文字编码和Unicode
谈谈Unicode编码,简要解释UCS、UTF、BMP、BOM等名词
这是一篇程序员写给程序员的趣味读物。所谓趣味是指可以比较轻松地了解一些原来不清楚的概念,增进知识,类似于打RPG游戏的升级。整理这篇文章的动机是两个问题:
- 问题一:
-
使用Windows记事本的“另存为”,可以在GBK、Unicode、Unicode big endian和UTF-8这几种编码方式间相互转换。同样是txt文件,Windows是怎样识别编码方式的呢?
我很早前就发现Unicode、Unicode big endian和UTF-8编码的txt文件的开头会多出几个字节,分别是FF、FE(Unicode),FE、FF(Unicode big endian),EF、BB、BF(UTF-8)。但这些标记是基于什么标准呢?
- 问题二:
- 最近在网上看到一个ConvertUTF.c,实现了UTF-32、UTF-16和UTF-8这三种编码方式的相互转换。对于Unicode(UCS2)、GBK、UTF-8这些编码方式,我原来就了解。但这个程序让我有些糊涂,想不起来UTF-16和UCS2有什么关系。
查了查相关资料,总算将这些问题弄清楚了,顺带也了解了一些Unicode的细节。写成一篇文章,送给有过类似疑问的朋友。本文在写作时尽量做到通俗易懂,但要求读者知道什么是字节,什么是十六进制。
0、big endian和little endian
big endian和little endian是CPU处理多字节数的不同方式。例如“汉”字的Unicode编码是6C49。那么写到文件里时,究竟是将6C写在前面,还是将49写在前面?如果将6C写在前面,就是big endian。如果将49写在前面,就是little endian。
“endian”这个词出自《格列佛游记》。小人国的内战就源于吃鸡蛋时是究竟从大头(Big-Endian)敲开还是从小头(Little-Endian)敲开,由此曾发生过六次叛乱,一个皇帝送了命,另一个丢了王位。
我们一般将endian翻译成“字节序”,将big endian和little endian称作“大尾”和“小尾”。
1、字符编码、内码,顺带介绍汉字编码
字符必须编码后才能被计算机处理。计算机使用的缺省编码方式就是计算机的内码。早期的计算机使用7位的ASCII编码,为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5。
GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。
GB2312支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。
从ASCII、GB2312到GBK,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。按照程序员的称呼,GB2312、GBK都属于双字节字符集 (DBCS)。
2000年的GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。从汉字字汇上说,GB18030在GB13000.1的20902个汉字的基础上增加了CJK扩展A的6582个汉字(Unicode码0x3400-0x4db5),一共收录了27484个汉字。
CJK就是中日韩的意思。Unicode为了节省码位,将中日韩三国语言中的文字统一编码。GB13000.1就是ISO/IEC 10646-1的中文版,相当于Unicode 1.1。
GB18030的编码采用单字节、双字节和4字节方案。其中单字节、双字节和GBK是完全兼容的。4字节编码的码位就是收录了CJK扩展A的6582个汉字。 例如:UCS的0x3400在GB18030中的编码应该是8139EF30,UCS的0x3401在GB18030中的编码应该是8139EF31。
微软提供了GB18030的升级包,但这个升级包只是提供了一套支持CJK扩展A的6582个汉字的新字体:新宋体-18030,并不改变内码。Windows 的内码仍然是GBK。
这里还有一些细节:
-
GB2312的原文还是区位码,从区位码到内码,需要在高字节和低字节上分别加上A0。
-
对于任何字符编码,编码单元的顺序是由编码方案指定的,与endian无关。例如GBK的编码单元是字节,用两个字节表示一个汉字。 这两个字节的顺序是固定的,不受CPU字节序的影响。UTF-16的编码单元是word(双字节),word之间的顺序是编码方案指定的,word内部的字节排列才会受到endian的影响。后面还会介绍UTF-16。
-
GB2312的两个字节的最高位都是1。但符合这个条件的码位只有128*128=16384个。所以GBK和GB18030的低字节最高位都可能不是1。不过这不影响DBCS字符流的解析:在读取DBCS字符流时,只要遇到高位为1的字节,就可以将下两个字节作为一个双字节编码,而不用管低字节的高位是什么。
2、Unicode、UCS和UTF
前面提到从ASCII、GB2312、GBK到GB18030的编码方法是向下兼容的。而Unicode只与ASCII兼容(更准确地说,是与ISO-8859-1兼容),与GB码不兼容。例如“汉”字的Unicode编码是6C49,而GB码是BABA。
Unicode也是一种字符编码方法,不过它是由国际组织设计,可以容纳全世界所有语言文字的编码方案。Unicode的学名是"Universal Multiple-Octet Coded Character Set",简称为UCS。UCS可以看作是"Unicode Character Set"的缩写。
根据维基百科全书(http://zh.wikipedia.org/wiki/)的记载:历史上存在两个试图独立设计Unicode的组织,即国际标准化组织(ISO)和一个软件制造商的协会(unicode.org)。ISO开发了ISO 10646项目,Unicode协会开发了Unicode项目。
在1991年前后,双方都认识到世界不需要两个不兼容的字符集。于是它们开始合并双方的工作成果,并为创立一个单一编码表而协同工作。从Unicode2.0开始,Unicode项目采用了与ISO 10646-1相同的字库和字码。
目前两个项目仍都存在,并独立地公布各自的标准。Unicode协会现在的最新版本是2005年的Unicode 4.1.0。ISO的最新标准是ISO 10646-3:2003。
UCS只是规定如何编码,并没有规定如何传输、保存这个编码。例如“汉”字的UCS编码是6C49,我可以用4个ascii数字来传输、保存这个编码;也可以用utf-8编码:3个连续的字节E6 B1 89来表示它。关键在于通信双方都要认可。UTF-8、UTF-7、UTF-16都是被广泛接受的方案。UTF-8的一个特别的好处是它与ISO-8859-1完全兼容。UTF是“UCS Transformation Format”的缩写。
IETF的RFC2781和RFC3629以RFC的一贯风格,清晰、明快又不失严谨地描述了UTF-16和UTF-8的编码方法。我总是记不得IETF是Internet Engineering Task Force的缩写。但IETF负责维护的RFC是Internet上一切规范的基础。
2.1、内码和code page
目前Windows的内核已经支持Unicode字符集,这样在内核上可以支持全世界所有的语言文字。但是由于现有的大量程序和文档都采用了某种特定语言的编码,例如GBK,Windows不可能不支持现有的编码,而全部改用Unicode。
Windows使用代码页(code page)来适应各个国家和地区。code page可以被理解为前面提到的内码。GBK对应的code page是CP936。微软也为GB18030定义了code page:CP54936。
3、UCS-2、UCS-4、BMP
UCS有两种格式:UCS-2和UCS-4。顾名思义,UCS-2就是用两个字节编码,UCS-4就是用4个字节(实际上只用了31位,最高位必须为0)编码。下面让我们做一些简单的数学游戏:
UCS-2有2^16=65536个码位,UCS-4有2^31=2147483648个码位。
UCS-4根据最高位为0的最高字节分成2^7=128个group。每个group再根据次高字节分为256个plane。每个plane根据第3个字节分为256行 (rows),每行包含256个cells。当然同一行的cells只是最后一个字节不同,其余都相同。
group 0的plane 0被称作Basic Multilingual Plane, 即BMP。或者说UCS-4中,高两个字节为0的码位被称作BMP。
将UCS-4的BMP去掉前面的两个零字节就得到了UCS-2。在UCS-2的两个字节前加上两个零字节,就得到了UCS-4的BMP。而目前的UCS-4规范中还没有任何字符被分配在BMP之外。
4、UTF编码
UTF-8就是以8位为单元对UCS进行编码。从UCS-2到UTF-8的编码方式如下:
| UCS-2编码(16进制) | UTF-8 字节流(二进制) |
| 0000 - 007F | 0xxxxxxx |
| 0080 - 07FF | 110xxxxx 10xxxxxx |
| 0800 - FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
例如“汉”字的Unicode编码是6C49。6C49在0800-FFFF之间,所以肯定要用3字节模板了:1110xxxx10xxxxxx10xxxxxx。将6C49写成二进制是:0110 110001 001001, 用这个比特流依次代替模板中的x,得到:111001101011000110001001,即E6 B1 89。
读者可以用记事本测试一下我们的编码是否正确。需要注意,UltraEdit在打开utf-8编码的文本文件时会自动转换为UTF-16,可能产生混淆。你可以在设置中关掉这个选项。更好的工具是Hex Workshop。
UTF-16以16位为单元对UCS进行编码。对于小于0x10000的UCS码,UTF-16编码就等于UCS码对应的16位无符号整数。对于不小于0x10000的UCS码,定义了一个算法。不过由于实际使用的UCS2,或者UCS4的BMP必然小于0x10000,所以就目前而言,可以认为UTF-16和UCS-2基本相同。但UCS-2只是一个编码方案,UTF-16却要用于实际的传输,所以就不得不考虑字节序的问题。
5、UTF的字节序和BOM
UTF-8以字节为编码单元,没有字节序的问题。UTF-16以两个字节为编码单元,在解释一个UTF-16文本前,首先要弄清楚每个编码单元的字节序。例如“奎”的Unicode编码是594E,“乙”的Unicode编码是4E59。如果我们收到UTF-16字节流“594E”,那么这是“奎”还是“乙”?
Unicode规范中推荐的标记字节顺序的方法是BOM。BOM不是“Bill Of Material”的BOM表,而是Byte Order Mark。BOM是一个有点小聪明的想法:
在UCS编码中有一个叫做"ZERO WIDTH NO-BREAK SPACE"的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输字符"ZERO WIDTH NO-BREAK SPACE"。
这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little-Endian的。因此字符"ZERO WIDTH NO-BREAK SPACE"又被称作BOM。
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符"ZERO WIDTH NO-BREAK SPACE"的UTF-8编码是EF BB BF(读者可以用我们前面介绍的编码方法验证一下)。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。
Windows就是使用BOM来标记文本文件的编码方式的。
6、进一步的参考资料
本文主要参考的资料是 "Short overview of ISO-IEC 10646 and Unicode" (http://www.nada.kth.se/i18n/ucs/unicode-iso10646-oview.html)。
我还找了两篇看上去不错的资料,不过因为我开始的疑问都找到了答案,所以就没有看:
- "Understanding Unicode A general introduction to the Unicode Standard" (http://scripts.sil.org/cms/scripts/page.php?site_id=nrsi&item_id=IWS-Chapter04a)
- "Character set encoding basics Understanding character set encodings and legacy encodings" (http://scripts.sil.org/cms/scripts/page.php?site_id=nrsi&item_id=IWS-Chapter03)
我写过UTF-8、UCS-2、GBK相互转换的软件包,包括使用Windows API和不使用Windows API的版本。以后有时间的话,我会整理一下放到我的个人主页上(http://www.fmddlmyy.cn)。
我是想清楚所有问题后才开始写这篇文章的,原以为一会儿就能写好。没想到考虑措辞和查证细节花费了很长时间,竟然从下午1:30写到9:00。希望有读者能从中受益。
附录1 再说说区位码、GB2312、内码和代码页
有的朋友对文章中这句话还有疑问:
“GB2312的原文还是区位码,从区位码到内码,需要在高字节和低字节上分别加上A0。”
我再详细解释一下:
“GB2312的原文”是指国家1980年的一个标准《中华人民共和国国家标准 信息交换用汉字编码字符集 基本集 GB 2312-80》。这个标准用两个数来编码汉字和中文符号。第一个数称为“区”,第二个数称为“位”。所以也称为区位码。1-9区是中文符号,16-55区是一级汉字,56-87区是二级汉字。现在Windows也还有区位输入法,例如输入1601得到“啊”。(这个区位输入法可以自动识别16进制的GB2312和10进制的区位码,也就是说输入B0A1同样会得到“啊”。)
内码是指操作系统内部的字符编码。早期操作系统的内码是与语言相关的。现在的Windows在系统内部支持Unicode,然后用代码页适应各种语言,“内码”的概念就比较模糊了。微软一般将缺省代码页指定的编码说成是内码。
内码这个词汇,并没有什么官方的定义,代码页也只是微软这个公司的叫法。作为程序员,我们只要知道它们是什么东西,没有必要过多地考证这些名词。
Windows中有缺省代码页的概念,即缺省用什么编码来解释字符。例如Windows的记事本打开了一个文本文件,里面的内容是字节流:BA、BA、D7、D6。Windows应该去怎么解释它呢?
是按照Unicode编码解释、还是按照GBK解释、还是按照BIG5解释,还是按照ISO8859-1去解释?如果按GBK去解释,就会得到“汉字”两个字。按照其它编码解释,可能找不到对应的字符,也可能找到错误的字符。所谓“错误”是指与文本作者的本意不符,这时就产生了乱码。
答案是Windows按照当前的缺省代码页去解释文本文件里的字节流。缺省代码页可以通过控制面板的区域选项设置。记事本的另存为中有一项ANSI,其实就是按照缺省代码页的编码方法保存。
Windows的内码是Unicode,它在技术上可以同时支持多个代码页。只要文件能说明自己使用什么编码,用户又安装了对应的代码页,Windows就能正确显示,例如在HTML文件中就可以指定charset。
有的HTML文件作者,特别是英文作者,认为世界上所有人都使用英文,在文件中不指定charset。如果他使用了0x80-0xff之间的字符,中文Windows又按照缺省的GBK去解释,就会出现乱码。这时只要在这个html文件中加上指定charset的语句,例如:
如果原作者使用的代码页和ISO8859-1兼容,就不会出现乱码了。
再说区位码,啊的区位码是1601,写成16进制是0x10,0x01。这和计算机广泛使用的ASCII编码冲突。为了兼容00-7f的ASCII编码,我们在区位码的高、低字节上分别加上A0。这样“啊”的编码就成为B0A1。我们将加过两个A0的编码也称为GB2312编码,虽然GB2312的原文根本没提到这一点。
Windows程序中的字符编码 :
0 Where is Win32 API
Windows程序有用户态和核心态的说法。在32位地址空间中,用户态只能访问0x80000000以下空间(其实只是0x00010000-0x7FFEFFFF),核心态代码可以访问0x80000000以上空间。所有硬件管理都在核心态。用户态代码不能直接使用核心态的任何代码。所谓用户态、核心态其实只是不同的CPU特权级别。在x86 CPU上,用户态处于ring 3,核心态处于ring 0。
从用户态进入核心态的最常用的方法是在寄存器eax填一个功能码,然后执行int 2e。这有点像DOS时代的DOS和BIOS系统调用。在NT架构中这种机制被称作system service。
在核心态提供system service的有两个家伙:ntoskrnl.exe和win32k.sys。ntoskrnl.exe是Windows的大脑,它的上层被称为Executive,下层被称作Kernel。Win32k.sys提供与显示有关的system service。
在用户态一侧,有一个重要的角色叫作ntdll.dll,大多数system service都是它调用的。它封装这些system service,然后提供一个API接口。这个接口被称作native API。 native API的用户是各个子系统(subsystem),包括Win32子系统、OS/2子系统、POSIX子系统。各个子系统为Win32、OS2、POSIX程序提供了运行平台。
ntdll.dll由于提供了平台无关的API接口,所以被看作是NT系统的原生接口,由之得到了“native API”的匪号。其实它的主要工作是将调用传递到核心态。
Win32、OS/2、POSIX,听起来很庞大。其实真正做好的只有Win32子系统。OS2、POSIX都是Console UI,即只有字符界面。提供OS/2子系统,只因为在1988年,NT的主要设计目标就是与OS/2兼容,后来由于Windows 3.0卖得很好,所以设计目标被变更为与Windows兼容。提供POSIX子系统,是为了应付美国政府的一个编号为FIPS 151-2的标准。
Win32子系统的管理员是一个叫作csrss.exe的弟兄,它的全名是:Client/Server Run-Time Subsystem。它刚上任时,本来要分管所有的子系统,但后来POSIX和OS/2都被分别处理了,所以只管了一个Win32。即使这样也很了不起,所有的Win32程序的进程、线程们都要向它登记。
不过Win32程序用得最多的还是Win32子系统的DLL们,最核心的DLL包括:kernel32.dll、User32.dll、Gdi32.dll、Advapi32.dll。这些DLL包装了ntdll.dll的native API。其中Gdi32.dll比较特殊,它与核心态的win32k.sys直接保持联系,以提高NT系统的图形处理能力。Win32子系统的DLL们提供的接口函数在MSDN文档中被详细介绍,它们就是Win32 API。
附录0 Windows的启动
计算机上电后,从BIOS的ROM开始运行。BIOS在做一些初始化后会将硬盘的第一个扇区的数据读入内存,然后将控制权交给它,这段数据被称作Master Boot Record(MBR)。
MBR包含一段启动代码和硬盘的主分区表。这段启动代码扫描主分区表,找到第一个可以启动的分区,然后将这个分区的第一个扇区读入内存并运行。这个扇区被称作引导扇区(boot sector)。
引导扇区的代码具备读文件系统根目录的能力,显然不同的文件系统需要不同的代码。引导扇区会从根目录中读出一个叫作ntldr的文件。顾名思义,这个文件是load NT的主要角色。它的业绩主要包括将CPU从实模式转入保护模式,启动分页机制,处理boot.ini等。
如果boot.ini中有一句:
C:/bootsect.rh="Red Hat Linux"
bootsect.rh的内容是Linux引导扇区,用户又选择了“Red Hat Linux”,ntldr就会将执行Linux的引导扇区,开始Linux的引导。如果用户选择继续使用Windows,ntldr会装载并运行我们前面提到的ntoskrnl.exe。
ntoskrnl.exe会启动会话管理器smss.exe。smss.exe启动csrss.exe和winlogon.exe。smss.exe会永远等待csrss.exe和winlogon.exe返回。如果两者之一异常中止,就会导致系统崩溃。所以病毒们经常以打击csrss.exe为乐。
winlogon.exe负责用户登录,在完成登录后,它会启动注册表HKLM/SOFTWARE/Microsoft/Windows NT/Current Version/Winlogon项下Userinit值指定的程序。该值的缺省数据是userinit.exe。userinit.exe会装载个人设置,让硬盘响个不停,并考验我们的耐性,最后启动注册表同一项下Shell值指定的程序。该值的缺省数据是Explorer.exe。Explorer.exe运行后,我们就会看到熟悉的开始菜单和桌面。
1 Win32 API的A/W函数
要了解Win32子系统的DLL们提供了哪些API,最直接的方法就是用Win32dsm直接查看DLL们的导出表。这时我们会发现Win32 API中带字符串的API一般都有两个版本,例如CreateFileA和CreateFileW。当然也有例外,例如GetProcAddress函数。
A代表ANSI代码页,W是宽字符,即Unicode字符。Windows中的Unicode字符一般指UCS2的UTF16-LE编码。让我们通过几个实例观察A/W版本间的关系。
例1:用WIn32dsm查看gdi32.dll的汇编代码,可以看到TextOutA调用GdiGetCodePage获取当前代码页,再调用MultiByteToWideChar转换输入的字符串,然后调用一个内部函数。而TextOutW直接调用这个内部函数。
例2:用调试器跟踪一个使用了CreateFileA的程序,可以看到:CreateFileA在将输入字符串转换为Unicode后,会调用CreateFileW。假设输入文件名是“测试.txt”,对应的数据就是:“B2 E2 CA D4 2E 74 78 74 00”。
在调试器中可以看到传给CreateFileW的文件名数据是:“4B 6D D5 8B 2E 00 74 00 78 00 74 00 00 00”。 这是"测试.txt"对应的Unicdoe字符串。CreateFileW会接着调用ntdll.dll中的NtCreateFile。顺便看看NtCreateFile的代码:
mov eax, 00000020
lea edx, dword ptr [esp+04]
int 2E
ret 002C
可见这个native API只是简单地调用了核心态提供的0x20号system service。
例3:gdi32.dll中的GetGlyphOutline函数可以获取指定字符的字模。GetGlyphOutlineA和GetGlyphOutlineW函数都会调用同一个内部函数(记作F)。函数F在返回前将通过int 2E调用0x10B1号system service。
GetGlyphOutlineW直接调用函数F。GetGlyphOutlineA在调用函数F前,要依次调用GdiGetCodePage、IsDBCSLeadByteEx和MultiByteToWideChar,将当前代码页的字符编码转换成Unicode编码。
如果我们调用GetGlyphOutlineA时传入“baba”,这是“汉”字的GBK编码,用调试器可以看到传给函数F的字符编码是“6c49”,这是“汉”字的Unicode编码。
从以上例子可见,A版本总会在某处将输入的字符串转换为Unicode字符串,然后和W版本执行相同的代码。在由A/W版本API引出MBCS程序和Unicode程序前,让我们先解释一下Locale和ANSI代码页。
2 Locale和ANSI代码页
2.1 Locale和LCID
Locale是指特定于某个国家或地区的一组设定,包括字符集,数字、货币、时间和日期的格式等。在Windows中,每个Locale可以用一个32位数字表示,记作LCID。在winnt.h中可以看到LCID的组成。它的高16位表示字符的排序方法,一般为0。在它的低16位中,低10位是primary language的ID,高4位指定sublanguage。sublanguage被用来区分同一种语言的不同编码。下面是部分primary language和sublanguage的常数定义:
#define LANG_CHINESE 0x04
#define LANG_ENGLISH 0x09
#define LANG_FRENCH 0x0c
#define LANG_GERMAN 0x07
#define SUBLANG_CHINESE_TRADITIONAL 0x01 // Chinese (Taiwan Region)
#define SUBLANG_CHINESE_SIMPLIFIED 0x02 // Chinese (PR China)
#define SUBLANG_ENGLISH_US 0x01 // English (USA)
#define SUBLANG_ENGLISH_UK 0x02 // English (UK)
好,现在我们可以计算简体中文的LCID了,将sublanguage的常数左移10位,即乘上1024,再加上primary language的常数:2*1024+4=2052,16进制是0804。美国英语是:1*1024+9=1033,16进制是0409。。繁体中文是1*1024+4=1028,16进制是0404。
2.2 代码页
每个Locale都联系着很多信息,可以通过GetLocalInfo函数读取。其中最重要的信息就是字符集了,即Locale对应的语言文字的编码。Windows将字符集称作代码页。
每个Locale可以对应一个ANSI代码页和一个OEM代码页。Win32 API使用ANSI代码页,底层设备使用OEM代码页,两者可以相互映射。
例如English (US)的ANSI和OEM代码页分别为“1252 (ANSI - Latin I)”和“437 (OEM - United States)”。 Chinese (PRC)的ANSI和OEM代码页都是“936 (ANSI/OEM - Simplified Chinese GBK)”。 Chinese (TW)的ANSI和OEM代码页都是“950 (ANSI/OEM - Traditional Chinese Big5)”。
附录1中有一张很长的表。列出了我正在使用的Windows所支持的135个Locale的部分信息,包括 LCID、国家/地区名称、语言名称、语言缩写和对应的ANSI代码页。
2.3 系统Locale、用户Locale,再谈ANSI代码页
在Windows中,通过控制面板可以为系统和用户分别设置Locale。系统Locale决定代码页,用户Locale决定数字、货币、时间和日期的格式。这不是一个好的设计,后面会谈到它带来的问题。
使用GetSystemDefaultLCID函数和GetUserDefaultLCID函数分别得到系统和用户的LCID。有很多材料将这两个函数和另外两个函数混淆:GetSystemDefaultUILanguage和GetUserDefaultUILanguage。
GetSystemDefaultUILanguage和GetUserDefaultUILanguage得到的是您当前使用的Windows版本所带的UI资源的语言。
用户程序缺省使用的代码页是当前系统Locale的ANSI代码页,可以称作ANSI编码,也就是A版本的Win32 API默认的字符编码。对于一个未指定编码方式的文本文件,Windows会按照ANSI编码解释。
2.4 AppLocale
如果一个文本文件采用BIG5编码,系统当前的ANSI代码页是GBK。打开这个文件,就会显示乱码。例如“中文”在BIG5中的编码是A4A4、A4E5,这两个编码在GBK中对应的字符是“いゅ”。这是日文的两个平假名。
在Windows XP平台有一个AppLocale程序,可以以指定的语言运行非Unicode程序。用Win32dsm打开看一看,其实它只是在运行程序前设置了两个环境变量。我们可以用个批处理文件模仿一下:
@ECHO OFF
SET __COMPAT_LAYER=#ApplicationLocale
SET ApplocaleID=0404
start notepad.exe
在简体中文平台,用这个批处理文件启动的记事本可以正确显示BIG5编码的文本文件。用它打开GBK编码的文本文件会怎么样?“中文”会被显示为“笢恅”。设置这两个环境变量会作用于当前进程和其子进程。Windows 2000平台不支持这个方法。
3 MBCS程序和Unicode程序
3.1 与字符编码有关的编译参数
让我们回到Win32 API。我们在程序中使用的Win32 API没有A/W后缀,Windows的头文件会根据编译参数UNICODE将没有后缀的函数名替换为A版本或W版本,例如:
#ifdef UNICODE
#define CreateFile CreateFileW
#else
#define CreateFile CreateFileA
#endif
C RunTime库(CRT)使用_UNICODE和_MBCS来区分三套字符串处理函数,分别用于SBCS、MBCS和Unicdoe字符串。SBCS和MBCS分别指单字节字符串和多字节字符串。例如_tcsclen的3个版本分别为strlen、_mbslen和wcslen ,猜猜以下函数返回几?
strlen("VOIP网关");
_mbslen((unsigned char *)"VOIP网关");
wcslen(L"VOIP网关");
答案是8、6、6。L"ANSI字符串"通知编译器将ANSI字符串转换为Unicode字符串,这是VC++编译器提供的一个小甜点。不过我们应该用宏:_T("ANSI字符串")。_T宏只在我们定义了_UNICODE时才转换。这样同一套代码既可以编译MBCS版本,也可以编译Unicode版本。
MFC用_UNICODE参数区分Unicode版本特有的代码,决定使用什么版本的导入库或静态库。
3.2 Unicode程序、MBCS程序和多语言支持
Unicode程序直接使用Unicode版本的CRT和Win32 API。Unicode程序的运行与当前的ANSI代码页没有关系。MBCS程序的运行依赖于ANSI代码页。如果设计者和使用者使用不同的代码页,就可能出现乱码。微软开发的程序大都是Unicode程序,不管我们怎样变换系统Locale,它们总能正常运行。
使用VCL类库的Delphi程序都是MBCS程序。VCL框架在程序启动会调用GetThreadLocale获取当前用户的LCID,然后在当前目录查找对应的资源文件,命名规则是:程序名+'.'+语言缩写,语言缩写可以参见附录1。在找不到时才会使用EXE文件中的资源。不过如果系统LCID是English(United States),用户LCID是Chinese(PRC),由VCL产生的程序就会出现乱码。读者可以自己分析原因。
为VCL程序做多语言版本。只要用Delphi自带的Resource DLL Wizard再做一个特定语言的资源DLL,原来的程序都不用改。不过很多程序员用其它组件做多语言版本,例如TsiLang 。
MBCS程序虽然也可以做成多语言版本,但它无法在同时显示不同代码页特有的字符,这时就必须使用Unicode程序了。
VS.NET文档中有个多语言资源的例子:SatDLL。它只用Win32 API的例子,却用了VC7项目。我在学习时将它改成了VC6项目,并纠正了它的两个问题:
1、用GetUserDefaultUILanguage读到的是Windows资源版本,不是当前用户设置的代码页。
2、启动时没有使用资源DLL里的菜单。
在我的个人主页(http://www.fmddlmyy.cn)上可以下载修改过的SatDll。这个程序说明了支持多语言资源的基本思路:将不同语言资源放到不同的DLL中,在程序启动时根据当前Locale装载对应的资源DLL。必要时动态切换资源。为了标记不同语言的资源,可以将它们放到不同的目录中,以LCID作为目录名,例如“2052”、“1033”。当然我们也可以用其它方法联系LCID和资源DLL。
MFC程序可以在App类的InitInstance函数中用AfxSetResourceHandle函数设置资源DLL。在Delphi中动态切换资源可以参考Delphi Demo目录RichEdit项目的ReInit.pas。在读取当前设定时,建议用GetSystemDefaultLCID函数,因为系统Locale决定ANSI代码页。
3.4 资源和乱码
通过检查可执行文件,我们可以确定VC和Delphi的资源编译器都以Unicode保存字符资源。在VC环境编辑资源时,我们会指定资源的代码页。编译器根据资源的代码页,将其转换到Unicode。
Unicode程序直接使用以Unicode编码保存的资源。MBCS程序需要将Unicode资源先转换回当前ANSI代码页,然后再使用。如果资源中的Unicode字符串不能映射到当前代码页中的字符,就会出现??。
例如Windows的标准对话框也会出现乱码。假设我们使用简体中文Windows,当前Locale是Chinese (TW),我们的程序是MBCS的,使用标准的打开文件对话框。因为在BIG5中没有“开”这个字,所以“打开”会被显示成“打?”。将程序编译成Unicode版本,就可以避免这个问题。
如果字符不是保存在资源中,而是硬编码在程序中。然后开发者和用户使用不同的代码页,就会导致乱码。假设开发者的Locale是Chinese (PRC),用户的Locale是English (US),程序中硬编码了字符串“文件”。 Chinese (PRC)的ANSI代码页是GBK,“文件”的编码“CE C4 BC FE”。English (US)的ANSI代码页是Latin I,用户按照Latin I编码去解释“CE C4 BC FE”,就会看到“Îļþ”。
回答我前面提过的一个问题:Delphi程序根据用户LCID转换资源中的字符串。如果用户LCID是Chinese (PRC),系统LCID是English (US)。那么资源中的Unicode字符串会被转换为GBK编码,然后按照Latin I显示,这时我们看到的就是类似“Îļþ”的东东,不是??。
既然资源是以Unicode保存的,MBCS程序如果不将其转换到ANSI代码页,而用W版本的函数直接显示,就不会产生乱码。例如MFC程序菜单里的中文,在English (US)的Locale也可以正常显示。不过这取决于各部分代码的具体实现,menu bar控件里的中文在English (US)的Locale会全部显示成??。
进一步的参考资料
本文的第0节和附录0主要参考了《Inside Windows 2000 Third Edition》,国内出过该书的影印版。DDK文档中有大量Windows内核的信息。用Win32dsm和各种调试器查看Windows系统文件可以获得更直接的信息。
关于Window程序的字符编码,最好的参考资料是winnt.h等SDK的包含文件、VCL、MFC、CRT的源文件。我们不需要阅读它们,只要找到自己感兴趣的信息就可以了,用Source Insight可能方便一些。
本文所谈的不是什么万古不迁的道理,只是别的程序员的一些设定,我们因为需要使用他们的程序,所以有必要了解一些细节。研究问题的方法和兴趣永远比问题本身重要,如一句拉丁俗语所说:res, non verba,实质胜于文字。
尾声
“明月虽有圆缺,但毕竟永恒不灭,人生却如过眼烟云,一去不回,真不知计较为何?”
“蛙声虽是短促,但却是万籁中一个活泼的禅机,也可以说万古如斯,永恒不迁,无奈感受到的,能有几人?”
这是一本武侠书中的对话。在时间的长河中,人生和蛙声一样易逝。说到蛙声,我的20个月的小宝宝在喝汤后,略加酝酿,就会紧闭着嘴巴,发出很像蛙鸣的声音。我们会逗他说:“小青蛙又来了”。小家伙益发得意,不管我的抗议,将连汤带油的小下巴亲热地贴在我的身上。
附录1 一些关于LCID的信息
使用EnumSystemLocales函数可以枚举系统支持的LCID。用GetLocaleInfo可以得到ANSI代码页的ID,再通过GetCPInfoEx可以获得代码页的全称。以下是我在中文Windows XP上读到的内容。
| LCID |
国家或地区 |
语言 |
语言缩写 |
ANSI代码页 |
| 1025 |
沙特阿拉伯 |
阿拉伯语(沙特阿拉伯) |
ARA |
1256 (ANSI - 阿拉伯文) |
| 1026 |
保加利亚 |
保加利亚语 |
BGR |
1251 (ANSI - 西里尔文) |
| 1027 |
西班牙 |
加泰隆语 |
CAT |
1252 (ANSI - 拉丁文 I) |
| 1028 |
台湾 |
中文(台湾) |
CHT |
950 (ANSI/OEM - 繁体中文 Big5) |
| 1029 |
捷克共和国 |
捷克语 |
CSY |
1250 (ANSI - 中欧) |
| 1030 |
丹麦 |
丹麦语 |
DAN |
1252 (ANSI - 拉丁文 I) |
| 1031 |
德国 |
德语(德国) |
DEU |
1252 (ANSI - 拉丁文 I) |
| 1032 |
希腊 |
希腊语 |
ELL |
1253 (ANSI - 希腊文) |
| 1033 |
美国 |
英语(美国) |
ENU |
1252 (ANSI - 拉丁文 I) |
| 1034 |
西班牙 |
西班牙语(传统) |
ESP |
1252 (ANSI - 拉丁文 I) |
| 1035 |
芬兰 |
芬兰语 |
FIN |
1252 (ANSI - 拉丁文 I) |
| 1036 |
法国 |
法语(法国) |
FRA |
1252 (ANSI - 拉丁文 I) |
| 1037 |
以色列 |
希伯来语 |
HEB |
1255 (ANSI - 希伯来文) |
| 1038 |
匈牙利 |
匈牙利语 |
HUN |
1250 (ANSI - 中欧) |
| 1039 |
冰岛 |
冰岛语 |
ISL |
1252 (ANSI - 拉丁文 I) |
| 1040 |
意大利 |
意大利语(意大利) |
ITA |
1252 (ANSI - 拉丁文 I) |
| 1041 |
日本 |
日语 |
JPN |
932 (ANSI/OEM - 日文 Shift-JIS) |
| 1042 |
朝鲜 |
朝鲜语 |
KOR |
949 (ANSI/OEM - 韩文) |
| 1043 |
荷兰 |
荷兰语(荷兰) |
NLD |
1252 (ANSI - 拉丁文 I) |
| 1044 |
挪威 |
挪威语(伯克梅尔) |
NOR |
1252 (ANSI - 拉丁文 I) |
| 1045 |
波兰 |
波兰语 |
PLK |
1250 (ANSI - 中欧) |
| 1046 |
巴西 |
葡萄牙语(巴西) |
PTB |
1252 (ANSI - 拉丁文 I) |
| 1048 |
罗马尼亚 |
罗马尼亚语 |
ROM |
1250 (ANSI - 中欧) |
| 1049 |
俄罗斯 |
俄语 |
RUS |
1251 (ANSI - 西里尔文) |
| 1050 |
克罗地亚 |
克罗地亚语 |
HRV |
1250 (ANSI - 中欧) |
| 1051 |
斯洛伐克语 |
斯洛伐克语 |
SKY |
1250 (ANSI - 中欧) |
| 1052 |
阿尔巴尼亚 |
阿尔巴尼亚语 |
SQI |
1250 (ANSI - 中欧) |
| 1053 |
瑞典 |
瑞典语 |
SVE |
1252 (ANSI - 拉丁文 I) |
| 1054 |
泰国 |
泰语 |
THA |
874 (ANSI/OEM - 泰文) |
| 1055 |
土耳其 |
土耳其语 |
TRK |
1254 (ANSI - 土耳其文) |
| 1056 |
巴基斯坦伊斯兰共和国 |
乌都语 |
URD |
1256 (ANSI - 阿拉伯文) |
| 1057 |
印度尼西亚 |
印度尼西亚语 |
IND |
1252 (ANSI - 拉丁文 I) |
| 1058 |
乌克兰 |
乌克兰语 |
UKR |
1251 (ANSI - 西里尔文) |
| 1059 |
比利时 |
比利时语 |
BEL |
1251 (ANSI - 西里尔文) |
| 1060 |
斯洛文尼亚 |
斯洛文尼亚语 |
SLV |
1250 (ANSI - 中欧) |
| 1061 |
爱沙尼亚 |
爱沙尼亚语 |
ETI |
1257 (ANSI - 波罗的海文) |
| 1062 |
拉脱维亚 |
拉脱维亚语 |
LVI |
1257 (ANSI - 波罗的海文) |
| 1063 |
立陶宛 |
立陶宛语 |
LTH |
1257 (ANSI - 波罗的海文) |
| 1065 |
伊朗 |
法斯语 |
FAR |
1256 (ANSI - 阿拉伯文) |
| 1066 |
越南 |
越南语 |
VIT |
1258 (ANSI/OEM - 越南) |
| 1067 |
亚美尼亚 |
亚美尼亚语 |
HYE |
936 (ANSI/OEM - 简体中文 GBK) |
| 1068 |
阿塞拜疆 |
阿塞拜疆语(拉丁文) |
AZE |
1254 (ANSI - 土耳其文) |
| 1069 |
西班牙 |
巴士克语 |
EUQ |
1252 (ANSI - 拉丁文 I) |
| 1071 |
前南斯拉夫马其顿共和国 |
马其顿语(FYROM) |
MKI |
1251 (ANSI - 西里尔文) |
| 1078 |
南非 |
南非语 |
AFK |
1252 (ANSI - 拉丁文 I) |
| 1079 |
格鲁吉亚 |
格鲁吉亚语 |
KAT |
936 (ANSI/OEM - 简体中文 GBK) |
| 1080 |
法罗群岛 |
法罗语 |
FOS |
1252 (ANSI - 拉丁文 I) |
| 1081 |
印度 |
印地语 |
HIN |
936 (ANSI/OEM - 简体中文 GBK) |
| 1086 |
马来西亚 |
马来语(马来西亚) |
MSL |
1252 (ANSI - 拉丁文 I) |
| 1087 |
吉尔吉斯坦 |
哈萨克语 |
KKZ |
1251 (ANSI - 西里尔文) |
| 1088 |
吉尔吉斯斯坦 |
吉尔吉斯语 (西里尔文) |
KYR |
1251 (ANSI - 西里尔文) |
| 1089 |
肯尼亚 |
斯瓦希里语 |
SWK |
1252 (ANSI - 拉丁文 I) |
| 1091 |
乌兹别克斯坦 |
乌兹别克语(拉丁文) |
UZB |
1254 (ANSI - 土耳其文) |
| 1092 |
鞑靼斯坦 |
鞑靼语 |
TTT |
1251 (ANSI - 西里尔文) |
| 1094 |
印度 |
旁遮普语 |
PAN |
936 (ANSI/OEM - 简体中文 GBK) |
| 1095 |
印度 |
古吉拉特语 |
GUJ |
936 (ANSI/OEM - 简体中文 GBK) |
| 1097 |
印度 |
泰米尔语 |
TAM |
936 (ANSI/OEM - 简体中文 GBK) |
| 1098 |
印度 |
泰卢固语 |
TEL |
936 (ANSI/OEM - 简体中文 GBK) |
| 1099 |
印度 |
卡纳拉语 |
KAN |
936 (ANSI/OEM - 简体中文 GBK) |
| 1102 |
印度 |
马拉地语 |
MAR |
936 (ANSI/OEM - 简体中文 GBK) |
| 1103 |
印度 |
梵文 |
SAN |
936 (ANSI/OEM - 简体中文 GBK) |
| 1104 |
蒙古 |
蒙古语(西里尔文) |
MON |
1251 (ANSI - 西里尔文) |
| 1110 |
西班牙 |
加里西亚语 |
GLC |
1252 (ANSI - 拉丁文 I) |
| 1111 |
印度 |
孔卡尼语 |
KNK |
936 (ANSI/OEM - 简体中文 GBK) |
| 1114 |
叙利亚 |
叙利亚语 |
SYR |
936 (ANSI/OEM - 简体中文 GBK) |
| 1125 |
马尔代夫 |
第维埃语 |
DIV |
936 (ANSI/OEM - 简体中文 GBK) |
| 2049 |
伊拉克 |
阿拉伯语(伊拉克) |
ARI |
1256 (ANSI - 阿拉伯文) |
| 2052 |
中华人民共和国 |
中文(中国) |
CHS |
936 (ANSI/OEM - 简体中文 GBK) |
| 2055 |
瑞士 |
德语(瑞士) |
DES |
1252 (ANSI - 拉丁文 I) |
| 2057 |
英国 |
英语(英国) |
ENG |
1252 (ANSI - 拉丁文 I) |
| 2058 |
墨西哥 |
西班牙语(墨西哥) |
ESM |
1252 (ANSI - 拉丁文 I) |
| 2060 |
比利时 |
法语(比利时) |
FRB |
1252 (ANSI - 拉丁文 I) |
| 2064 |
瑞士 |
意大利语(瑞士) |
ITS |
1252 (ANSI - 拉丁文 I) |
| 2067 |
比利时 |
荷兰语(比利时) |
NLB |
1252 (ANSI - 拉丁文 I) |
| 2068 |
挪威 |
挪威语(尼诺斯克) |
NON |
1252 (ANSI - 拉丁文 I) |
| 2070 |
葡萄牙 |
葡萄牙语(葡萄牙) |
PTG |
1252 (ANSI - 拉丁文 I) |
| 2074 |
塞尔维亚 |
塞尔维亚语(拉丁文) |
SRL |
1250 (ANSI - 中欧) |
| 2077 |
芬兰 |
瑞典语(芬兰) |
SVF |
1252 (ANSI - 拉丁文 I) |
| 2092 |
阿塞拜疆 |
阿塞拜疆语(西里尔文) |
AZE |
1251 (ANSI - 西里尔文) |
| 2110 |
文莱达鲁萨兰 |
马来语(文莱达鲁萨兰) |
MSB |
1252 (ANSI - 拉丁文 I) |
| 2115 |
乌兹别克斯坦 |
乌兹别克语(西里尔文) |
UZB |
1251 (ANSI - 西里尔文) |
| 3073 |
埃及 |
阿拉伯语(埃及) |
ARE |
1256 (ANSI - 阿拉伯文) |
| 3076 |
香港特别行政区 |
中文(香港特别行政区) |
ZHH |
950 (ANSI/OEM - 繁体中文 Big5) |
| 3079 |
奥地利 |
德语(奥地利) |
DEA |
1252 (ANSI - 拉丁文 I) |
| 3081 |
澳大利亚 |
英语(澳大利亚) |
ENA |
1252 (ANSI - 拉丁文 I) |
| 3082 |
西班牙 |
西班牙语(国际) |
ESN |
1252 (ANSI - 拉丁文 I) |
| 3084 |
加拿大 |
法语(加拿大) |
FRC |
1252 (ANSI - 拉丁文 I) |
| 3098 |
塞尔维亚 |
塞尔维亚语(西里尔文) |
SRB |
1251 (ANSI - 西里尔文) |
| 4097 |
利比亚 |
阿拉伯语(利比亚) |
ARL |
1256 (ANSI - 阿拉伯文) |
| 4100 |
新加坡 |
中文(新加坡) |
ZHI |
936 (ANSI/OEM - 简体中文 GBK) |
| 4103 |
卢森堡 |
德语(卢森堡) |
DEL |
1252 (ANSI - 拉丁文 I) |
| 4105 |
加拿大 |
英语(加拿大) |
ENC |
1252 (ANSI - 拉丁文 I) |
| 4106 |
危地马拉 |
西班牙语(危地马拉) |
ESG |
1252 (ANSI - 拉丁文 I) |
| 4108 |
瑞士 |
法语(瑞士) |
FRS |
1252 (ANSI - 拉丁文 I) |
| 5121 |
阿尔及利亚 |
阿拉伯语(阿尔及利亚) |
ARG |
1256 (ANSI - 阿拉伯文) |
| 5124 |
澳门特别行政区 |
中文(澳门特别行政区) |
ZHM |
950 (ANSI/OEM - 繁体中文 Big5) |
| 5127 |
列支敦士登 |
德语(列支敦士登) |
DEC |
1252 (ANSI - 拉丁文 I) |
| 5129 |
新西兰 |
英语(新西兰) |
ENZ |
1252 (ANSI - 拉丁文 I) |
| 5130 |
哥斯达黎加 |
西班牙语(哥斯达黎加) |
ESC |
1252 (ANSI - 拉丁文 I) |
| 5132 |
卢森堡 |
法语(卢森堡) |
FRL |
1252 (ANSI - 拉丁文 I) |
| 6145 |
摩洛哥 |
阿拉伯语(摩洛哥) |
ARM |
1256 (ANSI - 阿拉伯文) |
| 6153 |
爱尔兰 |
英语(爱尔兰) |
ENI |
1252 (ANSI - 拉丁文 I) |
| 6154 |
巴拿马 |
西班牙语(巴拿马) |
ESA |
1252 (ANSI - 拉丁文 I) |
| 6156 |
摩纳哥公国 |
法语(摩纳哥) |
FRM |
1252 (ANSI - 拉丁文 I) |
| 7169 |
突尼斯 |
阿拉伯语(突尼斯) |
ART |
1256 (ANSI - 阿拉伯文) |
| 7177 |
南非 |
英语(南非) |
ENS |
1252 (ANSI - 拉丁文 I) |
| 7178 |
多米尼加共和国 |
西班牙语(多米尼加共和国) |
ESD |
1252 (ANSI - 拉丁文 I) |
| 8193 |
阿曼 |
阿拉伯语(阿曼) |
ARO |
1256 (ANSI - 阿拉伯文) |
| 8201 |
牙买加 |
英语(牙买加) |
ENJ |
1252 (ANSI - 拉丁文 I) |
| 8202 |
委内瑞拉 |
西班牙语(委内瑞拉) |
ESV |
1252 (ANSI - 拉丁文 I) |
| 9217 |
也门 |
阿拉伯语(也门) |
ARY |
1256 (ANSI - 阿拉伯文) |
| 9225 |
加勒比海 |
英语(加勒比海) |
ENB |
1252 (ANSI - 拉丁文 I) |
| 9226 |
哥伦比亚 |
西班牙语(哥伦比亚) |
ESO |
1252 (ANSI - 拉丁文 I) |
| 10241 |
叙利亚 |
阿拉伯语(叙利亚) |
ARS |
1256 (ANSI - 阿拉伯文) |
| 10249 |
伯利兹 |
英语(伯利兹) |
ENL |
1252 (ANSI - 拉丁文 I) |
| 10250 |
秘鲁 |
西班牙语(秘鲁) |
ESR |
1252 (ANSI - 拉丁文 I) |
| 11265 |
约旦 |
阿拉伯语(约旦) |
ARJ |
1256 (ANSI - 阿拉伯文) |
| 11273 |
特立尼达和多巴哥 |
英语(特立尼达) |
ENT |
1252 (ANSI - 拉丁文 I) |
| 11274 |
阿根廷 |
西班牙语(阿根廷) |
ESS |
1252 (ANSI - 拉丁文 I) |
| 12289 |
黎巴嫩 |
阿拉伯语(黎巴嫩) |
ARB |
1256 (ANSI - 阿拉伯文) |
| 12297 |
津巴布韦 |
英语(津巴布韦) |
ENW |
1252 (ANSI - 拉丁文 I) |
| 12298 |
厄瓜多尔 |
西班牙语(厄瓜多尔) |
ESF |
1252 (ANSI - 拉丁文 I) |
| 13313 |
科威特 |
阿拉伯语(科威特) |
ARK |
1256 (ANSI - 阿拉伯文) |
| 13321 |
菲律宾共和国 |
英语(菲律宾) |
ENP |
1252 (ANSI - 拉丁文 I) |
| 13322 |
智利 |
西班牙语(智利) |
ESL |
1252 (ANSI - 拉丁文 I) |
| 14337 |
阿联酋 |
阿拉伯语(阿联酋) |
ARU |
1256 (ANSI - 阿拉伯文) |
| 14346 |
乌拉圭 |
西班牙语(乌拉圭) |
ESY |
1252 (ANSI - 拉丁文 I) |
| 15361 |
巴林 |
阿拉伯语(巴林) |
ARH |
1256 (ANSI - 阿拉伯文) |
| 15370 |
巴拉圭 |
西班牙语(巴拉圭) |
ESZ |
1252 (ANSI - 拉丁文 I) |
| 16385 |
卡塔尔 |
阿拉伯语(卡塔尔) |
ARQ |
1256 (ANSI - 阿拉伯文) |
| 16394 |
玻利维亚 |
西班牙语(玻利维亚) |
ESB |
1252 (ANSI - 拉丁文 I) |
| 17418 |
萨尔瓦多 |
西班牙语(萨尔瓦多) |
ESE |
1252 (ANSI - 拉丁文 I) |
| 18442 |
洪都拉斯 |
西班牙语(洪都拉斯) |
ESH |
1252 (ANSI - 拉丁文 I) |
| 19466 |
尼加拉瓜 |
西班牙语(尼加拉瓜) |
ESI |
1252 (ANSI - 拉丁文 I) |
| 20490 |
波多黎各(美) |
西班牙语(波多黎各(美)) |
ESU |
1252 (ANSI - 拉丁文 I) |
LCID取决于语言,在表中列出国家名只是为了增加趣味性。例如可以看到以色列还在使用古老的希伯来语。“希伯来语”的法文是hébreu,这个单词还有一个意思,就是“不能理解的东西”。
1 文字的显示
1.1 发生了什么?
我们首先以Windows为例来看看文字显示过程中发生了什么。用记事本打开一个文本文件,可以看到文件包含的文字:
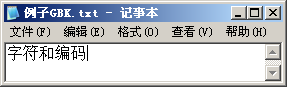
如果我们用UltraEdit或Hex Workshop查看这个文件的16进制数据,可以看到:

我们看到:文件“例子GBK.txt”有10个字节,依次是“D7 D6 B7 FB BA CD B1 E0 C2 EB”,这就是记事本从文件中读到的内容。记事本是用来打开文本文件的,所以它会调用Windows的文本显示函数将读到的数据作为文本显示。Windows首先将文本数据转换到它内部使用的编码格式:Unicode,然后按照文本的Unicode去字体文件中查找字体图像,最后将图像显示到窗口上。总结一下前面的分析,文字的显示应该是这样的:
- 步骤1:文字首先以某种编码保存在文件中。
- 步骤2:Windows将文件中的文字编码映射到Unicode。
- 步骤3:Windows按照Unicode在字体文件中查找字体图像,画到窗口上。
如果上述3个步骤中任何一步发生了错误,文字就不能被正确显示,例如:
-
错误1:如果弄错了编码,例如将Big5编码的文字当作GBK编码,就会出现乱码。

-
错误2:如果从特定编码到Unicode的映射发生错误,例如文本数据中出现该编码方案未定义的字符,Windows就会使用缺省字符,通常是?。
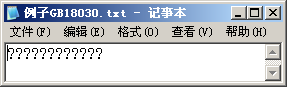
- 如果当前字体不支持要显示的字符,Windows就会显示字体文件中的缺省图像:空白或方格。
在Unicode被广泛使用前,有多少种语言、文字,就可能有多少种文字编码方案。一种文字也可能有多种编码方案。那么我们怎么确定文本数据采用了什么编码?
1.2 采用了哪种编码?
按照惯例,文本文件中的数据都是文本编码,那么它怎么表明自己的编码格式?在记事本的“打开”对话框上:
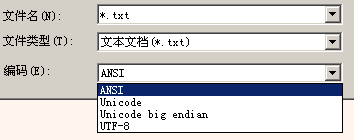
我们可以看到记事本支持4种编码格式:ANSI、Unicode、Unicode big endian、UTF-8。如果读者看过《谈谈Unicode编码》,对Unicode、Unicode big endian、UTF-8应该不会陌生,其实它们更准确的名称应该是UTF-16LE(Little Endian)、UTF-16BE(Big Endian)和UTF-8,它们是基于Unicode的不同编码方案。
在《谈谈Unicode编码》中介绍过,Windows通过在文本文件开头增加一些特殊字节(BOM)来区分上述3种编码,并将没有BOM的文本数据按照ANSI代码页处理。那么什么是代码页,什么是ANSI代码页?
2 代码页和字符集
2.1 Windows的代码页
2.1.1 代码页
代码页(Code Page)是个古老的专业术语,据说是IBM公司首先使用的。代码页和字符集的含义基本相同,代码页规定了适用于特定地区的字符集合,和这些字符的编码。可以将代码页理解为字符和字节数据的映射表。
Windows为自己支持的代码页都编了一个号码。例如代码页936就是简体中文 GBK,代码页950就是繁体中文 Big5。代码页的概念比较简单,就是一个字符编码方案。但要说清楚Windows的ANSI代码页,就要从Windows的区域(Locale)说起了。
2.1.2 区域和ANSI代码页
微软为了适应世界上不同地区用户的文化背景和生活习惯,在Windows中设计了区域(Locale)设置的功能。Local是指特定于某个国家或地区的一组设定,包括代码页,数字、货币、时间和日期的格式等。在Windows内部,其实有两个Locale设置:系统Locale和用户Locale。系统Locale决定代码页,用户Locale决定数字、货币、时间和日期的格式。我们可以在控制面板的“区域和语言选项”中设置系统Locale和用户Locale:
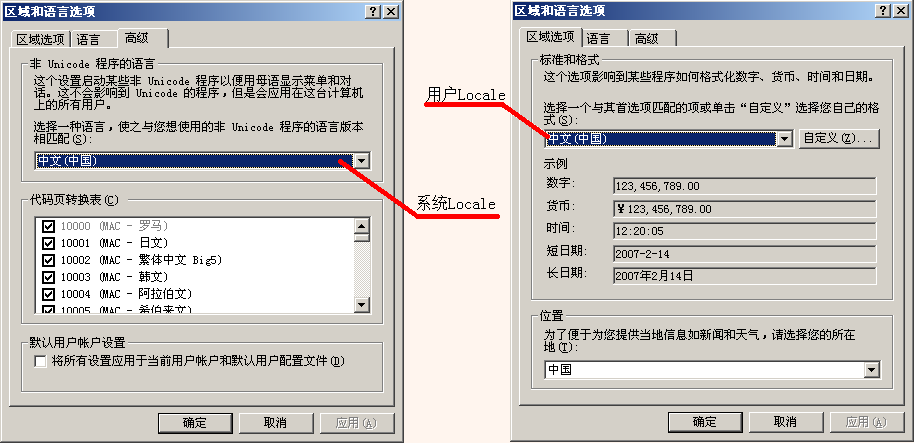
每个Locale都有一个对应的代码页。Locale和代码页的对应关系,大家可以参阅我的另一篇文章《谈谈Windows程序中的字符编码》的附录1。系统Locale对应的代码页被作为Windows的默认代码页。在没有文本编码信息时,Windows按照默认代码页的编码方案解释文本数据。这个默认代码页通常被称作ANSI代码页(ACP)。
ANSI代码页还有一层意思,就是微软自己定义的代码页。在历史上,IBM的个人计算机和微软公司的操作系统曾经是PC的标准配置。微软公司将IBM公司定义的代码页称作OEM代码页,在IBM公司的代码页基础上作了些增补后,作为自己的代码页,并冠以ANSI的字样。我们在“区域和语言选项”高级页面的代码页转换表中看到的包含ANSI字样的代码页都是微软自己定义的代码页。例如:
- 874 (ANSI/OEM - 泰文)
- 932 (ANSI/OEM - 日文 Shift-JIS)
- 936 (ANSI/OEM - 简体中文 GBK)
- 949 (ANSI/OEM - 韩文)
- 950 (ANSI/OEM - 繁体中文 Big5)
- 1250 (ANSI - 中欧)
- 1251 (ANSI - 西里尔文)
- 1252 (ANSI - 拉丁文 I)
- 1253 (ANSI - 希腊文)
- 1254 (ANSI - 土耳其文)
- 1255 (ANSI - 希伯来文)
- 1256 (ANSI - 阿拉伯文)
- 1257 (ANSI - 波罗的海文)
- 1258 (ANSI/OEM - 越南)
在UniToy中,我们可以按照代码页编码顺序查看这些代码页的字符和编码:
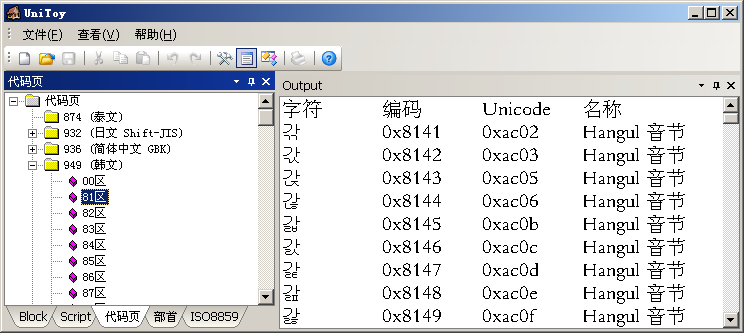
我们不能直接设置ANSI代码页,只能通过选择系统Locale,间接改变当前的ANSI代码页。微软定义的Locale只使用自己定义的代码页。所以,我们虽然可以通过“区域和语言选项”中的代码页转换表安装很多代码页,但只能将微软的代码页作为系统默认代码页。
2.1.3 代码页转换表
在Windows 2000以后,Windows统一采用UTF-16作为内部字符编码。现在,安装一个代码页就是安装一张代码页转换表。通过代码页转换表,Windows既可以将代码页的编码转换到UTF-16,也可以将UTF-16转换到代码页的编码。代码页转换表的具体实现可以是一个以nls为后缀的数据文件,也可以是一个提供转换函数的动态链接库。有的代码页是不需要安装的。例如:Windows将UTF-7和UTF-8分别作为代码页65000和代码页65001。UTF-7、UTF-8和UTF-16都是基于Unicode的编码方案。它们之间可以通过简单的算法直接转换,不需要安装代码页转换表。
在安装过一个代码页后,Windows就知道怎样将该代码页的文本转换到Unicode文本,也知道怎样将Unicode文本转换成该代码页的文本。例如:UniToy有导入和导出功能。所谓导入功能就是将任一代码页的文本文件转换到Unicode文本;导出功能就是将Unicode文本转换到任一指定的代码页。这里所说的代码页就是指系统已安装的代码页:
其实,如果全世界人民在计算机刚发明时就统一采用Unicode作为字符编码,那么代码页就没有存在的必要了。可惜在Unicode被发明前,世界各国人民都发明并使用了各种字符编码方案。所以,Windows必须通过代码页支持已经被广泛使用的字符编码。从这种意义看,代码页主要是为了兼容现有的数据、程序和习惯而存在的。
2.1.4 SBCS、DBCS和MBCS
SBCS、DBCS和MBCS分别是单字节字符集、双字节字符集和多字节字符集的缩写。SBCS、DBCS和MBCS的最大编码长度分别是1字节、两字节和大于两字节(例如4或5字节)。例如:代码页1252 (ANSI-拉丁文 I)是单字节字符集;代码页936 (ANSI/OEM-简体中文 GBK)是双字节字符集;代码页54936 (GB18030 简体中文)是多字节字符集。
单字节字符集中的字符都用一个字节表示。显然,SBCS最多只能容纳256个字符。
双字节字符集的字符用一个或两个字节表示。那么我们从文本数据中读到一个字节时,怎么判断它是单字节字符,还是双字节字符的首字符?答案是通过字节所处范围来判断。例如:在GBK编码中,单字节字符的范围是0x00-0x80,双字节字符首字节的范围是0x81到0xFE。我们顺序读取字节数据,如果读到的字节在0x81到0xFE内,那么这个字节就是双字节字符的首字节。GBK定义双字节字符的尾字节范围是0x40到0x7E和0x80到0xFE。
GB18030是多字节字符集,它的字符可以用一个、两个或四个字节表示。这时我们又如何判断一个字节是属于单字节字符,双字节字符,还是四字节字符?GB18030与GBK是兼容的,它利用了GBK双字节字符尾字节的未使用码位。GB18030的四字节字符的第一字节的范围也是0x81到0xFE,第二字节的范围是0x30-0x39。通过第二字节所处范围就可以区分双字节字符和四字节字符。GB18030定义四字节字符的第三字节范围是0x81到0xFE,第四字节范围是0x30-0x39。
2.2 代码页实例
2.2.1 实例一:GB18030代码页
1.1节的“错误2”中演示了一个全被显示成'?'的文件。这个文件的数据是:
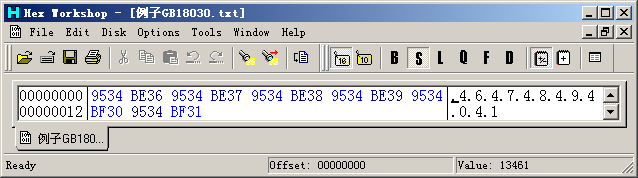
其实,这是一个包含了6个四字节字符的GB18030编码的文件。记事本按照GBK显示这些数据,而GB18030的四字节字符编码在GBK中是未定义的。Windows根据首字节范围判断出12个双字节字符,然后因为找不到匹配的转换而将其映射到默认字符'?'。使用UniToy按照GB18030代码页导入这个文件,就可以看到:
这个GB18030编码的文件是用UniToy创建的,编辑Unicode文本,然后导出到GB18030编码格式。
2.2.2 实例二:GBK和Big5的转换
综合使用UniToy的导入、导出功能就可以在任意两个代码页之间转换文本。其实,由于各代码页支持的字符范围不同,我们一般不会直接在代码页间转换文本。例如将以下GBK编码的文本:
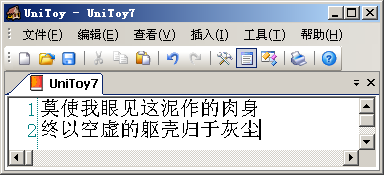
直接转换到Big5编码,就会看到:
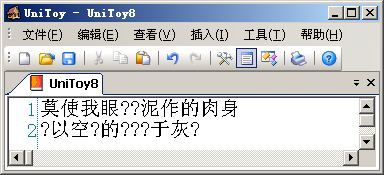
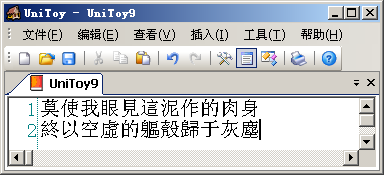
变成'?'的字符都是Big5编码不支持的简化字。在从Unicode转换到Big5编码时,由于Big5编码不支持这些字符,Windows就用默认字符'?'代替。在UniToy中,我们可以先将简体字转换到繁体字,然后再导出到Big5编码,就可以正常显示:
同理,将Big5编码的文本转换到GBK编码的步骤应该是:
- 将Big5编码的文本导入到Unicode文本;
- 将繁体的Unicode文本转换简体的Unicode文本;
- 将简体的Unicode文本导出到GBK文本。
2.3 互联网的字符集
2.3.1 字符集
互联网上的信息缤纷多彩,但文本依然是最重要的信息载体。html文件通过标记表明自己使用的字符集。例如:
或者:
那么我们可以使用哪些字符集(charset)呢?在IETF(互联网工程任务组)的网页上维护着一份可以在互联网上使用的字符集的清单:CHARACTER SETS。如果有新的字符集被登记,IETF会更新这份文档。
简单浏览一下,2006年12月7日的版本列出了253个字符集。其中也包括微软的CP1250 ~ CP1258,在这里它们不会被称作什么ANSI代码页,而是被简单地称作windows-1250、windows-1251等。其实在Unicode被广泛使用前,除了中日韩等大字符集,世界上,特别是西方使用最广泛的字符集应该是ISO 8859系列字符集。
2.3.2 ISO 8859系列字符集
ISO 8859系列字符集是欧洲计算机制造商协会(ECMA)在上世纪80年代中期设计,并被国际标准化(ISO)组织采纳为国际标准。ISO 8859系列字符集目前有15个字符集,包括:
- ISO 8859-1 大部分的西欧语系,例如英文、法文、西班牙文和德文等(Latin-1)
- ISO 8859-2 大部分的中欧和东欧语系,例如捷克文、波兰文和匈牙利文等(Latin-2)
- ISO 8859-3 欧洲东南部和其它各种文字(Latin-3)
- ISO 8859-4 斯堪的那维亚和波罗的海语系(Latin-4)
- ISO 8859-5 拉丁文与斯拉夫文(俄文、保加利亚文等)
- ISO 8859-6 拉丁文与阿拉伯文
- ISO 8859-7 拉丁文与希腊文
- ISO 8859-8 拉丁文与希伯来文
- ISO 8859-9 为土耳其文修正的Latin-1(Latin-5)
- ISO 8859-10 拉普人、北欧与爱斯基摩人的文字(Latin-6)
- ISO 8859-11 拉丁文与泰文
- ISO 8859-13 波罗的海周边语系,例如拉脱维亚文等(Latin-7)
- ISO 8859-14 凯尔特文,例如盖尔文、威尔士文等(Latin-8)
- ISO 8859-15 改进的Latin-1,增加遗漏的法文、芬兰文字符和欧元符号(Latin-9)
- ISO 8859-16 罗马尼亚文(Latin-10)
其中缺少的编号12据说是为了预留给天城体梵文字母(Deva-nagari)的。印地文和尼泊尔文都使用了这种在七世纪形成的字母表。由于印度定义了自己的编码ISCII(Indian Script Code for Information Interchange),所以这个编号就未被使用。ISO 8859系列字符集都是单字节字符集,即只使用0x00-0xFF对字符编码。
大家都知道ASCII吧,那么大家知道ANSI X3.4和ISO 646吗?在1968年发布的ANSI X3.4和1972年发布的ISO 646就是ASCII编码,只不过是不同组织发布的。绝大多数字符集都与ASCII编码保持兼容,ISO 8859系列字符集也不例外,它们的0x00-0x7f都与ASCII码保持一致,各字符集的不同之处在于如何利用0x80-0xff的码位。使用UniToy可以查看ISO 8859系列所有字符集的编码,例如:

3 字符编码模型
程序员经常会面对复杂的问题,而降低复杂性的最简单的方法就是分而治之。Peter Constable在他的文章"Character set encoding basics Understanding character set encodings and legacy encodings"中描述了字符编码的四层模型。我觉得这种说法确实可以更清晰地展现字符编码中发生的事情,所以在这里也介绍一下。
3.1 字符的范围(Abstract character repertoire)
设计字符编码的第一层就是确定字符的范围,即要支持哪些字符。有些编码方案的字符范围是固定的,例如ASCII、ISO 8859 系列。有些编码方案的字符范围是开放的,例如Unicode的字符范围就是世界上所有的字符。
3.2 用数字表示字符(Coded character set)
设计字符编码的第二层是将字符和数字对应起来。可以将这个层次理解成数学家(即从数学角度)看到的字符编码。数学家看到的字符编码是一个正整数。例如在Unicode中:汉字“字”对应的数字是23383。汉字“![]() ”对应的数字是134192。
”对应的数字是134192。
在写html文件时,可以通过输入"字"来插入字符“字”。不过在设计字符编码时,我们还是习惯用16进制表示数字。即将23383写成0x5BD7,将134192写成0x20C30。
3.3 用基本数据类型表示字符(Character encoding form)
设计字符编码的第三层是用编程语言中的基本数据类型来表示字符。可以将这个层次理解成程序员看到的字符编码。在Unicode中,我们有很多方式将数字23383表示成程序中的数据,包括:UTF-8、UTF-16、UTF-32。UTF是“UCS Transformation Format”的缩写,可以翻译成Unicode字符集转换格式,即怎样将Unicode定义的数字转换成程序数据。例如,“汉字”对应的数字是0x6c49和0x5b57,而编码的程序数据是:
BYTE data_utf8[]={0xE6,0xB1,0x89,0xE5,0xAD,0x97}; // UTF-8编码
WORD data_utf16[]={0x6c49,0x5b57}; // UTF-16编码
DWORD data_utf32[]={0x6c49,0x5b57}; // UTF-32编码
这里用BYTE、WORD、DWORD分别表示无符号8位整数,无符号16位整数和无符号32位整数。UTF-8、UTF-16、UTF-32分别以BYTE、WORD、DWORD作为编码单位。
“汉字”的UTF-8编码需要6个字节。“汉字”的UTF-16编码需要两个WORD,大小是4个字节。“汉字”的UTF-32编码需要两个DWORD,大小是8个字节。4.2节会介绍将数字映射到UTF编码的规则。
3.4 作为字节流的字符(Character encoding scheme)
字符编码的第四层是计算机看到的字符,即在文件或内存中的字节流。例如,“字”的UTF-32编码是0x5b57,如果用little endian表示,字节流是“57 5b 00 00”。如果用big endian表示,字节流是“00 00 5b 57”。
字符编码的第三层规定了一个字符由哪些编码单位按什么顺序表示。字符编码的第四层在第三层的基础上又考虑了编码单位内部的字节序。UTF-8的编码单位是字节,不受字节序的影响。UTF-16、UTF-32根据字节序的不同,又衍生出UTF-16LE、UTF-16BE、UTF-32LE、UTF-32BE四种编码方案。LE和BE分别是Little Endian和Big Endian的缩写。
3.5 小结
通过四层模型,我们又把字符编码中发生的这些事情梳理了一遍。其实大多数代码页都不需要完整的四层模型,例如GB18030以字节为编码单位,直接规定了字节序列和字符的映射关系,跳过了第二层,也不需要第四层。
4 再谈Unicode
Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。Unicode用数字0-0x10FFFF来映射这些字符,最多可以容纳1114112个字符,或者说有1114112个码位。码位就是可以分配给字符的数字。UTF-8、UTF-16、UTF-32都是将数字转换到程序数据的编码方案。
Unicode字符集可以简写为UCS(Unicode Character Set)。早期的Unicode标准有UCS-2、UCS-4的说法。UCS-2用两个字节编码,UCS-4用4个字节编码。UCS-4根据最高位为0的最高字节分成2^7=128个group。每个group再根据次高字节分为256个平面(plane)。每个平面根据第3个字节分为256行 (row),每行有256个码位(cell)。group 0的平面0被称作BMP(Basic Multilingual Plane)。将UCS-4的BMP去掉前面的两个零字节就得到了UCS-2。
Unicode标准计划使用group 0 的17个平面: 从BMP(平面0)到平面16,即数字0-0x10FFFF。《谈谈Unicode编码》主要介绍了BMP的编码,本文将介绍完整的Unicode编码,并从多个角度浏览Unicode。本文的介绍基于Unicode 5.0.0版本。
4.1 浏览Unicode
先看一些数字:每个平面有2^16=65536个码位。Unicode计划使用了17个平面,一共有17*65536=1114112个码位。其实,现在已定义的码位只有238605个,分布在平面0、平面1、平面2、平面14、平面15、平面16。其中平面15和平面16上只是定义了两个各占65534个码位的专用区(Private Use Area),分别是0xF0000-0xFFFFD和0x100000-0x10FFFD。所谓专用区,就是保留给大家放自定义字符的区域,可以简写为PUA。
平面0也有一个专用区:0xE000-0xF8FF,有6400个码位。平面0的0xD800-0xDFFF,共2048个码位,是一个被称作代理区(Surrogate)的特殊区域。它的用途将在4.2节介绍。
238605-65534*2-6400-2408=99089。余下的99089个已定义码位分布在平面0、平面1、平面2和平面14上,它们对应着Unicode目前定义的99089个字符,其中包括71226个汉字。平面0、平面1、平面2和平面14上分别定义了52080、3419、43253和337个字符。平面2的43253个字符都是汉字。平面0上定义了27973个汉字。
在更深入地了解Unicode字符前,我们先了解一下UCD。
4.1.1 什么是UCD
UCD是Unicode字符数据库(Unicode Character Database)的缩写。UCD由一些描述Unicode字符属性和内部关系的纯文本或html文件组成。大家可以在Unicode组织的网站看到UCD的最新版本。
UCD中的文本文件大都是适合于程序分析的Unicode相关数据。其中的html文件解释了数据库的组织,数据的格式和含义。UCD中最庞大的文件无疑就是描述汉字属性的文件Unihan.txt。在UCD 5.0,0中,Unihan.txt文件大小有28,221K字节。Unihan.txt中包含了很多有参考价值的索引,例如汉字部首、笔划、拼音、使用频度、四角号码排序等。这些索引都是基于一些比较权威的辞典,但大多数索引只能检索部分汉字。
我介绍UCD的目的主要是为了使用其中的两个概念:Block和Script。
4.1.2 Block
UCD中的Blocks.txt将Unicode的码位分割成一些连续的Block,并描述了每个Block的用途:
| 开始码位 | 结束码位 | Block名称(英文) | Block名称(中文) |
| 0000 | 007F | Basic Latin | 基本拉丁字母 |
| 0080 | 00FF | Latin-1 Supplement | 拉丁字母补充-1 |
| 0100 | 017F | Latin Extended-A | 拉丁字母扩充-A |
| 0180 | 024F | Latin Extended-B | 拉丁字母扩充-B |
| 0250 | 02AF | IPA Extensions | 国际音标扩充 |
| 02B0 | 02FF | Spacing Modifier Letters | 进格修饰字符 |
| 0300 | 036F | Combining Diacritical Marks | 组合附加符号 |
| 0370 | 03FF | Greek and Coptic | 希腊文和哥普特文 |
| 0400 | 04FF | Cyrillic | 西里尔文 |
| 0500 | 052F | Cyrillic Supplement | 西里尔文补充 |
| 0530 | 058F | Armenian | 亚美尼亚文 |
| 0590 | 05FF | Hebrew | 希伯来文 |
| 0600 | 06FF | Arabic | 基本阿拉伯文 |
| 0700 | 074F | Syriac | 叙利亚文 |
| 0750 | 077F | Arabic Supplement | 阿拉伯文补充 |
| 0780 | 07BF | Thaana | 塔纳文 |
| 07C0 | 07FF | NKo | N'Ko字母表 |
| 0900 | 097F | Devanagari | 天成文书(梵文) |
| 0980 | 09FF | Bengali | 孟加拉文 |
| 0A00 | 0A7F | Gurmukhi | 锡克教文 |
| 0A80 | 0AFF | Gujarati | 古吉拉特文 |
| 0B00 | 0B7F | Oriya | 奥里亚文 |
| 0B80 | 0BFF | Tamil | 泰米尔文 |
| 0C00 | 0C7F | Telugu | 泰卢固文 |
| 0C80 | 0CFF | Kannada | 卡纳达文 |
| 0D00 | 0D7F | Malayalam | 德拉维族文 |
| 0D80 | 0DFF | Sinhala | 僧伽罗文 |
| 0E00 | 0E7F | Thai | 泰文 |
| 0E80 | 0EFF | Lao | 老挝文 |
| 0F00 | 0FFF | Tibetan | 藏文 |
| 1000 | 109F | Myanmar | 缅甸文 |
| 10A0 | 10FF | Georgian | 格鲁吉亚文 |
| 1100 | 11FF | Hangul Jamo | 朝鲜文 |
| 1200 | 137F | Ethiopic | 埃塞俄比亚文 |
| 1380 | 139F | Ethiopic Supplement | 埃塞俄比亚文补充 |
| 13A0 | 13FF | Cherokee | 切罗基文 |
| 1400 | 167F | Unified Canadian Aboriginal Syllabics | 加拿大印第安方言 |
| 1680 | 169F | Ogham | 欧甘文 |
| 16A0 | 16FF | Runic | 北欧古字 |
| 1700 | 171F | Tagalog | 塔加路文 |
| 1720 | 173F | Hanunoo | 哈努诺文 |
| 1740 | 175F | Buhid | 布迪文 |
| 1760 | 177F | Tagbanwa | Tagbanwa文 |
| 1780 | 17FF | Khmer | 高棉文 |
| 1800 | 18AF | Mongolian | 蒙古文 |
| 1900 | 194F | Limbu | 林布文 |
| 1950 | 197F | Tai Le | 德宏傣文 |
| 1980 | 19DF | New Tai Lue | 新傣文 |
| 19E0 | 19FF | Khmer Symbols | 高棉文 |
| 1A00 | 1A1F | Buginese | 布吉文 |
| 1B00 | 1B7F | Balinese | 巴厘文 |
| 1D00 | 1D7F | Phonetic Extensions | 拉丁字母音标扩充 |
| 1D80 | 1DBF | Phonetic Extensions Supplement | 拉丁字母音标扩充增补 |
| 1DC0 | 1DFF | Combining Diacritical Marks Supplement | 组合附加符号补充 |
| 1E00 | 1EFF | Latin Extended Additional | 拉丁字母扩充附加 |
| 1F00 | 1FFF | Greek Extended | 希腊文扩充 |
| 2000 | 206F | General Punctuation | 一般标点符号 |
| 2070 | 209F | Superscripts and Subscripts | 上标和下标 |
| 20A0 | 20CF | Currency Symbols | 货币符号 |
| 20D0 | 20FF | Combining Diacritical Marks for Symbols | 符号用组合附加符号 |
| 2100 | 214F | Letterlike Symbols | 似字母符号 |
| 2150 | 218F | Number Forms | 数字形式 |
| 2190 | 21FF | Arrows | 箭头符号 |
| 2200 | 22FF | Mathematical Operators | 数学运算符号 |
| 2300 | 23FF | Miscellaneous Technical | 零杂技术用符号 |
| 2400 | 243F | Control Pictures | 控制图符 |
| 2440 | 245F | Optical Character Recognition | 光学字符识别 |
| 2460 | 24FF | Enclosed Alphanumerics | 带括号的字母数字 |
| 2500 | 257F | Box Drawing | 制表符 |
| 2580 | 259F | Block Elements | 方块元素 |
| 25A0 | 25FF | Geometric Shapes | 几何形状 |
| 2600 | 26FF | Miscellaneous Symbols | 零杂符号 |
| 2700 | 27BF | Dingbats | 杂锦字型 |
| 27C0 | 27EF | Miscellaneous Mathematical Symbols-A | 零杂数学符号-A |
| 27F0 | 27FF | Supplemental Arrows-A | 箭头符号补充-A |
| 2800 | 28FF | Braille Patterns | 盲文 |
| 2900 | 297F | Supplemental Arrows-B | 箭头符号补充-B |
| 2980 | 29FF | Miscellaneous Mathematical Symbols-B | 零杂数学符号-B |
| 2A00 | 2AFF | Supplemental Mathematical Operators | 数学运算符号 |
| 2B00 | 2BFF | Miscellaneous Symbols and Arrows | 零杂符号和箭头 |
| 2C00 | 2C5F | Glagolitic | 格拉哥里字母表 |
| 2C60 | 2C7F | Latin Extended-C | 拉丁字母扩充-C |
| 2C80 | 2CFF | Coptic | 科普特文 |
| 2D00 | 2D2F | Georgian Supplement | 格鲁吉亚文补充 |
| 2D30 | 2D7F | Tifinagh | 提非纳字母 |
| 2D80 | 2DDF | Ethiopic Extended | 埃塞俄比亚文扩充 |
| 2E00 | 2E7F | Supplemental Punctuation | 标点符号补充 |
| 2E80 | 2EFF | CJK Radicals Supplement | 中日韩部首补充 |
| 2F00 | 2FDF | Kangxi Radicals | 康熙字典部首 |
| 2FF0 | 2FFF | Ideographic Description Characters | 汉字结构描述字符 |
| 3000 | 303F | CJK Symbols and Punctuation | 中日韩符号和标点 |
| 3040 | 309F | Hiragana | 平假名 |
| 30A0 | 30FF | Katakana | 片假名 |
| 3100 | 312F | Bopomofo | 注音符号 |
| 3130 | 318F | Hangul Compatibility Jamo | 朝鲜文兼容字母 |
| 3190 | 319F | Kanbun | 日文的汉字批注 |
| 31A0 | 31BF | Bopomofo Extended | 注音符号扩充 |
| 31C0 | 31EF | CJK Strokes | 中日韩笔划 |
| 31F0 | 31FF | Katakana Phonetic Extensions | 片假名音标扩充 |
| 3200 | 32FF | Enclosed CJK Letters and Months | 带括号的中日韩字母及月份 |
| 3300 | 33FF | CJK Compatibility | 中日韩兼容字符 |
| 3400 | 4DBF | CJK Unified Ideographs Extension A | 中日韩统一表意文字扩充A |
| 4DC0 | 4DFF | Yijing Hexagram Symbols | 易经六十四卦象 |
| 4E00 | 9FFF | CJK Unified Ideographs | 中日韩统一表意文字 |
| A000 | A48F | Yi Syllables | 彝文音节 |
| A490 | A4CF | Yi Radicals | 彝文字根 |
| A700 | A71F | Modifier Tone Letters | 声调修饰字母 |
| A720 | A7FF | Latin Extended-D | 拉丁字母扩充-D |
| A800 | A82F | Syloti Nagri | Syloti Nagri字母表 |
| A840 | A87F | Phags-pa | Phags-pa字母表 |
| AC00 | D7AF | Hangul Syllables | 朝鲜文音节 |
| D800 | DB7F | High Surrogates | 高位替代 |
| DB80 | DBFF | High Private Use Surrogates | 高位专用替代 |
| DC00 | DFFF | Low Surrogates | 低位替代 |
| E000 | F8FF | Private Use Area | 专用区 |
| F900 | FAFF | CJK Compatibility Ideographs | 中日韩兼容表意文字 |
| FB00 | FB4F | Alphabetic Presentation Forms | 字母变体显现形式 |
| FB50 | FDFF | Arabic Presentation Forms-A | 阿拉伯文变体显现形式-A |
| FE00 | FE0F | Variation Selectors | 字型变换选取器 |
| FE10 | FE1F | Vertical Forms | 竖排标点符号 |
| FE20 | FE2F | Combining Half Marks | 组合半角标示 |
| FE30 | FE4F | CJK Compatibility Forms | 中日韩兼容形式 |
| FE50 | FE6F | Small Form Variants | 小型变体形式 |
| FE70 | FEFF | Arabic Presentation Forms-B | 阿拉伯文变体显现形式-B |
| FF00 | FFEF | Halfwidth and Fullwidth Forms | 半角及全角字符 |
| FFF0 | FFFF | Specials | 特殊区域 |
| 10000 | 1007F | Linear B Syllabary | 线形文字B音节文字 |
| 10080 | 100FF | Linear B Ideograms | 线形文字B表意文字 |
| 10100 | 1013F | Aegean Numbers | 爱琴海数字 |
| 10140 | 1018F | Ancient Greek Numbers | 古希腊数字 |
| 10300 | 1032F | Old Italic | 古意大利文 |
| 10330 | 1034F | Gothic | 哥特文 |
| 10380 | 1039F | Ugaritic | 乌加里特楔形文字 |
| 103A0 | 103DF | Old Persian | 古波斯文 |
| 10400 | 1044F | Deseret | 德塞雷特大学音标 |
| 10450 | 1047F | Shavian | 肃伯纳速记符号 |
| 10480 | 104AF | Osmanya | Osmanya字母表 |
| 10800 | 1083F | Cypriot Syllabary | 塞浦路斯音节文字 |
| 10900 | 1091F | Phoenician | 腓尼基文 |
| 10A00 | 10A5F | Kharoshthi | 迦娄士悌文 |
| 12000 | 123FF | Cuneiform | 楔形文字 |
| 12400 | 1247F | Cuneiform Numbers and Punctuation | 楔形文字数字和标点 |
| 1D000 | 1D0FF | Byzantine Musical Symbols | 东正教音乐符号 |
| 1D100 | 1D1FF | Musical Symbols | 音乐符号 |
| 1D200 | 1D24F | Ancient Greek Musical Notation | 古希腊音乐符号 |
| 1D300 | 1D35F | Tai Xuan Jing Symbols | 太玄经符号 |
| 1D360 | 1D37F | Counting Rod Numerals | 算筹 |
| 1D400 | 1D7FF | Mathematical Alphanumeric Symbols | 数学用字母数字符号 |
| 20000 | 2A6DF | CJK Unified Ideographs Extension B | 中日韩统一表意文字扩充 B |
| 2F800 | 2FA1F | CJK Compatibility Ideographs Supplement | 中日韩兼容表意文字补充 |
| E0000 | E007F | Tags | 标签 |
| E0100 | E01EF | Variation Selectors Supplement | 字型变换选取器补充 |
| F0000 | FFFFF | Supplementary Private Use Area-A | 补充专用区-A |
| 100000 | 10FFFF | Supplementary Private Use Area-B | 补充专用区-B |
Block是Unicode字符的一个属性。属于同一个Block的字符有着相近的用途。Block表中的开始码位、结束码位只是用来划分出一块区域,在开始码位和结束码位之间可能还有很多未定义的码位。使用UniToy,大家可以按照Block浏览Unicode字符,既可以按列表显示:
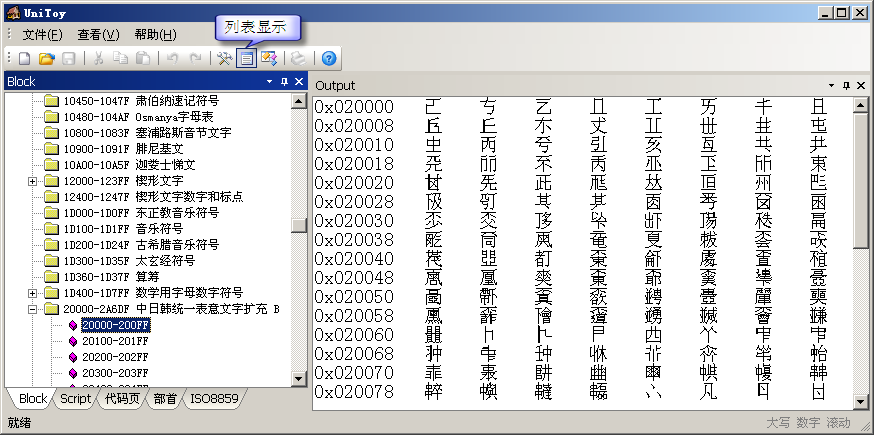
也可以显示每个字符的详细信息:

4.1.3 Script
Unicode中每个字符都有一个Script属性,这个属性表明字符所属的文字系统。Unicode目前支持以下Script:
| Script名称(英文) | Script名称(中文) | Script包含的字符数 |
| Arabic | 阿拉伯文 | 966 |
| Armenian | 亚美尼亚文 | 90 |
| Balinese | 巴厘文 | 121 |
| Bengali | 孟加拉文 | 91 |
| Bopomofo | 汉语注音符号 | 64 |
| Braille | 盲文 | 256 |
| Buginese | 布吉文 | 30 |
| Buhid | 布迪文 | 20 |
| Canadian Aboriginal | 加拿大印第安方言 | 630 |
| Cherokee | 切罗基文 | 85 |
| Common | Common | 5020 |
| Coptic | 科普特文 | 128 |
| Cuneiform | 楔形文字 | 982 |
| Cypriot | 塞浦路斯音节文字 | 55 |
| Cyrillic | 西里尔文 | 277 |
| Deseret | 德塞雷特大学音标 | 80 |
| Devanagari | 天成文书(梵文) | 107 |
| Ethiopic | 埃塞俄比亚文 | 461 |
| Georgian | 格鲁吉亚文 | 120 |
| Gothic | 哥特文 | 94 |
| Glagolitic | 格拉哥里字母表 | 27 |
| Greek | 希腊文 | 506 |
| Gujarati | 古吉拉特文 | 83 |
| Gurmukhi | 锡克教文 | 77 |
| Han | 汉文 | 71570 |
| Hangul | 韩文书写系统 | 11619 |
| Hanunoo | 哈努诺文 | 21 |
| Hebrew | 希伯来文 | 133 |
| Hiragana | 平假名 | 89 |
| Inherited | Inherited | 461 |
| Kannada | 卡纳达文 | 86 |
| Katakana | 片假名 | 164 |
| Kharoshthi | 迦娄士悌文 | 65 |
| Khmer | 高棉文 | 146 |
| Lao | 老挝文 | 65 |
| Latin | 拉丁文系 | 1070 |
| Limbu | 林布文(尼泊尔东部) | 66 |
| Linear B | 线形文字B | 211 |
| Malayalam | 德拉维族文(印度) | 78 |
| Mongolian | 蒙古文 | 152 |
| Myanmar | 缅甸文 | 78 |
| New Tai Lue | 新傣文 | 80 |
| Nko | N'Ko字母表 | 59 |
| Ogham | 欧甘文字 | 29 |
| Old Italic | 古意大利文 | 35 |
| Old Persian | 古波斯文 | 50 |
| Oriya | 奥里亚文 | 81 |
| Osmanya | Osmanya字母表 | 40 |
| Phags Pa | Phags Pa字母表(蒙古) | 56 |
| Phoenician | 腓尼基文 | 27 |
| Runic | 古代北欧文 | 78 |
| Shavian | 肃伯纳速记符号 | 48 |
| Sinhala | 僧伽罗文 | 80 |
| Syloti Nagri | Syloti Nagri字母表(印度) | 44 |
| Syriac | 叙利亚文 | 77 |
| Tagalog | 塔加路文(菲律宾) | 20 |
| Tagbanwa | Tagbanwa文(菲律宾) | 18 |
| Tai Le | 德宏傣文 | 35 |
| Tamil | 泰米尔文 | 71 |
| Telugu | 泰卢固文(印度) | 80 |
| Thaana | 马尔代夫书写体 | 50 |
| Thai | 泰国文 | 86 |
| Tibetan | 藏文 | 195 |
| Tifinagh | 提非纳字母表 | 55 |
| Ugaritic | 乌加里特楔形文字 | 31 |
| Yi | 彝文 | 1220 |
其中,有两个Script值有着特殊的含义:
- Common:Script属性为Common的字符可能在多个文字系统中使用,不是某个文字系统特有的。例如:空格、数字等。
- Inherited:Script属性为Inherited的字符会继承前一个字符的Script属性。主要是一些组合用符号,例如:在“组合附加符号”区(0x300-0x36f),字符的Script属性都是Inherited。
UCD中的Script.txt列出了每个字符的Script属性。使用UniToy可以按照Script属性查看字符。例如:
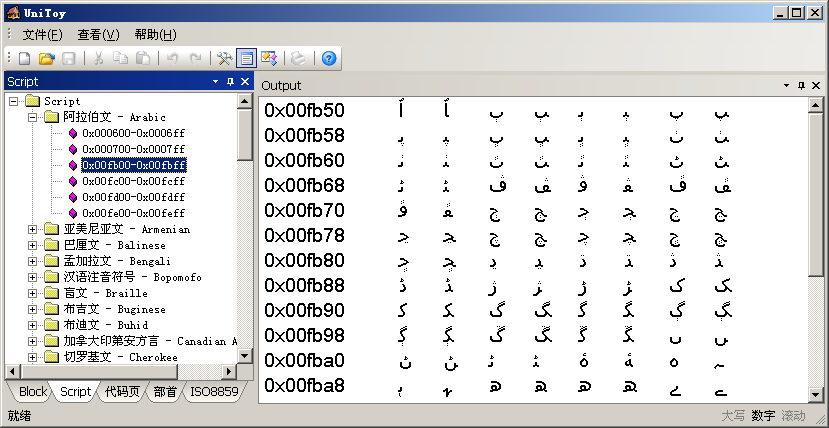
左侧Script窗口中,第一层节点是按英文字母顺序排列的Script属性。第二层节点是包含该Script文字的行(row),点击后显示该行内属于这个Script的字符。这样,就可以集中查看属于同一文字系统的字符。
4.1.4 Unicode中的汉字
前面提过,在Unicode已定义的99089个字符中,有71226个字符是汉字。它们的分布如下:
| Block名称 | 开始码位 | 结束码位 | 数量 | |
| 中日韩统一表意文字扩充A | 3400 | 4db5 | 6582 | |
| 中日韩统一表意文字 | 4e00 | 9fbb | 20924 | |
| 中日韩兼容表意文字 | f900 | fa2d | 302 | |
| 中日韩兼容表意文字 | fa30 | fa6a | 59 | |
| 中日韩兼容表意文字 | fa70 | fad9 | 106 | |
| 中日韩统一表意文字扩充B | 20000 | 2a6d6 | 42711 | |
| 中日韩兼容表意文字补充 | 2f800 | 2fa1d | 542 |
UCD的Unihan.txt中的部首偏旁索引(kRSUnicode)可以检索全部71226个汉字。kRSUnicode的部首是按照康熙字典定义的,共214个部首。简体字按照简体部首对应的繁体部首检索。UniToy整理了康熙字典部首对应的简体部首,提供了按照部首检索汉字的功能:
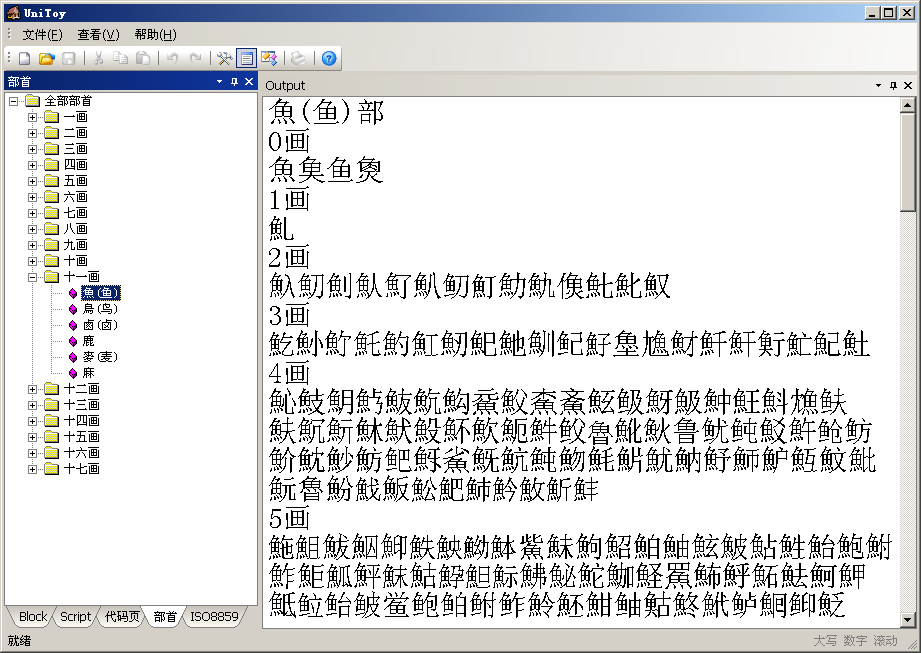
4.2 UTF编码
在字符编码的四个层次中,第一层的范围和第二层的编码在4.1节已经详细讨论过了。本节讨论第三层的UTF编码和第四层的字节序,主要谈谈第三层的UTF编码,即怎样将Unicode定义的编码转换成程序数据。
4.2.1 UTF-8
UTF-8以字节为单位对Unicode进行编码。从Unicode到UTF-8的编码方式如下:
| Unicode编码(16进制) | UTF-8 字节流(二进制) |
| 000000 - 00007F | 0xxxxxxx |
| 000080 - 0007FF | 110xxxxx 10xxxxxx |
| 000800 - 00FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 010000 - 10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
UTF-8的特点是对不同范围的字符使用不同长度的编码。对于0x00-0x7F之间的字符,UTF-8编码与ASCII编码完全相同。UTF-8编码的最大长度是4个字节。从上表可以看出,4字节模板有21个x,即可以容纳21位二进制数字。Unicode的最大码位0x10FFFF也只有21位。
例1:“汉”字的Unicode编码是0x6C49。0x6C49在0x0800-0xFFFF之间,使用用3字节模板了:1110xxxx10xxxxxx10xxxxxx。将0x6C49写成二进制是:0110 1100 0100 1001, 用这个比特流依次代替模板中的x,得到:111001101011000110001001,即E6 B1 89。
例2:“![]() ”字的Unicode编码是0x20C30。0x20C30在0x010000-0x10FFFF之间,使用用4字节模板了:11110xxx10xxxxxx10xxxxxx10xxxxxx。将0x20C30写成21位二进制数字(不足21位就在前面补0):0 0010 0000 1100 0011 0000,用这个比特流依次代替模板中的x,得到:11110000101000001011000010110000,即F0 A0 B0 B0。
”字的Unicode编码是0x20C30。0x20C30在0x010000-0x10FFFF之间,使用用4字节模板了:11110xxx10xxxxxx10xxxxxx10xxxxxx。将0x20C30写成21位二进制数字(不足21位就在前面补0):0 0010 0000 1100 0011 0000,用这个比特流依次代替模板中的x,得到:11110000101000001011000010110000,即F0 A0 B0 B0。
4.2.2 UTF-16
UniToy有个“输出编码”功能,可以输出当前选择的文本编码。因为UniToy内部采用UTF-16编码,所以输出的编码就是文本的UTF-16编码。例如:如果我们输出“汉”字的UTF-16编码,可以看到0x6C49,这与“汉”字的Unicode编码是一致的。如果我们输出“![]() ”字的UTF-16编码,可以看到0xD843, 0xDC30。“
”字的UTF-16编码,可以看到0xD843, 0xDC30。“![]() ”字的Unicode编码是0x20C30,它的UTF-16编码是怎样得到的呢?
”字的Unicode编码是0x20C30,它的UTF-16编码是怎样得到的呢?
4.2.2.1 编码规则
UTF-16编码以16位无符号整数为单位。我们把Unicode编码记作U。编码规则如下:
- 如果U<0x10000,U的UTF-16编码就是U对应的16位无符号整数(为书写简便,下文将16位无符号整数记作WORD)。
- 如果U≥0x10000,我们先计算U'=U-0x10000,然后将U'写成二进制形式:yyyy yyyy yyxx xxxx xxxx,U的UTF-16编码(二进制)就是:110110yyyyyyyyyy110111xxxxxxxxxx。
为什么U'可以被写成20个二进制位?Unicode的最大码位是0x10ffff,减去0x10000后,U'的最大值是0xfffff,所以肯定可以用20个二进制位表示。例如:“![]() ”字的Unicode编码是0x20C30,减去0x10000后,得到0x10C30,写成二进制是:0001 0000 1100 0011 0000。用前10位依次替代模板中的y,用后10位依次替代模板中的x,就得到:11011000010000111101110000110000,即0xD843 0xDC30。
”字的Unicode编码是0x20C30,减去0x10000后,得到0x10C30,写成二进制是:0001 0000 1100 0011 0000。用前10位依次替代模板中的y,用后10位依次替代模板中的x,就得到:11011000010000111101110000110000,即0xD843 0xDC30。
4.2.2.2 代理区(Surrogate)
按照上述规则,Unicode编码0x10000-0x10FFFF的UTF-16编码有两个WORD,第一个WORD的高6位是110110,第二个WORD的高6位是110111。可见,第一个WORD的取值范围(二进制)是11011000 00000000到11011011 11111111,即0xD800-0xDBFF。第二个WORD的取值范围(二进制)是11011100 00000000到11011111 11111111,即0xDC00-0xDFFF。
为了将一个WORD的UTF-16编码与两个WORD的UTF-16编码区分开来,Unicode编码的设计者将0xD800-0xDFFF保留下来,并称为代理区(Surrogate):
| D800 | DB7F | High Surrogates | 高位替代 |
| DB80 | DBFF | High Private Use Surrogates | 高位专用替代 |
| DC00 | DFFF | Low Surrogates | 低位替代 |
高位替代就是指这个范围的码位是两个WORD的UTF-16编码的第一个WORD。低位替代就是指这个范围的码位是两个WORD的UTF-16编码的第二个WORD。那么,高位专用替代是什么意思?我们来解答这个问题,顺便看看怎么由UTF-16编码推导Unicode编码。
解:如果一个字符的UTF-16编码的第一个WORD在0xDB80到0xDBFF之间,那么它的Unicode编码在什么范围内?我们知道第二个WORD的取值范围是0xDC00-0xDFFF,所以这个字符的UTF-16编码范围应该是0xDB80 0xDC00到0xDBFF 0xDFFF。我们将这个范围写成二进制:
110110111000000011011100 00000000 -11011011111111111101111111111111
按照编码的相反步骤,取出高低WORD的后10位,并拼在一起,得到
1110 0000 0000 0000 0000 - 1111 1111 1111 1111 1111
即0xe0000-0xfffff,按照编码的相反步骤再加上0x10000,得到0xf0000-0x10ffff。这就是UTF-16编码的第一个WORD在0xdb80到0xdbff之间的Unicode编码范围,即平面15和平面16。因为Unicode标准将平面15和平面16都作为专用区,所以0xDB80到0xDBFF之间的保留码位被称作高位专用替代。
4.2.3 UTF-32
UTF-32编码以32位无符号整数为单位。Unicode的UTF-32编码就是其对应的32位无符号整数。
4.2.4 字节序
根据字节序的不同,UTF-16可以被实现为UTF-16LE或UTF-16BE,UTF-32可以被实现为UTF-32LE或UTF-32BE。例如:
| 字符 | Unicode编码 | UTF-16LE | UTF-16BE | UTF32-LE | UTF32-BE |
| 汉 | 0x6C49 | 49 6C | 6C 49 | 49 6C 00 00 | 00 00 6C 49 |
| 0x20C30 | 43 D8 30 DC | D8 43 DC 30 | 30 0C 02 00 | 00 02 0C 30 |
那么,怎么判断字节流的字节序呢?
Unicode标准建议用BOM(Byte Order Mark)来区分字节序,即在传输字节流前,先传输被作为BOM的字符"零宽无中断空格"。这个字符的编码是FEFF,而反过来的FFFE(UTF-16)和FFFE0000(UTF-32)在Unicode中都是未定义的码位,不应该出现在实际传输中。下表是各种UTF编码的BOM:
| UTF编码 | Byte Order Mark |
| UTF-8 | EF BB BF |
| UTF-16LE | FF FE |
| UTF-16BE | FE FF |
| UTF-32LE | FF FE 00 00 |
| UTF-32BE | 00 00 FE FF |