操作符将一个或多个数据流转换为新的数据流。程序可以将多个转换组合成复杂的数据流拓扑。
本节描述了基本转换、应用这些转换后的有效物理分区以及对Flink的操作符chaining的理解。
DataStream数据转换(DataStream Transformations)
| Transformation | Description |
|---|---|
| Map DataStream → DataStream |
取一个元素并生成一个元素。一个map 函数,使输入流的值加倍: dataStream.map { x => x * 2 } |
| FlatMap DataStream → DataStream |
取一个元素并生成0个、1个或多个元素。一个flatmap函数,将句子分割成单词: dataStream.flatMap { str => str.split(" ") } |
| Filter DataStream → DataStream |
为每个元素计算boolean函数,并保留该函数返回true的元素。过滤掉零值的过滤器: dataStream.filter { _ != 0 } |
| KeyBy DataStream → KeyedStream |
逻辑上根据key对流分区,每个分区包含相同键的元素。 这是通过哈希分区实现的。有关如何指定键,请参见Key。这个转换返回一个KeyedStream。dataStream.keyBy("someKey") // Key by field "someKey"dataStream.keyBy(0) // Key by the first element of a Tuple |
| Reduce KeyedStream → DataStream |
keyed数据流上的"rolling" reduce。将当前元素与最后一个缩减值组合,并发出新值。 创建一个局部求和的reduce函数 keyedStream.reduce { _ + _ } |
| Fold KeyedStream → DataStream |
在一个keyed数据流上通过“滚动”折叠初始值,将当前元素与最后一个折叠值组合并发出新值。 当应用于序列(1,2,3,4,5)时,发出序列“start-1”、“start-1-2”、“start-1-2-3”、… val result: DataStream[String] = keyedStream.fold("start")((str, i) => { str + "-" + i }) |
| Aggregations KeyedStream → DataStream |
在keyed数据流上滚动聚合。min和minBy的区别是min返回最小值,而minBy返回该字段中值最小的元素(max和maxBy也是如此)。keyedStream.sum(0)keyedStream.sum("key")keyedStream.min(0)keyedStream.min("key")keyedStream.max(0)keyedStream.max("key")keyedStream.minBy(0)keyedStream.minBy("key")keyedStream.maxBy(0)keyedStream.maxBy("key") |
| Window KeyedStream → WindowedStream |
Windows可以在已经分区的KeyedStreams上定义。Windows根据一些特征对每个键中的数据进行分组(例如,最近5秒内到达的数据)。有关windows的描述,请参见windows。dataStream.keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(5))) // Last 5 seconds of data |
| WindowAll DataStream → AllWindowedStream |
窗口可以在常规的数据流上定义。Windows根据一些特征对所有流事件进行分组(例如,最近5秒内到达的数据)。有关windows的完整描述,请参见windows。 注意:在许多情况下,这是非并行转换。windowAll操作符的所有记录将在一个任务中为完成。 dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5))) // Last 5 seconds of data |
| Window Apply WindowedStream → DataStream AllWindowedStream → DataStream |
将通用函数作为一个整体应用于窗口。下面是一个手动求和窗口元素的函数。 注意:如果使用的是windowAll转换,则需要使用AllWindowFunction。 windowedStream.apply { WindowFunction }// applying an AllWindowFunction on non-keyed window streamallWindowedStream.apply { AllWindowFunction } |
| Window Reduce WindowedStream → DataStream |
对window 应用函数做reduce操作并返回reduce值。 windowedStream.reduce { _ + _ } |
| Window Fold WindowedStream → DataStream |
对窗口应用函数做flod操作并返回折叠值。将示例函数应用于sequence (1,2,3,4,5)时,将序列折叠成字符串“start-1-2-3-4-5”:val result: DataStream[String] = windowedStream.fold("start", (str, i) => { str + "-" + i }) |
| Aggregations on windows WindowedStream → DataStream |
聚合窗口的内容。min和minBy的区别在于,min返回最小值,而minBy返回该字段中最小值的元素(max和maxBy也是如此)。windowedStream.sum(0)windowedStream.sum("key")windowedStream.min(0)windowedStream.min("key")windowedStream.max(0)windowedStream.max("key")windowedStream.minBy(0)windowedStream.minBy("key")windowedStream.maxBy(0)windowedStream.maxBy("key") |
| Union DataStream → DataStream |
两个或多个数据流的Union,创建包含来自所有流的所有元素的新流。注意:如果您将一个数据流与它自己Union,您将在结果流中获得每个元素两次。dataStream.union(otherStream1, otherStream2, ...) |
| Window Join DataStream,DataStream → DataStream |
Join指定key和公共窗口上的两个数据流。dataStream.join(otherStream) .where( .equalTo( .window(TumblingEventTimeWindows.of(Time.seconds(3))) .apply { ... } |
| Window CoGroup DataStream,DataStream → DataStream |
将指定key和公共窗口上的两个数据流分组。dataStream.coGroup(otherStream) .where(0).equalTo(1) .window(TumblingEventTimeWindows.of(Time.seconds(3))) .apply {} |
| Connect DataStream,DataStream → ConnectedStreams |
“Connects”两个保留类型的数据流,允许在两个流之间共享状态。someStream : DataStream[Int] = ...otherStream : DataStream[String] = ...val connectedStreams = someStream.connect(otherStream) |
| CoMap, CoFlatMap ConnectedStreams → DataStream |
类似于连接数据流上的map和flatMap connectedStreams.map( (_ : Int) => true, (_ : String) => false ) connectedStreams.flatMap( (_ : Int) => true, (_ : String) => false ) |
| Split DataStream → SplitStream |
根据某种标准将流分成两个或多个流。 val split = someDataStream.split( (num: Int) => (num % 2) match { case 0 => List("even") case 1 => List("odd") }) |
| Select SplitStream → DataStream |
从分割流中选择一个或多个流。val even = split select "even"val odd = split select "odd"val all = split.select("even","odd") |
| Iterate DataStream → IterativeStream → DataStream |
通过将一个操作符的输出重定向到之前的某个操作符,在流中创建一个“反馈”循环。这对于定义持续更新模型的算法特别有用。下面的代码从一个流开始,并持续地应用迭代。大于0的元素被发送回反馈通道,其余的元素被转发到下游。有关完整描述,请参见迭代。 initialStream.iterate { iteration => { val iterationBody = iteration.map {/do something/} (iterationBody.filter(_ > 0), iterationBody.filter(_ <= 0)) } } |
| Extract Timestamps DataStream → DataStream |
从记录中提取时间戳,以便与使用事件时间语义的窗口一起工作。stream.assignTimestamps { timestampExtractor } |
通过匿名模式匹配从元组、case类和集合中提取,如下所示:
val data: DataStream[(Int, String, Double)] = // [...]
data.map {
case (id, name, temperature) => // [...]
}
API不支持开箱即用。要使用这个特性,您应该使用Scala API扩展
元组的数据流可以进行以下转换:
JAVA
| Transformation | Description |
|---|---|
| Project DataStream → DataStream |
从元组中选择字段的子集 DataStream DataStream |
物理分区(Physical partitioning)
Flink还通过以下函数对转换后的流分区进行低级控制(如果需要的话)。
| Transformation | Description |
|---|---|
| Custom partitioning DataStream → DataStream |
使用用户定义的分区器为每个元素选择目标任务。dataStream.partitionCustom(partitioner, "someKey")dataStream.partitionCustom(partitioner, 0) |
| Random partitioning |
根据均匀分布随机划分元素。dataStream.shuffle() |
| Rebalancing (Round-robin partitioning) DataStream → DataStream |
分区元素循环,每个分区创建相同的负载。对于数据倾斜情况下的性能优化非常有用。dataStream.rebalance() |
| Rescaling DataStream → DataStream |
循环地将元素划分到下游操作的子集中。如果您希望在管道中。例如,从源的每个并行实例中向多个映射器的子集展开分配负载,但不希望使用rebalance()带来的完全再平衡,那么这种方法非常有用。这只需要本地数据传输,而不需要通过网络传输数据,这取决于其他配置值,比如TaskManagers的槽数。 上游操作向下游操作发送元素的子集依赖于上游和下游操作的并行度。例如,如果上游操作并行度为2,下游操作并行度为4,然后一个上游操作将元素分配给两个下游操作,而另一个上游操作将分配给另外两个下游操作。另一方面,如果下游操作具有并行性2,而上游操作具有并行性4,那么两个上游操作将分布到一个下游操作,而另外两个上游操作将分布到另一个下游操作。 如果不同的并行度不是彼此的倍数,那么一个或多个下游操作将具有来自上游操作的不同数量的输入。 在上面的例子中,连接模式的可视化如图所示: 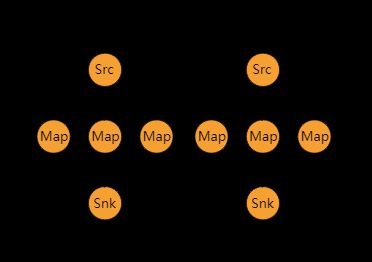
dataStream.rescale() |
| Broadcasting DataStream → DataStream |
向每个分区广播元素。dataStream.broadcast() |
任务链和资源组(Task chaining and resource groups)
链接两个后续转换意味着将它们放在同一个线程中以获得更好的性能。如果可能的话,Flink默认情况下是链操作符(例如,两个后续的map转换)。如果需要,该API提供了对链接的细粒度控制:
如果想在整个作业中禁用链接,请使用StreamExecutionEnvironment.disableOperatorChaining()。对于更细粒度的控制,可以使用以下函数。请注意,这些函数只能在DataStream转换之后使用,因为它们引用前一个转换。例如,您可以使用someStream.map(…). startnewchain(),但不能使用someStream.startNewChain()。
资源组是Flink中的插槽,参见插槽。如果需要,可以手动将操作符隔离在不同的插槽中。
| Transformation | Description |
|---|---|
| 开始新链 |
从这个运算符开始,开始一个新的链。两个map()将被链接,filter()将不会链接到第一个映射器。 someStream.filter(...).map(...).startNewChain().map(...) |
| 禁用链 |
禁用链map操作符 someStream.map(...).disableChaining() |
| 集槽共享组 |
设置操作的槽共享组。Flink会将具有相同槽共享组的操作放到同一个槽中,同时将没有槽共享组的操作保留在其他槽中。这可以用来隔离槽。如果所有输入操作都在同一个槽共享组中,则从输入操作继承槽共享组。默认槽共享组的名称为“default”,可以通过调用slotSharingGroup(“default”)显式地将操作放入这个组中。someStream.filter(...).slotSharingGroup("name") |