Netty-Mina深入学习与对比
这博文的系列主要是为了更好的了解一个完整的nio框架的编程细节以及演进过程,我选了同父(Trustin Lee)的两个框架netty与mina做对比。版本涉及了netty3.x、netty4.x、mina1.x、mina2.x、mina3.x。这里并没有写netty5.x的细节,看了netty5的修改文档,似乎有一些比较有意思的改动,准备单独写一篇netty4.x与netty5.x的不同。
netty从twitter发布的这篇Netty 4 at Twitter: Reduced GC Overhead文章让国内Java界为之一振,也小火了一把,同时netty的社区发展也不错,版本迭代非常快,半年不关注大、小版本就发了好几轮了。但是mina就有点淡了,github上面它最后大多数代码最后的修改日期均在2013年,不过我从个人情感上还是挺喜欢mina3的代码,没有太多的用不上的功能(支持各种协议啥的),跑自带的benchmark性能也比netty4好一些。但是如果是生产用的话,就偏向netty多一些了,毕竟社区活跃,版本迭代也快。
1. mina、netty的线程模型
mina与netty都是Trustin Lee的作品,所以在很多方面都十分相似,他们线程模型也是基本一致,采用了Reactors in threads模型,即Main Reactor + Sub Reactors的模式。由main reactor处理连接相关的任务:accept、connect等,当连接处理完毕并建立一个socket连接(称之为session)后,给每个session分配一个sub reactor,之后该session的所有IO、业务逻辑处理均交给了该sub reactor。每个reactor均是一个线程,sub reactor中只靠内核调度,没有任何通信且互不打扰。
在前面的博文:Netty 4.x学习笔记 – 线程模型,对netty的线程模型有一定的介绍。现在来讲讲我对线程模型演进的一些理解:
Thread per Connection: 在没有nio之前,这是传统的java网络编程方案所采用的线程模型。即有一个主循环,socket.accept阻塞等待,当建立连接后,创建新的线程/从线程池中取一个,把该socket连接交由新线程全权处理。这种方案优缺点都很明显,优点即实现简单,缺点则是方案的伸缩性受到线程数的限制。Reactor in Single Thread: 有了nio后,可以采用IO多路复用机制了。我们抽取出一个单线程版的reactor模型,时序图见下文,该方案只有一个线程,所有的socket连接均注册在了该reactor上,由一个线程全权负责所有的任务。它实现简单,且不受线程数的限制。这种方案受限于使用场景,仅适合于IO密集的应用,不太适合CPU密集的应用,且适合于CPU资源紧张的应用上。

Reactor + Thread Pool: 方案2由于受限于使用场景,但为了可以更充分的使用CPU资源,抽取出一个逻辑处理线程池。reactor仅负责IO任务,线程池负责所有其它逻辑的处理。虽然该方案可以充分利用CPU资源,但是这个方案多了进出thread pool的两次上下文切换。

Reactors in threads: 基于方案3缺点的考虑,将reactor分成两个部分。main reactor负责连接任务(accept、connect等),sub reactor负责IO、逻辑任务,即mina与netty的线程模型。该方案适应性十分强,可以调整sub reactor的数量适应CPU资源紧张的应用;同时CPU密集型任务时,又可以在业务处理逻辑中将任务交由线程池处理,如方案5。该方案有一个不太明显的缺点,即session没有分优先级,所有session平等对待均分到所有的线程中,这样可能会导致优先级低耗资源的session堵塞高优先级的session,但似乎netty与mina并没有针对这个做优化。
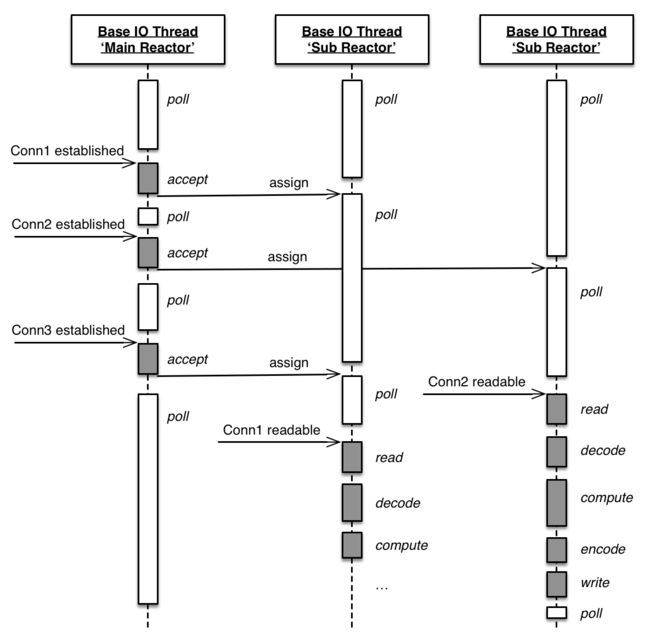
Reactors in threads + Threads pool: 这也是我所在公司应用框架采用的模型,可以更为灵活的适应所有的应用场景:调整reactor数量、调整thread pool大小等。

以上图片及总结参考:《Linux多线程服务端编程》
2. mina、netty的任务调度粒度
mina、netty在线程模型上并没有太大的差异性,主要的差异还是在任务调度的粒度的不同。任务从逻辑上我给它分为成三种类型:连接相关的任务(bind、connect等)、写任务(write、flush)、调度任务(延迟、定时等),读任务则由selector加循环时间控制了。mina、netty任务调度的趋势是逐渐变小,从session级别的调度 -> 类型级别任务的调度 -> 任务的调度。
2.1 代码
mina-1.1.7: SocketIoProcessor$Worker.runmina-2.0.4: AbstractPollingIoProcessor$Processor.runmina-3.0.0.M3-SNAPSHOT: AbstractNioSession.processWritenetty-3.5.8.Final: AbstractNioSelector.runnetty-4.0.6.Final: NioEventLoop.run
2.2 分析
mina1、2的任务调度粒度为session。mina会将有IO任务的的session写入队列中,当循环执行任务时,则会轮询所有的session,并依次把session中的所有任务取出来运行。这样粗粒度的调度是不公平调度,会导致某些请求的延迟很高。
mina3的模型改动比较大,代码相对就比较难看了,我仅是随便扫了一下,它仅提炼出了writeQueue。
而netty3的调度粒度则是按照IO操作,分成了registerTaskQueue、writeTaskQueue、eventQueue三个队列,当有IO任务时,依次processRegisterTaskQueue、processEventQueue、processWriteTaskQueue、processSelectedKeys(selector.selectedKeys)。
netty4可能觉得netty3的粒度还是比较粗,将队列细分成了taskQueue和delayedTaskQueue,所有的任务均放在taskQueue中,delayedTaskQueue则是定时调度任务,且netty4可以灵活配置task与selectedKey处理的时间比例。
BTW: netty3.6.0之后,所有的队列均合并成了一个taskQueue
有意思的是,netty4会优先处理selectedKeys,然后再处理任务,netty3则相反。mina1、2则是先处理新建的session,再处理selectedKeys,再处理任务。
难道selectedKeys处理顺序有讲究么?
接下来讲主要是讲nio编程中的注意事项,netty-mina的对这些注意事项的实现方式的差异,以及业务层会如何处理这些注意事项。
1. 数据是如何write出去的
java nio如果是non-blocking的话,在每次write(bytes[N])的时候,并不会将N字节全部write出去,每次write仅一部分(具体大小和tcp_write_buffer有关)。那么,mina和netty是怎么处理这种情况的呢?
代码
- mina-1.1.7: SocketIoProcessor.doFlush
- mina-2.0.4: AbstractPollingIoProcessor.flushNow
- mina-3.0.0.M3-SNAPSHOT: AbstractNioSession.processWrite
- netty-3.5.8.Final: AbstractNioWorker.write0
- netty-4.0.6.Final: AbstractNioByteChannel.doWrite
分析
mina1、2,netty3的方式基本一致。 在发送端每个session均有一个writeBufferQueue,有这样一个队列,可以保证写入与写出均有序。在真正write时,大致逻辑均是一一将队列中的writeBuffer取出,写入socket。但有一些不同的是,mina1是每次peek一次,当该buffer全部写出之后再poll(mina3也是这种机制);而mina2、netty3则是直接poll第一个,将其存为currentWriteRequest,直到currentWriteRequest全部写出之后,才会再poll下一个。这样的做法是为了省几次peek的时间么?
同时mina、netty在write时,有一种spin write的机制,即循环write多次。mina1的spin write count为256,写死在代码里了,表示256有点大;mina2这个机制废除但代码保留;netty3则可以配置,默认为16。netty在这里略胜一筹!
netty4与netty3的机制差不多,但是netty4为这个事情特意写了一个ChannelOutboundBuffer类,输出队列写在了该类的flushed:Object[]成员中,但表示ChannelOutboundBuffer这个类的代码有点长,就暂不深究了。T_T
2. 数据是如何read进来的
如第三段内容,每次write只是输出了一部分数据,read同理,也有可能只会读入部分数据,这样就是导致读入的数据是残缺的。而mina和netty默认不会理会这种由于nio导致的数据分片,需要由业务层自己额外做配置或者处理。
代码
- nfs-rpc: ProtocolUtils.decode
- mina-1.1.7: SocketIoProcessor.read, CumulativeProtocolDecoder.decode
- mina-2.0.4: AbstractPollingIoProcessor.read, CumulativeProtocolDecoder.decode
- mina-3.0.0.M3-SNAPSHOT: NioSelectorLoop.readBuffer
- netty-3.5.8.Final: NioWorker.read, FrameDecoder
- netty-4.0.6.Fianl: AbstractNioByteChannel$NioByteUnsafe.read
业务层处理
nfs-rpc在协议反序列化的过程中,就会考虑这个的问题,依次读入每个字节,当发现当前字节或者剩余字节数不够时,会将buf的readerIndex设置为初始状态。具体的实现,有兴趣的同学可以学习nfs-rpc:ProtocolUtils.decode
nfs-rpc在decode时,出现错误就会将buf的readerIndex设为0,把readerIndex设置为0就必须要有个前提假设:每次decode时buf是同一个,即该buf是复用的。那么,具体情况是怎样呢?
框架层处理
我看读mina与netty这块的代码,发现主要演进与不同的点在两个地方:读buffer的创建与数据分片的处理方式。
mina:
mina1、2的读buffer创建方式比较土,在每次read之前,会重新allocate一个新的buf对象,该buf对象的大小是根据读入数据大小动态调整。当本次读入数据等于该buf大小,下一次allocate的buf对象大小会翻倍;当本次读入数据不足该buf大小的二分之一,下一次allocate的buf对象同样会缩小至一半。需要注意的是,*2与/2的代码都可以用位运算,但是mina1竟没用位运算,有意思。
mina1、2处理数据分片可以继承CumulativeProtocolDecoder,该decoder会在session中存入(BUFFER, cumulativeBuffer)。decode过程为:1)先将message追加至cumulativeBuffer;2)调用具体的decode逻辑;3)判断cumulativeBuffer.hasRemaining(),为true则压缩cumulativeBuffer,为false则直接删除(BUFFER, cumulativeBuffer)。实现业务的decode逻辑可以参考nfs-rpc中MinaProtocolDecoder的代码。
mina3在处理读buffer的创建与数据分片比较巧妙,它所有的读buffer共用一个buffer对象(默认64kb),每次均会将读入的数据追加至该buffer中,这样即省去了buffer的创建与销毁事件,也省去了cumulativeDecoder的处理逻辑,让代码很清爽啊!
netty:
netty3在读buffer创建部分的代码还是挺有意思的,首先,它创建了一个SocketReceiveBufferAllocator的allocate对象,名字为recvBufferPool,但是里面代码完全和pool扯不上关系;其次,它每次创建buffer也会动态修改初始大小的机制,它设计了232个大小档位,最大值为Integer.MAX_VALUE,没有具体考究,这种实现方式似乎比每次大小翻倍优雅一点,具体代码可以参考:AdaptiveReceiveBufferSizePredictor。
对应mina的CumulativeProtocolDecoder类,在netty中则是FrameDecoder和ReplayingDecoder,没深入只是大致扫了下代码,原理基本一致。BTW,ReplayingDecoder似乎挺强大的,有兴趣的可以看看这两篇:
[High speed custom codecs with ReplayingDecoder]
[An enhanced version of ReplayingDecoder for Netty]netty4在读buffer创建部分机制与netty3大同小异,不过由于netty有了ByteBufAllocator的概念,要想每次不重新创建销毁buffer的话,可以采用PooledByteBufAllocator。
在处理分片上,netty4抽象出了Message这样的概念,我的理解就是,一个Message就是业务可读的数据,转换Message的抽象类:ByteToMessageDecoder,当然也有netty3中的ReplayingDecoder,继承自ByteToMessageDecoder,具体可以研究代码。
3. ByteBuffer设计的差异
自建buffer的原因
mina:
需要说明的是,只有mina1、2才有自己的buffer类,mina3内部只用nio的原生ByteBuffer类(提供了一个组合buffer的代理类-IoBuffer)。mina1、2自建buffer的原因如下:
- It doesn’t provide useful getters and putters such as fill,get/putString, and get/putAsciiInt()enough.
- It is difficult to write variable-length data due to its fixed capacity
第一条比较好理解,即提供了更为方便的方法用以操作buffer。第二条则是觉得nio的ByteBuffer是定长的,无法自动扩容或者缩容,所以提供了自动扩/缩容的方法:IoBuffer.setAutoExpand, IoBuffer.setAutoShrink。但是扩/缩容的实现,也是基于nio的ByteBuffer,重新ByteBuffer.allocate(capacity),再把原有的数据拷贝过去。
netty:
在我前面的博文([Netty 4.x学习笔记 – ByteBuf])我已经提到这些原因:
- 需要的话,可以自定义buffer类型
- 通过组合buffer类型,可实现透明的zero-copy
- 提供动态的buffer类型,如StringBuffer一样(扩容方式也是每次double),容量是按需扩展
- 无需调用flip()方法
- 常常「often」比ByteBuffer快
以上理由来自netty3的API文档:[Package org.jboss.netty.buffer]),netty4没见到官方的说法,但是我觉得还得加上一个更为重要也是最为重要的理由,就是可以实现buffer池化管理。
实现的差异
mina:
mina的实现较为基础,仅仅只是在ByteBuffer上的一些简单封装。
netty:
netty3与netty4的实现大致相同(ChannlBuffer -> ByteBuf),具体可以参见:[Netty 4.x学习笔记 – ByteBuf](http://hongweiyi.com/2014/01/netty-4-x-bytebuf/),netty4实现了PooledByteBufAllocator,传闻是可以大大减少GC的压力,但是官方不保证没有内存泄露,我自己压测中也出现了内存泄露的警告,建议生产中谨慎使用该功能。
netty5.x有一个更为高级的buffer泄露跟踪机制,PooledByteBufAllocator也已经默认开启,有机会可以尝试使用一下。