百度云 自然语言处理(Nlp)
这个自然语言处理功能十分强大,对一语话,可以进行类似我们以前的分词器分词效果,还能标记出可能倾向的搜索词.还有就是对语言的情感分析,文章的标签分类等等在商业场合应用都十分广泛的,来看这个小例子好像在微信小程序有看到
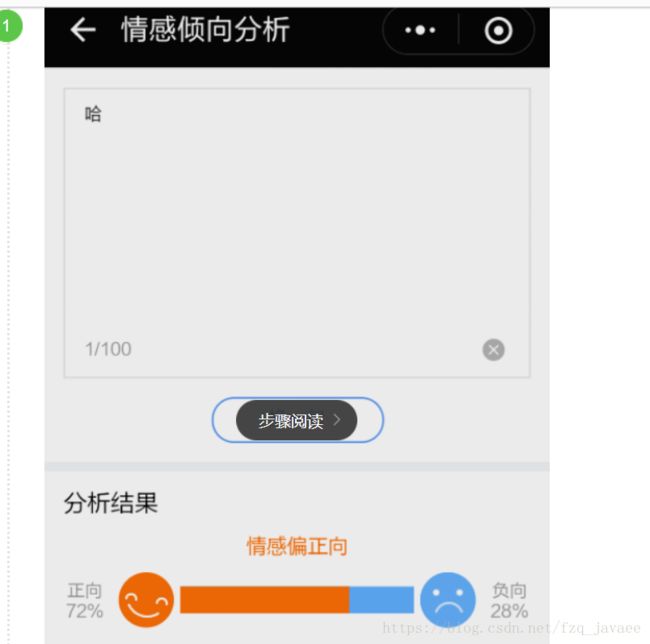
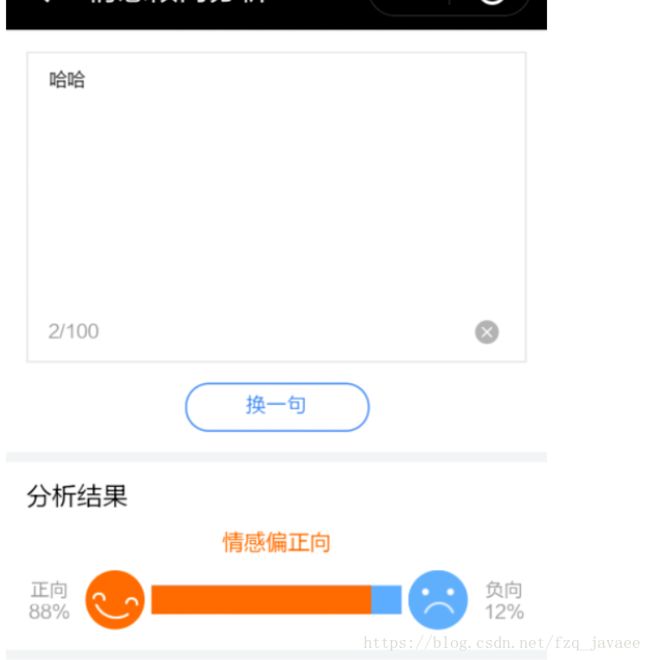
以上是引自百度的一个ai体验中心,.....
/** * 词法分析 */ @Test public void lexer(){ JavaAipNlp aipNlp = new JavaAipNlp(); HashMap<String, Object> options = new HashMap<String, Object>(); JSONObject lexer = aipNlp.lexer("好好学习天天向上!", options); System.out.println(lexer.toString()); //{"log_id":664642641923030240,"text":"好好学习天天向上!","items":[ // {"formal":"","loc_details":[],"item":"好好","pos":"d","ne":"","basic_words":["好","好"],"byte_length":4,"byte_offset":0,"uri":""}, // {"formal":"","loc_details":[],"item":"学习","pos":"v","ne":"","basic_words":["学习"],"byte_length":4,"byte_offset":4,"uri":""}, // {"formal":"","loc_details":[],"item":"天天向上","pos":"v","ne":"","basic_words":["天天","向上"],"byte_length":8,"byte_offset":8,"uri":""}, // {"formal":"","loc_details":[],"item":"!","pos":"w","ne":"","basic_words":["!"],"byte_length":1,"byte_offset":16,"uri":""}]}
//词法分析(定制版) @Test public void lexerCustom(){ JavaAipNlp aipNlp = new JavaAipNlp(); HashMap<String, Object> options = new HashMap<String, Object>(); JSONObject lexer = aipNlp.lexer("广东省南山区科苑北清华信息港!", options); System.out.println(lexer.toString());
// {"log_id":2841336793035219062,"text":"广东省南山区科苑北清华信息港!","items":[ // {"formal":"","loc_details":[],"item":"广东省","pos":"","ne":"LOC","basic_words":["广东","省"],"byte_length":6,"byte_offset":0,"uri":""}, // {"formal":"","loc_details":[],"item":"南山区","pos":"","ne":"LOC","basic_words":["南山","区"],"byte_length":6,"byte_offset":6,"uri":""}, // {"formal":"","loc_details":[],"item":"科苑","pos":"n","ne":"","basic_words":["科苑"],"byte_length":4,"byte_offset":12,"uri":""}, // {"formal":"","loc_details":[],"item":"北","pos":"f","ne":"","basic_words":["北"],"byte_length":2,"byte_offset":16,"uri":""}, // {"formal":"","loc_details":[],"item":"清华信息港","pos":"","ne":"ORG","basic_words":["清华","信息","港"],"byte_length":10,"byte_offset":18,"uri":""}, // {"formal":"","loc_details":[],"item":"!","pos":"w","ne":"","basic_words":["!"],"byte_length":1,"byte_offset":28,"uri":""}]} //LOC 地名
//依存法 句法分析 @Test public void depParser (){ JavaAipNlp aipNlp = new JavaAipNlp(); HashMap<String, Object> options = new HashMap<String, Object>(); //模型选择。默认值为0,可选值mode=0(对应web模型);mode=1(对应query模型 options.put("mode",1); JSONObject lexer = aipNlp.depParser("我不想上班", options); System.out.println(lexer.toString()); //{"log_id":8560515157495529056,"text":"我不想上班","items":[ // {"head":2,"deprel":"SBV","postag":"n","id":1,"word":"我不想"}, // {"head":0,"deprel":"HED","postag":"v","id":2,"word":"上班"}]} }
//DNN 语言模型 //中文DNN语言模型接口用于输出切词结果并给出每个词在句子中的概率值,判断一句话是否符合语言表达习惯。 //ppl float 描述句子通顺的值:数值越低,句子越通顺 resp_sample: //prob float 该词在句子中的概率值,取值范围[0,1] @Test public void dnnlmCn (){ // String words = "我上下班飞机在河里漂浮"; String words = "我爱生活!"; JavaAipNlp aipNlp = new JavaAipNlp(); HashMap<String, Object> options = new HashMap<String, Object>(); JSONObject lexer = aipNlp.dnnlmCn(words, options); System.out.println(lexer.toString()); //{"log_id":6371386997672135571,"text":"我上下班飞机在河里漂浮","items":[ // {"prob":0.0161273,"word":"我"}, // {"prob":0.00229803,"word":"上"}, // {"prob":0.00197205,"word":"下班"}, // {"prob":1.35979E-5,"word":"飞机"}, // {"prob":0.0167389,"word":"在"}, // {"prob":3.04629E-4,"word":"河里"}, // {"prob":1.17134E-4,"word":"漂浮"}], // "ppl":1077.36} //===================================================================== // {"log_id":962095172634786721,"text":"我爱生活!","items":[ // {"prob":0.0161273,"word":"我"}, // {"prob":0.0125896,"word":"爱"}, // {"prob":9.05624E-4,"word":"生活"}, // {"prob":0.0197345,"word":"!"}], }
//词义相似度 // 输入两个词,得到两个词的相似度结果。 @Test public void wordSimEmbedding (){ String words1 = "小"; // 最大64kb String words2 = "小"; JavaAipNlp aipNlp = new JavaAipNlp(); HashMap<String, Object> options = new HashMap<String, Object>(); // options.put("mode", 0); JSONObject lexer = aipNlp.wordSimEmbedding(words1,words2, options); System.out.println(lexer.toString()); //{"log_id":7955806838486346559,"score":1,"words":{"word_1":"小","word_2":"小"}} //score 相似度的分数 1 为完全相似 }
//短文本 相似度 // 输入两个短文本,得到两个词的相似度结果。 @Test public void simnet (){ String words1 = "立马"; String words2 = "马上"; JavaAipNlp aipNlp = new JavaAipNlp(); HashMap<String, Object> options = new HashMap<String, Object>(); options.put("model", "CNN"); JSONObject lexer = aipNlp.simnet(words1,words2, options); System.out.println(lexer.toString()); //{"log_id":5656570856871633902,"score":0.580114,"texts":{"text_1":"立马","text_2":"马上"}} }
//评论观点抽取 // 评论观点抽取接口用来提取一条评论句子的关注点和评论观点,并输出评论观点标签及评论观点极性 /** * Type * 1 - 酒店 2 - KTV3 - 丽人 4 - 美食餐饮 5 - 旅游 6 - 健康 7 - 教育 8 - 商业 9 - 房产 10 - 汽车 11 - 生活 12 - 购物 13 - 3C */ @Test public void commentTag (){ JavaAipNlp aipNlp = new JavaAipNlp(); String text = "这家餐馆味道很差"; HashMap<String, Object> options = new HashMap<String, Object>(); JSONObject lexer = aipNlp.commentTag(text, ESimnetType.FOOD, options); System.out.println(lexer.toString()); // {"log_id":8456459865047604201,"items":[ // {"sentiment":0,"adj":"差劲","prop":"味道","end_pos":16,"abstract":"这家餐馆味道很差<\/span>","begin_pos":8}]} String hotel = "喜来登酒店干净卫生"; JSONObject result = aipNlp.commentTag(hotel, ESimnetType.HOTEL, options); System.out.println(result.toString()); //prop string 匹配上的属性词 //adj string 匹配上的描述词 // sentiment int 该情感搭配的极性(0表示消极,1表示中性,2表示积极) //begin_pos int 该情感搭配在句子中的开始位置 (干) //end_pos int 该情感搭配在句子中的结束位置 (生) // abstract string 对应于该情感搭配的短句摘要 //{"log_id":6206030619412743250,"items":[ // {"sentiment":2,"adj":"卫生","prop":"干净","end_pos":18,"abstract":"喜来登酒店干净卫生<\/span>","begin_pos":10}, // {"sentiment":2,"adj":"干净","prop":"卫生","end_pos":18,"abstract":"喜来登酒店干净卫生<\/span>","begin_pos":10}]} }
/** * 情感倾向分析 * 对包含主观观点信息的文本进行情感极性类别(积极、消极、中性)的判断,并给出相应的置信度。 */ @Test public void sentimentClassify(){ JavaAipNlp aipNlp = new JavaAipNlp(); String text = "淘宝上很多假货"; HashMap<String, Object> options = new HashMap<String, Object>(); JSONObject lexer = aipNlp.sentimentClassify(text, options); System.out.println(lexer.toString()); // {"log_id":4774610278737884339,
//"text":"淘宝上很多假货",
//"items":[{"positive_prob":0.498948,"sentiment":1,"confidence":0.97895,"negative_prob":0.501053}]}
/** * +sentiment 是 number 表示情感极性分类结果, 0:负向,1:中性,2:正向 +confidence 是 number 表示分类的置信度 +positive_prob 是 number 表示属于积极类别的概率 +negative_prob 是 number 表示属于消极类别的概率 */ }
/* 文章标签 文章标签服务能够针对网络各类媒体文章进行快速的内容理解,根据输入含有标题的文章,输出多个内容标签以及对
应的置信度,用于个性化推荐、相似文章聚合、文内容分析等场景。
*/
@Test
public void
keyword(){
String title =
"iphone手机出现“白苹果”原因及解决办法,用苹果手机的可以看下"
;
String content =
"如果下面的方法还是没有解决你的问题建议来我们门店看下成都市锦江区红星路三段99号银石广场24层01室。"
;
JavaAipNlp aipNlp =
new JavaAipNlp()
;
HashMap<
String
,
Object>
options =
new HashMap<
String
,
Object>()
;
JSONObject lexer =
aipNlp.keyword(
title
,
content
,
options)
;
System.
out.println(
lexer.toString())
;
/*
{"log_id":3274746225884300396,"items":[
{"score":0.99775,"tag":"iphone"},
{"score":0.862602,"tag":"手机"},
{"score":0.845657,"tag":"苹果"},
{"score":0.837886,"tag":"苹果公司"},
{"score":0.811601,"tag":"白苹果"},
{"score":0.797911,"tag":"数码"}]}
+tag 是 string 关注点字符串
+score 是 number 权重(取值范围0~1)
*/}
/** * 文章分类 对文章按照内容类型进行自动分类,首批支持娱乐、体育、科技等26个主流内容类型,为文章聚类、
文本内容分析等应用提供基础技术支持。 */ @Test public void topic (){ String title = "欧洲冠军杯足球赛"; String content = "欧洲冠军联赛是欧洲足球协会联盟主办的年度足球比赛,
代表欧洲俱乐部足球最高荣誉和水平,被认为是全世界最高素质、" + "最具影响力以及最高水平的俱乐部赛事,亦是世界上奖金最高的足球赛事和体育赛事之一。"; JavaAipNlp aipNlp = new JavaAipNlp(); HashMap<String, Object> options = new HashMap<String, Object>(); JSONObject lexer = aipNlp.topic(title,content, options); System.out.println(lexer.toString()); /** * 返回参数说明 * +lv1_tag_list array of objects 一级分类结果 +lv2_tag_list array of objects 二级分类结果 实际返回参数: * {"log_id":6440401236167732852,"item":{"lv2_tag_list":[ * {"score":0.915631,"tag":"足球"}, * {"score":0.803507,"tag":"国际足球"}, * {"score":0.77813,"tag":"英超"}], * "lv1_tag_list":[{"score":0.830915,"tag":"体育"}]}} */ }像百度在大数据,人工智能这一块的业务做得已经很开了,就像调查问卷,你可以直接根据你想调查的行业和问题调用
他们的接口数据,返回他们的真是调查结果给你.已经很厉害了,只是这个需要一元一份问卷,看似很贵,但是这是他们
多年的数据积累啊.还有就是根据您的视频可以提取视频里面精彩部分作为帧图或者缩略图,等等很强大的接口,
视频播放网站上那些我们看到的电影的缩略图是不是就是这样来的?