Python 加载YOLOV2模型,实现目标检测
最近在学习YOLO目标检测的知识点,学习github上面的darkflow项目,项目功能多样复杂。如果想利用训练好的模型实现一些小的应用的话,直接用起来就很不方便,所以最近研究了一下项目里关于yolov2部分预测的代码,并按照自己的要求重新写了一个新的小项目,可以实现加载利用darkflow训练完成的模型,进行目标检测的功能。以备后期做目标检测,可以直接用。项目的git地址:https://github.com/xiaoqiang0008/YOLOV2-predict-use-tensorflow/tree/master
这个只能做预测,不能训练。训练的部分研究研究,弄明白了再自己重新搞一个,代码不自己重新再写写,总觉得用起来不爽!另外这个仅用于学习,考虑实现基本功能。
环境要求:
系统:windows7_X64
Tensorflow 1.4
Opencv3
先看一下目录结构:
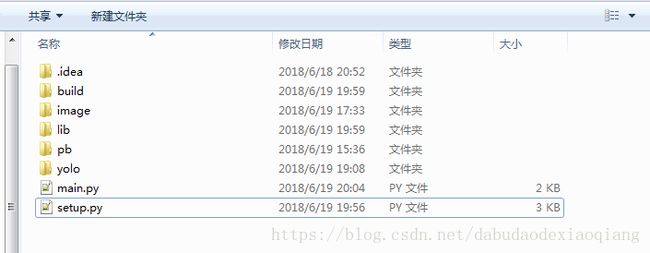
从上往下:
build文件夹存放Cython代码编译的中间文件;
image文件夹存放测试的图片文件;
lib文件夹存放Cython代码相关的模块,该部分主要摘自darkflow项目;
pb文件夹存放训练好的模型文件,包括后缀名为 ’.pb’以及 ’.meta’ 两个文件,前者记录网络结构、权重等变量,后者记录网络的一下参数信息,例如具体类别等;
yolo文件夹存放加载模型文件并实现目标检测的相关模块。
至于pb模型怎么来的,查看darkflow项目的说明,里面有把darknet模型转换为tensorflow的pb模型的指令,搞一搞就可以了。这里也有两个我转换好的模型tiny_yolo,pb、YOLOV2的pb模型文件,可以下载直接使用。
使用方法说明:
开始之前需要先编译Cython代码。打开命令行窗口,进入到根目录下,执行
python setup.py build_ext --inplace如果执行上面命令报错的话,可能是因为你的电脑没有安装Cython以及与Python版本相对应的VS的C编译器,这个搞起来也真是麻烦,不过网上有很多解决办法的。
执行 -h 或 --help 查看使用方法
python main.py -h 或 python main.py --help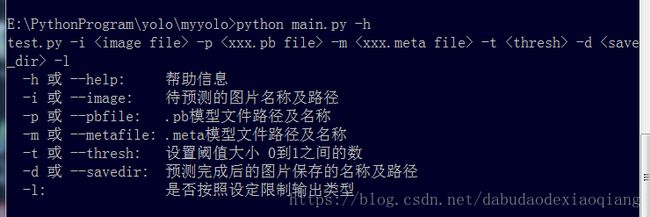
只有-i 或 --image 必须要指定之外,其他都是由默认值的,不更改的话,直接采用默认即可
接下来可以试着用命令行检测一张照片,看看效果!
python main.py -i image/car.jpg预测完成,会默认在image文件夹下生成一个名为predict.jpg的图片文件。
当然,pb文件夹中的yolo模型可以预测输出80目标,然而有时候,只想检测几类目标,这样可以利用-l指令了。加上-l的话,程序会自动加载yolo/labels.py 文件下的mylabels列表。我们可以修改这个列表的值,实现只输出制定目标类型。下面看看效果!
先后执行
python main.py -i image/car.jpg
python main.py -i image/car.jpg -l

我的yolo/labels.py中mylabels只设置了一个类别“person”,所以第一张图片只显示检测到了两个人,其他车辆等目标没有显示。
使用命令行模式实现预测是为了测试方便,如果想直接嵌入到自己的项目里,可以修改main.py文件,像这样子:
from yolo.predict import YOLO_V2_Predict
from yolo.labels import mylabels
import cv2
image = "image/t.jpg"
pbfile = 'pb/yolo.pb'
metafile = 'pb/yolo.meta'
thresh = 0.2
savedir = 'image/predict.jpg'
labels = mylabels
yolo = YOLO_V2_Predict(pbfile, metafile ,thresh=thresh,classes=labels)
img = yolo.predict(image,save=False)[0]
cv2.imshow('predict',img)
cv2.waitKey(0)至于代码非常简单,就是加载模型、预测、再就是利用darkflow的代码将网络输出的tensor转换为具体的分类信息。
贴一下主要代码,程序里也有详细的注释就不解释了,记录写来以备自己以后查看方便。
import sys
sys.path.append("..")
import tensorflow as tf
import cv2
import numpy as np
import ast
from skimage import io, transform
from lib import cy_yolo2_findboxes
import time
#装饰器
def deco(func):
'''
说明:
装饰器
:param func:
回调函数
:return:
'''
def wrapper(*args, **kwargs):
startTime = time.time()
f=func(*args, **kwargs)
endTime = time.time()
msecs = (endTime - startTime)*1000
print("time is %d ms" %msecs)
return f
return wrapper
class YOLO_V2_Predict(object):
'''
YOLO_V2 模型加载,及预测
'''
def __init__(self, pbfile, meta, thresh=None,classes=None):
'''
说明:
初始化函数,加载网络模型,初始化相关参数
:param pbfile:
tensorflow .pb文件路径及名称
:param meta:
tensorflow .meta文件路径及名称
:param thresh:
设置阈值 [0,1]\n
None: 使用.meta文件中的模型阈值,一般为0.1\n
0~1之间的数: 使用设置的阈值
:param classes:
设置分类种类,该设置仅仅设置图片显示时是否用矩形框框出指定类别的物体
'''
super(YOLO_V2_Predict,self).__init__()
self.meta = self.get_meta(meta)
if type(thresh) != type(None):
self.meta['thresh'] = thresh
if type(classes) != type(None) and type(classes) == type([]):
self.classes = classes
else:
self.classes = self.meta['labels']
with tf.Graph().as_default():
self.output_graph_def = tf.GraphDef()
with open(pbfile, "rb") as f:
self.output_graph_def.ParseFromString(f.read())
_ = tf.import_graph_def(self.output_graph_def, name="")
self.sess = tf.Session()
init = tf.global_variables_initializer()
self.sess.run(init)
self.input_x = self.sess.graph.get_tensor_by_name("input:0")
self.inW = int(self.input_x.shape[1])
self.inH = int(self.input_x.shape[2])
print(self.input_x)
self.out_label = self.sess.graph.get_tensor_by_name("output:0")
self.outW = int(self.out_label.shape[1])
self.outH = int(self.out_label.shape[2])
self.outC = int(self.out_label.shape[3])
print(self.out_label)
def __del__(self):
print('del sess')
self.sess.close()
def get_meta(self,meta):
'''
说明:
加载.meta文件
:param meta:
tensorflow .meta文件路径及名称
:return:
字典类型,包含网络设置相关参数
'''
with open(meta,'r') as f:
data = f.read()
return ast.literal_eval(data)
def findboxes(self, net_out):
'''
说明:
调用Cython程序,处理网络输出的tensor,计算得到boxes
:param net_out:
网络输出的tensor
:return:
boxes
'''
# meta
meta = self.meta
boxes = list()
boxes=cy_yolo2_findboxes.box_constructor(meta,net_out)
return boxes
@deco
def get_net(self,imname):
'''
说明:
读取图片,网络前向计算,得到网络输出
:param imname:
图片名称及路径
:return:
输出的tensor
'''
img = io.imread(imname)
img = transform.resize(img, (self.inW, self.inH, 3))
# img = cv2.imread(imname)
# img = cv2.resize(img,(self.inW, self.inH),interpolation=cv2.INTER_AREA)
img_out_softmax = self.sess.run(self.out_label, feed_dict={self.input_x:np.reshape(img, [-1, self.inW, self.inH, 3])})
return img_out_softmax.reshape(self.outW,self.outH,self.outC)
def process_box(self, b, h, w, threshold):
'''
说明:
进一步处理boxes,得到矩形框的详细信息\n
包括 left, right, top, bot, mess, max_indx, max_prob\n
x y h w 类别 颜色 概率值
:param b:
boxes
:param h:
图片高度
:param w:
图片宽度
:param threshold:
阈值
:return:
预测结果的详细信息\n
left, right, top, bot, mess, max_indx, max_prob\n
x y h w 类别 颜色 概率值
'''
max_indx = np.argmax(b.probs)
max_prob = b.probs[max_indx]
label = self.meta['labels'][max_indx]
if max_prob > threshold:
left = int((b.x - b.w / 2.) * w)
right = int((b.x + b.w / 2.) * w)
top = int((b.y - b.h / 2.) * h)
bot = int((b.y + b.h / 2.) * h)
if left < 0: left = 0
if right > w - 1: right = w - 1
if top < 0: top = 0
if bot > h - 1: bot = h - 1
mess = '{}'.format(label)
return (left, right, top, bot, mess, max_indx, max_prob)
return None
def postprocess(self, net_out, im, save=True,save_dir = 'image/aaa.jpg'):
'''
说明:
前向网络计算完成后,对网络输出tensor进行处理
:param net_out:
前向网络输出的tensor
:param im:
待预测的图片
:param save:
设置是否保存预测完成的图片
:param save_dir:
指定图片保存路径及名称,仅save=True 时有效
:return:
预测结果\n
image:
预测完成的图片数据
results:
以列表形式返回预测结果,列表元素为字典,每个字典中包含每个预测结果的\n
类别、概率值、包围框四个顶点的坐标值
'''
boxes = self.findboxes(net_out)
# meta
meta = self.meta
threshold = meta['thresh']
colors = meta['colors']
if type(im) is not np.ndarray:
imgcv = cv2.imread(im)
else:
imgcv = im
#imgcv = cv2.resize(imgcv,(self.inW, self.inH),interpolation=cv2.INTER_AREA)
h, w, _ = imgcv.shape
results = []
for b in boxes:
boxResults = self.process_box(b, h, w, threshold)
if boxResults is None:
continue
left, right, top, bot, mess, max_indx, confidence = boxResults
thick = int((h + w) // 300)
results.append(
{"label": mess, "confidence": float('%.2f' % confidence), "topleft": {"x": left, "y": top},
"bottomright": {"x": right, "y": bot}})
if mess in self.classes:
cv2.rectangle(imgcv,
(left, top), (right, bot),
colors[max_indx], thick)
cv2.putText(imgcv, mess+' '+str(confidence), (left, top - 12),
0, 1e-3 * h, colors[max_indx], thick // 3)
if save:
cv2.imwrite(save_dir, imgcv)
return imgcv,{"label": mess, "confidence": float('%.2f' % confidence),
"topleft": {"x": left, "y": top},"bottomright": {"x": right, "y": bot}}
@deco
def predict(self,image,save = True,save_dir = 'image/predict.jpg',thresh=None):
'''
说明:
预测函数
:param image:
待预测的图片名称及路径
:param save:
设置是否保存预测完成的图片
:param save_dir:
指定图片保存路径及名称,仅save=True 时有效
:param thresh:
设置阈值 [0,1]\n
None: 使用.meta文件中的模型阈值,一般为0.1\n
0~1之间的数: 使用设置的阈值
:return:
预测结果\n
image:
预测完成的图片数据
results:
以列表形式返回预测结果,列表元素为字典,每个字典中包含每个预测结果的\n
类别、概率值、包围框四个顶点的坐标值
'''
if type(thresh) != type(None):
self.meta['thresh'] = thresh
return self.postprocess(self.get_net(image),image,save=save,save_dir=save_dir)
参考:
https://github.com/thtrieu/darkflow