hadoop2.x MapReduce过程
首先要编写一个mapreduce程序:自定义一个Mapper类继承hadoop的Mapper、一个Reducer类继承hadoop的hadoop的Reducer类,然后使用Job对象把它们组装起来;可以通过Configuration的set方法对这个任务进行个性化设置(设置全局的话修改core-site.xml和mapred-site.xml),然后通过job.waitForCompletation()方法提交作业。
具体过程:
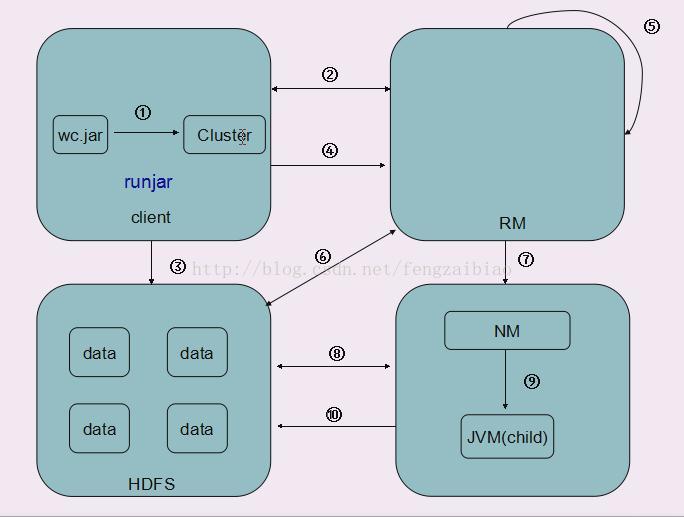
1、在hadoop任意节点上通过 bin/hadoop jar命令开始任务;RunJar进程启动,相当于一个客户端client,RunJar内置有一个Cluster对象,通它过可以向ResourceManager进行rpc通信;
2、客户端向ResourceManager申请作业ID和作业资源文件存放描述信息;包括MapReduce程序打包的jar文件、配置信息和客户端计算的输入划分信息;作业ID可以让作业加入队列,输入划分信息决定了ResourceManager为该作业启动多少个map任务等信息;任务的资源文件存放到HDFS上减轻了ResourceManager的压力;
3、客户端获取作业ID后根据描述信息把作业资源文件上传到HDFS文件系统,程序jar默认会存10份;
4、客户端完成后向ResourceManager提交任务;
5、ResourceManager初始化任务,创建作业对象,把这个任务放到调度器(任务槽)中;
6、当调度器根据自己的算法调到到该作业时,ResourceManager向HDFS查询要处理的数据的详细描述信息,包括分成多少block块,每个block块存放位置,从而确定要启动的Mapper数量,要启动的Reducer的数量是自定义的,MapReduce框架会将map任务安排在含有该任务要处理的数据的节点上;
7、NodeManager向ResourceManager进行rpc心跳机制通信时领取到自己的具体任务描述信息,如运行map任务还是reduce任务,要运行的任务数量,任务jar存放的位置等等;
8、NodeManager根据任务描述信息向HDFS获取任务相关文件;
9、NodeManager在本地启动JVM虚拟机后运行子进程YarnChild,同时一个NodeManager启动MRAppMaster进程,MRAppMaster通过rpc心跳通信机制获取所有任务信息,在YarnChild上运行据具体的MapRreduce任务,Mapper或Reducer,同时监控这些任务的运行情况并直接向ResourceManager汇报;
10、reduce任务完成后结果会输入到HDFS;
map和reduce的原理
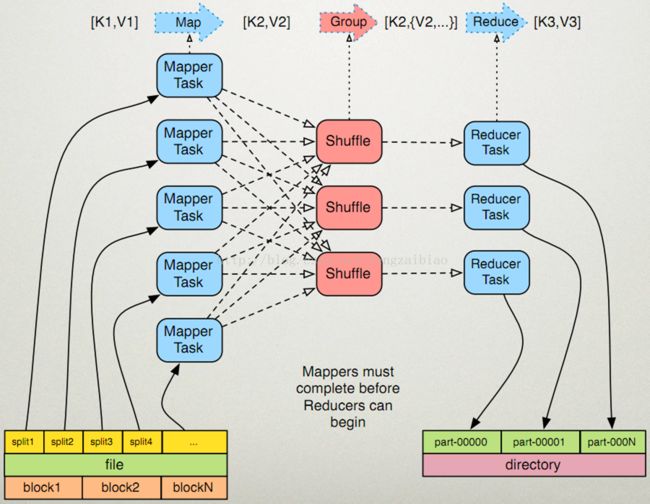 有两个过程,map过程和reduce过程
有两个过程,map过程和reduce过程
map过程:
1、map读取输入文件内容,按行解析成key1、value1键值对,key为每行首字母在文件中的偏移量,value为行的内容,每个键值对调用一次map函数;
2、map根据自己逻辑,对输入的key1、value1处理,转换成新的key2、value2输出;
3、对输出的key2、value2进行分区;
4、对不同分区的数据,按照key2进行排序、分组,相同的key2的value放到一个集合中(中间进行复杂的shuffle过程);
5、分组后的数据进行规约;
reduce过程:
1、对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点;
2、对多个map任务的输出进行Merge(合并、排序),根据reduce自己的任务逻辑对输入的key2、value2处理,转换成新的key3、value3输出;
3、把reduce的输出保存到hdfs上;
shuffle过程:
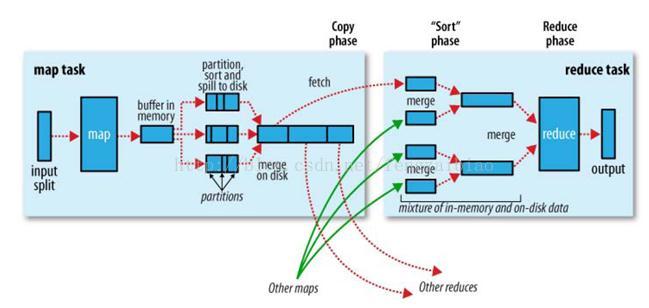 1、一个大文件需要处理,它在在HDFS上是以block块形式存放,每个block默认为128M存3份,运行时每个map任务会处理一个split,如果block大和split相同,有多少个block就有多少个map任务,所以对整个文件处理时会有很多map 任务进行并行计算;
1、一个大文件需要处理,它在在HDFS上是以block块形式存放,每个block默认为128M存3份,运行时每个map任务会处理一个split,如果block大和split相同,有多少个block就有多少个map任务,所以对整个文件处理时会有很多map 任务进行并行计算;
2、每个map任务处理完输入的split后会把结果写入到内存的一个环形缓冲区,写入过程中会进行简单排序,它的默认大小为100M(可以配置mapred-site.xml:mapreduce.task.io.sort.mb),当缓冲区的大小使用超过一定的阀值(mapred-site.xml:mapreduce.map.sort.spill.percent,默认80%),一个后台的线程就会启动把缓冲区中的数据溢写(spill)到本地磁盘中(mapred-site.xml:mapreduce.cluster.local.dir),同Mapper继续时向环形缓冲区中写入数据;
3、数据溢写入到磁盘之前,首先会根据reducer的数量划分成同数量的分区(partition),每个分区中的都数据会有后台线程根据map任务的输出结果key2进行内排序(字典顺序、自然数顺序或自定义顺序compare to),如果有combiner,它会在溢写到磁盘之前排好序的输出上运行(combiner的作用是使map输出更紧凑,写到本地磁盘和传给reducer的数据更少),最后在本地生成分好区且排好序的小文件;
如果map向环形缓冲区写入数据的速度大于向本地写入数据的速度,环形缓冲区被写满,向环形缓冲区写入数据的线程会阻塞直至缓冲区中的内容全部溢写到磁盘后再次启动,到阀值后会向本地磁盘新建一个溢写文件;
4、map任务完成之前,会把本地磁盘溢写的所有文件不停地合并成得到一个结果文件,合并得到的结果文件会根据小溢写文件的分区而分区,每个分区的数据会再次根据key2进行排序,得到的结果文件是分好区且排好序的,可以合并成一个文件的溢写文件数量默认为10(mapred-site.xml:mapreduce.task.io.sort.factor);这个结果文件的分区存在一个映射关系,比如0~1024字节内容为0号分区内容,1025~4096字节内容为1号分区内容等等;
5、reduce任务启动,Reducer个数由mapred-site.xml的mapreduce.job.reduces配置决定,或者初始化job时调用Job.setNumReduceTasks(int);Reducer中的一个线程定期向MRAppMaster询问Mapper输出结果文件位置,mapper结束后会向MRAppMaster汇报信息;从而Reducer得知Mapper状态,得到map结果文件目录;
6、当有一个Mapper结束时,reduce任务进入复制阶段,reduce任务通过http协议(hadoop内置了netty容器)把所有Mapper结果文件的对应的分区数据复制过来,比如,编号为0的reducer复制map结果文件中0号分区数据,1号reduce复制map结果文件中1号分区的数据等等,Reducer可以并行复制Mapper的结果,默认线程数为5(mapred-site.xml:mapreduce.reduce.shuffle.parallelcopies);
所有Reducer复制完成map结果文件后,由于Reducer会失败,NodeManager并没有在第一个map结果文件复制完成后删除它,直到作业完成后MRAppMaster通知NodeManager进行删除;
另外:如果map结果文件相当小,则会被直接复制到reduce NodeManager的内存中(缓冲区大小由mapred-site.xml:mapreduce.reduce.shuffle.input.buffer.percent指定,默认0.7);一旦缓冲区达到reduce的阈值大小0.66(mapred-site.xml:mapreduce.reduce.shuffle.merge.percent)或写入到reduce NodeManager内存中文件个数达到map输出阈值1000(mapred-site.xml:mapreduce.reduce.merge.inmem.threshold),reduce就会把map结果文件合并溢写到本地;
7、复制阶段完成后,Reducer进入Merge阶段,循环地合并map结果文件,维持其顺序排序,合并因子默认为10(mapred-site.xml:mapreduce.task.io.sort.factor),经过不断地Merge后得到一个“最终文件”,可能存储在磁盘也可能存在内存中;
8、“最终文件”输入到reduce进行计算,计算结果输入到HDFS。
初学hadoop,查看了很多朋友的资料,不知道总结的对不对,主要有:
《hadoop权威指南(第二版)中文版》
http://liouwei20051000285.blog.163.com/blog/static/252367420116125223809/
http://langyu.iteye.com/blog/992916