论文笔记(三) 【Learning from Simulated and Unsupervised Images through Adversarial Training】
论文地址:论文
一、论文记录
1.摘要
因为随着训练技巧的提升,使用合成(产生)的图片进行训练,避免了人工注释的麻烦。但是存在着一个问题,就是合成图片与真实图片的分布存在着一定的差距。为了解决这一问题,本文提出了Simulated + Unsupervised(仿真+无监督)learning的方法。具体来说是通过没有标签的真实图片来提高仿真器生成图片的真实性,同时还保持原有合成图片的注释信息不变。
新提出的GAN网络有三点优势:1、自动正则化的损失(进一步保证refined图片的注释信息不变);2、局部对抗损失;3、使用改善的图片(a history of refined images)来更新D网络。
2.介绍
进一步介绍SimGAN的目的和大体思路。Figure1是Refiner网络,介绍了利用未标注的真实图片将合成的图片进行Refine操作得到改善的图片。

Figure2介绍了整个网络SimGAN网络的框架,前半部分是改善图片神经网络(refiner neural network)R网络,根据‘self-regularization term’和‘local adversarial loss’生成refined图片,后半部分是判别器(Discrimination)D网络,判断图片是refined还是real。
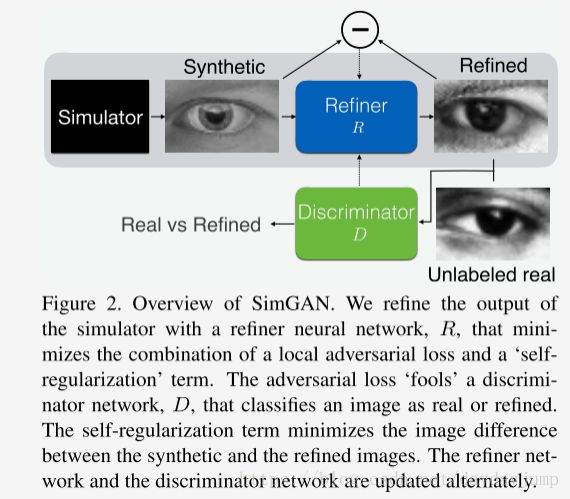
在一开始读论文,感觉本文的GAN网络模式就是GAN+Discriminator模型。
3.进一步讲解三个创新点的作用。
self-regularization loss用来进一步保证refined images和synthetic images注释信息不变。
local adversarial loss是为了避免GAN中的Discriminator过强导致生成假的图片,让D网络对图片的局部进行损失计算,而不是整张图片直接计算,这样也使得每张图片有多个损失函数值(multiple local adversarial losses per image)。
using a history of refined images 是为了保证D网络的稳定性,使用历史记录的refined图片更新D,而不仅仅是传统GAN网络每次提供的图片来更新。
4.第2章节S+U Learning with SimGAN
介绍损失函数,公式一是R网络的损失函数,但只给出了目标,前半部分是保证refined图片尽可能地像真实的图片,第二部分是保证refined图片保留原有的注释信息
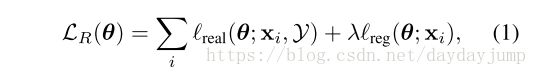
公式二是关于D的损失函数,通过最小化该函数实现目标,第一部分是希望refined图片尽可能真,第二部分希望未标注真实图片输入后值尽可能小。这个的loss与原始GAN的D的loss刚好相反,原始GAN的D希望real图片尽可能为真,generated图片尽可能为假。也许是这样才能保证refined图片更加真实。

实际训练中,x的标签是1,y的标签是0。
公式四是R网络具体的损失函数,第一部分通过最小化该函数,利用已经训练过的D来更新R网络,保证refined图片与原始合成图片不同;第二部分是自动正则化部分(self-regularization)在像素级(进行特征提取后)确保refinged的图片与原始synthetic图片的注释信息不变。
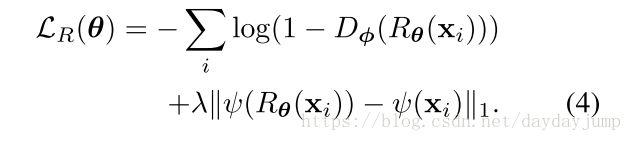
5.局部对抗损失函数(Local Adversarial Loss )
本文中提出在训练过程中Refiner网络经常会局限于图片的某一特征,重点放在一个区域来欺骗D网络,忽视了整张图片的特征。因此提出了local adversarial loss保证refined图片的每一个区域都应该趋向于真实的图片。具体效果如下图。

具体来说,并不是定义一个全局的判别器,而是定义一个判别器去分别判别图片的每一个区域。D网络输出WxH个区域的值,然后将每个区域进行交叉熵计算,并进行累加,从而提高整个网络的性能。
6.使用一系列使用过的refined图片来更新Discriminator
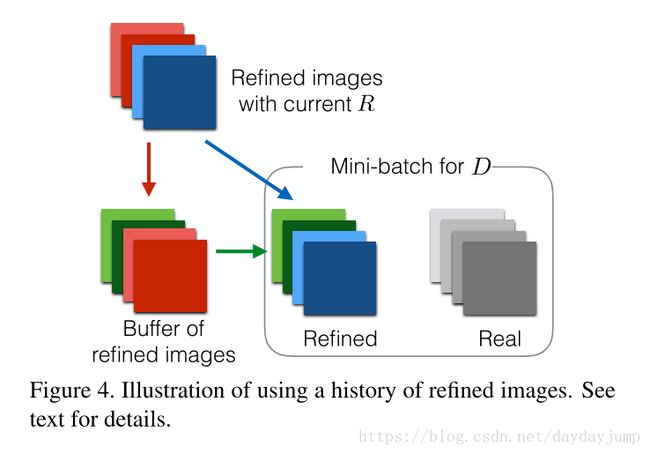
在对抗训练中存在着另外一个问题就是D网络只会注意到最新的refined图片,这会导致一是整个训练的发散;二是R网络会生成重复的图片,但是D网络已经忘记了。对于判别器而言,任何时候R网络生成的图片都应该判别为假,基于此,本文提出了用之前训练过的refined图片来再次更新Discriminator。
作者通过为之前生成的refined图片设置一缓存区,B为缓存区图片的数量,b为每次batch的大小。在每轮D的训练过程中,使用b/2的当前生成的图片和b/2的缓存区的图片来计算loss,更新参数。训练过程始终保持B的数量固定,每次训练结束用随机的b/2的新生成的refined图片来替换缓存区的图片。具体如Figure4所示。
7.具体网络细节在第6页的 Implementation Details。
Refiner网络使用的是ResNet。
二、感想
1.总体上提供了训练gan的许多技巧,但是从论文来看比较有效的应该是Updating Discriminator using a History of Refined Images这个方法比较有效可以试一下。
2.文章还提到了另外一篇论文,需要去看一下。T. Salimans, I. Goodfellow, W. Zaremba, V. Che- ung, A. Radford, and X. Chen. Improved techniques for training gans.
arXiv preprint
arXiv:1606.03498, 2016.