SynchronousQueue解析
简介
SynchronousQueue作为阻塞队列的时候,对于每一个take的线程会阻塞直到有一个put的线程放入元素为止,反之亦然。在SynchronousQueue内部没有任何存放元素的能力。所以类似peek操作或者迭代器操作也是无效的,元素只能通过put类操作或者take类操作才有效。通常队列的第一个元素是当前第一个等待的线程。如果没有线程阻塞在该队列则poll会返回null。从Collection的视角来看SynchronousQueue表现为一个空的集合。
SynchronousQueue相似于使用CSP和Ada算法(不知道怎么具体指什么算法),他非常适合做交换的工作,生产者的线程必须与消费者的线程同步以传递某些信息、事件或任务
SynchronousQueue支持支持生产者和消费者等待的公平性策略。默认情况下,不能保证生产消费的顺序。如果是公平锁的话可以保证当前第一个队首的线程是等待时间最长的线程,这时可以视SynchronousQueue为一个FIFO队列。
原理
数据结构
由于SynchronousQueue的支持公平策略和非公平策略,所以底层可能两种数据结构:
- 队列(实现公平策略)
- 栈(实现非公平策略)
队列与栈都是通过链表来实现的。具体的数据结构如下

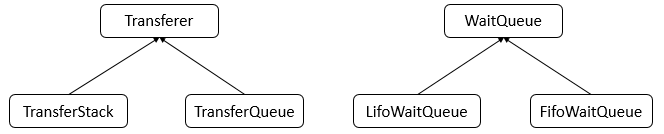
Transferer是TransferStack栈和TransferQueue队列的公共类,定义了转移数据的公共操作,由TransferStack和TransferQueue具体实现,WaitQueue、LifoWaitQueue、FifoWaitQueue表示为了兼容JDK1.5版本中的SynchronousQueue的序列化策略所遗留的
公平模式下的模型:
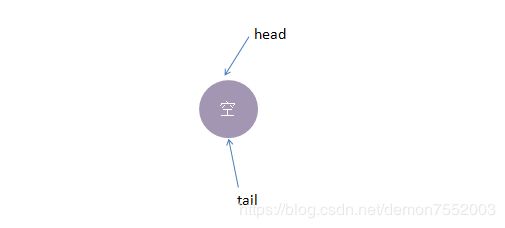
公平模式下,底层实现使用的是TransferQueue这个内部队列,它有一个head和tail指针,用于指向当前正在等待匹配的线程节点。
初始化时,TransferQueue的状态如下:
接着我们进行一些操作:
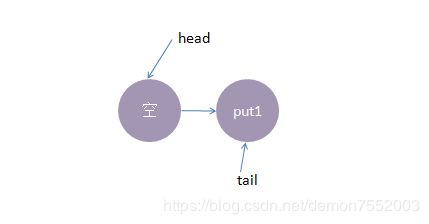
1、线程put1执行 put(1)操作,由于当前没有配对的消费线程,所以put1线程入队列,自旋一小会后睡眠等待,这时队列状态如下:
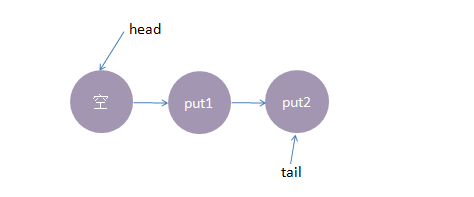
2、接着,线程put2执行了put(2)操作,跟前面一样,put2线程入队列,自旋一小会后睡眠等待,这时队列状态如下:
3、这时候,来了一个线程take1,执行了 take操作,由于tail指向put2线程,put2线程跟take1线程配对了(一put一take),这时take1线程不需要入队,但是请注意了,这时候,要唤醒的线程并不是put2,而是put1。为何? 大家应该知道我们现在讲的是公平策略,所谓公平就是谁先入队了,谁就优先被唤醒,我们的例子明显是put1应该优先被唤醒。至于读者可能会有一个疑问,明明是take1线程跟put2线程匹配上了,结果是put1线程被唤醒消费,怎么确保take1线程一定可以和次首节点(head.next)也是匹配的呢?因为put如果入队说明前面一定为put。
公平策略总结下来就是:队尾匹配队头出队。
执行后put1线程被唤醒,take1线程的 take()方法返回了1(put1线程的数据),这样就实现了线程间的一对一通信,这时候内部状态如下:
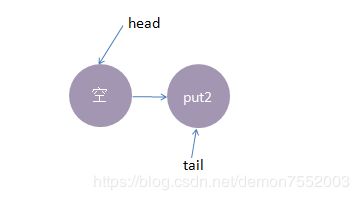
4、最后,再来一个线程take2,执行take操作,这时候只有put2线程在等候,而且两个线程匹配上了,线程put2被唤醒,
take2线程take操作返回了2(线程put2的数据),这时候队列又回到了起点,如下所示:
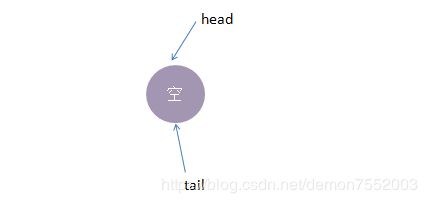
以上便是公平模式下,SynchronousQueue的实现模型。总结下来就是:队尾匹配队头出队,先进先出,体现公平原则。
非公平模式下的模型:
我们还是使用跟公平模式下一样的操作流程,对比两种策略下有何不同。非公平模式底层的实现使用的是TransferStack,
一个栈,实现中用head指针指向栈顶,接着我们看看它的实现模型:
1、线程put1执行 put(1)操作,由于当前没有配对的消费线程,所以put1线程入栈,自旋一小会后睡眠等待,这时栈状态如下:

2、接着,线程put2再次执行了put(2)操作,跟前面一样,put2线程入栈,自旋一小会后睡眠等待,这时栈状态如下:
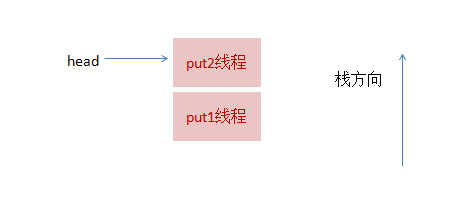
3、这时候,来了一个线程take1,执行了take操作,这时候发现栈顶为put2线程,匹配成功,但是实现会先把take1线程入栈,然后take1线程循环执行匹配put2线程逻辑,一旦发现没有并发冲突,就会把栈顶指针直接指向 put1线程

4、最后,再来一个线程take2,执行take操作,这跟步骤3的逻辑基本是一致的,take2线程入栈,然后在循环中匹配put1线程,最终全部匹配完毕,栈变为空,恢复初始状态,如下图所示:
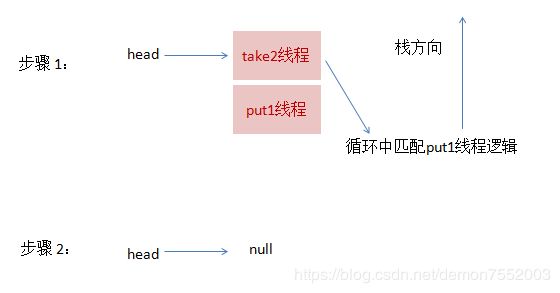
可以从上面流程看出,虽然put1线程先入栈了,但是却是后匹配,这就是非公平的由来。
源码
字段
设定时限类的
static final int NCPUS = Runtime.getRuntime().availableProcessors();
static final int maxTimedSpins = (NCPUS < 2) ? 0 : 32;
static final int maxUntimedSpins = maxTimedSpins * 16;
static final long spinForTimeoutThreshold = 1000L;
这几个主要是用来设定自旋时限的,这里首先解释一下自旋时间限有什么用。
首先阻塞是代价非常大的操作,要保存当前线程的很多数据,并且要切换上下文,等线程解释阻塞的时候还有切换回来。所以通常来说在阻塞之前都先自旋,自旋其实就是在一个循环里不停的检测是否有效,当然这要设定时限。如果在时间限内通过自旋完成了操作。那就不需要去阻塞这也自然是最好的提高了响应速度。但是如果自旋时限内还是能没能完成操作那就只有阻塞了。
java中大量运用了这样的技术。凡是有阻塞的操作都会这样做,包括内置锁在内,内置锁其实也是这样的,内置锁分为偏向锁,轻量级锁和重量级锁,其中轻量级锁其实就是自旋来替代阻塞。
当然需要自旋多长时间。这是一个根据不同情况来设定的值并没有一个准确的结论,通常来说竞争越激烈这样多自旋一段时间总是好的,效果也越明显,但是自旋时间过长会浪费cpu时间所以,设定时间还是一个很依靠经验的值。
在这里其实是这样做的,首先看一下当前cpu的数量--NCPUS
然后分两种情况
- 设定了时限的自旋时间
如果设定了时限则使用maxTimedSpins,如果NCPUS数量大于等于2则设定为为32否则为0,既一个CPU时不自旋;这是显然了,因为唯一的cpu在自旋显然不能进行其他操作来满足条件。
- 没有设定时间限
使用maxUntimedSpins,如果NCPUS数量大于等于2则设定为为32*16,否则为0;
这里的两个时间限实际上表示的是自旋次数主要用在TransferQueue和TransfStack的awaitFulfill中。
另外还有一个参数spinForTimeoutThreshold 这个参数是为了防止自定义的时间限过长,而设置的,如果设置的时间限长于这个值则取这个spinForTimeoutThreshold 为时间限。这是为了优化而考虑的。这个的单位为纳秒。
JDK1.5序列化相关
private ReentrantLock qlock;
private WaitQueue waitingProducers;
private WaitQueue waitingConsumers;其他
private transient volatile Transferer transferer;
返回固定值函数
SynchronousQueue集合大小为0,因此很多操作无意义。
public boolean isEmpty() {
return true;
}
public int size() {
return 0;
}
public int remainingCapacity() {
return 0;
}
public void clear() {
}
public boolean contains(Object o) {
return false;
}
public boolean remove(Object o) {
return false;
}
public boolean containsAll(Collection c) {
return c.isEmpty();
}
public boolean removeAll(Collection c) {
return false;
}
public boolean retainAll(Collection c) {
return false;
}
public E peek() {
return null;
}
offer,poll
public boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException {
if (e == null) throw new NullPointerException();
if (transferer.transfer(e, true, unit.toNanos(timeout)) != null)
return true;
if (!Thread.interrupted())
return false;
throw new InterruptedException();
}
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
return transferer.transfer(e, true, 0) != null;
}
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
E e = transferer.transfer(null, true, unit.toNanos(timeout));
if (e != null || !Thread.interrupted())
return e;
throw new InterruptedException();
}
public E poll() {
return transferer.transfer(null, true, 0);
}
put,take
public E take() throws InterruptedException {
E e = transferer.transfer(null, false, 0);
if (e != null)
return e;
Thread.interrupted();
throw new InterruptedException();
}
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
if (transferer.transfer(e, false, 0) == null) {
Thread.interrupted();
throw new InterruptedException();
}
}
Transferer
以上Queue的方法,实际上都调用了Transferer.transfer()方法。
abstract static class Transferer {
/**
* Performs a put or take.
*执行一个put或take操作
*如果元素为非空,则交给消费者处理,如果为null,请求生产者生产一个元素,并返回元素
*返回元素,如果非null,要不是队列中已经存在的,要不是生产者刚生产的。
*如果为null,意味着由于超时,中断导致操作失败,调用可以通过检查线程中断位,辨别发生了哪一种情况。
* @param timed if this operation should timeout
* @param nanos the timeout, in nanoseconds
* @return if non-null, the item provided or received; if null,
* the operation failed due to timeout or interrupt --
* the caller can distinguish which of these occurred
* by checking Thread.interrupted.
*/
abstract E transfer(E e, boolean timed, long nanos);
}
TransferStack
节点
static final class SNode {
// 下一个结点
volatile SNode next; // next node in stack
// 相匹配的结点
volatile SNode match; // the node matched to this
// 等待的线程
volatile Thread waiter; // to control park/unpark
// 元素项
Object item; // data; or null for REQUESTs
// 模式
int mode;
// item域和mode域不需要使用volatile修饰,因为它们在volatile/atomic操作之前写,之后读
SNode(Object item) {
this.item = item;
}
boolean casNext(SNode cmp, SNode val) {
return cmp == next &&
UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
/*
尝试匹配目标节点与本节点,如果匹配,可以唤醒线程。补给者调用tryMatch方法
确定它们的等待线程。等待线程阻塞到它们自己被匹配。如果匹配返回true。
*/
boolean tryMatch(SNode s) {
if (match == null &&
UNSAFE.compareAndSwapObject(this, matchOffset, null, s)) {
Thread w = waiter;
if (w != null) { // waiters need at most one unpark
waiter = null;
LockSupport.unpark(w);
}
return true;
}
return match == s;
}
/**
* 把match设置为自身。
*/
void tryCancel() {
UNSAFE.compareAndSwapObject(this, matchOffset, null, this);
}
//match==自身,表示取消
boolean isCancelled() {
return match == this;
}
// Unsafe mechanics
// 反射机制
private static final sun.misc.Unsafe UNSAFE;
// match域的内存偏移地址
private static final long matchOffset;
// next域的偏移地址
private static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class k = SNode.class;
matchOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("match"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}tryMatch函数说明:
将s结点与本结点进行匹配,匹配成功,则unpark等待线程。具体流程如下
① 判断本结点的match域是否为null,若为null,则进入步骤②,否则,进入步骤⑤
② CAS设置本结点的match域为s结点,若成功,则进入步骤③,否则,进入步骤⑤
③ 判断本结点的waiter域是否为null,若不为null,则进入步骤④,否则,进入步骤⑤
④ 重新设置本结点的waiter域为null,并且unparkwaiter域所代表的等待线程。进入步骤⑥
⑤ 比较本结点的match域是否为本结点,若是,则进入步骤⑥,否则,进入步骤⑦
⑥ 返回true
⑦ 返回false
属性
static final class TransferStack extends Transferer {
// 表示消费数据的消费者
static final int REQUEST = 0;
// 表示生产数据的生产者
static final int DATA = 1;
// 表示匹配另一个生产者或消费者
static final int FULFILLING = 2;
static boolean isFulfilling(int m) { return (m & FULFILLING) != 0; }
/** The head (top) of the stack */
// 头结点
volatile SNode head;
} 说明:TransferStack有三种不同的状态:
- REQUEST,表示消费数据的消费者
- DATA,表示生产数据的生产者
- FULFILLING,表示匹配另一个生产者或消费者。
任何线程对TransferStack的操作都属于上述3种状态中的一种。
这里怎么形象的描述一下TransferStack是怎么工作的。一个典型的例子就是像俄罗斯方块一样。
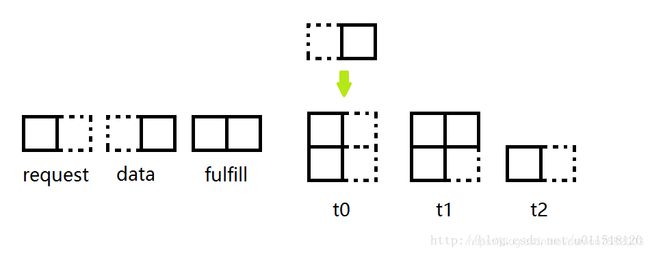
栈的状态就好像玩俄罗斯方块一样,只有三种情况
- 当前传入的模块是域栈顶模块相同(或者栈为空也是一样),对应于t0。
- 当前传入的模块与栈顶模块匹配,达成交付操作,对应于t1。
- 当前栈顶的模块是匹配模块需要删除,对应于t2。
方法
transfer()
/**
put或take一个元素
*/
Object transfer(Object e, boolean timed, long nanos) {
/*
算法的基本步骤是,循环尝试以下3步
1.如果队列为空或已经包含相同模式的节点,则尝试节点入栈,等待匹配, 返回,如果取消返回null。
2.如果包含一个互补模式的节点(take(REQUEST)->put(DATA);put(DATA)->take(REQUEST)),
则尝试一个FULFILLING节点入栈,同时匹配等待的协同节点,两个节点同时出栈,返回匹配的元素。
由于其他线程执行步骤3,实际匹配和解除链接指针动作不会发生。
3.如果栈顶存在另外一个FULFILLING的节点,则匹配节点,并出栈。这段的代码
与fulfilling相同,除非没有元素返回
*/
SNode s = null; // constructed/reused as needed
//根据元素判断节点模式,元素不为null,则为DATA,否则为REQUEST
int mode = (e == null) ? REQUEST : DATA;
for (;;) {
SNode h = head;
if (h == null || h.mode == mode) { //如果是空队列,或栈头节点的模式与要放入的节点模式相同
if (timed && nanos <= 0) { // can't wait
//如果超时,则取消等待,出栈,设置栈头为其后继
if (h != null && h.isCancelled())
casHead(h, h.next); // pop cancelled node
else
return null; //否则返回null
}
else if (casHead(h, s = snode(s, e, h, mode)))
{
//如果非超时,则将创建的新节点入栈成功,即放在栈头,自旋等待匹配节点(timed决定超时,不超时)
SNode m = awaitFulfill(s, timed, nanos);
if (m == s) { // wait was cancelled
//如果返回的是自己,节点取消等待,从栈中移除,并遍历栈移除取消等待的节点
clean(s);
return null;
}
if ((h = head) != null && h.next == s)
casHead(h, s.next); // help s's fulfiller //s节点匹配成功,则设置栈头为s的后继
//匹配成功,REQUEST模式返回,匹配到的节点元素(DATA),DATA模式返回当前节点元素
return (mode == REQUEST) ? m.item : s.item;
}
} else if (!isFulfilling(h.mode)) { // try to fulfill
//如果栈头节点模式不为Fulfilling,判断是否取消等待,是则出栈
if (h.isCancelled()) // already cancelled
casHead(h, h.next); // pop and retry
//非取消等待,则是节点入栈
else if (casHead(h, s=snode(s, e, h, FULFILLING|mode))) {
for (;;) { // loop until matched or waiters disappear
SNode m = s.next; // m is s's match
//后继节点为null,则出栈
if (m == null) { // all waiters are gone
casHead(s, null); // pop fulfill node
s = null; // use new node next time
break; // restart main loop
}
SNode mn = m.next;
//尝试匹配是s节点
if (m.tryMatch(s)) {
//匹配成功两个节点则出栈,
casHead(s, mn); // pop both s and m
return (mode == REQUEST) ? m.item : s.item;
} else // lost match
//否则,跳过s的后继节点
s.casNext(m, mn); // help unlink
}
}
} else { // help a fulfiller
//如果栈头节点模式为Fulfilling,找出栈头的匹配节点
SNode m = h.next; // m is h's match
if (m == null) // waiter is gone
//如果无后继等待节点,则栈头出栈
casHead(h, null); // pop fulfilling node
else {
//尝试匹配,如果匹配成功,栈头和匹配节点出栈,否则跳过后继节点
SNode mn = m.next;
if (m.tryMatch(h)) // help match
casHead(h, mn); // pop both h and m
else // lost match
h.casNext(m, mn); // help unlink
}
}
}
} 整个程序在一个循环内,只有满足情况才能跳出循环。
大概分三种情况。
- 第一种情况是当前栈为空或者当前模式相同的节点遇到一起。
- 第二种情况是尝试匹配当前的节点,先将当前节点s如栈,如果失败(栈顶节点可能会被其他线程匹配),则循环进行匹配。
- 第三种情况是辅助方法,清除匹配成功的节点,或者当节点所属线程消失后将其移除栈。
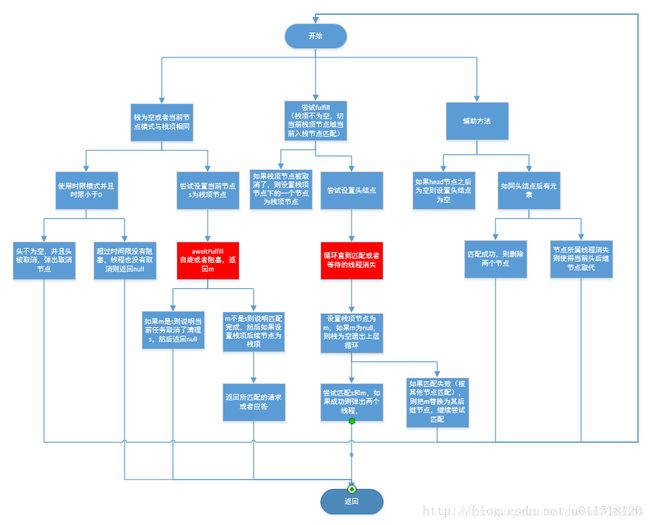
awaitFulfill()
说明:此函数表示当前线程自旋或阻塞,直到结点被匹配。awaitFulfill函数调用了shouldSpin函数
SNode awaitFulfill(SNode s, boolean timed, long nanos) {
/*
当一个节点线程将要阻塞时,在实际park之前,设置等待线程的field,重新至少检查
自身状态一次,这样可以避免在fulfiller注意到有等待线程非null,可以操作时,掩盖了竞争。
当awaitFulfill被栈头节点调用时,通过自旋park一段时间,以免在刚要阻塞的时刻,
有生产者或消费者到达。这在多处理机上将会发生。
主循环检查返回的顺序将会反应,在正常返回时,中断是否处理,还是超时处理。
(在放弃匹配之前,及最后一次检查,正好超时),除非调用SynchronousQueue的
非超时poll/offer操作,不会检查中断,不等待,那么将调用transfer方法中的其他部分逻辑,
而不是调用awaitFulfill。
*/
long lastTime = timed ? System.nanoTime() : 0;
Thread w = Thread.currentThread();
SNode h = head;
//获取自旋的次数
int spins = (shouldSpin(s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
if (w.isInterrupted())
//如果线程被中断,则取消等待
s.tryCancel();
SNode m = s.match;
if (m != null)
//如果节点的匹配节点不为null,则返回匹配节点
return m;
if (timed) {
long now = System.nanoTime();
nanos -= now - lastTime;
lastTime = now;
if (nanos <= 0) {
//如果超时,则取消等待
s.tryCancel();
continue;
}
}
if (spins > 0)
//如果自旋次数大于零,且可以自旋,则自旋次数减1
spins = shouldSpin(s) ? (spins-1) : 0;
else if (s.waiter == null)
//如果节点S的等待线程为空,则设置当前节点为S节点的等待线程,以便可以park后继节点。
s.waiter = w; // establish waiter so can park next iter
else if (!timed)
//非超时等在者,park当前线程
LockSupport.park(this);
else if (nanos > spinForTimeoutThreshold)
//如果超时时间大于,最大自旋阈值,则超时park当前线程
LockSupport.parkNanos(this, nanos);
}
}
/**
如果节点在栈头或栈头为FULFILLING的节点,则返回true
*/
boolean shouldSpin(SNode s) {
SNode h = head;
return (h == s || h == null || isFulfilling(h.mode));
}
说明:shouldSpin函数表示是当前结点所包含的线程(当前线程)进行空旋等待,有如下情况需要进行空旋等待
① 当前结点为头结点
② 头结点为null
③ 头结点正在匹配中
clean函数
说明:此函数用于移除从栈顶头结点开始到该结点(不包括)之间的所有已取消结点。
void clean(SNode s) {
// s结点的item设置为null
s.item = null; // forget item
// waiter域设置为null
s.waiter = null; // forget thread
// 获取s结点的next域
SNode past = s.next;
if (past != null && past.isCancelled()) // next域不为null并且next域被取消
// 重新设置past
past = past.next;
// Absorb cancelled nodes at head
SNode p;
while ((p = head) != null && p != past && p.isCancelled()) // 从栈顶头结点开始到past结点(不包括),将连续的取消结点移除
// 比较并替换head域(弹出取消的结点)
casHead(p, p.next);
// Unsplice embedded nodes
while (p != null && p != past) { // 移除上一步骤没有移除的非连续的取消结点
// 获取p的next域
SNode n = p.next;
if (n != null && n.isCancelled()) // n不为null并且n被取消
// 比较并替换next域
p.casNext(n, n.next);
else
// 设置p为n
p = n;
}
}
TransferQueue
节点
static final class QNode {
volatile QNode next; // next node in queue
// 元素项。指向this,表示取消
volatile Object item; // CAS'ed to or from null
volatile Thread waiter; // to control park/unpark
// 是否为数据
final boolean isData;
QNode(Object item, boolean isData) {
this.item = item;
this.isData = isData;
}
// 比较并替换next域
boolean casNext(QNode cmp, QNode val) {
return next == cmp &&
UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
// 比较并替换item域
boolean casItem(Object cmp, Object val) {
return item == cmp &&
UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}
// 取消本结点,将item域设置为自身
void tryCancel(Object cmp) {
UNSAFE.compareAndSwapObject(this, itemOffset, cmp, this);
}
// 是否被取消
boolean isCancelled() {
// item域是否等于自身
return item == this;
}
// 是否不在队列中
boolean isOffList() {
// next与是否等于自身
return next == this;
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long itemOffset;
private static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class k = QNode.class;
itemOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("item"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}属性
static final class TransferQueue extends Transferer {
// 队列的头结点
transient volatile QNode head;
// 队列的尾结点
transient volatile QNode tail;
// 指向一个取消的结点,当一个结点是最后插入队列时,当被取消时,它可能还没有离开队列
transient volatile QNode cleanMe;
} 方法
构造函数:
head指向一个dummy Node。作为哨兵节点,tail=head;
TransferQueue() {
//构造队列
QNode h = new QNode(null, false); // initialize to dummy node.
head = h;
tail = h;
} 引用控制
/**
* Tries to cas nh as new head; if successful, unlink
* old head's next node to avoid garbage retention.
尝试设置新的队头节点为nh,并比较旧头节点,成功则,解除旧队列头节点的next链接,及指向自己
*/
void advanceHead(QNode h, QNode nh) {
if (h == head &&
UNSAFE.compareAndSwapObject(this, headOffset, h, nh))
h.next = h; // forget old next
}
/**
* Tries to cas nt as new tail.
尝试设置队尾
*/
void advanceTail(QNode t, QNode nt) {
if (tail == t)
UNSAFE.compareAndSwapObject(this, tailOffset, t, nt);
}
/**
* Tries to CAS cleanMe slot.
尝试设置取消等待节点为val。并比较旧的等待节点是否为cmp
*/
boolean casCleanMe(QNode cmp, QNode val) {
return cleanMe == cmp &&
UNSAFE.compareAndSwapObject(this, cleanMeOffset, cmp, val);
} transfer
/**
生产或消费一个元素
*/
Object transfer(Object e, boolean timed, long nanos) {
/*
基本算法是循环尝试,执行下面两个步中的,其中一个:
1.如果队列为空,或队列中为相同模式的节点,尝试节点入队列等待, 直到fulfilled,返回匹配元素,或者由于中断,超时取消等待。
2.如果队列中包含节点,transfer方法被一个协同模式的节点调用, 则尝试补给或填充等待线程节点的元素,并出队列,返回匹配元素。
在每一种情况,执行的过程中,检查和尝试帮助其他stalled/slow线程移动队列头和尾节点
循环开始,首先进行null检查,防止为初始队列头和尾节点。当然这种情况,
在当前同步队列中,不可能发生,如果调用持有transferer的non-volatile/final引用,
可能出现这种情况。一般在循环的开始,都要进行null检查,检查过程非常快,不用过多担心
性能问题。
*/
QNode s = null; // constructed/reused as needed
//如果元素e不为null,则为DATA模式,否则为REQUEST模式
boolean isData = (e != null);
for (;;) {
QNode t = tail;
QNode h = head;
//如果队列头或尾节点没有初始化,则跳出本次自旋
if (t == null || h == null) // saw uninitialized value
continue; // spin
if (h == t || t.isData == isData) { // 如果队列为空,或当前节点与队尾模式相同
QNode tn = t.next;
if (t != tail) // 如果t不是队尾,非一致性读取,跳出本次自旋
continue;
if (tn != null) { // lagging tail 。tn不为null,有其他线程添加了tn结点 (设置了tail.next)
//如果t的next不为null,设置新的队尾,跳出本次自旋
advanceTail(t, tn);
continue;
}
if (timed && nanos <= 0) // can't wait
//如果超时,且超时时间小于0,则返回null
return null;
if (s == null)
//根据元素和模式构造节点
s = new QNode(e, isData);
if (!t.casNext(null, s)) // 新节点入队列失败,则退出循环
continue;
//设置队尾为当前节点
advanceTail(t, s); // swing tail and wait
//自旋或阻塞直到节点被fulfilled
Object x = awaitFulfill(s, e, timed, nanos);
if (x == s) { // wait was cancelled
//如果s指向自己,s出队列,并清除队列中取消等待的线程节点
clean(t, s);
return null;
}
if (!s.isOffList()) { // s仍然在队列中
advanceHead(t, s); // unlink if head
if (x != null) // and forget fields
s.item = s;
s.waiter = null;
}
//如果自旋等待匹配的节点元素不为null,则返回x,否则返回e
return (x != null) ? x : e;
} else { // complementary-mode
//如果队列不为空,且与队头的模式不同,及匹配成功 (与队尾匹配成功,则一定与队头匹配成功!)
QNode m = h.next; // node to fulfill
if (t != tail || m == null || h != head)
//如果h不为当前队头,则返回,即读取不一致
continue; // inconsistent read
Object x = m.item;
if (
isData == (x != null) || // m already fulfilled
x == m || // m cancelled
!m.casItem(x, e) // // CAS failed
)
{
//如果队头后继,取消等待,则出队列
advanceHead(h, m); // dequeue and retry
continue;
}
//否则匹配成功
advanceHead(h, m); // successfully fulfilled
//unpark等待线程
LockSupport.unpark(m.waiter);
//如果匹配节点元素不为null,则返回x,否则返回e,即take操作,返回等待put线程节点元素,
//put操作,返回put元素
return (x != null) ? x : e;
}
}
}
实现逻辑:
- 如果头节点为空或者已经包含了相同模式的结点,那么尝试将结点增加到栈中并且等待匹配。如果被取消,返回null
- 如果头节点是一个模式不同的结点,尝试将一个
fulfilling结点加入到栈中,匹配相应的等待结点,然后一起从栈中弹出,并且返回匹配的元素。匹配和弹出操作可能无法进行,由于其他线程正在执行操作3 - 如果栈顶已经有了一个
fulfilling结点,帮助它完成它的匹配和弹出操作,然后继续。

awaitFulFill()
此函数表示当前线程自旋或阻塞,直到结点被匹配。
Object awaitFulfill(QNode s, E e, boolean timed, long nanos) {
/* Same idea as TransferStack.awaitFulfill */
// 根据timed标识计算截止时间
final long deadline = timed ? System.nanoTime() + nanos : 0L;
// 获取当前线程
Thread w = Thread.currentThread();
// 计算空旋时间
int spins = ((head.next == s) ? //不是是第一个匹配元素。spins 设置为0
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) { // 无限循环,确保操作成功
if (w.isInterrupted()) // 当前线程被中断
// 取消 。设置item为自身。
s.tryCancel(e);
// 获取s的元素域
Object x = s.item;
if (x != e) // 元素不为e。表示未取消。返回item属性。
// 返回
return x;
if (timed) { // 设置了timed
// 计算继续等待的时间
nanos = deadline - System.nanoTime();
if (nanos <= 0L) { // 继续等待的时间小于等于0
// 取消
s.tryCancel(e);
// 跳过后面的部分,继续
continue;
}
}
if (spins > 0) // 空旋时间大于0
// 减少空旋时间
--spins;
else if (s.waiter == null) // 等待线程为null
// 设置等待线程
s.waiter = w;
else if (!timed) // 没有设置timed标识
// 禁用当前线程并设置了阻塞者
LockSupport.park(this);
else if (nanos > spinForTimeoutThreshold) // 继续等待的时间大于阈值
// 禁用当前线程,最多等待指定的等待时间,除非许可可用
LockSupport.parkNanos(this, nanos);
}
}clean()
此函数用于移除已经被取消的结点
void clean(QNode pred, QNode s) {
// 设置等待线程为null
s.waiter = null; // forget thread
/*
* 在任何时候,最后插入的结点不能删除,为了满足这个条件
* 如果不能删除s结点,我们将s结点的前驱设置为cleanMe结点
* 删除之前保存的版本,至少s结点或者之前保存的结点能够被删除
* 所以最后总是会结束
*/
while (pred.next == s) { // pred的next域为s // Return early if already unlinked
// 获取头结点
QNode h = head;
// 获取头结点的next域
QNode hn = h.next; // Absorb cancelled first node as head
if (hn != null && hn.isCancelled()) { // hn不为null并且hn被取消
// 设置新的头结点
advanceHead(h, hn);
// 跳过后面的部分,继续
continue;
}
// 获取尾结点,保证对尾结点的读一致性
QNode t = tail; // Ensure consistent read for tail
if (t == h) // 尾结点为头结点,表示队列为空
// 返回
return;
// 获取尾结点的next域
QNode tn = t.next;
if (t != tail) // t不为尾结点,不一致,重试
// 跳过后面的部分,继续
continue;
if (tn != null) { // tn不为null
// 设置新的尾结点
advanceTail(t, tn);
// 跳过后面的部分,继续
continue;
}
if (s != t) { // s不为尾结点,移除s // If not tail, try to unsplice
QNode sn = s.next;
if (sn == s || pred.casNext(s, sn)) //
return;
}
// 获取cleanMe结点
QNode dp = cleanMe;
if (dp != null) { // dp不为null,断开前面被取消的结点 // Try unlinking previous cancelled node
// 获取dp的next域
QNode d = dp.next;
QNode dn;
if (d == null || // d is gone or
d == dp || // d is off list or
!d.isCancelled() || // d not cancelled or
(d != t && // d not tail and
(dn = d.next) != null && // has successor
dn != d && // that is on list
dp.casNext(d, dn))) // d unspliced
casCleanMe(dp, null);
if (dp == pred)
return; // s is already saved node
} else if (casCleanMe(null, pred))
return; // Postpone cleaning s
}
}这里的队列其实是单向链表。所以他只能设置后继的节点而不能设置前向的节点,这会产生一个问题,就是加入队列尾的节点失效了要删除怎么办?我们没办法引用队列尾部倒数第二个节点。所以这里采用了一个方法就是将当前的尾结点保存为cleanMe节点,这样在下次再次清除的时候通常cleanMe通常就不是尾结点了,这样就可以删除了。也就是每次调用的时候删除的其实是上次需要结束的节点。
参考:
https://blog.csdn.net/yanyan19880509/article/details/52562039
https://blog.csdn.net/u011518120/article/details/53906484
http://www.cs.rochester.edu/research/synchronization/pseudocode/duals.html