Google 又逆天:语音输入离线实时输出文字,仅占 80 MB !然而……

作者 | 琥珀
出品 | AI科技大本营(公众号id:rgznai100)
Python规划学习路线图,速领取?
https://edu.csdn.net/topic/python115?utm_source=csdn_bw
谷歌语音输入法可离线识别啦!
这次出手的,又是谷歌 AI 团队。刚刚,他们为旗下的一款手机输入法 Gboard (不要跟谷歌拼音输入法搞混了啊~)上线了新功能:离线语音识别。目前这一新功能,只能在其自家的产品 Pixel 系列手机上使用。
广大已经下载或正在赶往下载路上的 Pixel 圈外人士,包括 iOS 用户可能都会失望了。
他们是这样描述这款新功能的配置的:端到端、全神经、本地部署的语音识别系统。
在其最近的论文 “Streaming End-to-End Speech Recognition for Mobile Devices” 中,他们提出了一种基于 RNN-T(RNN transducer)的训练模型。

它非常紧凑,可满足在手机上部署。这意味着不会出现太多网络延迟或紊乱,即使用户处于脱机状态,这款语音识别系统也始终可用。该模型始终以字符级工作, 因此即便你说话,它也会逐个字符地输出单词,就好像有人在实时键入并准确在虚拟键盘听写出你说的话。
例如,下面两张图片中展示的是在听写系统中输入相同句子时的情况展示:左侧为服务器端,右侧为本地端。哪边的语音识别体验更好呢?
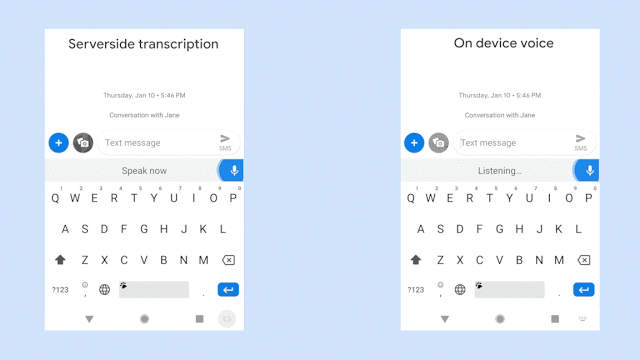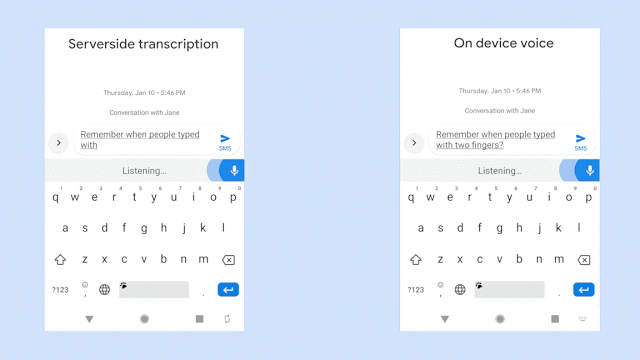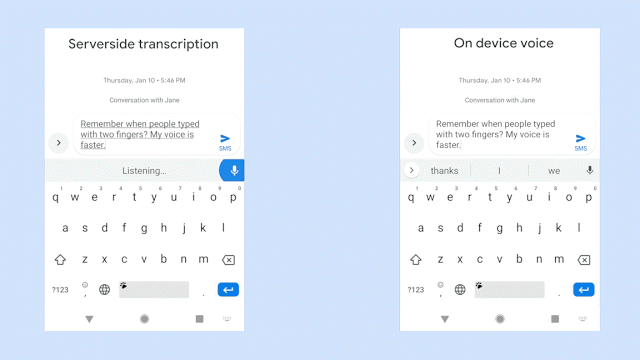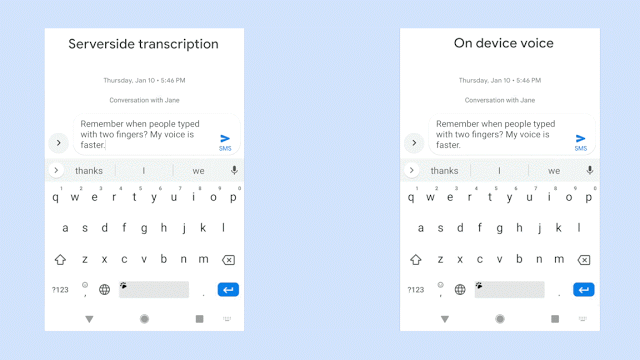
总结起来就是,“离线状态下,没有任何延迟。”这也是谷歌此次亮出的大杀器。
发生延迟是因为你的语音数据必须从手机传输到服务器上,解析完成后再返回。这可能需要几毫秒甚至几秒的时间。万一语音数据包在以太网中丢失,则需要更长的时间。
将语音转换成毫秒级的文本需要相当多的计算力。这不只简单是听到声音然后写一个单词那么简单,而是需要理解一个人讲话的含义,以及背后涉及的很多有关语言和意图的上下文语境。
在手机上是可以做到这一点的,但如此的话,又会很损耗电池电量。
![]()
语音识别模型简史
一般来讲,语音识别系统由几个部分组成:将音频片段(通常为 10 毫秒帧)映射到音素的声学模型、将音素连接起来形成单词的发声模型,以及一个表达给定模型的语言模型。在早期系统,这些组件是相对独立优化的。
2014 年左右,研究人员开始专注于训练单个神经网络,将输入音频波形直接映射到输出句子。通过在给定一系列音频特征的情况下生成一系列单词或字形来学习模型,这种 sequence-to-sequence 的方法促使了 attention-based 和 listen-attend-spell(LAS)模型的诞生。虽然这些模型在准确性方面表现出极大的前景,但它们通常会检查整个输入序列,并且在输入时不允许输出,这是实时语音转录的必要特征。
同时,一种称为 connectionist temporal classification(CTC)的技术有助于减少当时识别系统的延时问题。这对于后来创建 RNN-T 架构是一次重要的里程碑,也被看作是 CTC 技术的一次泛化。
(编者注:CTC,其全称为 Connectionist Temporal Classfication,由 Graves 等人于 2006 年提出,用于训练递归神经网络(RNN)以解决时序可变的序列问题。它可用于在线手写识别或识别语音音频中音素等任务。发展到如今,CTC 早已不是新名词,它在工业界的应用十分成熟。例如,在百度近日公布的在线语音识别输入法中,其最新语音模型在 CTC 的基础上还融合了 Attention 等新技术。)
![]()
何为RNN-T?
RNN-T 是一种不采用注意力机制的 sequence-to-sequence 模型。与大多数 sequence-to-sequence 模型(通常需要处理整个输入序列(在语音识别中即是波形)以产生输出句子)不同,RNN-T 会连续处理输入样本和流输出符号。
输出符号是字母表的字符。RNN-T 会逐个输出字符,并在适当的位置输入空格。它通过反馈循环执行此操作,该训练将模型预测的符号反馈到其中以预测下一个符号。如下图所示。
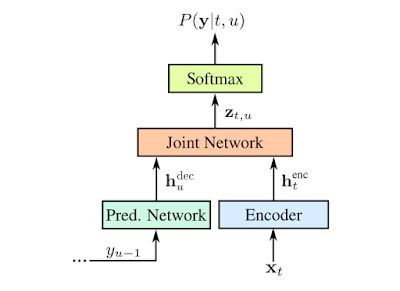
用输入音频样本 x 和预测符号 y 表示 RNN-T。预测符号(Softmax 层的输出)通过预测网络反馈到模型中。
有效训练这样的模型已经很困难,但随着新开发的训练技术进一步将单词错误率降低了 5%,它的计算强度变得更高。为了解决这个问题,研究人员开发了一个并行实现过程,因此 RNN-T 损失功能可以在 Google Cloud TPU v2 上大批量运行。训练中实现了大约 3 倍的加速。
![]()
离线识别
在传统的语音识别引擎中,声学、发声和语音模型组合成一个大的图搜索(search graph),其边缘用语音单元及其概率标记。
当语音波形呈现给识别系统时,“解码器”在给定输入信号的情况下会搜索图中相似度最高的路径,并读出该路径所采用字序列。
通常,解码器采用基础模型的有限状态传感器(Finite State Transducer, FST)表示。
然而,尽管有复杂的解码技术,图搜索仍很困难,因为生产模型几乎有 2GB 大小。这可不是在移动电话上想托管就可以实现的,因此这种方法需要在线连接才能正常使用。
为了提高语音识别的有效性,研究人员尝试直接在设备上托管新模型以避免通信网络的延迟和固有的不可靠性。
因此,端到端的方法不需要在大型解码器图上进行搜索。相反,解码器包括通过单个神经网络的集束搜索(beam search)。
RNN-T 与传统的基于服务器端的模型具有相同的精度,但前者只有 450MB,而且更加智能地使用参数和打包信息。但即便在如今的智能手机上,450MB 还是占用了很大的空间,例如通过大型网络是信号传播可能会很慢。
因此,研究人员通过使用参数量化和混合内核技术进一步减小了模型大小。这项技术早在 2016 年就已发布,并在 TensorFlow Lite 版本中提供公开的模型优化工具包。
模型量化相对于训练的浮点模型提供 4 倍压缩,在运行时实现了 4 倍加速,这使得 RNN-T 比单核上的实时语音运行得更快。压缩后,最终模型大小只占 80MB。
![]()
效果如何?
谷歌公开这一新功能后,TechCrunch 评论称,“鉴于 Google 的其他产品几乎没有是离线工作的,那么你会在离线状态下写一封电子邮件吗?当然,在网络条件不好的情况下,这款应用新功能可能会解决了用户痛点,但显然,这还是有点讽刺(鸡肋)。”
而这也一度吸引来了 HackerNews 上不少用户评论,他们也将部分矛头指向了所谓的“离线功能”:

“离线功能虽然不是最主要的吸引力,但正如本文中提到的,延迟问题的减少是巨大的。他们可能没有提及的是对隐私问题的影响。不过,用户一般不会离线处理事物,但如果需要来回的稳定数据包流,连接网络也是很麻烦的问题。”

不过,经过尝试后的用户还是非常看好:“我只是将我的 Pixel1 代切换到飞行模型,并尝试了语音输入。果然,它的离线工作速度很快!这令人非常印象深刻(我之前尝试过,但过去它只能理解一些特殊的短语。)
有多好方法可以实现这一功能呢,但我认为任何应用都能从这次语音的改进中受益。“
为此,笔者也特意下载了 Gboard、讯飞、百度三家语音输入法,试看它们在飞行模式下的效果如何。
Round 1:
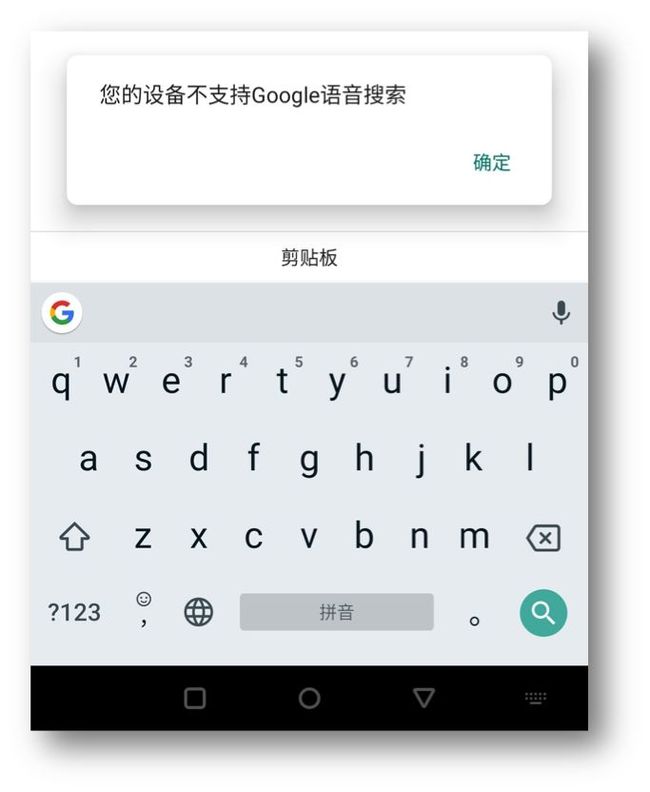
Gboard:目前非 Pixel 手机中离线语音尚无法使用,且针对某些机型甚至不支持语音。不过,打字还是比较丝滑流畅的。
Round 2:
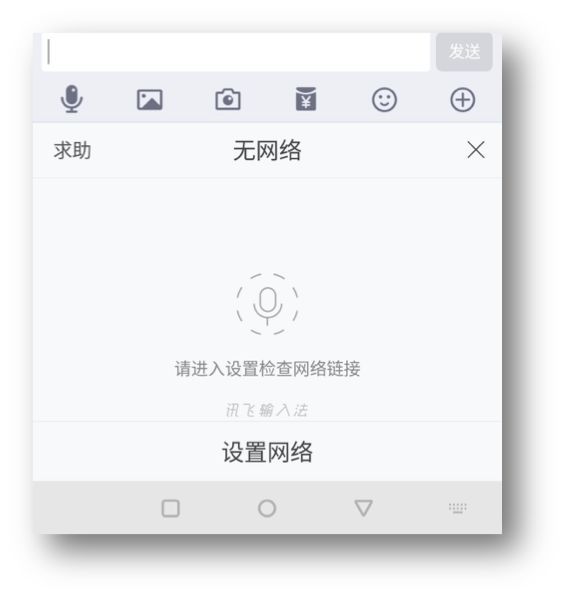
讯飞:可下载离线语音包,不过在正常网络通畅情况下,语音识别的速度和准确性还是相当高的。
Round 3:
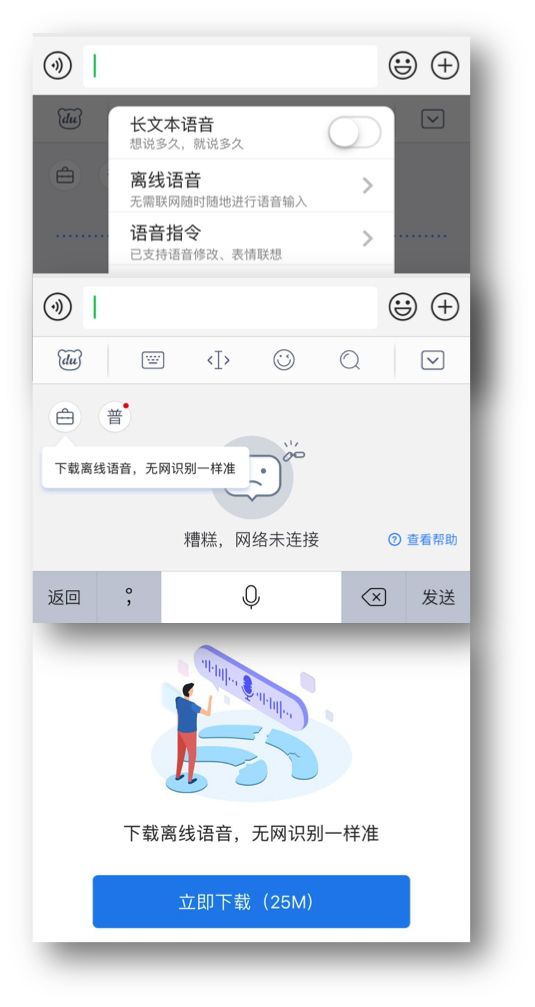
百度:也可下载离线语音,无网络连接状态下,语音识别效果还是可以的。
不知国内经常使用讯飞、百度输入法的小伙伴们,看到这一消息有何想法?欢迎留言。
参考:
https://ai.googleblog.com/2019/03/an-all-neural-on-device-speech.html
(本文为AI科技大本营原创文章,转载请微信联系 1092722531)
【End】
热 文 推 荐
熊猫直播凉了,直播大战厮杀后只剩遍地鸡毛! | 畅言
☞ 技术头条
☞ 16 岁程序媛遭辍学歧视死亡威胁,最终是如何开发出爆款应用的?
13 岁女学生因两行 JavaScript 代码被捕!
☞ 中国区块链开发者真实现状:半数只懂皮毛; 数据分析师吃香; Java/Python或成为主流开发语言
波音737连续坠毁,AI要背锅?
人人之间“不简单”,关系图谱“有一套”
☞ 没有一个人,能躲过程序员的诱惑!
System.out.println("点个好看吧!");
console.log("点个好看吧!");
print("点个好看吧!");
printf("点个好看吧!\n");
cout << "点个好看吧!" << endl;
Console.WriteLine("点个好看吧!");
Response.Write("点个好看吧!");
alert("点个好看吧!")
echo "点个好看吧!"
 点击阅读原文,输入关键词,即可搜索您想要的 CSDN 文章。
点击阅读原文,输入关键词,即可搜索您想要的 CSDN 文章。
![]() 喜欢就点击“好看”吧!
喜欢就点击“好看”吧!