Faiss:Facebook开源的相似性搜索类库
Facebook在今年3月份发布了Facebook AI相似性搜索(简称Faiss)项目,该项目提供的类库可以从多媒体文档中快速搜索出相似的条目——这个场景下的挑战是基于查询的传统搜索引擎无法解决的。Facebook 人工智能实验室(FAIR)基于十亿级别的数据集构建了最近邻搜索算法的实现,这比之前介绍的已知文献中在GPU上实现的最先进且最快的k-selection算法还要快大约8.5倍,因此创造了新的记录,包括第一个基于十亿高维向量构建的k最近邻图。
\\关于相似性搜索
\\传统的数据库是由包含符号信息的结构化数据表组成。比如,一个图片集可以表示为一个数据表,每行代表一个被索引的图片,包含图片标识符和描述文字之类的信息;每一行也可以与其他数据表中的实体关联起来,比如某个用户的一张图片可以与用户姓名表建立关联。
\\像文本嵌入(word2vec)或者卷积神经网络(CNN)描述符这样通过深度学习训练出的AI工具,都可以生成高维向量。这种表示远比一个固定的符号表示更加强大和灵活,正如后文将解释的那样。然而使用SQL查询的传统数据库并不适用这些新的表示方式。首先,海量多媒体信息的涌入产生了数十亿的向量;其次,且更重要的是,查找相似实体意味着查找相似的高维向量,如果只是使用标准查询语言这将非常低效和困难。
\\如何使用向量表示?
\\假设有一张建筑物的图片——比如某个你不记得名字的中等规模城市的市政大厅——然后你想在图片集中查找所有该建筑物的图片。由于不记得城市的名字,此时传统SQL中常用的key/value查询就帮不上忙了。
\\这就是相似性搜索的用武之地了。图片的向量化表示旨在为相似的图片生成相似向量,这里相似向量定义为欧氏距离最近的向量。
\\向量化表示的另一个应用是分类。假设需要一个分类器,来判定某个相册中的哪些图片属于菊花。分类器的训练过程众所周知:给算法分别输入菊花的图片和非菊花的图片(比如汽车、羊、玫瑰、矢车菊等);如果分类器是线性的,那么就输出一个分类向量,其属性值是它与图片向量的点积,反映了该图片包含菊花的可能性;然后分类器可以与相册中所有图片计算点积,并返回点积最大的图片。这种查询就是“最大内积”搜索。
\\所以,对于相似性搜索和分类,我们需要做下列处理:
\\- 给定一个查询向量,返回与该向量的欧式距离最近的数据库对象列表。\\t
- 给定一个查询向量,返回与该向量点积最大的数据库对象列表。\
一个额外的挑战是,要在一个超大规模比如数十亿向量上做这些运算。
\\软件包
\\现有软件工具都不足以完成上述数据库检索操作。传统的SQL数据库系统也不太适合,因为它们是为基于哈希的检索或1维区间检索而优化的;像OpenCV等软件包中的相似性搜索功能在扩展性方面则严重受限;同时其他的相似性搜索类库主要适用于小规模数据集(比如,1百万大小的向量);另外的软件包基本是为发表论文而输出的学术研究产物,旨在展示某些特定设置下的效果。
\\
Faiss类库则解决了以上提到的种种局限,其优点如下:
\\- 提供了多种相似性搜索方法,支持各种各样的不同用法和功能集。\\t
- 特别优化了内存使用和速度。\\t
- 为最相关索引方法提供了最先进的GPU实现。\
相似性搜索评估
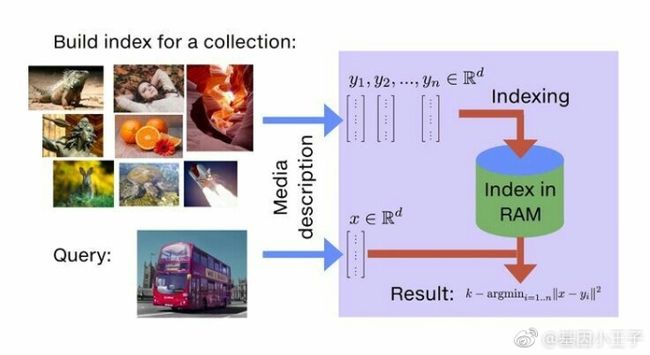
\\一旦从学习系统(从图片、视频、文本文件以及其他地方)抽取出向量,就能准备将其用于相似性搜索类库。
\\我们有一个暴力算法作为参考对比,该算法计算出了所有的相似度——非常精确和齐全——然后返回最相似的元素列表。这就提供了一个黄金标准的参考结果列表。需要注意的是,暴力算法的高效实现并不简单,一般依赖于其他组件的性能。
\\如果牺牲一些精度的话,比如允许与参考结果有一点点偏差,那么相似性搜索能快几个数量级。举个例子,如果一张图片的相似性搜索结果中的第一个和第二个交换了,可能并没有太大问题,因为对于一个给定的查询,它们可能都是正确结果。加快搜索速度还涉及到数据集的预处理,我们通常把这个预处理操作称作索引。
\\这样一来我们就关注到下面三个指标:
\\- 速度。找到与查询最相似的10个或更多个向量要耗时多久?期望比暴力算法耗时更少,不然索引的意义何在?\\t
- 内存消耗。该方法需要消耗多少RAM?比原始向量更多还是更少?Faiss支持只在RAM上搜索,而磁盘数据库就会慢几个数量级,即便是SSD也是一样。\\t
- 精确度。返回的结果列表与暴力搜索结果匹配程度如何?精确度可以这样评估,计算返回的真正最近邻结果在查询结果第一位(这个指标一般叫做1-recall@1)的数量,或者衡量返回结果前10个(即指标10-intersection)中包含10个最近邻结果的平均占比。\
通常我们都会在确定的内存资源下在速度和精准度之间权衡。Faiss专注于压缩原始向量的方法,因为这是扩展到数十亿向量数据集的不二之选:当必须索引十亿个向量的时候,每个向量32字节,就会消耗很大的内存。
\\许多索引类库适用于百万左右向量的小规模数据集,比如nmslib就包含了一些适于这种规模数据的非常高效的算法,这比Faiss快很多,但需要消耗更多的存储。
\\基于10亿向量的评估
\\由于工程界并没有针对这种大小数据集的公认基准,所以我们就基于研究结果来评估。
\\评估精度基于Deep1B,这是一个包含10亿图片的数据集。每张图片已通过CNN处理,CNN激活图之一用于图片描述。比较这些向量之间的欧氏距离,就能量化图片的相似程度。
\\Deep1B还带有一个较小的查询图片集,以及由暴力算法产生的真实相似性搜索结果。因此,如果运行一个搜索算法,就能评估结果中的1-recall@1。
\\选择索引
\\为了评估,我们把内存限制在30G以内。这个内存约束是我们选择索引方法和参数的依据。Faiss中的索引方法表示为一个字符串,在本例中叫做OPQ20_80,IMI2x14,PQ20。
\\该字符串包含的信息有,作用到向量上的预处理步骤(OPQ20_80),一个选择机制(IMI2x14)表明数据库如何分区,以及一个编码组件(PQ20)表示向量编码时使用一个产品量化器(PQ)来生成一个20字节的编码。所以在内存使用上,包括其他开销,累计少于30G。
\\这听起来技术性较强,所以Faiss文档提供了使用指南,来说明如何选择满足需求的最佳索引。
\\选好了索引类型,就可以开始执行索引过程了。Faiss中的算法实现会处理10亿向量并把它们置于一个索引库中。索引会存在磁盘上或立即使用,检索和增加/移除索引的操作可以穿插进行。
\\查询索引
\\当索引准备好以后,一系列搜索时间参数就会被设置来调整算法。为方便评估,这里使用单线程搜索。由于内存消耗是受限并固定的,所以需要在精确度和搜索时间之间权衡优化。举例说来,这表示为了获取40%的1-recall@1,可以设置参数以花费尽可能短的搜索时间。
\\幸运的是,Faiss带有一个自动调优机制,能扫描参数空间并收集提供最佳操作点的参数;也就是说,最可能的搜索时间对应某个精确度,反之亦然,最优的精确度对应某个搜索时间。Deep1B中操作点被可视化为如下图示:
\\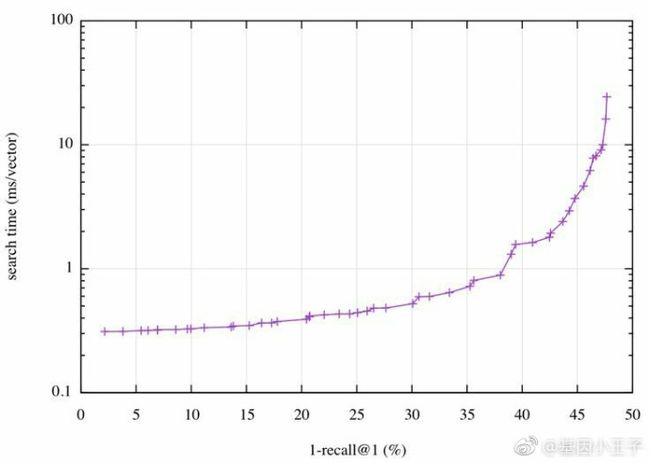
本图中我们可以看到,达到40%的1-recall@1,要求每次查询耗时必须小于2ms,或者能优化到耗时0.5ms的话,就可以达到30%的1-recall@1。一次查询耗时2ms表示单核500 QPS的处理能力。
\\这个结果基本上能媲美目前业内最新研究成果了,即Babenko和Lempitsky在CVPR 2016发表的论文“Efficient Indexing of Billion-Scale Datasets of Deep Descriptors”,这篇论文介绍了Deep1B数据集,他们达到45%的1-recall@1需要耗时20ms。
\\10亿级数据集的GPU计算
\\GPU实现方面也做了很大的投入,在原生多GPU的支持下能产出惊人的单机性能。GPU实现已经可以作为对应CPU设备的替代,无需了解CUDA API就能挖掘出GPU的性能。Faiss支持所有Nvidia 2012之后发布的GPU(Kepler,计算能力 3.5+)。
\\我们把roofline model作为指南,它指出应当尽量让内存带宽或浮点运算单元满载。Faiss 的GPU实现在单GPU上的性能要比对应的CPU实现快5到10倍,像英伟达P100这样的新型Pascal架构硬件甚至会快20倍以上。
\\一些性能关键数字:
\\- 对于近似的索引,使用YFCC100M数据集中的9500万张图片,一个基于128D CNN描述符的暴力k近邻图(k=10),只需4个Maxwell Titan X GPU就能在35分钟内构建完成,包括索引构建时间。\\t
- 十亿级向量的k近邻图现在触手可及。基于Deep1B数据集,可以构建一个暴力 k-NN图(k=10),达到0.65的10-intersection,需要使用4个Maxwell Titan X GPU花费不到12小时,或者达到0.8,使用8个Pascal P100-PCIe GPU消耗不到12小时。Titan X配置可以在不到5小时生成低质量的图。\\t
- 其他组件也表现出了骄人的性能。比如,构建上述Deep1B索引需要使用k均值聚类 6701万个120维的向量到262,144个簇,对于25 E-M迭代需要在4个Titan X GPU(12.6 tflop/s)上花139分钟,或者在8个P100 GPU(40 tflop/s)上花43.8分钟。注意聚类的训练数据集并不需要放在GPU内存中,因为数据可以在需要时流到GPU而没有额外的性能影响。\
底层实现
\\Facebook AI研究团队2015年就开始开发Faiss,这建立在许多研究成果和大量工程实践的基础之上。对于Faiss类库,我们选择聚焦在一些基础技术方面的优化,特别是在CPU方面,我们重度使用了:
\\- 采用多线程来利用多核资源,并在多个GPU上执行并行检索。\\t
- 使用BLAS类库通过矩阵和矩阵乘法来高效精准地完成距离计算。一个不采用BLAS的暴力实现很难达到最优。BLAS/LAPACK是Faiss唯一强制依赖的软件。\\t
- 采用机器SIMD向量化和popcount加速独立向量的距离计算。\
关于GPU
\\对于前述相似性搜索的GPU实现,k-selection(查找k个最小或最大元素)有一个性能问题,因为传统CPU算法(比如堆查找算法)对GPU并不友好。针对Faiss GPU,我们设计了文献中已知的最快轻量k-selection算法(k\u0026lt;=1024)。所有的中间状态全部保存在寄存器,方便高速读写。可以对输入数据一次性完成k-select,运行至高达55%的理论峰值性能,作为输出的峰值GPU内存带宽。因为其状态单独保存在寄存器文件中,所以与其他内核很容易集成,使它成为极速的精准和近似检索算法。
\\大量的精力投在了为高效策略做铺垫,以及近似搜索的内核实现。通过数据分片或数据副本可以提供对多核GPU支持,而不会受限于单GPU的可用显存大小;还提供了对半精度浮点数的支持(float16),可在支持的GPU上做完整float16运算,以及早期架构上提供的中间float16存储。我们发现以float16编码向量技术可以做到精度无损加速。
\\简而言之,对关键因素的不断突破在实践中非常重要,Faiss确实在工程细节方面下了很大的功夫。
\\开始使用Faiss
\\Faiss使用C++实现,并支持Python。只要从Github下载源码并编译,然后在Python中导入Faiss模块即可开始使用。Faiss还完整集成了Numpy,并支持构造numpy(使用float32)数组的所有函数。
\\获取Faiss: https://github.com/facebookresearch/faiss
\\索引对象
\\Faiss(包括C++和Python)提供了索引Index的实例。每个Index子类实现一个索引结构,以说明哪些向量可被加入和搜索。比如,IndexFlatL2是一个能使用L2距离搜索的暴力索引。
\\\import faiss # 导入faiss\index = faiss.IndexFlatL2(d) # 构建索引,d是向量大小\# here we assume xb contains a n-by-d numpy matrix of type float32\index.add(xb) # 把向量加入索引\print index.ntotal\\\
这样会打印出索引向量的数量。增加到一个IndexFlat仅仅表示拷贝它们到索引的内部存储,因为后面没有其他操作会作用在该向量上。
\\执行一次搜索:
\\\# xq is a n2-by-d matrix with query vectors\k = 4 # 需要4个相似向量\D, I = index.search(xq, k) # 实际搜索\print I\\\
I是一个整型矩阵,输出后是这样的:
\\\[[ 0 393 363 78]\ [ 1 555 277 364]\ [ 2 304 101 13]]\\\
对于xq的第一个向量,xb中最相似向量的索引是0(从0开始),第二相似的是 #393,第三是 #363。对于xq的第二个向量,相似向量列表是 #1, #555 等等。本例中,xq的前三个向量看起来与xb的前三个向量一样。
\\矩阵D是一个平方距离矩阵,与I的大小一致,表示对于每个结果向量查询的平方欧氏距离。
\\Faiss实现了十多个由其他索引组合的索引类型。可选的GPU版本有完全相同的接口,并有通道在CPU和CPU索引之间互通。Python接口主要由C++生成以凸显C++索引,所以可以很容易地将Python验证代码转换为集成的C++代码。
\\查看英文原文:https://code.facebook.com/posts/1373769912645926/faiss-a-library-for-efficient-similarity-search/
\\感谢蔡芳芳对本文的审校。
\\给InfoQ中文站投稿或者参与内容翻译工作,请邮件至[email protected]。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号:InfoQChina)关注我们。