Hadoop2.6.0启动脚本分析
Start-all.sh启动原理
Step1:start-all.sh
先看sbin目录下的start-all.sh脚本。
抛出注释,内容很少:
# Start all hadoop daemons. Run this on master node.
这个脚本在hadoop-2.6.0被建议不要使用。推荐使用的是分别启动start-dfs.sh和start-yarn.sh.
其内容步骤:
1.找到bin文件夹的路径,并设置HADOOP_LIBEXEC_DIR这个环境变量。
2.执行HADOOP_LIBEXEC_DIR(实际上hadoop目录下libexec)的hadoop-config.sh脚本(这个脚本设置了环境变量等)
3.判断sbin目录下是否有start-dfs和start-yarn这两个脚本。如果有的话,分别执行start-dfs.sh和start-yarn.sh两个脚本,
运行yarn和hdfs进程(daemon)。开启服务。
其中,--config后面的HADOOP_CONF_DIR(hadoop的配置文件目录通常指/etc/hadoop)
echo "This script is Deprecated.Instead use start-dfs.sh and start-yarn.sh"
bin=`dirname "${BASH_SOURCE-$0}"`
bin=`cd "$bin"; pwd`
DEFAULT_LIBEXEC_DIR="$bin"/../libexec
HADOOP_LIBEXEC_DIR=${HADOOP_LIBEXEC_DIR:-$DEFAULT_LIBEXEC_DIR}
. $HADOOP_LIBEXEC_DIR/hadoop-config.sh
# start hdfs daemons if hdfs is present
if [ -f"${HADOOP_HDFS_HOME}"/sbin/start-dfs.sh ]; then
"${HADOOP_HDFS_HOME}"/sbin/start-dfs.sh --config$HADOOP_CONF_DIR
fi
# start yarn daemons if yarn is present
if [ -f"${HADOOP_YARN_HOME}"/sbin/start-yarn.sh ]; then
"${HADOOP_YARN_HOME}"/sbin/start-yarn.sh --config$HADOOP_CONF_DIR
fi
Step2:start-dfs.sh
# Start hadoop dfs daemons.
# Optinally upgrade or rollback dfs state.
# Run this on master node.
启动hadoop dfs daemons,启动方式可以在后面加参数。参数有rollback和upgrade,还有clusterID。
此脚本需在master节点上启动。
usage="Usage: start-dfs.sh[-upgrade|-rollback] [other options such as -clusterId]"
使用方法:通常情况下什么都不加,直接start-dfs.sh即可
bin=`dirname "${BASH_SOURCE-$0}"`
bin=`cd "$bin"; pwd`
DEFAULT_LIBEXEC_DIR="$bin"/../libexec
HADOOP_LIBEXEC_DIR=${HADOOP_LIBEXEC_DIR:-$DEFAULT_LIBEXEC_DIR}
. $HADOOP_LIBEXEC_DIR/hdfs-config.sh跟step1一样,不再赘述。
bin=`dirname "${BASH_SOURCE-$0}"`
bin=`cd "$bin"; pwd`
DEFAULT_LIBEXEC_DIR="$bin"/../libexec
HADOOP_LIBEXEC_DIR=${HADOOP_LIBEXEC_DIR:-$DEFAULT_LIBEXEC_DIR}
. $HADOOP_LIBEXEC_DIR/hdfs-config.sh
判断参数,如果start-dfs.sh后面有大于等于1个参数的情况。
# get arguments
if [ $# -ge 1 ]; then
nameStartOpt="$1"
shift
case"$nameStartOpt" in
(-upgrade)
;;
(-rollback)
dataStartOpt="$nameStartOpt"
;;
(*)
echo $usage
exit 1
;;
esac
fi
#Add other possible options
nameStartOpt="$nameStartOpt $@"令nameStartOpt这个参数等于$nameStartOpt $@
(如果没有参数的时候,这个语句不执行。)
#---------------------------------------------------------
# namenodes
NAMENODES=$($HADOOP_PREFIX/bin/hdfs getconf-namenodes)
echo "Starting namenodes on[$NAMENODES]"
"$HADOOP_PREFIX/sbin/hadoop-daemons.sh"\
--config "$HADOOP_CONF_DIR" \
--hostnames "$NAMENODES" \
--script "$bin/hdfs" start namenode $nameStartOpt
启动namenodes
“NAMENODES=$($HADOOP_PREFIX/bin/hdfs getconf -namenodes)”这句的意思是设置NAMENODES的环境变量(单机)。其中/bin/hdfs是负责启动与HDFS相关的服务与命令行工具的脚本。因为hadoop是由java实现的,所以这个脚本实际上是添加一个java的命令行来启动服务和工具对应的MainClass。它是最底层的启动脚本。

因为我是单机环境,所以NAMENODES是localhost。因为我这个没有安装ZooKeeper,只是基本的环境。所以这里只启动了namenodes,datanodes和secondary namenodes。
需要注意的是:每个模块都启动了sbin/ hadoop-daemons.sh并且设置了相应的属性。
#---------------------------------------------------------
# datanodes (using default slaves file)
if [ -n "$HADOOP_SECURE_DN_USER"]; then
echo \
"Attempting to start secure cluster, skipping datanodes. " \
"Run start-secure-dns.sh as root to complete startup."
else
"$HADOOP_PREFIX/sbin/hadoop-daemons.sh" \
--config "$HADOOP_CONF_DIR" \
--script "$bin/hdfs" start datanode $dataStartOpt
fi
因为HADOOP_SECURE_DN_USER环境变量这个值为空(默认为空,这个安全模式),所以没有提示echo。而是直接使用sbin/hadoop-daemons.sh来启动datanodes。
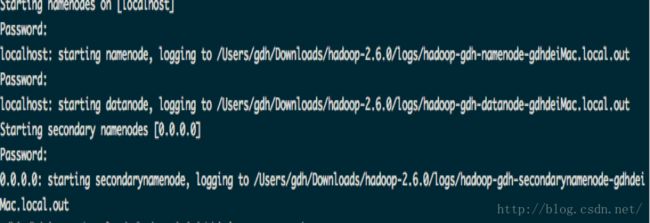
#---------------------------------------------------------
# secondary namenodes (if any)
SECONDARY_NAMENODES=$($HADOOP_PREFIX/bin/hdfsgetconf -secondarynamenodes 2>/dev/null)
if [ -n "$SECONDARY_NAMENODES" ];then
echo "Starting secondary namenodes [$SECONDARY_NAMENODES]"
"$HADOOP_PREFIX/sbin/hadoop-daemons.sh" \
--config "$HADOOP_CONF_DIR" \
--hostnames "$SECONDARY_NAMENODES" \
--script "$bin/hdfs" start secondarynamenode
fi实际上:start-dfs.sh所有的命令,不管是启动单个的namenode还是启动多个datanode,都是通过hadoop-daemons.sh,再通过slaves.sh推送到目标机器上的。唯一不同的地方是:在启动namenode和secondary-namenode的时候都通过--hostnames参数显示地给出了命令的推送目标(注:将--hostnames参数的值会赋给HADOOP_SLAVE_NAMES这个动作发生在libexec/hadoop-config.sh脚本里,在hadoop-daemons.sh里,调用slaves.sh之前会先执行hadoop-config.sh,完成对HADOOP_SLAVE_NAMES的设值)。而在启动datanode时,则不会设置--hostnames的值,这样HADOOP_SLAVE_NAMES的值会从slaves文件中读取,也就datanode的列表。
Step3:start-daemons.sh
# secondary namenodes (if any)
SECONDARY_NAMENODES=$($HADOOP_PREFIX/bin/hdfsgetconf -secondarynamenodes 2>/dev/null)
if [ -n "$SECONDARY_NAMENODES" ];then
echo "Starting secondary namenodes [$SECONDARY_NAMENODES]"
"$HADOOP_PREFIX/sbin/hadoop-daemons.sh" \
--config "$HADOOP_CONF_DIR" \
--hostnames "$SECONDARY_NAMENODES" \
--script "$bin/hdfs" start secondarynamenode
fihadoop-daemons.sh后面的参数数目务必大于1
bin=`dirname "${BASH_SOURCE-$0}"`
bin=`cd "$bin"; pwd`
DEFAULT_LIBEXEC_DIR="$bin"/../libexec
HADOOP_LIBEXEC_DIR=${HADOOP_LIBEXEC_DIR:-$DEFAULT_LIBEXEC_DIR}
. $HADOOP_LIBEXEC_DIR/hadoop-config.sh老套路···(这里需要注意的是,在hadoop-config.sh里面,将--hostnames参数的值会赋给HADOOP_SLAVE_NAMES这个动作发生在libexec/hadoop-config.sh脚本里。)
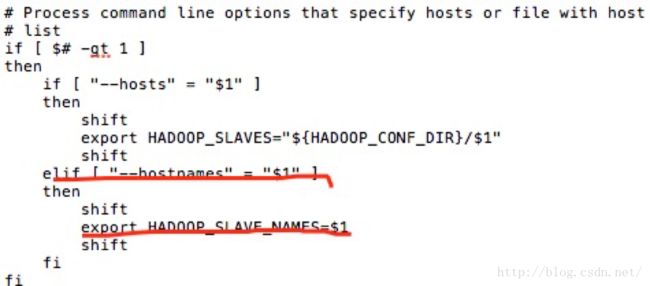
(图为hadoop-config.sh里面对--hostnames后面的参数进行判断并且赋值。)
bin=`dirname "${BASH_SOURCE-$0}"`
bin=`cd "$bin"; pwd`
DEFAULT_LIBEXEC_DIR="$bin"/../libexec
HADOOP_LIBEXEC_DIR=${HADOOP_LIBEXEC_DIR:-$DEFAULT_LIBEXEC_DIR}
. $HADOOP_LIBEXEC_DIR/hadoop-config.sh
在hadoop-daemons.sh里,调用slaves.sh之前会先执行hadoop-config.sh,完成对HADOOP_SLAVE_NAMES的设值。
借用一个图:

摘自:http://blog.csdn.net/bluishglc/article/details/43237289
其中:图4的括号括起来的部分:
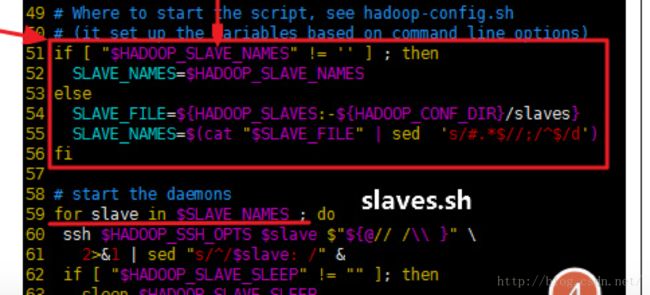
环境变量HADOOP_CONF_DIR 为etc/hadoop,其下面的slaves是在单机环境下是localhost。在线上环境下:内容为
在我的单机环境下,内容就是localhost。(线上环境是我实习公司的集群)
Step 4 hadoop-daemon.sh
下面就是start daemons,启动进程。ssh 连接每台datanode机器,并且cd到每台机器的$HADOOP_PREFIX(在我的sd0主机上是/usr/local/hadoop)。
还拿这句话来分析,目前已经执行完成的是slaves.sh。下面要执行的是hadoop-daemon.sh。
1) 先在注释里面说明了了几个环境变量对应的值。
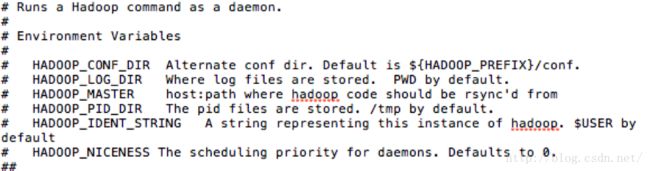
2) 判断参数:如果参数小于等于1,则告知用法并且退出。再设置bin,HADOOP_LIBEXEC_DIR的值,并执行hadoop-config.sh。(按照这个顺序,每个脚本正式执行前,都要执行下面这段代码)
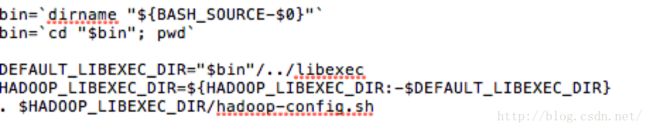
对于此脚本,hadoop-config.sh脚本的作用就是把配置文件和主机列表的文件处理好了并设置相应的环境变量保存它们。
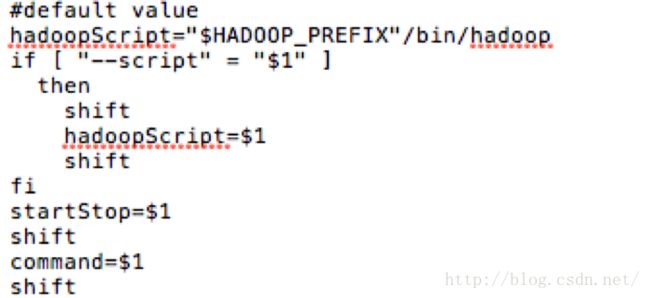
3) 接下来,设置hadoopScript(后面用nohup引用),并且保存startStop变量和command变量。
4) 然后是定义了一个叫hadoop_rotate_log()的函数:hadoop滚动日志函数。其意思是:
① 先判断hadoop-deamon跟的第五个参数(根据之前的shift次数得出,如果—script = $1,否则是第三个参数)的长度是不是大于0,如果是的话,那么num 变量不再等于5,而是等于第五个参数,否则是5。
② 再判断$log(第四个参数)时候是一个文件,如果是的话,则滚动日志(rotate logs)
③ 顺序是:out4->out5,out3->out4,out2-out3,out1->out2,out->out1
5) 下面,判断hadoop-env.sh是否存在,如果存在执行此文件。这个文件里面有JAVA_HOME等比较重要的环境变量,对大集群来说,这个文件很重要。其后面红色框内的内容,是设置一些环境变量。(拿HADOOP_LOG_DIR来说,先是判断它是否为空,再判断其是否有权限进行写操作。)
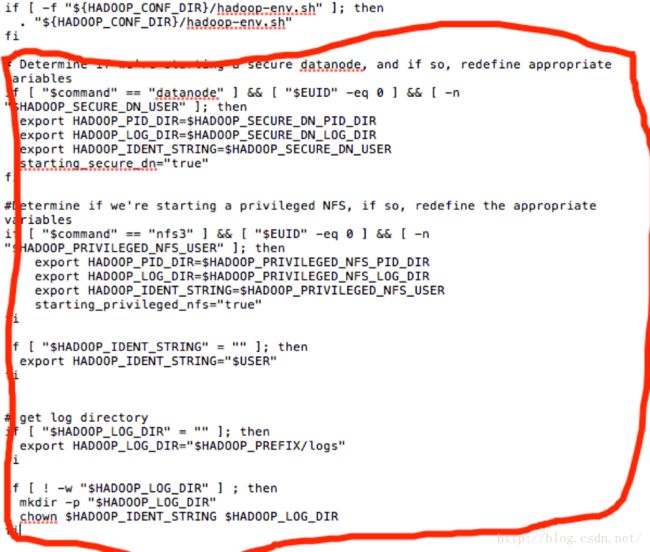
6) 最后用一个case –esac来控制程序的start与stop。
case $startStop in
(start)
如果第三/五个参数为start,则执行下面的语句。
[-w "$HADOOP_PID_DIR" ] || mkdir -p "$HADOOP_PID_DIR"
如果HADOOP_PID_DIR没有写权限(不可写),则创建。
if [ -f $pid ]; then
if kill -0 `cat $pid` >/dev/null 2>&1; then
kill -0 是测试指定的PID是否存在,2>&1是把stderr和stdout定向到一起 /dev/null。如果存在,会提示提示需要先关闭才能启动,并退出shell。
echo $command running as process `cat $pid`. Stop it first.
exit 1
fi
fi
if [ "$HADOOP_MASTER" != "" ]; then
echo rsync from$HADOOP_MASTER
rsync是类unix系统下的数据镜像备份工具,从软件的命名上就可以看出来了——remote sync。
rsync -a -essh --delete --exclude=.svn --exclude='logs/*' --exclude='contrib/hod/logs/*'$HADOOP_MASTER/ "$HADOOP_PREFIX"
fi
日志文件备份
hadoop_rotate_log $log
echo starting $command, logging to $log
cd "$HADOOP_PREFIX"
case $command in
namenode|secondarynamenode|datanode|journalnode|dfs|dfsadmin|fsck|balancer|zkfc)
if [ -z "$HADOOP_HDFS_HOME" ]; then
hdfsScript="$HADOOP_PREFIX"/bin/hdfs
else
hdfsScript="$HADOOP_HDFS_HOME"/bin/hdfs
fi
nohup命令是登出远程计算机后继续执行任务,nice命令用于以指定的进程调度优先级启动其他的程序。参考来自:http://man.linuxde.net/nice
nohup nice -n $HADOOP_NICENESS $hdfsScript --config$HADOOP_CONF_DIR $command "$@" > "$log" 2>&1 "$log" 2>&1 < /dev/null &
;;
esac
echo $! > $pid
$!为此shell最后运行的process的ID
sleep 1
head "$log"
# capture theulimit output
获取文件系统与程序的限制关系的输出
if [ "true" = "$starting_secure_dn" ]; then
echo "ulimit -a for secure datanode user$HADOOP_SECURE_DN_USER" >> $log
# capture theulimit info for the appropriate user
su –是不仅将用户身份切换,而且还把shell环境也切换。切换了shell环境,PATH的环境变量才有效(~/.bash_profile或者~/.profile)
su--shell=/bin/bash $HADOOP_SECURE_DN_USER -c 'ulimit -a' >> $log2>&1
elif [ "true" = "$starting_privileged_nfs" ]; then
echo "ulimit -a for privileged nfs user$HADOOP_PRIVILEGED_NFS_USER" >> $log
su--shell=/bin/bash $HADOOP_PRIVILEGED_NFS_USER -c 'ulimit -a' >> $log2>&1
else
echo"ulimit -a for user $USER" >> $log
ulimit 命令。ulimit用于shell启动进程所占用的资源. –a显示当前所有的资源限制.
ulimit -a >>$log 2>&1
fi
sleep 3;
如果shell最后的进程id不存在,退出shell
if ! ps -p $! > /dev/null; then
exit 1
fi
;;
(stop)
if [ -f $pid ]; then
TARGET_PID=`cat $pid`
先判断进程是否存在,如果存在,第一个if是正常杀死进程,如果失败,”睡”HADOOP_STOP_TIMEOUT的时间。第二个if用kill -9 强行杀死进程。(kill -l可以查看所有的进程通信信号)
if kill -0 $TARGET_PID > /dev/null 2>&1; then
echo stopping $command
kill $TARGET_PID
sleep $HADOOP_STOP_TIMEOUT
if kill -0 $TARGET_PID > /dev/null 2>&1; then
echo "$command did not stop gracefully after $HADOOP_STOP_TIMEOUTseconds: killing with kill -9"
kill -9 $TARGET_PID
fi
else
echo no $command to stop
fi
rm -f $pid
else
echo no $command to stop
fi
;;
(*)
echo $usage
exit 1
;;
esac
总的来说,执行hadoop-env.sh设置环境变量,因为即将启动的JVM是由这个shell启动的,所以这个环境变量会传给JVM。
配置启动单点NameNode或者DataNode的运行环境:除了hadoop-config.sh里面的以外还有HADOOP_LOG_DIR,HADOOP_PID_DIR,HADOOP_IDENT_STRING等等,这些都是与运行这个daemon的本机相关的变量。
最后通过

启动对应的进程,也就是hdfs start namenode命令。其实是调用 bin/hdfs脚本,启动JVM。
hadoop-daemon.sh这个脚本是在每台机器上启动各种JVM前的准备工作,包括设置环境变量什么的,并启动进程。这里要特别注意ssh到各个node之后,环境变量失效的问题。(摘自:http://www.cnblogs.com/zhwl/p/3670997.html)
Step5:start-yarn.shyarn.config.sh
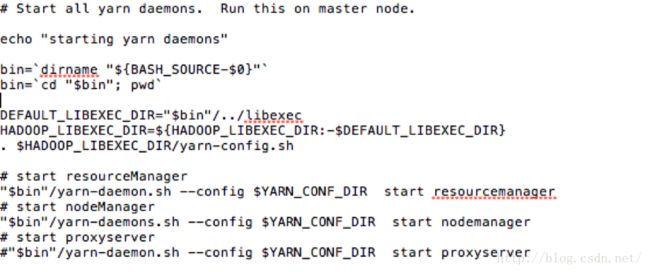
这个脚本是启动所有的yarn进程。
注意到这个脚本里面,没有直接的执行hadoop-config.sh设置环境变量,而是通过执行yarn-config.sh(①把hadoop-config.sh内置于yarn-config.sh内执行,如果hadoop-config.sh在三个环境变量的libexec目录下就执行(避免了环境变量设置乱的问题。),如果这三个目录下都没有则 报错)来设置环境变量。
②然后是引入MALLOC_ARENA_MAXZ这个环境变量。默认是4,可以设置为你想要的值。如果设置的值比较小,会限制memory arenas 的数目和虚拟内存,而(非大型生成环境下)不会显著使性能降低。glibc为了分配内存的性能的问题,使用了很多叫做arena的memorypool,缺省配置在64bit下面是每一个arena为64M,一个进程可以最多有 cores * 8个arena。假设你的机器是4核的,那么最多可以有4 * 8 = 32个arena,也就是使用32 * 64 =2048M内存。(摘自:http://blog.csdn.net/chen19870707/article/details/43202679.目前没对这块有深入了解。)
③ 检查yarn-config后面是否参数为第一个参数为—config和--hosts的情况。(对应的,分别设置YARN_CONF_DIR和YARN_SLAVES这两个环境变量。)
最后是先后执行resourceManager,nodeManager和proxyserver.其中,resourceManager和proxyserver是通过yarn-daemon.sh启动的,nodeManager.sh是通过yarn-daemons.sh启动。
Step6:yarn-daemon.shyarn-daemons.sh
跟hadoop-daemon.sh和hadoop-daemons.sh类似,也都前置执行yarn-config.sh(设置环境变量等。)
和hadoop-daemon.sh类似,不过把HADOOP_PID_DIR等环境变量变为YARN_PID_DIR。
下面是yarn-daemon.sh最后的代码(我这里没有把stop的放在内,主要分析的是start。)
case $startStop in
(start)
如果第三/五个参数为start,则执行下面的语句。
[-w "$HADOOP_PID_DIR" ] || mkdir -p "$HADOOP_PID_DIR"
如果HADOOP_PID_DIR没有写权限(不可写),则创建。
if [ -f $pid ]; then
if kill -0 `cat $pid` >/dev/null 2>&1; then
kill -0 是测试指定的PID是否存在,2>&1是把stderr和stdout定向到一起 /dev/null。如果存在,会提示提示需要先关闭才能启动,并退出shell。
echo $command running as process `cat $pid`. Stop it first.
exit 1
fi
fi
if [ "$HADOOP_MASTER" != "" ]; then
echo rsync from$HADOOP_MASTER
rsync是类unix系统下的数据镜像备份工具,从软件的命名上就可以看出来了——remote sync。
rsync -a -essh --delete --exclude=.svn --exclude='logs/*' --exclude='contrib/hod/logs/*'$HADOOP_MASTER/ "$HADOOP_PREFIX"
fi
日志文件备份
hadoop_rotate_log $log
echo starting $command, logging to $log
cd "$HADOOP_PREFIX"
case $command in
namenode|secondarynamenode|datanode|journalnode|dfs|dfsadmin|fsck|balancer|zkfc)
if [ -z "$HADOOP_HDFS_HOME" ]; then
hdfsScript="$HADOOP_PREFIX"/bin/hdfs
else
hdfsScript="$HADOOP_HDFS_HOME"/bin/hdfs
fi
nohup命令是登出远程计算机后继续执行任务,nice命令用于以指定的进程调度优先级启动其他的程序。来自:http://man.linuxde.net/nice
nohup nice -n $HADOOP_NICENESS $hdfsScript --config$HADOOP_CONF_DIR $command "$@" > "$log" 2>&1 "$log" 2>&1 < /dev/null &
;;
esac
echo $! > $pid
$!为此shell最后运行的process的ID
sleep 1
head "$log"
# capture theulimit output
获取文件系统与程序的限制关系的输出
if [ "true" = "$starting_secure_dn" ]; then
echo "ulimit -a for secure datanode user$HADOOP_SECURE_DN_USER" >> $log
# capture theulimit info for the appropriate user
su –是不仅将用户身份切换,而且还把shell环境也切换。切换了shell环境,PATH的环境变量才有效(~/.bash_profile或者~/.profile)
su--shell=/bin/bash $HADOOP_SECURE_DN_USER -c 'ulimit -a' >> $log2>&1
elif [ "true" = "$starting_privileged_nfs" ]; then
echo "ulimit -a for privileged nfs user$HADOOP_PRIVILEGED_NFS_USER" >> $log
su--shell=/bin/bash $HADOOP_PRIVILEGED_NFS_USER -c 'ulimit -a' >> $log2>&1
else
echo"ulimit -a for user $USER" >> $log
ulimit 命令。ulimit用于shell启动进程所占用的资源. –a显示当前所有的资源限制.
ulimit -a >>$log 2>&1
fi
sleep 3;
如果shell最后的进程id不存在,退出shell
if ! ps -p $! > /dev/null; then
exit 1
fi
;;
(stop)
if [ -f $pid ]; then
TARGET_PID=`cat $pid`
先判断进程是否存在,如果存在,第一个if是正常杀死进程,如果失败,”睡”HADOOP_STOP_TIMEOUT的时间。第二个if用kill -9 强行杀死进程。(kill -l可以查看所有的进程通信信号)
if kill -0 $TARGET_PID > /dev/null 2>&1; then
echo stopping $command
kill $TARGET_PID
sleep $HADOOP_STOP_TIMEOUT
if kill -0 $TARGET_PID > /dev/null 2>&1; then
echo "$command did not stop gracefully after $HADOOP_STOP_TIMEOUTseconds: killing with kill -9"
kill -9 $TARGET_PID
fi
else
echo no $command to stop
fi
rm -f $pid
else
echo no $command to stop
fi
;;
(*)
echo $usage
exit 1
;;
esac
这里的分析基本和hadoop-daemon.sh是一样的,不再赘述了。不过这里有一点不同:start-dfs.sh中,都是通过hadoop-daemons.sh里调用hadoop-daemon.sh来启动进程。而start-yarn.sh是分yarn-daemon.sh和yarn-daemons.sh来分别启动ResourceManager和nodeManger的。
# start nodeManager
"$bin"/yarn-daemons.sh--config $YARN_CONF_DIR startnodemanager
(start-yarn.sh)
# Run a Yarn command on all slave hosts.
exec "$bin/slaves.sh" --config$YARN_CONF_DIR cd "$HADOOP_YARN_HOME" \;"$bin/yarn-daemon.sh" --config $YARN_CONF_DIR "$@"
(yarn-daemons.sh)和启动DataNode类似,也是通过SSH到每台slave节点上之后,执行yarn-daemon.sh启动对应的NodeManager。(注意,这里也推荐设置相应的环境变量)
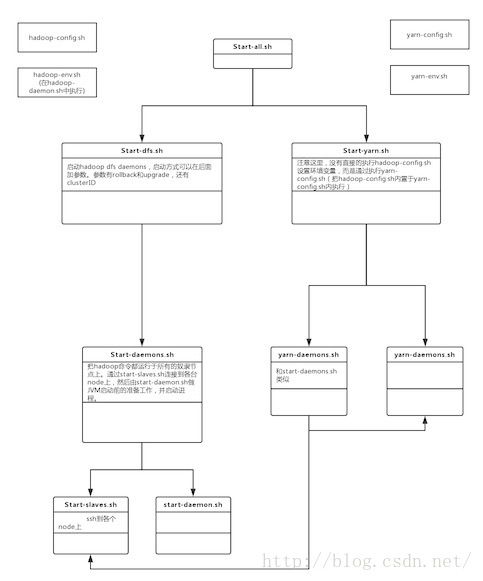
总结:
总的来说,整个启动过程是从上到下分层次进行的。从整个集群级别的配置,单台机器的配置和单个JVM的配置。详情见下面的流程图。
ps:本人原创文章,如需转载请联系我qq:314913739。