从零开始学Seata(Fescar)-部署运行官方DEMO
(本篇文章主要参考了官方网站的Quick-Start,在此基础上结合自身的搭建过程,进行了重新编辑和梳理。)
让我们从一个简单的电商微服务示例开始Seata的学习。
业务场景分析
业务场景是用户购买商品。 整个业务逻辑由3个微服务提供支持:
- ·存储服务:扣除特定商品的存储数量。
- ·订单服务:根据采购申请创建订单。
- ·账户服务:扣除用户账户的余额。
对应逻辑架构图:
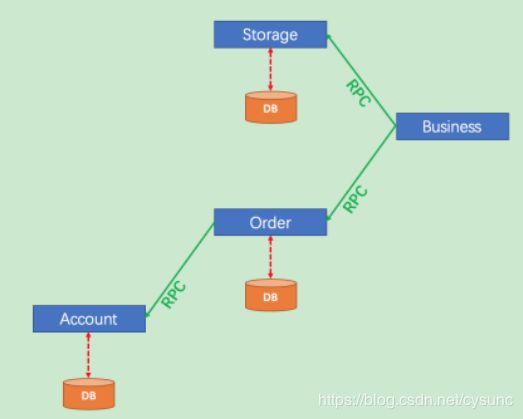
基于Dubbo + Seata构建一个简单示例
第1步:创建数据库
·要求:带有InnoDB引擎的MySQL。
注意:实际上,示例用例中的3个服务应该有3个数据库。 但是,我们只需创建一个数据库并配置3个数据源。
第2步:创建UNDO_LOG表
Seata AT模式需要UNDO_LOG表。
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_unionkey` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
第3步:创建业务表
DROP TABLE IF EXISTS `storage_tbl`;
CREATE TABLE `storage_tbl` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`commodity_code` varchar(255) DEFAULT NULL,
`count` int(11) DEFAULT 0,
PRIMARY KEY (`id`),
UNIQUE KEY (`commodity_code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
DROP TABLE IF EXISTS `order_tbl`;
CREATE TABLE `order_tbl` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` varchar(255) DEFAULT NULL,
`commodity_code` varchar(255) DEFAULT NULL,
`count` int(11) DEFAULT 0,
`money` int(11) DEFAULT 0,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
DROP TABLE IF EXISTS `account_tbl`;
CREATE TABLE `account_tbl` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` varchar(255) DEFAULT NULL,
`money` int(11) DEFAULT 0,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
第4步:启动Seata服务(二选一)
从https://github.com/seata/seata/releases下载服务器包,解压缩。
可自行选择Windows环境或者Linux环境。
如果只是跑demo,看看效果,尤其是集成在eclpse里面运行的时候,Windows环境更方便一些。
Windows环境
直接双击fescar-server.bat执行。
运行窗口
【验证】
通过jcmd,可以找到Seata进程。
![]()
linux环境
通过命令sh fescar-server.sh $LISTEN_PORT PATH_FOR_PERSISTENT_DATA启动服务。
例如:
sh fescar-server.sh 8091 /home/admin/fescar/data/
第5步:构建示例工程
通过https://github.com/fescar-group/fescar-samples获取示例工程。
然后导入eclilpse工程。
导完后,我们会看到三个子工程:fescar-samples-dubbo、fescar-samples-nacos和fescar-samples-springboot。本文只需要关注fescar-samples-dubbo工程就可以了。

接下来,我们需要修改一下数据源和分布式协调器的配置,才能正常运行。
第6步:修改数据源配置
修改配置文件:jdbc.properties
根据刚刚创建的数据库URL /用户名/密码进行修改。
jdbc.account.url=jdbc:mysql://localhost:3306/fescar_demo
jdbc.account.username=root
jdbc.account.password=root
jdbc.account.driver=com.mysql.jdbc.Driver
# storage db config
jdbc.storage.url=jdbc:mysql://localhost:3306/fescar_demo
jdbc.storage.username=root
jdbc.storage.password=root
jdbc.storage.driver=com.mysql.jdbc.Driver
# order db config
jdbc.order.url=jdbc:mysql://localhost:3306/fescar_demo
jdbc.order.username=root
jdbc.order.password=root
jdbc.order.driver=com.mysql.jdbc.Driver
第7步:启动zookeeper服务(二选一)
从https://www.apache.org/dyn/closer.cgi/zookeeper/找一个镜像下载,解压缩后即可使用。
可自行选择Windows环境或者Linux环境。
由于本文的工程运行在eclpse中,所以使用Windows环境更方便一些。
Windows环境
直接双击zkServer.cmd执行。
运行窗口

【验证】
通过jcmd,可以找到zookeeper进程。

linux环境
通过命令 sh bin/zkServer.sh start启动服务。
第8步:修改分布式协调器配置
1)、修改/src/main/resources/spring/dubbo-storage-service.xml
注释掉上面组播的连接模式,启用下方的zookeeper,并修改正确的ip和端口。
<dubbo:registry address="zookeeper://localhost:2181" />
2)、修改/src/main/resources/spring/dubbo-account-service.xml
注释掉上面组播的连接模式,启用下方的zookeeper,并修改正确的ip和端口。
<dubbo:registry address="zookeeper://localhost:2181" />
3)、修改/src/main/resources/spring/dubbo-order-service.xml
注释掉上面组播的连接模式,启用下方的zookeeper,并修改正确的ip和端口。
<dubbo:registry address="zookeeper://localhost:2181" />
第9步:运行三个账户、库存和订单服务
运行服务顺序如下:
1)、运行库存服务
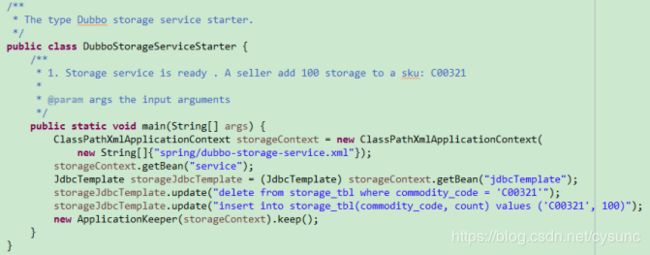

2)、运行账户服务

![]()
3)、运行订单服务

![]()
第10步:运行业务调用服务
1)、运行业务调用服务之前,检查一下数据库表中的记录情况。
ACCOUNT_TBL表: 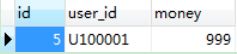
STORAGE_TBL表:
2)、运行业务调用服务

![]()
3)、运行之后检查两张表是否有变化
ACCOUNT_TBL表:
STORAGE_TBL表:
结果,发现没有任何变化。说明分布式事务已经在起作用了。
后续,我将再写一篇文章,根据源代码和输出日志,对运行过程做一个梳理。
文章结束。