利用PySpark进行迁移学习的多类图像分类
在本文中,我们将演示计算机视觉问题,它具有结合两种最先进技术的能力:深度学习和Apache Spark。我们将利用深度学习管道的强大功能来解决多类图像分类问题。
PySpark 是 Spark 为 Python 开发者提供的 API。
PySpark 提供的类
1、pyspark.SparkConf
pyspark.SparkConf 类提供了对一个 Spark 应用程序配置的操作方法。用于将各种Spark参数设置为键值对。2、pyspark.SparkContext
pyspark.SparkContext 类提供了应用与 Spark 交互的主入口点,表示应用与 Spark 集群的连接,基于这个连接,应用可以在该集群上创建 RDD 和 广播变量 (pyspark.Broadcast)。3、pyspark.SparkFiles
SparkFiles 只包含类方法,开发者不应创建 SparkFiles 类的实例。4、pyspark.RDD
first() 是 pyspark.RDD 类提供的方法,返回 RDD 的第一个元素。aggregate() 方法使用给定的组合函数和中性“零值,先聚合每个分区的元素,然后再聚合所有分区的结果。
cache() 使用默认存储级别(MEMORY_ONLY)对此 RDD 进行持久化。
collect() 返回一个列表,包含此 RDD 中所有元素 。
5、pyspark.Accumulator
一种“只允许添加”的共享变量,Spark 任务只能向其添加值。6、pyspark.Broadcast
Spark 提供了两种共享变量:广播变量 和 累加器,pyspark.Broadcast 类提供了对广播变量的操作方法。7、pyspark.Accumulator
pyspark.Accumulator 提供了对累加器变量的操作方法。 累加器是仅仅被相关操作累加的变量,因此可以在并行中被有效地支持。迁移学习
深度学习中在计算机视觉任务和自然语言处理任务中将预训练的模型作为新模型的起点是一种常用的方法,通常这些预训练的模型在开发神经网络的时候已经消耗了巨大的时间资源和计算资源,迁移学习可以将已习得的强大技能迁移到相关的的问题上。迁移学习是一种机器学习的方法,指的是一个预训练的模型被重新用在另一个任务中。迁移学习与多任务学习以及概念飘移这些问题相关,它不是一个专门的机器学习领域。
然而,迁移学习在某些深度学习问题中是非常受欢迎的,例如在具有大量训练深度模型所需的资源或者具有大量的用来预训练模型的数据集的情况。仅在第一个任务中的深度模型特征是泛化特征的时候,迁移学习才会起作用。 深度学习中的这种迁移被称作归纳迁移。就是通过使用一个适用于不同但是相关的任务的模型,以一种有利的方式缩小可能模型的搜索范围。
迁移学习的主要方法
- 1、 开发模型的方法
- 2、 预训练模型的方法
开发模型的方法
选择源任务。你必须选择一个具有丰富数据的相关的预测建模问题,原任务和目标任务的输入数据、输出数据以及从输入数据和输出数据之间的映射中学到的概念之间有某种关系,开发源模型。然后,你必须为第一个任务开发一个精巧的模型。这个模型一定要比普通的模型更好,以保证一些特征学习可以被执行。重用模型。然后,适用于源任务的模型可以被作为目标任务的学习起点。这可能将会涉及到全部或者部分使用第一个模型,这依赖于所用的建模技术。调整模型。模型可以在目标数据集中的输入-输出对上选择性地进行微调,以让它适应目标任务。预训练模型方法
选择源模型。一个预训练的源模型是从可用模型中挑选出来的。很多研究机构都发布了基于超大数据集的模型,这些都可以作为源模型的备选者。重用模型。选择的预训练模型可以作为用于第二个任务的模型的学习起点。这可能涉及到全部或者部分使用与训练模型,取决于所用的模型训练技术。调整模型。模型可以在目标数据集中的输入-输出对上选择性地进行微调,以让它适应目标任务。第二种类型的迁移学习在深度学习领域比较常用。深度学习管道是一个高级深度学习框架,通过Spark MLlib Pipelines API 促进常见的深度学习工作流程。它目前支持TensorFlow和Keras以及TensorFlow后端。
该库来自Databricks,并利用Spark的两个最强大的方面:
本着Spark和Spark MLlib的精神,它提供了易于使用的API,可以在极少数代码行中实现深度学习。
它使用Spark强大的分布式引擎来扩展大规模数据集的深度学习。
转移学习
转移学习一般是机器学习中的一种技术,侧重于在解决一个问题时保存所获得的知识(权重和偏见),并进一步将其应用于不同但相关的问题。
深度学习管道提供实用程序来对图像执行传输学习,这是开始使用深度学习的最快方法之一。借助Featurizer的概念, Deep Learning Pipelines可以在Spark-Cluster上实现快速转移学习。现在,它为转移学习提供了以下神经网络:
InceptionV3
Xception
ResNet50
VGG16
VGG19
出于演示目的,我们将仅使用InceptionV3模型。您可以从此处阅读此模型的技术细节。
以下示例将Spark中的InceptionV3模型和多项逻辑回归组合在一起。
Deep Learning Pipelines中的一个名为DeepImageFeaturizer的效用函数会自动剥离预训练神经网络的最后一层,并使用所有前一层的输出作为逻辑回归算法的特征。
数据集
孟加拉语脚本有十个数字(字母或符号表示从0到9的数字)。使用位置基数为10的数字系统在孟加拉语中写入大于9的数字。

让我们看看下面我们在十个文件夹中的内容。为了演示目的,我重命名下面显示的相应类标签的每个图像。

图2:孟加拉语手写数字
首先,我们将所有图像加载到SparkData Frame。然后我们建立模型并训练它。之后,我们将评估我们训练模型的性能。加载图片
数据集(从0到9)包含近500个手写的Bangla数字(每个类别50个图像)。在这里,我们使用目标列手动将每个图像加载到spark数据框架中。加载整个数据集后,我们将训练集和最终测试集随机分成8:2比例。
我们的目标是使用训练数据集训练模型,最后使用测试数据集评估模型的性能。
# necessary import from pyspark.sql import SparkSessionfrom pyspark.ml.image import ImageSchemafrom pyspark.sql.functions import litfrom functools import reduce# create a spark sessionspark = SparkSession.builder.appName(‘DigitRecog’).getOrCreate()# loaded imagezero = ImageSchema.readImages("0").withColumn("label", lit(0))one = ImageSchema.readImages("1").withColumn("label", lit(1))two = ImageSchema.readImages("2").withColumn("label", lit(2))three = ImageSchema.readImages("3").withColumn("label", lit(3))four = ImageSchema.readImages("4").withColumn("label", lit(4))five = ImageSchema.readImages("5").withColumn("label", lit(5))six = ImageSchema.readImages("6").withColumn("label", lit(6))seven = ImageSchema.readImages("7").withColumn("label", lit(7))eight = ImageSchema.readImages("8").withColumn("label", lit(8))nine = ImageSchema.readImages("9").withColumn("label", lit(9))dataframes = [zero, one, two, three,four, five, six, seven, eight, nine]# merge data framedf = reduce(lambda first, second: first.union(second), dataframes)# repartition dataframe df = df.repartition(200)# split the data-frametrain, test = df.randomSplit([0.8, 0.2], 42)
from pyspark.sql import SparkSession
from pyspark.ml.image import ImageSchema
from pyspark.sql.functions import lit
from functools import reduce
# create a spark session
spark = SparkSession.builder.appName(‘DigitRecog’).getOrCreate()
# loaded image
zero = ImageSchema.readImages("0").withColumn("label", lit(0))
one = ImageSchema.readImages("1").withColumn("label", lit(1))
two = ImageSchema.readImages("2").withColumn("label", lit(2))
three = ImageSchema.readImages("3").withColumn("label", lit(3))
four = ImageSchema.readImages("4").withColumn("label", lit(4))
five = ImageSchema.readImages("5").withColumn("label", lit(5))
six = ImageSchema.readImages("6").withColumn("label", lit(6))
seven = ImageSchema.readImages("7").withColumn("label", lit(7))
eight = ImageSchema.readImages("8").withColumn("label", lit(8))
nine = ImageSchema.readImages("9").withColumn("label", lit(9))
dataframes = [zero, one, two, three,four,
five, six, seven, eight, nine]
# merge data frame
df = reduce(lambda first, second: first.union(second), dataframes)
# repartition dataframe
df = df.repartition(200)
# split the data-frame
train, test = df.randomSplit([0.8, 0.2], 42)
df.printSchema()root |-- image: struct (nullable = true) | |-- origin: string (nullable = true) | |-- height: integer (nullable = false) | |-- width: integer (nullable = false) | |-- nChannels: integer (nullable = false) | |-- mode: integer (nullable = false) | |-- data: binary (nullable = false) |-- label: integer (nullable = false)
|-- image: struct (nullable = true)
| |-- origin: string (nullable = true)
| |-- height: integer (nullable = false)
| |-- width: integer (nullable = false)
| |-- nChannels: integer (nullable = false)
| |-- mode: integer (nullable = false)
| |-- data: binary (nullable = false)
|-- label: integer (nullable = false)
我们还可以使用.toPandas()将Spark-DataFrame转换为Pandas-DataFrame。
模型训练
在这里,我们将Spark节点中的InceptionV3模型和逻辑回归结合起来。所述DeepImageFeaturizer自动剥离一个预训练神经网络的最后一层,并使用从所有的前面的层的输出作为特征在于用于逻辑回归算法。
由于逻辑回归是一种简单快速的算法,因此这种转移学习训练可以快速收敛。
from pyspark.ml.evaluation import MulticlassClassificationEvaluatorfrom pyspark.ml.classification import LogisticRegressionfrom pyspark.ml import Pipelinefrom sparkdl import DeepImageFeaturizer# model: InceptionV3# extracting feature from imagesfeaturizer = DeepImageFeaturizer(inputCol="image", outputCol="features", modelName="InceptionV3")# used as a multi class classifierlr = LogisticRegression(maxIter=5, regParam=0.03, elasticNetParam=0.5, labelCol="label")# define a pipeline modelsparkdn = Pipeline(stages=[featurizer, lr])spark_model = sparkdn.fit(train) # start fitting or trainingimport MulticlassClassificationEvaluator
from pyspark.ml.classification import LogisticRegression
from pyspark.ml import Pipeline
from sparkdl import DeepImageFeaturizer
# model: InceptionV3
# extracting feature from images
featurizer = DeepImageFeaturizer(inputCol="image",
outputCol="features",
modelName="InceptionV3")
# used as a multi class classifier
lr = LogisticRegression(maxIter=5, regParam=0.03,
elasticNetParam=0.5, labelCol="label")
# define a pipeline model
sparkdn = Pipeline(stages=[featurizer, lr])
spark_model = sparkdn.fit(train) # start fitting or training评估
现在,是时候评估模型性能了。 我们现在想要评估测试数据集上的四个评估指标,例如F1-score,精度,召回,准确度。
from pyspark.ml.evaluation import MulticlassClassificationEvaluator# evaluate the model with test setevaluator = MulticlassClassificationEvaluator() tx_test = spark_model.transform(test)print('F1-Score ', evaluator.evaluate(tx_test, {evaluator.metricName: 'f1'}))print('Precision ', evaluator.evaluate(tx_test, {evaluator.metricName: 'weightedPrecision'}))print('Recall ', evaluator.evaluate(tx_test, {evaluator.metricName: 'weightedRecall'}))print('Accuracy ', evaluator.evaluate(tx_test, {evaluator.metricName: 'accuracy'}))import MulticlassClassificationEvaluator
# evaluate the model with test set
evaluator = MulticlassClassificationEvaluator()
tx_test = spark_model.transform(test)
print('F1-Score ', evaluator.evaluate(tx_test,
{evaluator.metricName: 'f1'}))
print('Precision ', evaluator.evaluate(tx_test,
{evaluator.metricName: 'weightedPrecision'}))
print('Recall ', evaluator.evaluate(tx_test,
{evaluator.metricName: 'weightedRecall'}))
print('Accuracy ', evaluator.evaluate(tx_test,
{evaluator.metricName: 'accuracy'}))F1-Score 0.8111782234361806Precision 0.8422058244785519Recall 0.8090909090909091Accuracy 0.8090909090909091
Precision 0.8422058244785519
Recall 0.8090909090909091
Accuracy 0.8090909090909091混淆矩阵
在这里,我们将使用混淆矩阵总结分类模型的性能。
import matplotlib.pyplot as pltimport numpy as npimport itertoolsdef plot_confusion_matrix(cm, classes, normalize=False, title='Confusion matrix', cmap=plt.cm.GnBu): plt.imshow(cm, interpolation='nearest', cmap=cmap) plt.title(title) tick_marks = np.arange(len(classes)) plt.xticks(tick_marks, classes, rotation=45) plt.yticks(tick_marks, classes) fmt = '.2f' if normalize else 'd' thresh = cm.max() / 2. for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])): plt.text(j, i, format(cm[i, j], fmt), horizontalalignment="center", color="white" if cm[i, j] > thresh else "black") plt.tight_layout() plt.ylabel('True label') plt.xlabel('Predicted label')as plt
import numpy as np
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.GnBu):
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]),
range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
为此,我们需要先将Spark-DataFrame转换为Pandas-DataFrame,然后使用true和predict标签调用Confusion Matrix。
from sklearn.metrics import confusion_matrixy_true = tx_test.select("label")y_true = y_true.toPandas()y_pred = tx_test.select("prediction")y_pred = y_pred.toPandas()cnf_matrix = confusion_matrix(y_true, y_pred,labels=range(10))import confusion_matrix
y_true = tx_test.select("label")
y_true = y_true.toPandas()
y_pred = tx_test.select("prediction")
y_pred = y_pred.toPandas()
cnf_matrix = confusion_matrix(y_true, y_pred,labels=range(10))
让我们想象一下混淆矩阵
import seaborn as snssns.set_style("darkgrid")plt.figure(figsize=(7,7))plt.grid(False)# call pre defined functionplot_confusion_matrix(cnf_matrix, classes=range(10))as sns
sns.set_style("darkgrid")
plt.figure(figsize=(7,7))
plt.grid(False)
# call pre defined function
plot_confusion_matrix(cnf_matrix, classes=range(10))
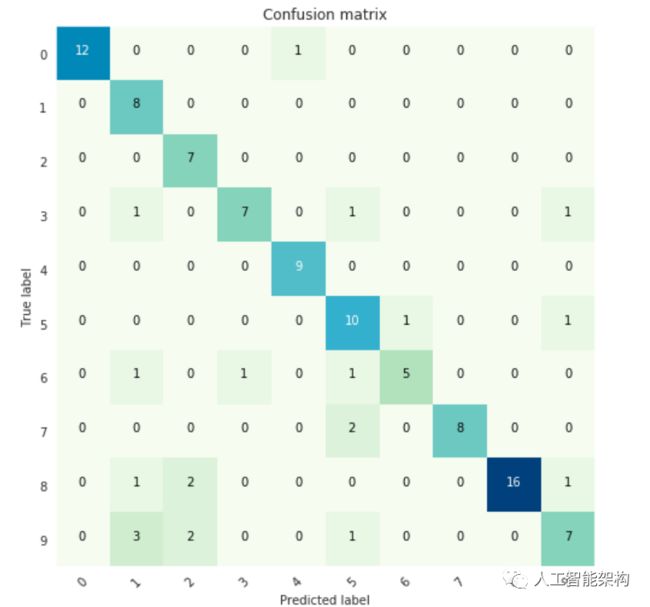
图 3:10个孟加拉数字的混淆矩阵(0到9)
分类报告
在这里,我们还可以通过评估矩阵获得每个类别的分类报告。
from sklearn.metrics import classification_reporttarget_names = ["Class {}".format(i) for i in range(10)]print(classification_report(y_true, y_pred, target_names = target_names))import classification_report
target_names = ["Class {}".format(i) for i in range(10)]
print(classification_report(y_true, y_pred,
target_names = target_names))
它将证明每个类标签预测的模型性能要好得多。
precision recall f1-score support Class 0 1.00 0.92 0.96 13 Class 1 0.57 1.00 0.73 8 Class 2 0.64 1.00 0.78 7 Class 3 0.88 0.70 0.78 10 Class 4 0.90 1.00 0.95 9 Class 5 0.67 0.83 0.74 12 Class 6 0.83 0.62 0.71 8 Class 7 1.00 0.80 0.89 10 Class 8 1.00 0.80 0.89 20 Class 9 0.70 0.54 0.61 13 micro avg 0.81 0.81 0.81 110 macro avg 0.82 0.82 0.80 110weighted avg 0.84 0.81 0.81 1100 1.00 0.92 0.96 13
Class 1 0.57 1.00 0.73 8
Class 2 0.64 1.00 0.78 7
Class 3 0.88 0.70 0.78 10
Class 4 0.90 1.00 0.95 9
Class 5 0.67 0.83 0.74 12
Class 6 0.83 0.62 0.71 8
Class 7 1.00 0.80 0.89 10
Class 8 1.00 0.80 0.89 20
Class 9 0.70 0.54 0.61 13
micro avg 0.81 0.81 0.81 110
macro avg 0.82 0.82 0.80 110
weighted avg 0.84 0.81 0.81 110
ROC AUC Score
让我们也找到这个模型的ROC AUC得分点。我从这里使用了以下代码。
from sklearn.metrics import roc_curve, auc, roc_auc_scorefrom sklearn.preprocessing import LabelBinarizerdef multiclass_roc_auc_score(y_test, y_pred, average="macro"): lb = LabelBinarizer() lb.fit(y_test) y_test = lb.transform(y_test) y_pred = lb.transform(y_pred) return roc_auc_score(y_test, y_pred, average=average)print('ROC AUC score:', multiclass_roc_auc_score(y_true,y_pred))import roc_curve, auc, roc_auc_score
from sklearn.preprocessing import LabelBinarizer
def multiclass_roc_auc_score(y_test, y_pred, average="macro"):
lb = LabelBinarizer()
lb.fit(y_test)
y_test = lb.transform(y_test)
y_pred = lb.transform(y_pred)
return roc_auc_score(y_test, y_pred, average=average)
print('ROC AUC score:', multiclass_roc_auc_score(y_true,y_pred))
它得分0.901.
预测样本
让我们看看它的一些预测,与真实标签的比较。
# all columns after transformationsprint(tx_test.columns)# see some predicted outputtx_test.select('image', "prediction", "label").show()
print(tx_test.columns)
# see some predicted output
tx_test.select('image', "prediction", "label").show()
结果如下
['image', 'label', 'features', 'rawPrediction', 'probability', 'prediction']+------------------+----------+--------+| image |prediction| label |+------------------+----------+--------+|[file:/home/i...| 1.0| 1||[file:/home/i...| 8.0| 8||[file:/home/i...| 9.0| 9||[file:/home/i...| 1.0| 8||[file:/home/i...| 1.0| 1||[file:/home/i...| 1.0| 9||[file:/home/i...| 0.0| 0||[file:/home/i...| 2.0| 9||[file:/home/i...| 8.0| 8||[file:/home/i...| 9.0| 9||[file:/home/i...| 0.0| 0||[file:/home/i...| 4.0| 0||[file:/home/i...| 5.0| 9||[file:/home/i...| 1.0| 1||[file:/home/i...| 9.0| 9||[file:/home/i...| 9.0| 9||[file:/home/i...| 1.0| 1||[file:/home/i...| 1.0| 1||[file:/home/i...| 9.0| 9||[file:/home/i...| 3.0| 6|+--------------------+----------+-----+only showing top 20 rows'label', 'features', 'rawPrediction',
'probability', 'prediction']
+------------------+----------+--------+
| image |prediction| label |
+------------------+----------+--------+
|[file:/home/i...| 1.0| 1|
|[file:/home/i...| 8.0| 8|
|[file:/home/i...| 9.0| 9|
|[file:/home/i...| 1.0| 8|
|[file:/home/i...| 1.0| 1|
|[file:/home/i...| 1.0| 9|
|[file:/home/i...| 0.0| 0|
|[file:/home/i...| 2.0| 9|
|[file:/home/i...| 8.0| 8|
|[file:/home/i...| 9.0| 9|
|[file:/home/i...| 0.0| 0|
|[file:/home/i...| 4.0| 0|
|[file:/home/i...| 5.0| 9|
|[file:/home/i...| 1.0| 1|
|[file:/home/i...| 9.0| 9|
|[file:/home/i...| 9.0| 9|
|[file:/home/i...| 1.0| 1|
|[file:/home/i...| 1.0| 1|
|[file:/home/i...| 9.0| 9|
|[file:/home/i...| 3.0| 6|
+--------------------+----------+-----+
only showing top 20 rows
结论
虽然我们使用了 ImageNet 重量,但我们的模型非常有希望识别手写数字。此外,我们还没有执行任何图像处理任务以实现更好的通用化。此外,与ImageNet数据集相比,该模型仅使用极少量的数据进行训练。
在很高的层次上,每个Spark应用程序都包含一个驱动程序,可以在集群上启动各种并行操作。驱动程序包含我们的应用程序的主要功能,并在群集上定义分布式数据集,然后对它们应用操作。 由于这是一个独立的应用程序,我们首先将应用程序链接到Spark,然后我们在程序中导入了Spark包,并创建了一个由SparkSession启动的SparkContext。虽然我们已经在一台机器上工作,但我们可以将同一个shell连接到一个集群来并行训练数据。 但是,你可以从 这里 获得今天演示的源代码,你也可以在 GitHub上 关注我的未来代码更新。 接下来,我们将看看使用Spark的Distributed Hyperparameter Tuning,我们将尝试自定义Keras模型和一些新的具有挑战性的示例。
参考:
1、Databricks: https://docs.databricks.com/applications/deep-learning/index.html?source=post_page2、Apache Spark: https://spark.apache.org/docs/latest/api/python/index.html?source=post_page
3、本文中演示的源码:
https://github.com/iphton/Transfer-Learning-PySpark
长按订阅更多精彩▼

如有收获,点个在看,诚挚感谢