HDFS IO操作总结
Hadoop IO操作
意义
Hadoop自带一套用于I/O的原子性的操作
(不会被线程调度机制打断,一直到结束,中间不会有任何context switch)
特点
基于保障海量数据集的完整性和压缩性
Hadoop提供了一些用于开发分布式系统的API(一些序列化操作+基于磁盘的底层数据结构)
一、数据完整性
实现
- Configuration conf=...
- FileSystem fs=new RawLocalFileSystem();
- fs.initialize(null, conf);
- FileSystem rawFs=...
- FileSystem checksummedFs=new ChecksumFileSystem(fs){} ;
二、文件格式
Hadoop中的文件格式大致上分为面向行和面向列两类:
-
面向行:同一行的数据存储在一起,即连续存储。SequenceFile,MapFile,Avro Datafile。采用这种方式,如果只需要访问行的一小部分数据,亦需要将整行读入内存,推迟序列化一定程度上可以缓解这个问题,但是从磁盘读取整行数据的开销却无法避免。面向行的存储适合于整行数据需要同时处理的情况。
-
面向列:整个文件被切割为若干列数据,每一列数据一起存储。Parquet , RCFile,ORCFile。面向列的格式使得读取数据时,可以跳过不需要的列,适合于只处于行的一小部分字段的情况。但是这种格式的读写需要更多的内存空间,因为需要缓存行在内存中(为了获取多行中的某一列)。同时不适合流式写入,因为一旦写入失败,当前文件无法恢复,而面向行的数据在写入失败时可以重新同步到最后一个同步点,所以Flume采用的是面向行的存储格式。
1. SequenceFile
SequenceFile的文件结构如下:
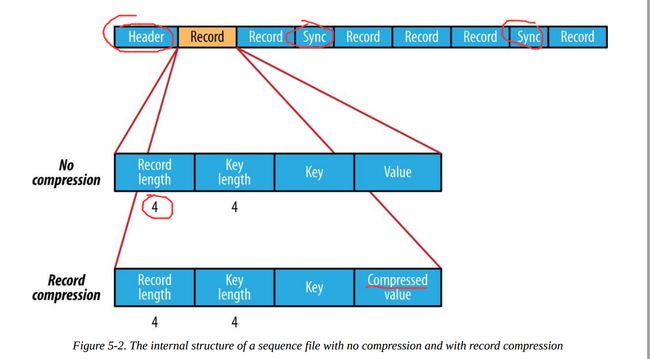
根据是否压缩,以及采用记录压缩还是块压缩,存储格式有所不同:
-
不压缩:
按照记录长度、Key长度、Value程度、Key值、Value值依次存储。长度是指字节数。采用指定的Serialization进行序列化。 -
Record压缩:
只有value被压缩,压缩的codec保存在Header中。 -
Block压缩:
多条记录被压缩在一起,可以利用记录之间的相似性,更节省空间。Block前后都加入了同步标识。Block的最小值由io.seqfile.compress.blocksize属性设置。
2. MapFile
MapFile是SequenceFile的变种,在SequenceFile中加入索引并排序后就是MapFile。索引作为一个单独的文件存储,一般每个128个记录存储一个索引。索引可以被载入内存,用于快速查找。存放数据的文件根据Key定义的顺序排列。
MapFile的记录必须按照顺序写入,否则抛出IOException。
MapFile的衍生类型:
- SetFile:特殊的MapFile,用于存储一序列Writable类型的Key。Key按照顺序写入。
- ArrayFile:Key为整数,代表在数组中的位置,value为Writable类型。
- BloomMapFile:针对MapFile的get()方法,使用动态Bloom过滤器进行优化。过滤器保存在内存中,只有带key值存在的时候,才会调用常规的get()方法,真正进行读操作。
Hadoop体系下面向列的文件包括RCFile,ORCFile,Parquet的。Avro的面向列版本为Trevni。
三、压缩
四、序列化
1、什么是序列化?
将结构化对象转换成字节流以便于进行网络传输或写入持久存储的过程。
2、什么是反序列化?
将字节流转换为一系列结构化对象的过程。
序列化用途:
1、作为一种持久化格式。
2、作为一种通信的数据格式。
3、作为一种数据拷贝、克隆机制。
Java序列化和反序列化
1、创建一个对象实现了Serializable
2、序列化:ObjectOutputStream.writeObject(序列化对象)
反序列化:ObjectInputStream.readObject()返回序列化对象
具体实现,可参考如下文章:
http://blog.csdn.net/scgaliguodong123_/article/details/45938555
为什么Hadoop不直接使用java序列化?
Hadoop的序列化机制与Java的序列化机制不同,它将对象序列化到流中,值得一提的是java的序列化机制是不断的创建对象,但在hadoop的序列化机制中,用户可以复用对象,这样就减少了java对象的分配和回收,提高了应用效率。
Hadoop序列化
Hadoop的序列化不采用java的序列化,而是实现了自己的序列化机制。
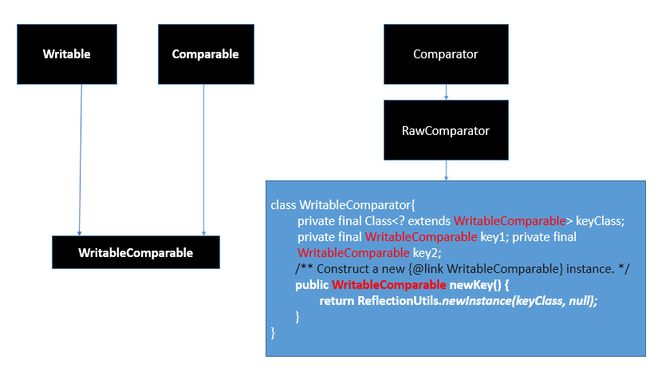
Hadoop通过Writable接口实现的序列化机制,不过没有提供比较功能,所以和java中的Comparable接口合并,提供一个接口WritableComparable。(自定义比较)
Writable接口提供两个方法(write和readFields)。
package org.apache.hadoop.io;
public interface Writable {
void write(DataOutput out) throws IOException;
void readFields(DataInput in) throws IOException;
}- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
需要进行比较的话,要实现WritableComparable接口。
public interface WritableComparable<T> extends Writable, Comparable<T>{
}- 1
- 2
- 1
- 2
比如mapreduce中需要对key值进行相应的排序。可参考下面的例子:
http://blog.csdn.net/scgaliguodong123_/article/details/46010947
Hadoop提供了几个重要的序列化接口与实现类:
外部集合的比较器
RawComparator
package org.apache.hadoop.io;
public interface RawComparator<T> extends Comparator<T> {
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
}
public class WritableComparator implements RawComparator {
private final Classextends WritableComparable> keyClass;
private final WritableComparable key1;
private final WritableComparable key2;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
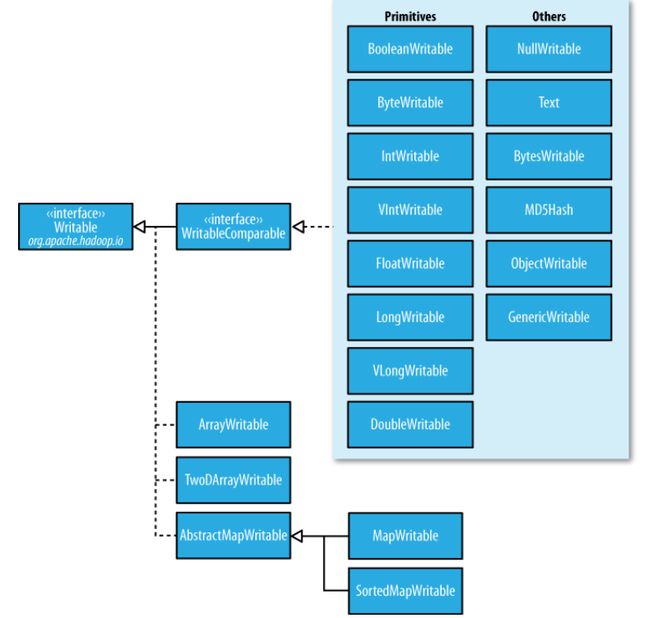
实现了WritableComparable接口的类(自定义比较)
org.apache.hadoop.io
接口
WritableComparable
父接口
Comparable, Writable
基础实现类
BooleanWritable, ByteWritable, ShortWritable,IntWritable,
VIntWritable,LongWritable, VLongWritable , FloatWritable, DoubleWritable
高级实现类
MD5Hash, NullWritable,Text, BytesWritable,ObjectWritable,GenericWritable - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
仅实现了Writable接口的类
org.apache.hadoop.io
Interface(接口) Writable
All Known Subinterfaces(子接口):
Counter, CounterGroup, CounterGroupBase, InputSplit, InputSplitWithLocationInfo, WritableComparable
仅实现了Writable接口的类
数组:AbstractWritable、TwoDArrayWritable
映射:AbstractMapWritable、MapWritable、SortedMapWritable - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Writable接口
Text
Text是UTF-8的Writable,可以理解为java.lang.String相类似的Writable。Text类替代了UTF-8类。Text是可变的,其值可以通过调用set()方法改变。最大可以存储2GB的大小。
NullWritable
NullWritable是一种特殊的Writable类型,它的序列化长度为零,可以用作占位符。
BytesWritable
BytesWritable是一个二进制数据数组封装,序列化格式是一个int字段。
例如:一个长度为2,值为3和5的字节数组序列后的结果是:
@Test
public void testByteWritableSerilizedFromat() throws IOException {
BytesWritable bytesWritable=new BytesWritable(new byte[]{3,5});
byte[] bytes=SerializeUtils.serialize(bytesWritable);
Assert.assertEquals(StringUtils.byteToHexString(bytes),"000000020305"); //true
} - 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
BytesWritable是可变的,其值可以通过调用set()方法来改变。
ObjectWritable
ObjectWritable适用于字段使用多种类型时。
Writable集合
1、ArrayWritable和TwoDArrayWritable是针对数组和二维数组。
2、MapWritable和SortedMapWritable是针对Map和SortMap。
自定义Writable
1、实现WritableComparable接口
2、实现相应的接口方法:
A.write() //将对象转换为字节流并写入到输出流out中。
B.readFileds() //从输入流in中读取字节流并发序列化为对象。
C.compareTo(o) //将this对象和对象o进行比较。
可参考下面的例子,自定义NewK2类:
http://blog.csdn.net/scgaliguodong123_/article/details/46010947
package Writable;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.DataInput;
import java.io.DataInputStream;
import java.io.DataOutput;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
public class DefineWritable {
public static void main(String[] args) throws IOException {
Student student = new Student("liguodong", 22, "男");
BufferedOutputStream bos = new BufferedOutputStream(
new FileOutputStream(new File("g:/liguodong.txt")));
DataOutputStream dos = new DataOutputStream(bos);
student.write(dos);
dos.flush();
dos.close();
bos.close();
Student student2 = new Student();
BufferedInputStream bis = new BufferedInputStream(
new FileInputStream(new File("g:/liguodong.txt")));
DataInputStream dis = new DataInputStream(bis);
student2.readFields(dis);
System.out.println("name="+student2.getName()
+",age="+student2.getAge()+",sex="+student2.getSex());
}
}
class Student implements WritableComparable{
private Text name = new Text();
private IntWritable age = new IntWritable();
private Text sex = new Text();
public Student() {
}
public Student(String name, int age, String sex) {
super();
this.name = new Text(name);
this.age = new IntWritable(age);
this.sex = new Text(sex);
}
public Text getName() {
return name;
}
public void setName(Text name) {
this.name = name;
}
public IntWritable getAge() {
return age;
}
public void setAge(IntWritable age) {
this.age = age;
}
public Text getSex() {
return sex;
}
public void setSex(Text sex) {
this.sex = sex;
}
@Override
public void write(DataOutput out) throws IOException {
name.write(out);
age.write(out);
sex.write(out);
}
@Override
public void readFields(DataInput in) throws IOException {
//如果使用Java数据类型,比如String name;
//this.name = in.readUTF();只能使用这种类型。
name.readFields(in);
age.readFields(in);
sex.readFields(in);
}
@Override
public int compareTo(Student o) {
int result=0;
if((result=this.name.compareTo(o.getName())) != 0 ){
return result;
}
if((result=this.age.compareTo(o.getAge())) != 0 ){
return result;
}
if((result=this.sex.compareTo(o.getSex())) != 0 ){
return result;
}
return 0;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
运行结果:
name=liguodong,age=22,sex=男- 1
- 1
Hadoop序列化优势:
1、紧凑:Hadoop中最稀缺的资源是宽带,所以紧凑的序列化机制可以充分的利用宽带。
2、快速:通信时大量使用序列化机制,因此,需要减少序列化和反序列化的开销。
3、可扩展:随着通信协议的升级而可升级。
4、互操作:支持不同开发语言的通信。
Hadoop1.x 序列化仅满足了紧凑和快速的特点。
Hadoop序列化的作用
序列化在分布式环境的两大作用:进程间通信,永久存储。
Hadoop节点间通信。
序列化框架
Apache Avro
1、丰富的数据结构类型
2、快速可压缩的二进制数据形式
3、存储持久数据的文件容器
4、远程过程调用RPC
5、简单的动态语言结合功能,Avro和动态语言结合后,读写数据文件和使用RPC协议都不需要生成代码,而代码生成作为一种可选的优化,只值得在静态类型语言中实现。
Facebook Thrift
1、是一种可伸缩的跨语言服务的发展软件框架。
2、它结合了功能强大的软件堆栈的代码生成引擎,以建设服务,工作效率和无缝地与C++,C#,.Java,Python和PHP和Ruby结合。
3、允许定义一个简单的定义文件中的数据类型和服务接口,以作为输入文件,编
译器生成代码用来方便地生成RPC客户端和服务器通信的无缝跨编程语言。
Google Protocolbuffer
PB是Google开源的一种轻量级的结构化数据存储格式,可以用于结构化数据的序
列化与反序列化,很适合做数据存储或RPC数据交换格式。
优点:
与 XML相比,它更小、更快、也更简单。你可以定义自己的数据结构,然后使用代码生成器生成的代码来读写这个数据结构。你甚至可以在无需重新部署程序的情况下更新数据结构。只需使用 Protobuf 对数据结构进行一次描述,即可利用各种不同语言或从各种不同数据流中对你的结构化数据轻松读写。
它有一个非常棒的特性,即“向后”兼容性好,人们不必破坏已部署的、依靠”老”数据格式的程序就可以对数据结构进行升级。这样您的程序就可以不必担心因为消息结构的改变而造成的大规模的代码重构或者迁移的问题。因为添加新的消息中的 field 并不会引起已经发布的程序的任何改变。
Protocolbuffer语义更清晰,无需类似 XML 解析器的东西(因为 Protobuf 编译器会将 .proto 文件编译生成对应的数据访问类以对 Protobuf 数据进行序列化、反序列化操作)。使用 Protobuf 无需学习复杂的文档对象模型,Protobuf 的编程模式比较友好,简单易学,同时它拥有良好的文档和示例,对于喜欢简单事物的人们而言,Protobuf 比其他的技术更加有吸引力。
不足:
Protbuf 与 XML 相比也有不足之处。它功能简单,无法用来表示复杂的概念。
由于文本并不适合用来描述数据结构,所以 Protobuf 也不适合用来对基于文本的标记文档(如 HTML)建模。另外,由于 XML 具有某种程度上的自解释性,它可以被人直接读取编辑,在这一点上 Protobuf 不行,它以二进制的方式存储,除非你有 .proto 定义,否则你没法直接读出 Protobuf 的任何内容。
Hadoop2.X用到的Protocolbuffer hadoop-2.6.0-src/hadoop-hdfs-project/hadoop-hdfs/src/main/proto