匹配的元素
* 对并行流十分有效
* 只要在任何片段发现了第一个匹配元素就会结束整个运算
*/
@Test
public void testFindAny(){
Optional optional = Stream.of(arr).parallel().filter(x->x.length()>3).findAny();
optional.ifPresent(System.out::println);
}
/**
* anyMatch
* 是否含有匹配元素
*/
@Test
public void testAnyMatch(){
Boolean aBoolean = Stream.of(arr).anyMatch(x->x.startsWith("a"));
System.out.println(aBoolean);
}
@Test
public void testStream1() {
Optional optional = Stream.of(1,2,3).filter(x->x>1).reduce((x,y)->x+y);
System.out.println(optional.get());
}
5 Optional类型
通常聚合操作会返回一个Optional类型,Optional表示一个安全的指定结果类型,所谓的安全指的是避免直接调用返回类型的null值而造成空指针异常,调用optional.ifPresent()可以判断返回值是否为空,或者直接调用ifPresent(Consumer consumer)在结果不为空时进行消费操作;调用optional.get()获取返回值。通常的使用方式如下:
@Test
public void testOptional() {
List list = new ArrayList() {
{
add("user1");
add("user2");
}
};
Optional opt = Optional.of("andy with u");
opt.ifPresent(list::add);
list.forEach(System.out::println);
}
使用Optional可以在没有值时指定一个返回值
@Test
public void testOptional2() {
Integer[] arr = new Integer[]{4,5,6,7,8,9};
Integer result = Stream.of(arr).filter(x->x>9).max(Comparator.naturalOrder()).orElse(-1);
System.out.println(result);
Integer result1 = Stream.of(arr).filter(x->x>9).max(Comparator.naturalOrder()).orElseGet(()->-1);
System.out.println(result1);
Integer result2 = Stream.of(arr).filter(x->x>9).max(Comparator.naturalOrder()).orElseThrow(RuntimeException::new);
System.out.println(result2);
}
采用Optional.empty()创建一个空的Optional,使用Optional.of()创建指定值的Optional。同样也可以调用Optional对象的map方法进行Optional的转换,调用flatMap方法进行Optional的迭代
@Test
public void testStream1() {
Optional studentOptional = Optional.of(new Student("user1",21));
Optional optionalStr = studentOptional.map(Student::getName);
System.out.println(optionalStr.get());
}
public static Optional inverse(Double x) {
return x == 0 ? Optional.empty() : Optional.of(1 / x);
}
public static Optional squareRoot(Double x) {
return x < 0 ? Optional.empty() : Optional.of(Math.sqrt(x));
}
/**
* Optional的迭代
*/
@Test
public void testStream2() {
double x = 4d;
Optional result1 = inverse(x).flatMap(StreamTest7::squareRoot);
result1.ifPresent(System.out::println);
Optional result2 = Optional.of(4.0).flatMap(StreamTest7::inverse).flatMap(StreamTest7::squareRoot);
result2.ifPresent(System.out::println);
}
6 收集结果
Student[] students;
@Before
public void init(){
students = new Student[100];
for (int i=0;i<30;i++){
Student student = new Student("user",i);
students[i] = student;
}
for (int i=30;i<60;i++){
Student student = new Student("user"+i,i);
students[i] = student;
}
for (int i=60;i<100;i++){
Student student = new Student("user"+i,i);
students[i] = student;
}
}
@Test
public void testCollect1(){
/**
* 生成List
*/
List list = Arrays.stream(students).collect(Collectors.toList());
list.forEach((x)-> System.out.println(x));
/**
* 生成Set
*/
Set set = Arrays.stream(students).collect(Collectors.toSet());
set.forEach((x)-> System.out.println(x));
/**
* 如果包含相同的key,则需要提供第三个参数,否则报错
*/
Map map = Arrays.stream(students).collect(Collectors.toMap(Student::getName,Student::getScore,(s,a)->s+a));
map.forEach((x,y)-> System.out.println(x+"->"+y));
}
/**
* 生成数组
*/
@Test
public void testCollect2(){
Student[] s = Arrays.stream(students).toArray(Student[]::new);
for (int i=0;i s = Arrays.stream(students).collect(toCollection(HashSet::new));
s.forEach(System.out::println);
}
/**
* 统计
*/
@Test
public void testCollect4(){
IntSummaryStatistics summaryStatistics = Arrays.stream(students).collect(Collectors.summarizingInt(Student::getScore));
System.out.println("getAverage->"+summaryStatistics.getAverage());
System.out.println("getMax->"+summaryStatistics.getMax());
System.out.println("getMin->"+summaryStatistics.getMin());
System.out.println("getCount->"+summaryStatistics.getCount());
System.out.println("getSum->"+summaryStatistics.getSum());
}
7 分组和分片
分组和分片的意义是,将collect的结果集展示为Map
Student[] students;
@Before
public void init(){
students = new Student[100];
for (int i=0;i<30;i++){
Student student = new Student("user1",i);
students[i] = student;
}
for (int i=30;i<60;i++){
Student student = new Student("user2",i);
students[i] = student;
}
for (int i=60;i<100;i++){
Student student = new Student("user3",i);
students[i] = student;
}
}
/**
* 按照名称分组
*
*/
@Test
public void testGroupBy1(){
Map> map = Arrays.stream(students).collect(Collectors.groupingBy(Student::getName));
map.forEach((x,y)-> System.out.println(x+"->"+y));
}
/**
* 如果只有两类,使用partitioningBy会比groupingBy更有效率,按照分数是否大于50分组
*/
@Test
public void testPartitioningBy(){
Map> map = Arrays.stream(students).collect(Collectors.partitioningBy(x->x.getScore()>50));
map.forEach((x,y)-> System.out.println(x+"->"+y));
}
/**
* downstream指定类型
*/
@Test
public void testGroupBy2(){
Map> map = Arrays.stream(students).collect(Collectors.groupingBy(Student::getName,Collectors.toSet()));
map.forEach((x,y)-> System.out.println(x+"->"+y));
}
/**
* downstream 聚合操作
*/
@Test
public void testGroupBy3(){
/**
* counting
*/
Map map1 = Arrays.stream(students).collect(Collectors.groupingBy(Student::getName,Collectors.counting()));
map1.forEach((x,y)-> System.out.println(x+"->"+y));
/**
* summingInt
*/
Map map2 = Arrays.stream(students).collect(Collectors.groupingBy(Student::getName,Collectors.summingInt(Student::getScore)));
map2.forEach((x,y)-> System.out.println(x+"->"+y));
/**
* maxBy
*/
Map> map3 = Arrays.stream(students).collect(groupingBy(Student::getName,maxBy(Comparator.comparing(Student::getScore))));
map3.forEach((x,y)-> System.out.println(x+"->"+y));
/**
* mapping
*/
Map> map4 = Arrays.stream(students).collect(Collectors.groupingBy(Student::getName,Collectors.mapping(Student::getScore,Collectors.toSet())));
map4.forEach((x,y)-> System.out.println(x+"->"+y));
}
8 原始类型流
在数据量比较大的情况下,将基本数据类型(int,double…)包装成相应对象流的做法是低效的,因此,我们也可以直接将数据初始化为原始类型流,在原始类型流上的操作与对象流类似,我们只需要记住两点
1.原始类型流的初始化
2.原始类型流与流对象的转换
DoubleStream doubleStream;
IntStream intStream;
/**
* 原始类型流的初始化
*/
@Before
public void testStream1(){
doubleStream = DoubleStream.of(0.1,0.2,0.3,0.8);
intStream = IntStream.of(1,3,5,7,9);
IntStream stream1 = IntStream.rangeClosed(0,100);
IntStream stream2 = IntStream.range(0,100);
}
/**
* 流与原始类型流的转换
*/
@Test
public void testStream2(){
Stream stream = doubleStream.boxed();
doubleStream = stream.mapToDouble(Double::new);
}
9 并行流
可以将普通顺序执行的流转变为并行流,只需要调用顺序流的parallel() 方法即可,如Stream.iterate(1, x -> x + 1).limit(10).parallel()。
1) 并行流的执行顺序
我们调用peek方法来瞧瞧并行流和串行流的执行顺序,peek方法顾名思义,就是偷窥流内的数据,peek方法声明为Stream peek(Consumer action);加入打印程序可以观察到通过流内数据,见如下代码:
public void peek1(int x) {
System.out.println(Thread.currentThread().getName() + ":->peek1->" + x);
}
public void peek2(int x) {
System.out.println(Thread.currentThread().getName() + ":->peek2->" + x);
}
public void peek3(int x) {
System.out.println(Thread.currentThread().getName() + ":->final result->" + x);
}
/**
* peek,监控方法
* 串行流和并行流的执行顺序
*/
@org.junit.Test
public void testPeek() {
Stream stream = Stream.iterate(1, x -> x + 1).limit(10);
stream.peek(this::peek1).filter(x -> x > 5)
.peek(this::peek2).filter(x -> x < 8)
.peek(this::peek3)
.forEach(System.out::println);
}
@Test
public void testPeekPal() {
Stream stream = Stream.iterate(1, x -> x + 1).limit(10).parallel();
stream.peek(this::peek1).filter(x -> x > 5)
.peek(this::peek2).filter(x -> x < 8)
.peek(this::peek3)
.forEach(System.out::println);
}
串行流打印结果如下:

并行流打印结果如下:
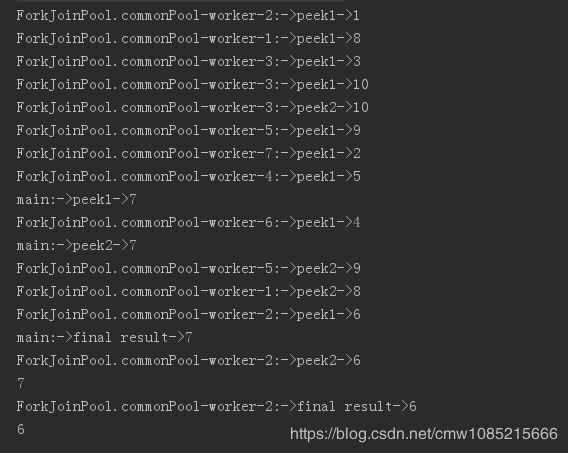
咋看不一定能看懂,我们用如下的图来解释

我们将stream.filter(x -> x > 5).filter(x -> x < 8).forEach(System.out::println)的过程想象成上图的管道,我们在管道上加入的peek相当于一个阀门,透过这个阀门查看流经的数据,
(1)当我们使用顺序流时,数据按照源数据的顺序依次通过管道,当一个数据被filter过滤,或者经过整个管道而输出后,第二个数据才会开始重复这一过程
(2)当我们使用并行流时,系统除了主线程外启动了七个线程(我的电脑是4核八线程)来执行处理任务,因此执行是无序的,但同一个线程内处理的数据是按顺序进行的。
2) sorted()、distinct()等对并行流的影响
sorted()、distinct()是元素相关方法,和整体的数据是有关系的,map,filter等方法和已经通过的元素是不相关的,不需要知道流里面有哪些元素 ,并行执行和sorted会不会产生冲突呢?
结论:1.并行流和排序是不冲突的,2.一个流是否是有序的,对于一些api可能会提高执行效率,对于另一些api可能会降低执行效率,3.如果想要输出的结果是有序的,对于并行的流需要使用forEachOrdered(forEach的输出效率更高)
我们做如下实验:
/**
* 生成一亿条0-100之间的记录
*/
@Before
public void init() {
Random random = new Random();
list = Stream.generate(() -> random.nextInt(100)).limit(100000000).collect(toList());
}
/**
* tip
*/
@org.junit.Test
public void test1() {
long begin1 = System.currentTimeMillis();
list.stream().filter(x->(x > 10)).filter(x->x<80).count();
long end1 = System.currentTimeMillis();
System.out.println("串行流执行时间:" + (end1-begin1));
list.stream().parallel().filter(x->(x > 10)).filter(x->x<80).count();
long end2 = System.currentTimeMillis();
System.out.println("并行流执行时间" + (end2-end1));
long begin1_ = System.currentTimeMillis();
list.stream().filter(x->(x > 10)).filter(x->x<80).distinct().sorted().count();
long end1_ = System.currentTimeMillis();
System.out.println("串行流执行排序时间" + (end1-begin1));
list.stream().parallel().filter(x->(x > 10)).filter(x->x<80).distinct().sorted().count();
long end2_ = System.currentTimeMillis();
System.out.println("并行流执行排序时间" + (end2_-end1_));
}
执行结果如下:

可见,对于串行流.distinct().sorted()方法对于运行时间没有影响,但是对于串行流,会使得运行时间大大增加,因此对于包含sorted、distinct()等与全局数据相关的操作,不推荐使用并行流。