反向传播算法的理解(Nielsen版)
在学习standford大学机器学习在coursera上的公开课中,对于其中讲授的神经网络的反向传播算法不是很清楚,经过网上查找资料,觉得Michael Nielsen的「Neural Networks and Deep Learning」中的解释特别清楚,于是这份材料为主经过学习,现在说一下我的理解。
记忆BP算法的窍门
我总结记住反向传播算法的关键要素可以用三个数字来代表:214
- 两个假设
- 一个中间变量
- 四个公式
代价函数
在阐述反向传播算法之前,我们还是先明确代价函数的定义,我们定义代价函数的形式如下:
其中n是样本的总数,L是神经网络的总层数, y(x)=y 是样本的值, aL(x)=x 是自变量带入hypothesis计算的结果, aL(x)=x 也可以看成 hw,b(x) ,这个式子也可以写成 C=12n∑x||y−aL||2 ,吴恩达的版本是: J(W,b;x,y)=12||hw,b(x)−y||2
两个假设
总体的代价函数可以写成全部单个样本的代价总和的平均值。
也就是 C=1n∑xCx ,其中 Cx=12||y−aL||2代价函数可以认为是神经网络输出的函数。
比如对于单独的一个样本来说,代价函数可以写成 C=12||y−aL||=12∑j(yj−aLj)2
一个中间变量
我们定义神经网络中第 l 层的第 j 个神经元上的误差 δlj 为:
其中 zlj 是这个神经元上的输入,这里我们用 zlj 表示神经元上的输入,用 alj 表示这个神经元的输出。
凭什么这么定义?凭什么这么定义?凭什么这么定义?(重要的事情说三遍)
我认为理解这点是整个算法的核心,算法的全部内容都是基于这个假设展开的,如果这点不成立后面推导出花也没用!不幸的是,网上大多数文章都在这个问题都是一笔带过,在Nielsen的书里有对这点进行描述,我结合他的阐述以及我的理解表达一下我对这个假设的看法::如果我们在第 l 层的第 j 个神经元的输入 zlj 上增加一个微小的变化 Δzlj ,根据误差传递法则,这个微小的变化最终会导致代价C产生 ∂C∂zljΔzlj 的改变,其实按理来说 ∂C∂zljΔzlj 这个东西才是所谓的误差。但是在这个算法里我们并没有把整个式子定义为误差,而是取其中的偏导数部分为误差。偏导部分其实是C这个函数对于 zlj 这个变量的梯度,它反映了这个函数对于这个变量变化的敏感程度(CS231n),如果敏感程度高那么即使是自变量非常微小的变化也会引起整个函数值很大的变化,反之如果非常不敏感,即使是自变量很大的变化也不会另函数整体发生多少改变(按Nielsen的说法就是这个神经元已经接近最优了,所谓的神经元接近最优我理解的是在这个神经元上的激励函数 σ 已经非常接近真实的情况,也就是hypothesis无限的接近true,如果每个神经元的激励函数都是最优的那么整体的神经网络就是最优的)。所以偏导数部分在整个式子中是最重要的部分,为了简化运算,我们就把这部分作为第 l 层的第 j 个神经元上的误差。另外这种设定只能在 Δzlj 非常微小的情况下才管用。( 理解可能不一定准确,求批评求指正,给我讲明白了我给您发红包)
如果这个解释你还是理解不了,你就把它单纯的理解为是一种数学技巧吧,数学中我们经常会引入一些中间变量来方便计算。
我们为什么要引入这个中间变量,它非常重要,BP算法就是通过它来间接的计算 ∂C∂Wljk 和 ∂C∂blj 的。
四个公式
BP1:输出层误差公式
推导过程:
- 我们之前定义了中间变量 δlj=∂C∂zlj
因此对于最后一层(输出层)则有 δLj=∂C∂zLj ; - 由 C 是 aL 的函数(第二个假设 C=12||y−aL||=12∑j(yj−aLj)2 ),而 a 是 z 的函数( ali=σ(zli) ),根据链式求导法则有 δLj=∑k∂C∂aLk∂aLk∂zLj ;
- 为什么会有一个 ∑k 呢?这是由于第二个假设 C 可以看成 aL 的函数 C=12||y−aL||=12∑j(yj−aLj)2 ,也就是 C 是由L层全部的输出构成的,因此在求导的时候需要对每一个L层的激励元进行求导,假设L层有k个,再加上链式求导法则于是 ∂C∂zLj 就写成 ∑k∂C∂aLk∂aLk∂zLj ;
- 要注意 aLk 和 zLj 的关系,一个是L层某个神经元的输出部分,一个是L层某个神经元的输入部分,只当这两个部分作用于同一神经元的时候才有意义,也就是k=j的时候 aLk=σ(zLj) 这个式子才成立,或者说对于L层的第k个神经元来说,连到其他神经元的输入对它的输出没有意义啊,还可以这么理解对于z = x + 1 这样一个函数来说,你非要对y(一个不存在的自变量)求导(这个在复合函数求导中特别常见,经过第一次求偏导之后,第二次求偏导的自变量就没了因此得0),所以对于 k≠j 的 ∂aLk∂zLj 都等于0,所以最后式子化为 δLj=∂C∂aLj∂aLj∂zLj ;
- 又因为 aLj=σ(zLj) ,所以式子就变成 δLj=∂C∂aLjσ′(zLj) 这就是BP-1,BP-1是分量(elementwise)形式的表达方式。
再进一步由于 C=12∑j(yj−aLj)2 ,所以 ∂C∂aLj=−∑j(yj−aLj)=∑j(aLj−yj) ,所以BP-1又可以写成 δLj=∑j(aLj−yj)σ′(zLj) ,这个就是BP-1b的分量形式。 - BP-1a是BP-1的向量形式, ∇aC 表示 C 在 a 上的梯度, ∇ 是梯度符号,梯度是一个向量,其中的每个分量就是 ∂C∂aLj ;
- 而中间的普通乘积为什么会变成Hadamard乘积,这个其实就是公式从标量形式变成矢量形式的时候根据需要调整的,前两课的笔记里面有我是如何把通过标量形式推导出矢量形式的过程(基本上就是用几个小的数带进去观察一下规律总结出来的),吴恩达在standford大学机器学习讲义(CS229-notes-deeplearning)里面公式3.29到公式3.30也有类似的描述;
直观的解释
上面是从数学细节来证明的,我们再从直观的角度理解一下BP-1的含义:
∂C∂alj 表示的是代价在第L层第j个神经元输出上的变化速度,如果C不太依赖这个神经元,那么 ∂C∂alj 的值理论上接近0,也就是整个式子为0,也就是说这个神经元基本上没有误差,是非常理想的情况。而 σ′(zLj) 提现了这个激活函数在 zLj 这一点上的变化速度。
BP2:相邻两层之间的误差关系
推导过程:
- 我们还是中间变量开始 δlj=∂C∂zlj
- 这一步利用了一些数学技巧:对于第l+1层来说有 δl+1k=∂C∂zlj ,我们可以推导出,第l层的第j个神经元上的输入 zlj 与第l+1层的的第k个神经元的输入 zl+1k 之间存在着这样的关系, zl+1k=∑jwl+1kjσ(zlj)+bl+1k ,于是 zl+1k 可以看成 zlj 的函数,根据链式求导法则,我们重新改写一下 δlj=∂C∂zlj 这个公式为 δlj=∂C∂zlj=∑k∂C∂zl+1k∂zl+1k∂zlj ,而 δl+1k=∂C∂zlj ,于是 ∑k∂C∂zl+1k∂zl+1k∂zlj=∑k∂zl+1k∂zljδl+1k
- ∂zl+1k∂zlj=wl+1kjσ′(zlj)
为什么 zl+1k 明明是求和公式怎么一求偏导就没有累加符号了?符号太多看着有点眼晕,那么我们用一个简化问题的大招——代几个小数进去把问题具体化再观察其规律。
比如这样的一个结构

j在l层,其取值范围为{1,2,3},k在l+1层,取值范围为{1,2},那么 zl+1k=∑jwl+1kjσ(zlj)+bl+1k=wl+1k1σ(zl1)+wl+1k2σ(zl2)+wl+1k3σ(zl3)+bl+1k ,对于 ∂zl+1k∂zlj 我们令 j=1 那么 ∂zl+1k∂zl1 相当于用上面展开的式子对 zl1 求偏导,那么对于不含有 zl1 的项自然为零了,结果就是 wl+1k1σ(zl1) ;
所以 ∂zl+1k∂zlj=wl+1kjσ′(zlj) - 再回到式子 ∑k∂zl+1k∂zljδl+1k 中把上一步的结果代入,得到 δlj=∑kwl+1kjσ′(zlj) ,这个就是公式BP-2的分量形式。
直观的解释
还是以上面那个图为例

在原有的结构中,假设数据从输出层往输入层方向流动,我们可以知道利用原有的系数矩阵,将其转置就能计算从l+1层的输出到l层的输入。
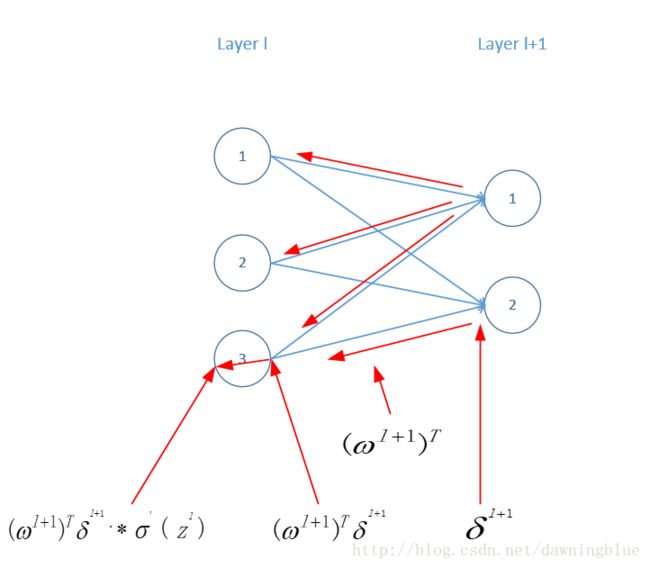
注意这里visio画不出 ⨀ ,所以左下角那个公式用“.*”来代替
BP3: 代价函数对任意一个神经元的偏置的偏导:
推导过程:
- 之前我们在推导相邻两层误差关系的时候利用了这个公式 zl+1k=∑jwl+1kjσ(zlj)+bl+1k ,所以有 zlj=∑kwljkσ(zl−1k)+blj ,或者 zlj=∑kwljkal−1k+blj (这里把l+1换成l,把j,k调换一下看着方便)。由这个公式我们可以知道 zlj 是 blj 的函数。
- 我们依然利用链式求导法则改写 ∂C∂blj ,则有 ∂C∂blj=∂C∂zlj∂zlj∂blj
- 注意到 ∂C∂zlj 其实就是 δlj ,而 zlj 对 blj 为1,也就是 ∑ 那一大堆被当成常数求导为0。所以 ∂C∂blj=δlj
直观的解释:
代价函数对某个神经元偏置的偏导就是这个神经元上的误差,这是一个特别好的性质。
BP4:代价函数对任意一个权重的偏导
推导过程:
- 我们依然使用 zlj=∑kwljkal−1k+blj 这个公式,这个公式我们可以知道 zlj 是 wljk 的函数
- 于是 ∂C∂wljk=al−1kδlj 。注意这里依然涉及到累和求导的问题,最后只会留下一个。
直观解释

∂C∂wljk=al−1kδlj 这个公式的下标太多以至于让人觉得很乱,于是我们还是用上面一个简单的结构具体化一下,最后我们再推出一般的情况。
最后我们得到这样一个结论——代价函数对于某一条弧上的权重的偏导数等于这条弧左端的神经元的输出与弧右端神经元的误差的乘积。所以BP4有的时候也可以表示成 ∂C∂w=ainδout
从BP4我们可以知道当激活值(神经元的输出值) ain 很小的时候,整个偏导数的值就很小,偏导数的值就是梯度的值,梯度小就说明梯度下降步子小,也就是说要经过多轮迭代才能得到最优的结果,这种情况也被成为“学习缓慢”。
学习缓慢的问题
下面我们我们从“学习缓慢”的角度来审视BP1到BP4这四个公式。
对于BP1,其中包含有 σ′(zlj) 这一项,如果 σ 是sigmoid函数, σ(zlj) 的值再接近1或者0的时候会变得很平,函数图形变得很平的时候意味着导数也接近于0,也就是 σ′(zlj)≈0 ,那么输出层的误差就接近于0,由于权重的梯度和偏置的梯度的计算都依赖与误差,所以梯度也都接近与0,这也就是说输出层的学习会很缓慢。
对于BP2也有类似的结果,因为BP2中也含有 σ′(zlj) 项。
对于这种由于高激活值( σ(zlj) 的值接近1)或者低激活值( σ(zlj) 的值接近0)而导致学习缓慢的神经元,我们称这个神经元饱和了。
了解了BP算法的这种特性,有什么帮助呢?由于我们上面的推导其实不依赖于任何具体的函数,所以,我们可以设计一些具有特殊特性的学习函数来避免学习缓慢的情况。说白了还是为了优化计算速度。
小结一下反向传播的四个方程式
反向传播算法
- 输入x : 求输入层神经元的输出 a1 (这个一般来说就是样本输入)
- 向前传播: 从第二层开始到最后一层,依次的计算各层的 zl 和 al
for l in [2,L]
compute zl ( zl=wlal−1+bl )
compute al ( al=σ(zl) ) - 计算输出层误差: 利用公式 δLj=∇aC⨀σ′(zLj) 计算出输出层的误差
- 反向传播误差:从L-1层开始一直到第二层,利用公式 δl=((wl+1)Tδl+1))⨀σ′(zl) 计算每一层的误差
- 输出:利用公式 ∂C∂blj=δlj , ∂C∂wljk=al−1kδlj 计算代价函数对所有未知参数的偏导数
参考文献:
- How the backpropagation algorithm works
- Backpropagation Algorithm
- CS231n:Backpropagation, Intuitions
- CS229: Deeplearning classnotes