使用Spark的JavaAPI访问局域网中的Spark集群
1、客户端环境
Win7 + JDK1.8 + IDEA
Meaven配置:
4.0.0
cn.edu.shu.ces.chenjie
sparkjavaapistudy
1.0-SNAPSHOT
org.apache.spark
spark-core_2.11
2.0.2
org.apache.hadoop
hadoop-client
2.7.3
2、测试代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.ArrayList;
import java.util.List;
public class SparkConnect {
public static List getStringsByTXT(String txtFilePath, Configuration conf, String userID)
{
List lines = new ArrayList();
FSDataInputStream fsr = null;
BufferedReader bufferedReader = null;
String lineTxt = null;
try
{
FileSystem fs = FileSystem.get(URI.create(txtFilePath), conf);
fsr = fs.open(new Path(txtFilePath));
bufferedReader = new BufferedReader(new InputStreamReader(fsr));
while ((lineTxt = bufferedReader.readLine()) != null)
{
if(lineTxt.contains(userID))
lines.add(lineTxt);
System.out.println(lineTxt);
}
return lines;
}
catch (Exception e)
{
return lines;
}
finally
{
if (bufferedReader != null)
{
try
{
bufferedReader.close();
}
catch (IOException e)
{
e.printStackTrace();
}
}
}
}
public static void main(String[] args) {
//1、测试HDFS文件访问
Configuration conf1 = new Configuration();
String txtFilePath = "hdfs://192.168.1.112:9000/users/part-r-00000";
List lines = getStringsByTXT(txtFilePath, conf1, "");
//2、测试Spark访问
String [] jars = {"D:\\OneDrive - shu.edu.cn\\SourceCode\\IdeaProject\\sparkjavaapistudy\\out\\artifacts\\sparkjavaapistudy_jar\\sparkjavaapistudy.jar"};
SparkConf conf = new SparkConf().setAppName("Spark Java API 学习")
.setMaster("spark://192.168.1.112:7077")
.set("spark.executor.memory", "512m")
.setJars(jars)
.set("spark.cores.max", "1");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD users = sc.textFile("hdfs://192.168.1.112:9000/users");
System.out.println(users.first());
}
} 其中的jars路径为将此工程打包成的jar包路径
打包方式:
file-->project structure-->左侧选项卡Artifacts-->绿色加号-->Jar-->From modules...-->
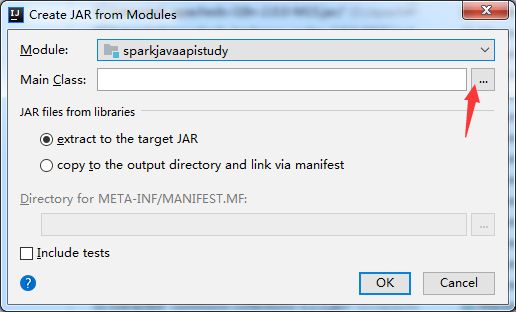

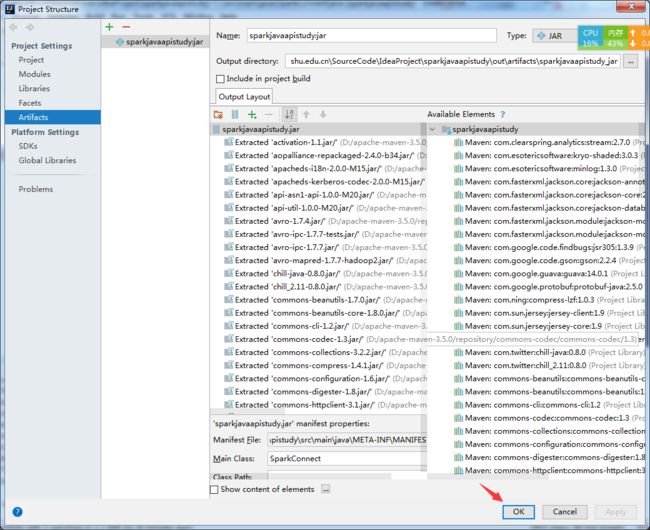
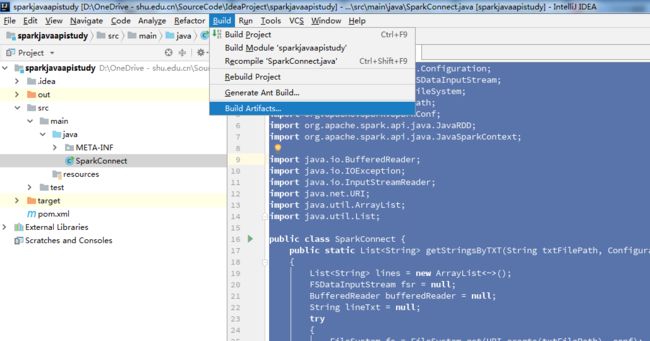
生成jar包后,将jar包地址加入Jars中
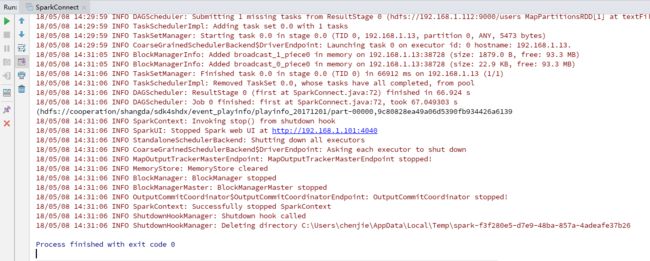
运行示例:
三、Bug
18/05/08 11:56:52 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 111.186.116.5:58985 (size: 1879.0 B, free: 1048.8 MB)
18/05/08 11:56:52 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1012
18/05/08 11:56:52 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 0 (hdfs://192.168.1.112:9000/users MapPartitionsRDD[1] at textFile at SparkConnect.java:77)
18/05/08 11:56:52 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks
18/05/08 11:57:07 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
18/05/08 11:57:22 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
18/05/08 11:57:37 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
18/05/08 11:57:52 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
18/05/08 11:57:53 INFO StandaloneAppClient$ClientEndpoint: Executor updated: app-20180508115650-0010/0 is now EXITED (Command exited with code 1)
18/05/08 11:57:53 INFO StandaloneSchedulerBackend: Executor app-20180508115650-0010/0 removed: Command exited with code 1
18/05/08 11:57:53 INFO StandaloneAppClient$ClientEndpoint: Executor added: app-20180508115650-0010/1 on worker-20180505220404-192.168.1.13-43916 (192.168.1.13:43916) with 1 cores
18/05/08 11:57:53 INFO StandaloneSchedulerBackend: Granted executor ID app-20180508115650-0010/1 on hostPort 192.168.1.13:43916 with 1 cores, 512.0 MB RAM
18/05/08 11:57:53 INFO BlockManagerMaster: Removal of executor 0 requested
18/05/08 11:57:53 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Asked to remove non-existent executor 0
18/05/08 11:57:53 INFO BlockManagerMasterEndpoint: Trying to remove executor 0 from BlockManagerMaster.
18/05/08 11:57:53 INFO StandaloneAppClient$ClientEndpoint: Executor updated: app-20180508115650-0010/1 is now RUNNING
18/05/08 11:58:07 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
18/05/08 11:58:22 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
18/05/08 11:58:37 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
18/05/08 11:58:52 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
18/05/08 11:58:57 INFO StandaloneAppClient$ClientEndpoint: Executor updated: app-20180508115650-0010/1 is now EXITED (Command exited with code 1)
18/05/08 11:58:57 INFO StandaloneSchedulerBackend: Executor app-20180508115650-0010/1 removed: Command exited with code 1
18/05/08 11:58:57 INFO StandaloneAppClient$ClientEndpoint: Executor added: app-20180508115650-0010/2 on worker-20180505220404-192.168.1.13-43916 (192.168.1.13:43916) with 1 cores
18/05/08 11:58:57 INFO StandaloneSchedulerBackend: Granted executor ID app-20180508115650-0010/2 on hostPort 192.168.1.13:43916 with 1 cores, 512.0 MB RAM
18/05/08 11:58:57 INFO StandaloneAppClient$ClientEndpoint: Executor updated: app-20180508115650-0010/2 is now RUNNING
18/05/08 11:58:57 INFO BlockManagerMaster: Removal of executor 1 requested
18/05/08 11:58:57 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Asked to remove non-existent executor 1
18/05/08 11:58:57 INFO BlockManagerMasterEndpoint: Trying to remove executor 1 from BlockManagerMaster.
18/05/08 11:59:07 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
18/05/08 11:59:22 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
18/05/08 11:59:37 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
18/05/08 11:59:52 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
18/05/08 12:00:01 INFO StandaloneAppClient$ClientEndpoint: Executor updated: app-20180508115650-0010/2 is now EXITED (Command exited with code 1)
18/05/08 12:00:01 INFO StandaloneSchedulerBackend: Executor app-20180508115650-0010/2 removed: Command exited with code 1
18/05/08 12:00:01 INFO BlockManagerMaster: Removal of executor 2 requested
18/05/08 12:00:01 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Asked to remove non-existent executor 2
18/05/08 12:00:01 INFO BlockManagerMasterEndpoint: Trying to remove executor 2 from BlockManagerMaster.
18/05/08 12:00:01 INFO StandaloneAppClient$ClientEndpoint: Executor added: app-20180508115650-0010/3 on worker-20180505220404-192.168.1.13-43916 (192.168.1.13:43916) with 1 cores
18/05/08 12:00:01 INFO StandaloneSchedulerBackend: Granted executor ID app-20180508115650-0010/3 on hostPort 192.168.1.13:43916 with 1 cores, 512.0 MB RAM
18/05/08 12:00:01 INFO StandaloneAppClient$ClientEndpoint: Executor updated: app-20180508115650-0010/3 is now RUNNING
18/05/08 12:00:07 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
18/05/08 12:00:22 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources错误:
Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
解决过程:
在Spark管理节目,在Completed Applications中切换到到没有运行成功的应用中
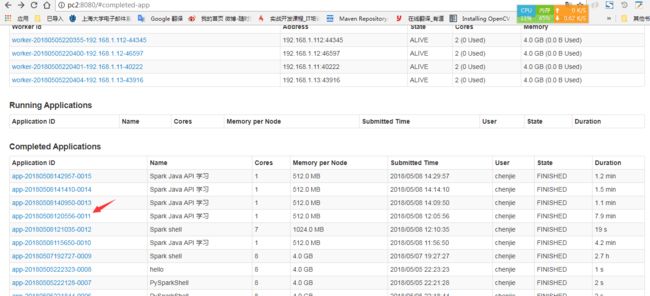
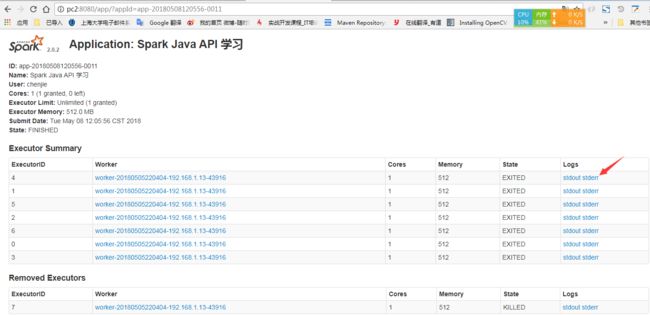
观察错误信息:

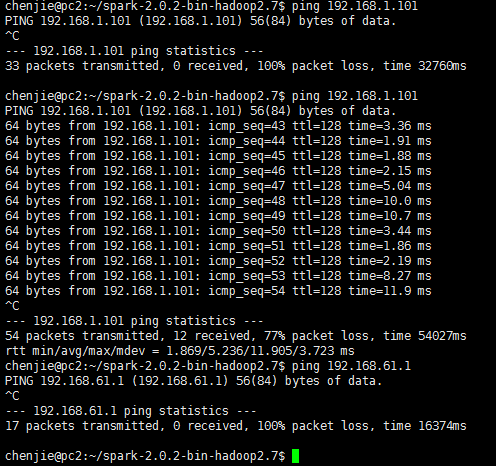
Caused by: java.io.IOException: Failed to connect to /192.168.61.1:59249
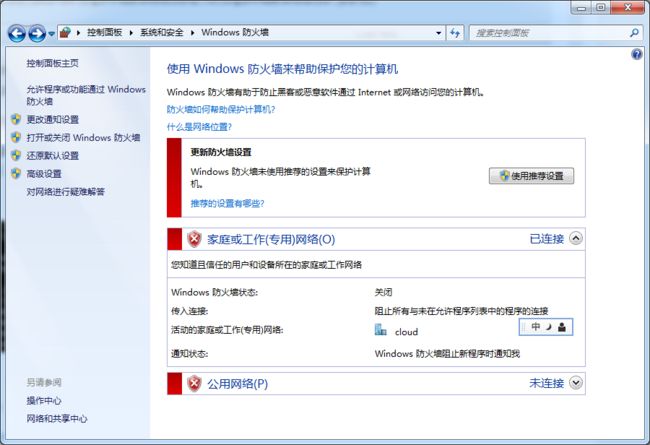
在命令行中查看本机网络设置ipconfig /all
发现192.168.61.1是Vmware虚拟机软件分配的IP,将Vmware卸载后,spark不再连接此ip
而是连接本机在局域网中的IP,但是仍然连接不是,在局域网中的另一台机器上ping本机,发现ping不通,想到可能是防火墙的作用,关闭防火墙后,ping通并且运行成功