python scrapy爬取网站数据二(scrapy使用详细介绍)
上篇文章 python scrapy爬取网站数据一 从一个简单的例子中给大家呈现了scrapy的使用,本篇将对scrapy的常用写法 做一个简单的介绍。
1、scrapy工程创建
在命令行输入如下命令,创建一个使用scrapy框架的工程
scrapy startproject scrapyDemo
创建好后的工程结构如下图
输入如下命令,在工程目录中创建示例代码
PS C:\ProjectPycharm> cd scrapyDemo
PS C:\ProjectPycharm\scrapyDemo> scrapy genspider example example.com
Created spider 'example' using template 'basic' in module:
scrapyDemo.spiders.example
上面的工程文件说明
- scrapyDemo/spiders/ 爬虫目录,如:创建文件,编写爬虫规则
- scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)(一般不需要做修改)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model,定义的结构可在piplines中、example.py中使用
- pipelines.py 数据处理行为,如:一般结构化的数据持久化(保存到excel、保存到数据库、下载图片到本地等)
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
2、scrapy简单爬虫代码
本示例代码以爬取今日头条的新闻,抓取标题和内容并保存为本地文件。
1)定义爬取的条目(item)
该条目的信息 在items.py中定义,在example.py中填充,通过pipelines.py保存到excel
# items.py
import scrapy
class ScrapydemoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() # 新闻标题
content = scrapy.Field() # 新闻内容
pass2)爬取信息
在example.py中编写爬取信息代码,首先访问FT中文网-中国咨询,然后遍历新闻分类banner,然后访问该分类,在获取该分类下的新闻列表,然后访问每条新闻的详细信息页,保存新闻标题和内容到item中
① xpath分析
财经的xpath截取为:
categoryLinks = response.xpath('//li[@data-section="china"]/ol[@class="nav-items"]/li[@class="nav-item"]/a/@href').extract()
categoryNames = response.xpath('//li[@data-section="china"]/ol[@class="nav-items"]/li[@class="nav-item"]/a/text()').extract()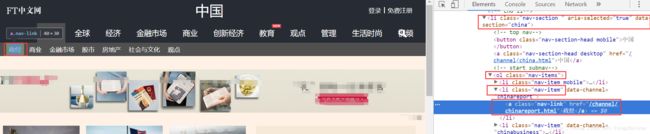
② 爬取代码
在发起请求函数scrapy.Request中可以传入自定义值到meta这个变量中,可以在自定义分析函数中获取到请求中的自定义参数
# -*- coding: utf-8 -*-
import scrapy
from scrapyDemo.items import ScrapydemoItem
headers = {
'accept':'application/json, text/javascript',
'accept-encoding':'gzip, deflate, br',
'accept-language':'zh-CN,zh;q=0.9',
'content-type':'application/x-www-form-urlencoded',
'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'x-requested-with':'XMLHttpRequest'
}
class ExampleSpider(scrapy.Spider):
name = 'ExampleSpider'
allowed_domains = ['www.ftchinese.com']
start_urls = []
def start_requests(self):
yield scrapy.Request('http://www.ftchinese.com/channel/china.html',headers=headers,meta={'baseUrl': 'http://www.ftchinese.com/'}, callback=self.parse)
def parse(self, response):
baseUrl = response.meta['baseUrl']
categoryLinks = response.xpath('//li[@data-section="china"]/ol[@class="nav-items"]/li[@class="nav-item"]/a/@href').extract()
categoryNames = response.xpath('//li[@data-section="china"]/ol[@class="nav-items"]/li[@class="nav-item"]/a/text()').extract()
i = 0
for categoryLink in categoryLinks:
# meta={'category': categoryNames[i]} 用于scrapy爬取信息分散在多个页面,
# 用于向后面的parse传递前面parse分析得到的内容
yield scrapy.Request(baseUrl+categoryLink,headers=headers,meta={'category': categoryNames[i],'baseUrl':baseUrl},
callback=self.parseTwise)
i = i+1
def parseTwise(self,response):
baseUrl = response.meta['baseUrl']
newLinks = response.xpath('//a[@class="item-headline-link"]/@href').extract()
for newLink in newLinks:
yield scrapy.Request(baseUrl+newLink,headers=headers, meta=response.meta,callback=self.parseThird)
def parseThird(self,response):
category = response.meta['category']
newTitle = response.xpath('//h1[@class="story-headline"]/text()').extract()
newContent = response.xpath('//h1[@class="story-body"]/text()').extract()
item = ScrapydemoItem()
item['category'] = category
item['title'] = if len(newTitle)<=0 else newTitle[0]
item['content'] = '' if len(newContent)<=0 else newContent[0]
yield item3)保存内容
在pipelines.py中编写保存文件代码
import os
class ScrapydemoPipeline(object):
def process_item(self, item, spider):
basePath = "c:\\ft_news\\"
fileFolder = basePath + "\\" + item['category']
filePath = fileFolder+"\\"+item['title']+".txt"
if not os.path.exists(fileFolder): # 判断当前路径是否存在,没有则创建new文件夹
os.makedirs(fileFolder)
file = open(filePath, 'w')
file.write(item['content']) # 写入内容信息
file.close()
print(filePath)
return item4)工程启用功能配置
想让 ScrapydemoPipeline起作用,我们还需要在settings.py中添加开启pipline(开启通道)代码。
# settings.py文件代码
BOT_NAME = 'scrapyDemo'
SPIDER_MODULES = ['scrapyDemo.spiders']
NEWSPIDER_MODULE = 'scrapyDemo.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# 开启pipline
ITEM_PIPELINES = {
'scrapyDemo.pipelines.ScrapydemoPipeline':300
}
# 设置爬取速度,一般为0.25~0.3(即250ms~300ms)间,设置的时间太短,网关防火墙会截获连接认为是恶意访问
DOWNLOAD_DELAY = 0.33、总结
本篇博客记录了scrapy常用的功能,同时还在示例代码中展示了 多级访问共享参数的方式,即
# meta中放入共享参数即可
scrapy.Request(baseUrl+categoryLink,headers=headers,
meta={'category': categoryNames[i],'baseUrl':baseUrl},
callback=self.parseTwise)