MySQL Group Replication 节点状态详解
replication_group_members表
通过查询performance_schema下的replication_group_members表可以知道MGR集群中节点的状态:
mysql> desc performance_schema.replication_group_members;
+--------------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+----------+------+-----+---------+-------+
| CHANNEL_NAME | char(64) | NO | | NULL | |
| MEMBER_ID | char(36) | NO | | NULL | |
| MEMBER_HOST | char(60) | NO | | NULL | |
| MEMBER_PORT | int(11) | YES | | NULL | |
| MEMBER_STATE | char(64) | NO | | NULL | |
+--------------+----------+------+-----+---------+-------+
5 rows in set (0.01 sec)- CHANNEL_NAME : 显示的值永远为group_replication_applier
- MEMBER_ID : 节点serer_uuid
- MEMBER_PORT : 节点服务端口,取值为server_port指定的端口
- MEMBER_HOST : 如果没有配置report_host选项,那么取值为机器的hostname,可以通过report_host配置指定具体的IP
- MEMBER_STATE : 节点状态,取值下一节讨论
MEMBER_STATE取值
MEMBER_STATE字段显示当前节点的状态,根据官方文档,取值和介绍如下所示:
| 取值 | 解释 | 状态是否在集群内同步 |
|---|---|---|
| ONLINE | 表示该节点可正常提供服务 | YES |
| RECOVERING | 表示当前节点正在从其他节点恢复数据 | YES |
| OFFLINE | 表示GR插件已经加载,但是该节点不属于任何一个GR组 | NO |
| ERROR | 表示节点在recovery阶段出现错误或者从其他节点同步状态中出现错误 | NO |
| UNREACHABLE | 节点处于不可达状态,无法与之发生网络通讯 | NO |
从上表可以知道,只有ONLINE和RECOVERING两种状态会在集群中得到同步。这个状态同步是指状态在所有节点上面查询均能保持一致的意思。至于OFFLINE,ERROR和UNREABLE,做以下说明:
- 只有在当前OFFLINE节点查询replication_group_members表才能得到OFFLINE状态,在其他节点上查询replication_group_members表,则一般没有该节点的状态(很好理解,因为OFFLINE节点已经不属于这个GR组了)
- 只有在当前ERROR节点查询replication_group_members表才能得到ERROR状态,同上面的OFFLINE,在其他节点上查询也看不到该节点
- 假设节点A与B网络通讯失败,那么在节点A上查询replication_group_members表,有可能得到B的状态为UNREACHABLE
那么,从状态是否自身可见或者其他节点可见的角度来区分,有如下区分,
状态对自身可见的有:
- ONLINE
- OFFLINE
- RECOVERING
- ERROR
状态在其他节点上可见的有:
- ONLINE
- RECOVERING
- UNREACHABLE
节点状态转移
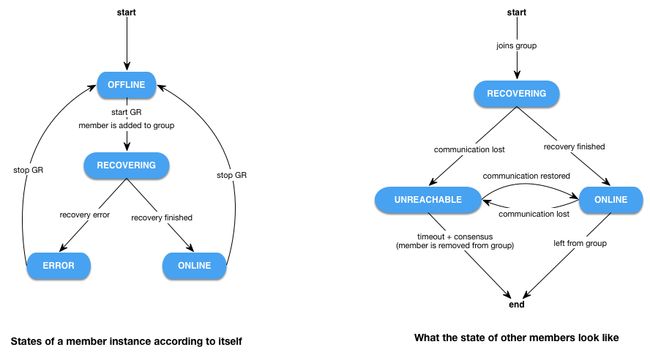
当一个节点加进一个GR组,其状态首先变成RECOVERING,表示当前节点正处于集群恢复阶段,这个阶段下,节点会选择集群中一个节点(donor节点),利用传统的异步复制,做recovery。当数据能够成功追平,节点的状态将会变成ONLINE,这个过程中通过其他节点也可以看到该节点的状态,不管是RECOVERING还是最后的ONLINE。
假如该节点在RECOVERING阶段出现了异常(选donor进行复制失败 or 在donor追数据的过程中失败),那么该节点的状态将会变成ERROR,注意,这时候在其他节点上查询时,发现该RECOVERING节点已经从组里面被踢出。
另外,如果一个ONLINE节点失去与其他节点的通讯(可能因为节点crash或者网络异常),则该节点在其他节点上面查询到的状态将会是UNREACHABLE。如果这个UNREACHABLE节点在规定的超时时间内没有恢复过来,那么节点将会被踢出去。这个规定的超时时间是多少呢?下面会讲这个时间在集群失去这个节点是否可用的条件下是不一样的。
可疑的UNREACHABLE状态
前面提到,UNREACHABLE节点在规定的超时时间内如果没有恢复过来,那么节点将会被踢出去。这个规定的超时时间,取决于你集群失去这个节点下还是不是达到可用状态(之前的文章里面强调的2N + 1)。假设失去这个节点,集群仍然可用,那么这个UNREACHABLE的超时时间很短,几乎看不到这个状态;但是,如果失去这个节点后集群马上不可用,那么这个UNREACHABLE节点的超时时间,近似于无线大,将会一直处于UNREACHABLE!
以一个例子来验证:
3节点组成的集群,最开始3个节点均为ONLINE状态:
mysql> select * from performance_schema.replication_group_members;
+---------------------------+--------------------------------------+---------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+---------------+-------------+--------------+
| group_replication_applier | 748703ac-dbcc-11e6-a668-90e2bac5d924 | 10.202.44.215 | 24801 | ONLINE |
| group_replication_applier | 8f8bc352-2566-11e7-aa5e-d4ae52ab91b3 | 10.202.44.214 | 24801 | ONLINE |
| group_replication_applier | 9c09340a-e04c-11e6-9916-0024e869a606 | 10.202.44.213 | 24801 | ONLINE |
+---------------------------+--------------------------------------+---------------+-------------+--------------+
3 rows in set (0.00 sec)这时候,kill(注意是kill实例而不是正常down实例)掉其中的一个实例(10.202.44.214),通过其他可用节点查询到,那一个kill掉的实例从集群中被踢走了:
mysql> select * from performance_schema.replication_group_members;
+---------------------------+--------------------------------------+---------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+---------------+-------------+--------------+
| group_replication_applier | 748703ac-dbcc-11e6-a668-90e2bac5d924 | 10.202.44.215 | 24801 | ONLINE |
| group_replication_applier | 9c09340a-e04c-11e6-9916-0024e869a606 | 10.202.44.213 | 24801 | ONLINE |
+---------------------------+--------------------------------------+---------------+-------------+--------------+
2 rows in set (0.00 sec)接下来我们再kill掉一个实例(10.202.44.213)
mysql> select * from performance_schema.replication_group_members;
+---------------------------+--------------------------------------+---------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+---------------+-------------+--------------+
| group_replication_applier | 748703ac-dbcc-11e6-a668-90e2bac5d924 | 10.202.44.215 | 24801 | ONLINE |
| group_replication_applier | 9c09340a-e04c-11e6-9916-0024e869a606 | 10.202.44.213 | 24801 | UNREACHABLE |
+---------------------------+--------------------------------------+---------------+-------------+--------------+
2 rows in set (0.00 sec)这个时候,UNREACHABLE状态将一直持续,而且此时,集群不满足2N + 1,集群已经不可用(即使有主节点,主节点也是不可写的)。恢复主节点可写有两种方式:
- 把前面kill掉的一个节点拉起来,加入GR组里面
- 暴力地使用group_replication_force_members参数,强制设置节点组成一个新的GR组(强制剔除UNRECHABLE节点)