Python爬取淘宝商品信息并对其进行数据分析
上一篇文章https://www.jianshu.com/p/9683898a4237
已经爬取了淘宝商品信息了现在对其进行数据分析
####对商品标题进行文本分析
使用jieba分词器,对raw_title列每一个商品标题进行分词,通过停用表StopWords对标题进行去除停用词。因为下面要统计每个词语的个数,所以 为了准确性,在这里对过滤后的数据 title_clean 中的每个list的元素进行去重,即每个标题被分割后的词语唯一。
代码如下:
# 将所有商品标题转换为list
title = data.raw_title.values.tolist()
'''
遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
'''
# 对每个标题进行分词,使用jieba分词
import jieba
title_s = []
for line in title:
title_cut = jieba.lcut(line)
title_s.append(title_cut)
# 导入停用此表
stopwords = [line.strip() for line in open('StopWords.txt', 'r', encoding='utf-8').readlines()]
# 剔除停用词
title_clean = []
for line in title_s:
line_clean = []
for word in line:
if word not in stopwords:
line_clean.append(word)
title_clean.append(line_clean)
# 进行去重
title_clean_dist = []
for line in title_clean:
line_dist = []
for word in line:
if word not in line_dist:
line_dist.append(word)
title_clean_dist.append(line_dist)
# 将 title_clean_dist 转化为一个list
allwords_clean_dist = []
for line in title_clean_dist:
for word in line:
allwords_clean_dist.append(word)
# 把列表 allwords_clean_dist 转为数据框
df_allwords_clean_dist = pd.DataFrame({
'allwords':allwords_clean_dist
})
# 对过滤_去重的词语 进行分类汇总
word_count = df_allwords_clean_dist.allwords.value_counts().reset_index()
word_count.columns = ['word', 'count']
接下来需要对已分词好的数据进行词云可视化,代码如下:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from scipy.misc import imread
plt.figure(figsize=(20,10))
# 读取图片
pic = imread("猫.png")
w_c = WordCloud(font_path="simhei.ttf", background_color="white", mask=pic, max_font_size=100, margin=1)
wc = w_c.fit_words({
x[0]:x[1] for x in word_count.head(100).values
})
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()

分析结论:
- 组合、整装商品占比很高;
- 特产、零食、休闲、小吃等字眼的商品占比较高;
- 从品牌上看:三只松鼠、百草味、良品铺子等网红零食品牌为多。
不同商品关键字word对应的sales之和的统计分析:
假如所爬取到的商品标题中含有“糖果”一词的销量之和,也就是说求出具有“糖果”关键字的商品销量之和。代码如下:
import numpy as np
'''
遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
'''
# 重新更新索引,之前去重的时候没有更新数据data的索引,导致部分行缺失值
data = data.reset_index(drop=True)
# 不同关键词word对应的sales之和的统计分析
w_s_sum = []
for w in word_count.word:
i = 0
s_list = []
for t in title_clean_dist:
if w in t:
s_list.append(data.sales[i]);
i+=1
w_s_sum.append(sum(s_list)) # list求和
df_w_s_sum = pd.DataFrame({'w_s_sum':w_s_sum})
# 把 word_count 与对应的 df_w_s_sum 合并为一个表:
df_word_sum = pd.concat([word_count, df_w_s_sum],
axis=1, ignore_index=True)
df_word_sum.columns = ['word', 'count', 'w_s_sum'] #添加列名
然后对df_word_sum中的word和w_s_sum两列进行可视化,本文将取销量排名前30的词语进行绘图:
df_word_sum.sort_values('w_s_sum', inplace=True, ascending=True) # 升序
df_w_s = df_word_sum.tail(30) # 取最大的30行数据
import matplotlib
from matplotlib import pyplot as plt
'''
遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
'''
font = {'family' : 'SimHei'} # 设置字体
matplotlib.rc('font', **font)
index = np.arange(df_w_s.word.size)
plt.figure(figsize=(10,20))
plt.barh(index, df_w_s.w_s_sum, color='blue', align='center', alpha=0.8)
plt.yticks(index, df_w_s.word, fontsize=15)
#添加数据标签
for y, x in zip(index, df_w_s.w_s_sum):
plt.text(x, y, '%.0f' %x , ha='left', va='center', fontsize=15)
plt.show()
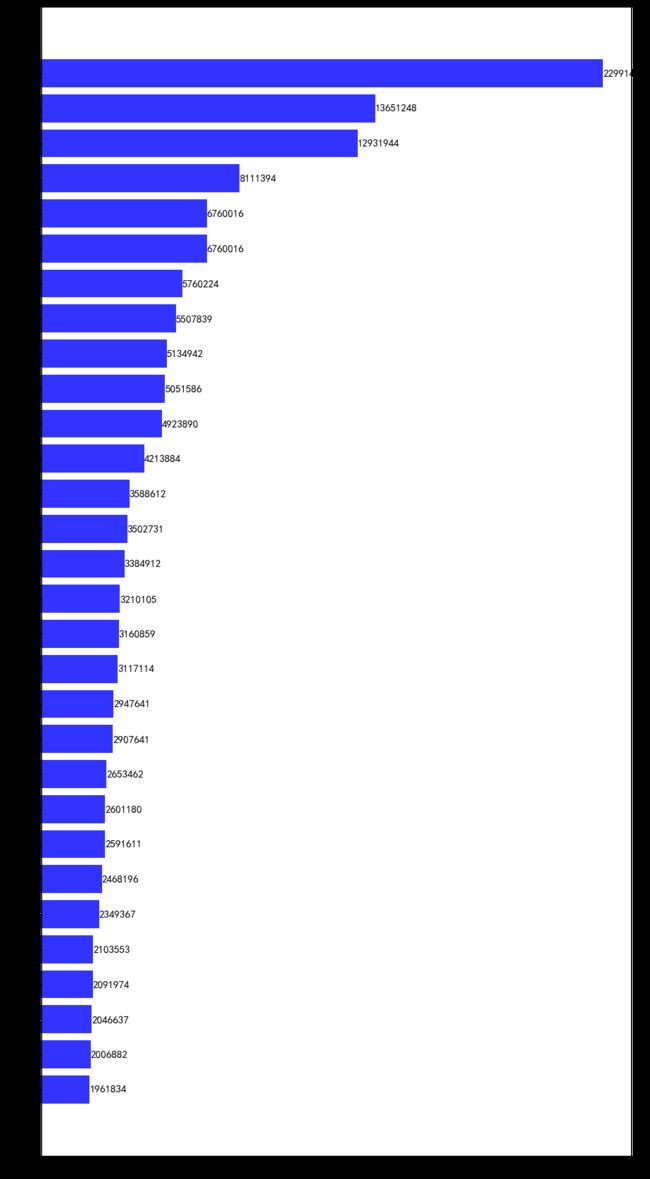
由图表可知:
-
休闲零食小吃之类的销量最高;
-
组合、整装商品占比很高;
-
从关键字可以看出销量榜上以网红品牌为主。
####商品的价格分布情况分析:
本文中限定所爬取的零食单品的销售价格区间在0-200元,在这里我们结合自身产品情况对商品的价格分布情况分析,代码如下:
plt.figure(figsize=(7,5))
plt.hist(data['view_price'], bins=15, color='blue')
plt.xlabel('价格', fontsize=25)
plt.ylabel('商品数量', fontsize=25)
plt.title('不同价格对应的商品数量分布', fontsize=17)
plt.show()
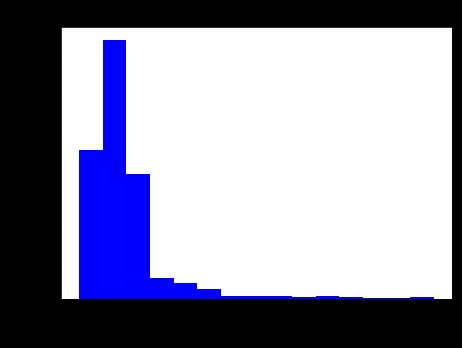
由图表可知:
-
商品数量集中在0-50元之间,总体呈现先增后减;
-
低价位商品居多,价格在12-25元之间的商品最多,次之0-12元,商品最少的在价格160-180元之间;