大数据之hadoop 环境搭建从零开始——WordCount词频计数入门实战训练
这里的前提是要先安装一个干净的CentOS系统,我这里用的是CentOS6.6,安装教程参考另一篇博客:https://blog.csdn.net/gaofengyan/article/details/85054337
目录
hadoop 环境搭建
2.3 Hadoop 集群搭建
1. 安装hadoop
2. 格式化与启动
3. hdfs 命令
4. 安装eclipse
5.hdfs分布式 wordcount 单词计数作业 测试
hadoop 环境搭建
注意下面Linux环境搭建和jdk安装的部分顺序,有提示(为了方便,少操作步骤,安装完jdk再克隆就少两次jdk安装)。
1. 概念
集群概念图:我们将项目A整体按照规划好的方式拆分多个模块到不同的服务器部署,这些服务器的网址是受到保护的,为了安全,不向外泄露。因此,客户为了访问到项目A的所有内容又不能分不同网址访问不同服务器上的内容,所以用一个虚拟的PC统一管理项目的发布地址,并做安全防护,用户就可以通过中间虚拟PC的链接访问整个内容。而所有的部署了项目服务器就形成一个集群。
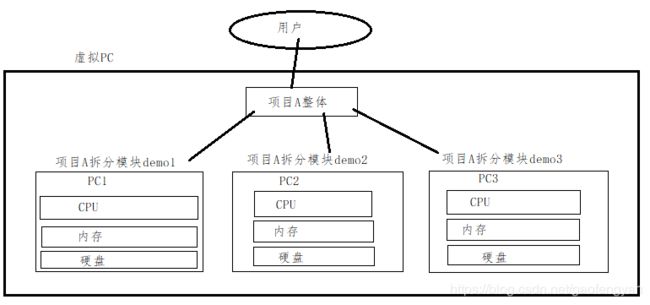
1.1 理论
1)集群:指的是多台设备构成一个完整的应用,构成该应用的这些设备就构成了一个集群。
2)Hadoop:只是集群中的一种,Hadoop集群本身也包含两种集群。
Hadoop=hdfs + 运算框架。
Hadoop的运算框架有两种:mapreduce(第一代运算框架)和yarn(第二代运算框架)
3)hdfs:
hdfs = hadoop dfs ; d->分布式,fs->filesystem(文件系统,物理存储)
4)mapreduce
hadoop第一代运算框架:hadoop的底层运算框架。
5)yarn
hadoop第二代运算框架:yarn 必须在第一代运算框架启动后才能使用。
1.2 术语
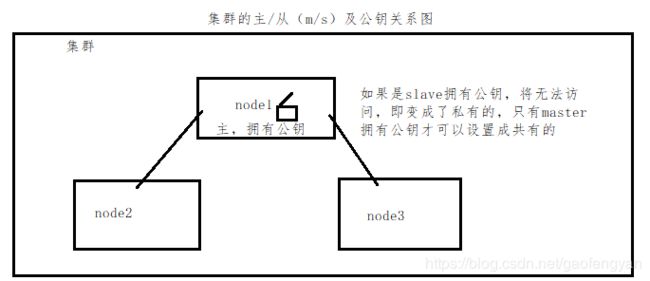
1)m/s
m/s指的是master(主)/slave(从)结构,即主从结构
一个管理者(master)多个工作者(slave)。master负责分配与派发任务,slave负责执行任务。
在hadoop配置和命令中,主机是namenode,从机是datanode。
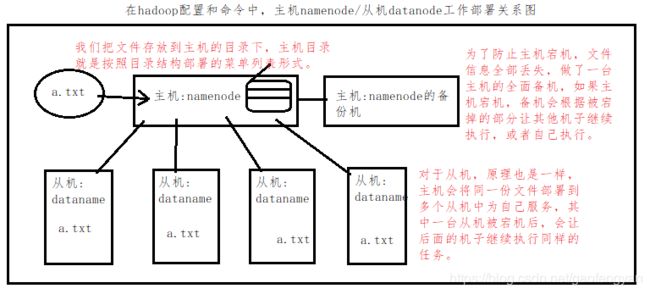
2)公钥
公钥是一对加密代码(MD5加密文件),A节点将A的公钥发送给其他设备后,A节点就能免密登陆其他设备。
3)免密登陆
集群节点之间通信不需要输入密码也能互相登陆发送信息。实现方式是通过公钥实现的。
2. Hadoop集群搭建
2.1 集群配置方案
以下是集群设备配置方案(这里我给的是一个示例,以三台设备来实战练习):
角色 网络用户名 用户名 用户组 ip 子网掩码 网关 DNS
master node1 hduser hadoop 192.168.3.55 255.255.255.0 192.168.3.1 192.168.3.1
slave node2 hduser hadoop 192.168.3.56 255.255.255.0 192.168.3.1 192.168.3.1
slave node3 hduser hadoop 192.168.3.57 255.255.255.0 192.168.3.1 192.168.3.1
2.2 Linux环境搭建
1)创建用户与用户组(root账号用户)
用户:hduser 用户组:hadoop
[liang@localhost ~]$ su root
密码:
[root@localhost liang]$ groupadd hadoop
[root@localhost liang]$ useradd -g hadoop hduser
[root@localhost liang]$ passwd hduser
更改用户 hduser 的密码 。
新的 密码:
无效的密码: 过于简单化/系统化
无效的密码: 过于简单
重新输入新的 密码:
passwd: 所有的身份验证令牌已经成功更新。
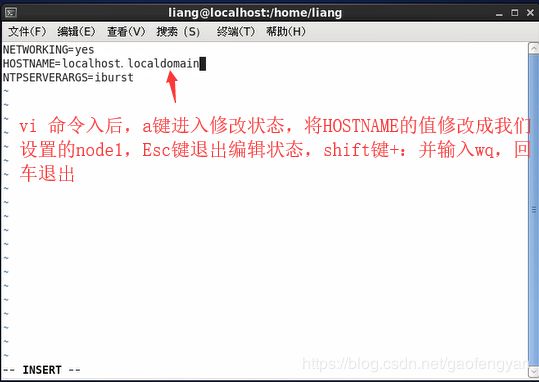
[root@localhost liang]# 2)修改网络用户名,所在网卡位置:(/etc/sysconfig/network)
[root@localhost liang]$ cat /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=localhost.localdomain
NTPSERVERARGS=iburst
[root@localhost liang]$ vi /etc/sysconfig/network修改hostname 值为 node1
3)修改本地主机名(网络用户名)解析记录
为了更好学习使用集群,我们把Windows主机网络连接更改成静态绑定ip,使用局域网,这样我们可以访问外网,但外网不能访问内部,绑定ip如下:
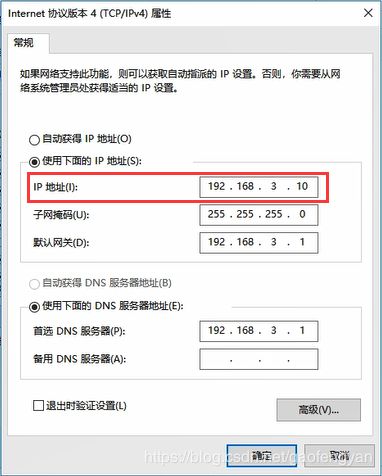
打开hosts配置文件
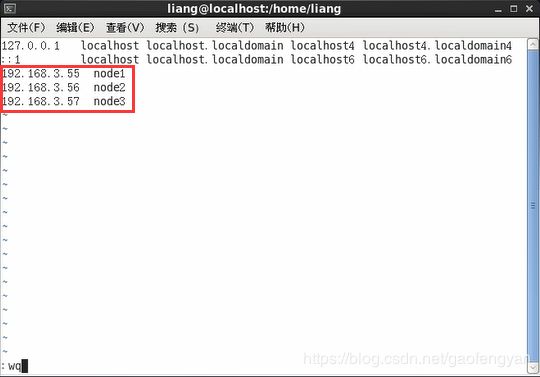
$>vi /etc/hosts
在文件中增加如下内容:
192.168.3.55 node1
192.168.3.56 node2
192.168.3.57 node3
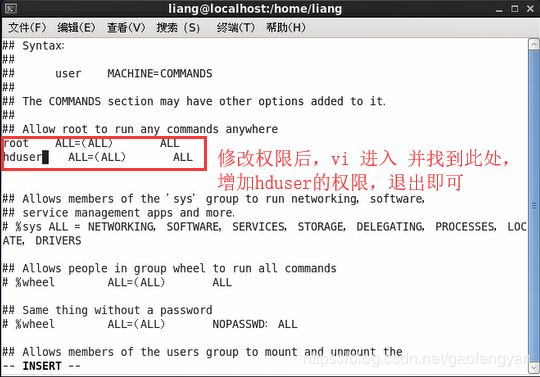
4)更改用户 hduser 拥有超级用户角色( /etc/sudoers )
查看权限: $>ls -l /etc/sudoers -r--r----- 权限码是440
$>ls -l /etc/sudoers -r--r----- 权限码是440
① 修改sudoers权限为可变编辑
$>chmod 777 /etc/sudoers
② 打开sudoers文件增加内容:
$>vi /etc/sudoers
③ 增加内容:
在root ALL=(ALL) ALL 下面增加 hduser ALL=(ALL) ALL
④ 增加完以上内容再将sudoers权限改回440,一定要改回去,不改回去整改系统都会崩掉不能用。
$>chmod 440 /etc/sudoers
5)配置ip 子网掩码 网关 dns
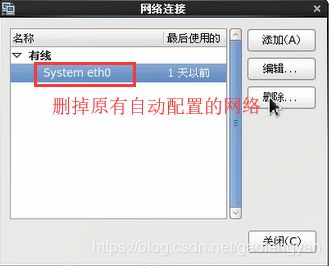
删除完后添加,新建:
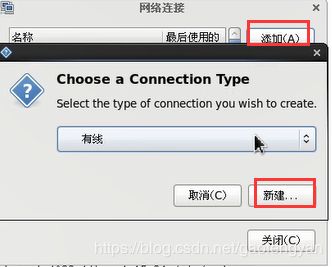
更改连接名字,方法改为手动,添加自动分配的ip,子网掩码,网关,DNS服务器,更改好后应用,退出联网。
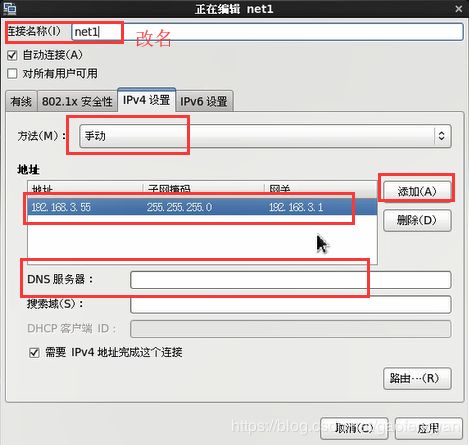
此时ip地址还没有更改:
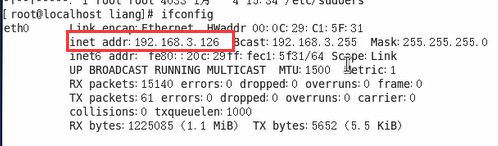
解决方法:
6)jdk 安装 root账号(/usr/java)
卸载已安装的jdk
解压 tar
配置环境变量
生效配置文件
------------------------------------------------------------------jdk安装开始----------------------------------------------------------------------------
A. jdk安装及配置
1. yum卸载系统以有(默认安装)安装的jdk
$>yum list installed | grep java 查看系统内自带的Java-jdk程序

$>yum remove -y 程序名称
2. 获取jdk的 tar安装包 jdk-8u171-linux-x64.tar.gz 复制到Linux桌面
3. 创建目录 $>mkdir /usr/java ![]()
4. 将解压到 /usr/java 路径下
$>tar -zxvf /(补全路径)/ jdk-8u**.tar.gz -C /usr/java/
![]()
B.jdk 配置环境变量(/etc/profile)
① 先打开vi /etc/profile
② 在文档最后追加内容:
export JAVA_HOME=/usr/java/jdk1.8.0_171
export PATH=$JAVA_HOME/bin:$PATH

C.生效环境变量
$>source /etc/profile
D.测试
$>java -version
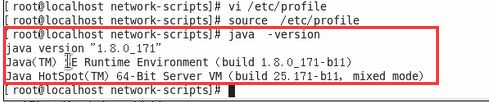 安装成功!
安装成功!
------------------------------------------------------------jdk安装结束---------------------------------------------------------------------------
7)防火墙服务关闭(root)jdk安装完后再关闭
$>service iptables stop
$>chkconfig iptables off

--------------------------------------------------------以上是集群中的每一台都要的配置---------------------------------------------------------
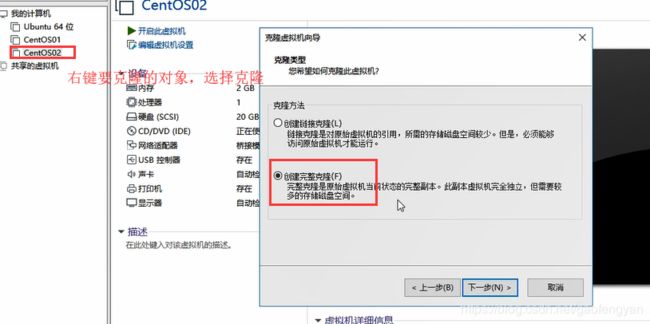
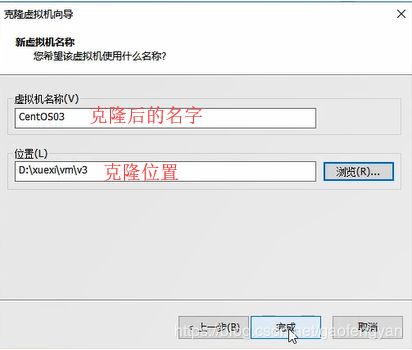
8)克隆两台设备 分别是 CentOS03 , CentOS04
D:\xuexi\vm\v3
D:\xuexi\vm\v4
克隆完启动虚拟机,账户名选择新建的用户名操作:

克隆完后,之前设置的 终端快捷键 和 手动分配的ip,子网掩码,网关,DNS服务器都恢复了初始状态,需要重新设置:
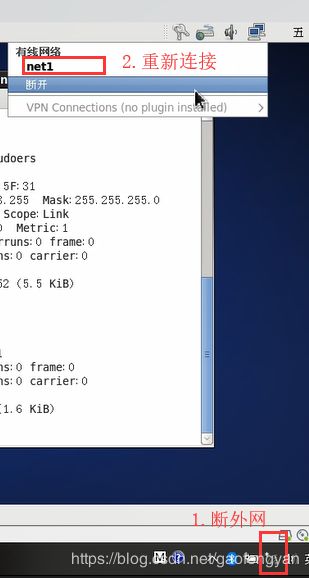
克隆完后一定要再次检查并手动修改node1 node2 node3 的 IP 与网络用户名(如果连不上,先把外网断了,再连接Linux网络,ifconfig后网址更改后再连接外网即可):
1. 克隆完后再检查网络连接:

这里手动更改跟上面的步骤一样:
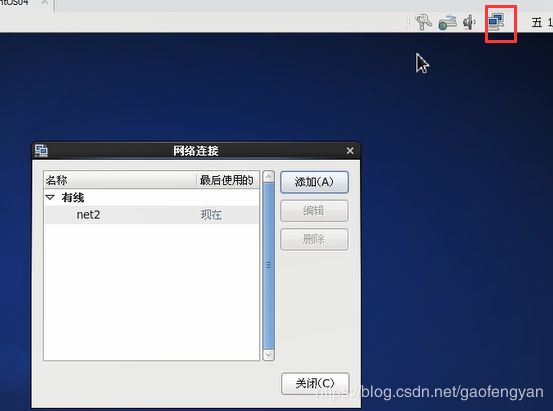
更改完后重新连接网络,再检查一次:

2. 更改好网络配置后,进入克隆的虚拟机,将克隆的系统的用户名node1改为node2 / node3 记得要用该用户(hduser)的超级用户权限进入修改:
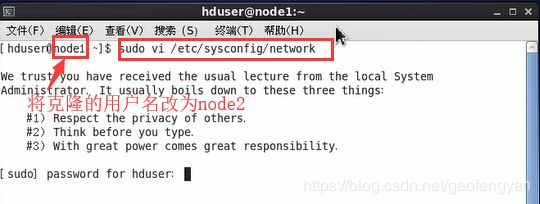 $>sudo vi /etc/sysconfig/network
$>sudo vi /etc/sysconfig/network
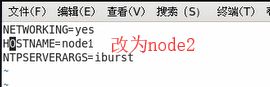
3. 改完之后重启系统:$>sudo reboot
重复上面的操作将另一个克隆的和被克隆的也改过来。删除之前的用户liang:$>sudo userdel liang
9)集群设备之间免密码登陆(hduser账户操作)
a. 在node1上生成公钥
$>ssh-keygen -t rsa
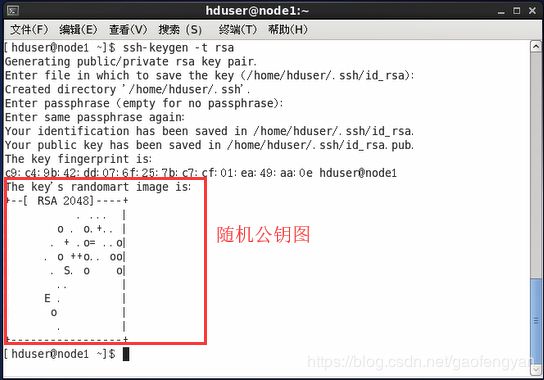
b. 将 node1 的公钥派发给 node2
$>ssh-copy-id node2
c. 将 node1 的公钥派发给 node3
$>ssh-copy-id node3
d. 将 node1 的公钥派发给 node1
$>ssh-copy-id node1
e. 将 node1 的公钥派发给 node1的localhost
$>ssh-copy-id localhost
f. 将 node1 的公钥派发给 node1的127.0.0.1
$>ssh-copy-id 127.0.0.1
h. 测试:ssh node2 / node3..... exit退出

2.3 Hadoop 集群搭建
1. 安装hadoop
1.) 获取hadoop 的 tar安装包并解压(先只安装node1)
2.) 解压到 /home/hduser/下 ,解压后更改文件夹名为hadoop。
//解压到当前用户下
[hduser@node1 ~]$ tar -zxvf /home/hduser/hadoop-2.6.5.tar.gz -C /home/hduser/3.) 解压完后更改包名:
//解压完后更改包名
[hduser@node1 ~]$ mv /home/hduser/hadoop-2.6.5/ /home/hduser/hadoop
4.) 以上步骤完成后我们获取hadoop主目录 /home/hduser/hadoop
[hduser@node1 ~]$ cd /home/hduser/hadoop/5.) 更改hadoop 配置文件(hadoop主目录/etc/hadoop/)其中的配置,在手动配置过程中千万不要有错,不然在格式化后就麻烦了,所有机子都会出问题,严重的就直接重装系统开始做。
![]() 进入hadoop主目录/etc/hadoop/ 后用 ll 查看目录:
进入hadoop主目录/etc/hadoop/ 后用 ll 查看目录:
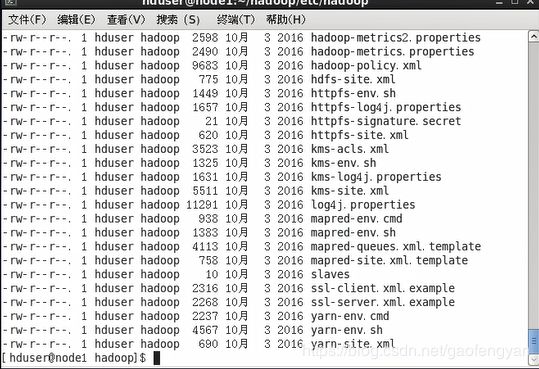
5.1) hadoop-env.sh (hadoop hdfs运行环境文件)
更改配置文件中JAVA_HOME 如下:
[hduser@node1 hadoop]$ vi etc/hadoop/hadoop-env.shexport JAVA_HOME=/usr/java/jdk1.8.0_171

5.2) mapred-env.sh (hadoop mapreduce运算框架运行环境文件)
[hduser@node1 hadoop]$ vi etc/hadoop/mapred-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_171
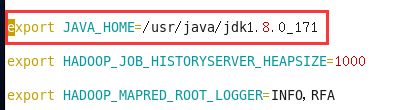
5.3) yarn-env.sh (hadoop yarn预算框架运行环境文件)
[hduser@node1 hadoop]$ vi etc/hadoop/yarn-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_171
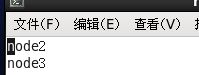
5.4) slaves (工作者节点信息)
[hduser@node1 hadoop]$ vi etc/hadoop/slaves
修改工作者信息如下:
node2
node3
查看:
[hduser@node1 hadoop]$ cat etc/hadoop/slaves
node2
node3
5.5) core-site.xml (hadoop核心配置文件)
fs.defaultFS
hdfs://node1:9000
fs,defaultFS:该属性配置的dfs的访问入口 hdfs:// 这是hdfs文件系统的访问协议
hadoop.tmp.dir
file:/home/hduser/hadoop/tmp
hadoop.tmp.dir:hadoop 本地临时文件夹 file:/ 是访问本地文件的协议格式
这里的tmp 文件需要后面手动创建
5.6) hsfs-site.xml (hdfs的配置文件)
dfs.namenode.secordary.http-address
node1:50090
dfs.namenode.name.dir
file:/home/hduser/hadoop/dfs/name
dfs.datanode.data.dir
file:/home/hduser/hadoop/dfs/data
dfs.replication
2
dfs.webhdfs.enabled
true
5.7) mapred-site.xml (mapreduce 配置文件)
mapreduce.framework.name
yarn
mapreduce.framework.name :配置作业运算框架使用yarn框架
[hduser@node1 hadoop]$ cp ~/桌面/mapred-site.xml ~/hadoop/etc/hadoop/ (上面的这些配置文件信息,特别是第5.6.7.8个,要么全部手动输入完成,但必须要正确,不正确,后面格式化后就回报一连串的错误,所有机子都用不了,得重头开始做一遍;要么就是之前有的文件,拷贝到主机的桌面像我这样复制到相应文件即可;最简单的就是用 Xshell 工具在Windows直接复制到相应的目录下。)
5.8) yarn-site.xml (yarn配置文件)
[hduser@node1 hadoop]$ cp ~/桌面/yarn-site.xml ~/hadoop/etc/hadoop/

创建以上第5.6步需要的三个文件:
/home/hduser/hadoop/tmp
/home/hduser/hadoop/dfs/name
/home/hduser/hadoop/dfs/data
[hduser@node1 hadoop]$ mkdir /home/hduser/hadoop/tmp
[hduser@node1 hadoop]$ mkdir -p /home/hduser/hadoop/dfs/name
[hduser@node1 hadoop]$ mkdir /home/hduser/hadoop/dfs/data将node1 的 hadoop 文件夹复制到node2 与 node3 的 hduser 对应的文件夹下。
$> scp -r /home/hduser/hadoop hduser@node2:/home/hduser/
$> scp -r /home/hduser/hadoop hduser@node3:/home/hduser/5.9) 配置hadoop环境变量:
A. 先打开vi /etc/profile
在文档最后追加内容:
export HADOOP_HOME=/home/hduser/hadoop
export PATH=$HADOOP_HOME/bin:$PATH B. 生效环境变量
$>source /etc/profile
C. 测试
$>hadoop version
2. 格式化与启动
1)格式化(只能格式化一次)
利用hadoop主目录下的bin目录下的hadoop命令格式化
$>hadoop namenode -format
[hduser@node1 hadoop]$ bin/hadoop namenode -format
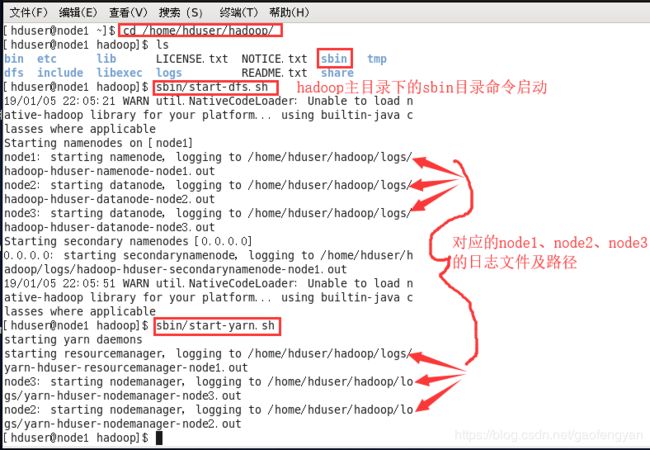
2)启动(这里注意一下,hadoop非常脆弱,每次开关机都要用命令执行,并且先启动的后关闭原则)
利用hadoop主目录下的sbin目录
启动分布式文件系统
$>sbin/start-dfs.sh
启动运算框架
$>sbin/start-yarn.sh
3)关闭
利用hadoop主目录下的sbin目录
关闭运算框架
$>sbin/stop-yarn.sh
关闭分布式文件系统
$>sbin/stop-dfs.sh
4) 浏览器 打开:http://node1:50070 web访问分布式系统
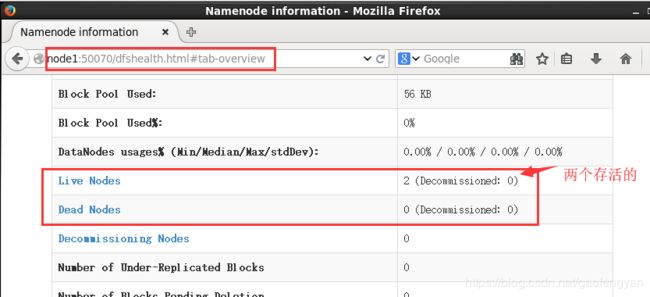
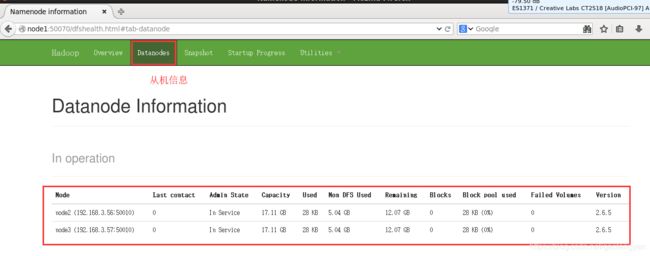
3. hdfs 命令
1) 访问hdfs 根目录(/)
$>bin/hadoop dfs -ls
[hduser@node1 hadoop]$ bin/hadoop dfs -ls
2) 在hdfs 新建目录 /test
$>bin/hadoop dfs -mkdir /test
[hduser@node1 hadoop]$ bin/hadoop dfs -mkdir /test
创建后查看是否成功:
[hduser@node1 hadoop]$ bin/hadoop dfs -ls / 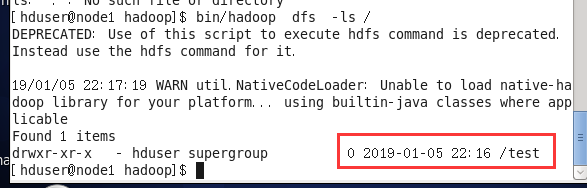
3) 从本地上传文件a.txt到hdfs /test/下
$>bin/hadoop dfs -put ***/a.txt /test/
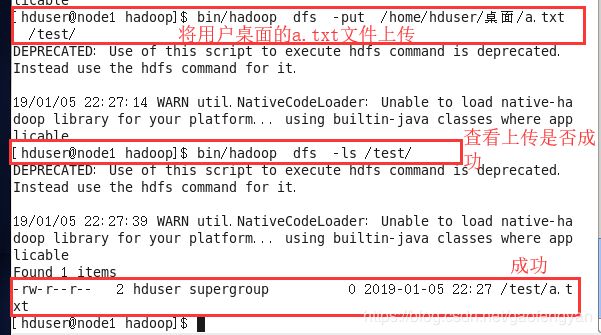
4) 将hdfs /test/下a.txt 下载到本地桌面并命名为b.txt
$>bin/hadoop dfs -get /test/a.txt /home/hduser/hadoop/桌面/b.txt
[hduser@node1 hadoop]$ bin/hadoop dfs -get /test/a.txt /home/hduser/桌面/b.txt
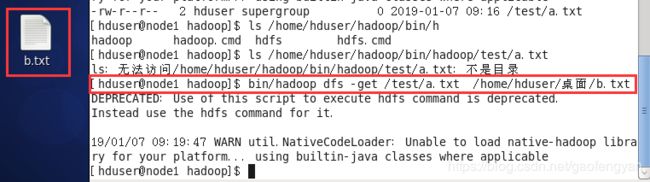
5) 删除hdfs 上 /test 目录
$>bin/hadoop dfs -rmr /test
4. 安装eclipse
新下载 eclipse 需要安装插件,插件名如下:
1*) 这里因为提前准备好了,所以直接将eclipse.tar.gz包解压到 /usr/下(hduser用户操作,需要root用户修改 /usr/文件夹权限)
更改权限:[root@node1 hadoop]# chmod 777 /usr/
解压安装:[hduser@node1 hadoop]$ tar -zxvf ~/桌面/eclipse.tar.gz -C /usr/
更改权限:[root@node1 hadoop]# chmod 755 /usr/
1) 这里为了权限统一并和上面的hadoop安装相同,就直接安装到/home/hduser/目录下 这样就不用更改权限那么麻烦。
解压安装:
[hduser@node1 ~]$ tar -zxvf ~/桌面/eclipse.tar.gz -C /home/hduser/查看:
[hduser@node1 ~]$ ls
eclipse hadoop 公共的 模板 视频 图片 文档 下载 音乐 桌面 2) eclipse 需要hadoop-eclipse-plugin-2.6.4.jar 插件,将该插件复制到 eclipse/plugin/下(这里在安装之前的tar包已经插入了,这一步我这里就省掉了,没有的这里一定要加上去)。
3) 用命令启动eclipse eclipse目录/eclipse -clean
切换目录:
[hduser@node1 ~]$ cd eclipse/查看目录下文件(plugins):
[hduser@node1 eclipse]$ ls
artifacts.xml dropins eclipse.ini icon.xpm plugins
configuration eclipse features p2 readme查看plugins/下是否有hadoop-eclipse-plugin-2.6.4.jar 插件:
[hduser@node1 eclipse]$ ls -l plugins/hadoop-eclipse-plugin-2.6.4.jar
-rwxr--r--. 1 hduser hadoop 31494436 12月 8 18:04 plugins/hadoop-eclipse-plugin-2.6.4.jar启动eclipse:
[hduser@node1 eclipse]$ ./eclipse -clean 
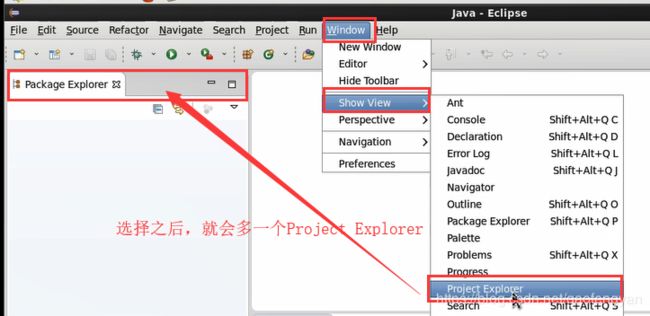
4) 启动后改变显示视图:
windows -> show view -> project Explorer
5) 在命令启动的eclipse后,配置hadoop环境
eclipse -> windows -> preference -> Hadoop mapreduce 右侧配置:hadoop installation direction: /home/hduser/hadoop
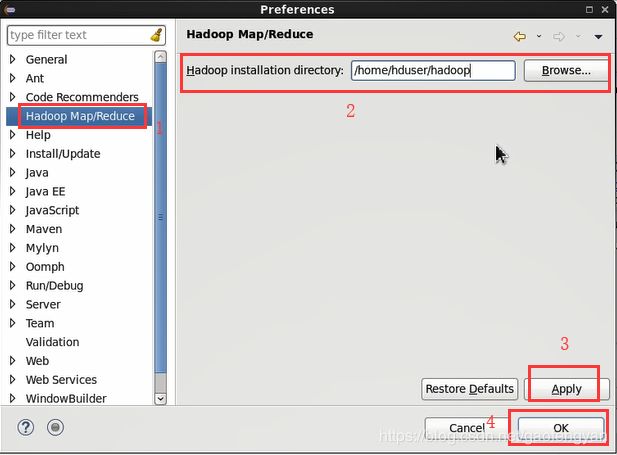
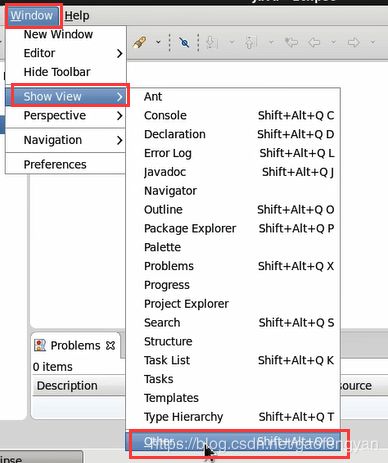
6) 打开mappreduce 选项卡
eclipse -> windows ->show view -> others -> 搜索并打开 map/Reduce Tools
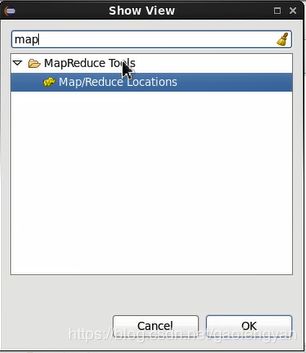
7) 在新打开的map/Reduce 选项卡中 右键点击 new Hadoop location 新增 map/Reduce Location ,弹出配置界面
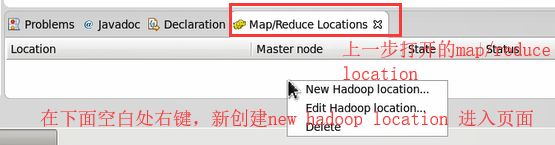
8) 弹出的配置界面做以下配置:
name: xxxx(例如:firsthadoop)取名字
DFS:node1 9000
map/Reduce:node1 9001
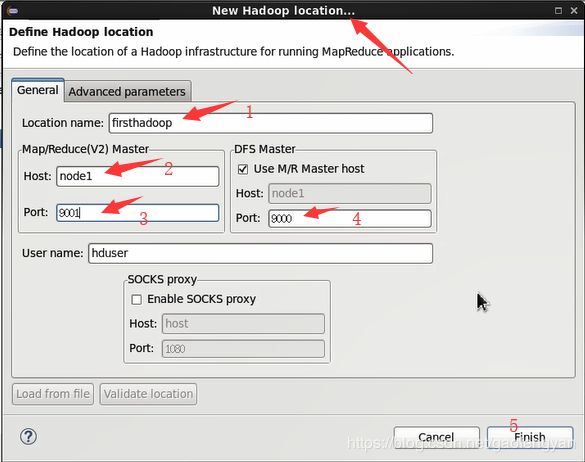
8) 保存
9) eclipse 工作空间左侧project explore 选项卡中,点击 DFS Locations 能看到我们刚配置的分布式文件xxxx.
10) 点击xxxx 展开 分布式文件系统目录结构
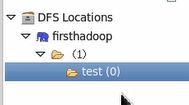
11)使用完后退出eclipse 但要记得关闭hadoop:
[hduser@node1 eclipse]$ /home/hduser/hadoop/sbin/stop-yarn.sh
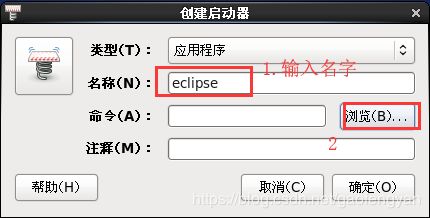
[hduser@node1 eclipse]$ /home/hduser/hadoop/sbin/stop-dfs.sh 12)eclipse创建桌面快捷键 右键桌面选择【创建启动器】:
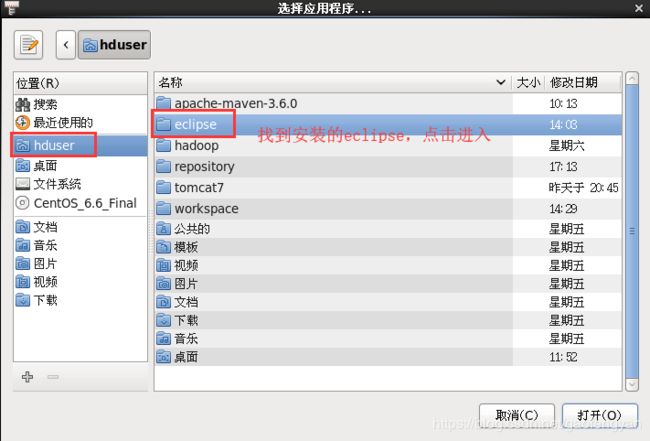
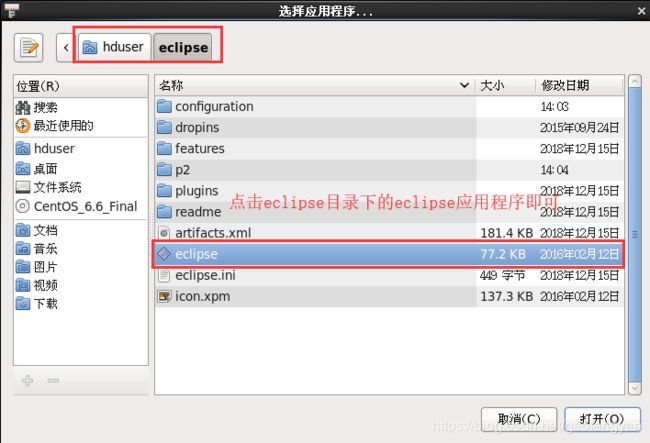
找到安装的eclipse,比如我的是:hduser/eclipse ,点击进入:
5.hdfs分布式 wordcount 单词计数作业 测试
1) node1 本地( /home/hduser/桌面 )创建1个 2个记事本 1.txt 2.txt
$>vi /home/hduser/桌面/1.txt 增加以下内容:
1.txt:
this is a hadoop text .hadoop is a application .
this is a example .
$>vi /home/hduser/桌面/2.txt 增加以下内容:
2.txt:
java
mysql
hadoop
mybatis
在分布式hdfs 创建两个文件夹 /input 和 /output
$>bin/hadoop dfs -mkdir /input
$>bin/hadoop dfs -mkdir /output2) 将node1 本地的1.txt , 2.txt 分别上传到 hdfs /input/下
$>bin/hadoop dfs -put /home/hduser/桌面/1.txt /input/
$>bin/hadoop dfs -put /home/hduser/桌面/2.txt /input/3) 在hdfs上新建一个文件夹 /output/ 用于存放计算的结果集。
4) 利用hadoop 自带样例jar 包执行单词计数器运算。
自带样例:hadoop/share/hadoop/mapreduce/hadoop-mapreduce--examples-2.6.5.jar
语法:hadoop jar hadoop-mapreduce--examples-2.6.5.jar wordcout 被运算的资源位置 结果输出位置
$>hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /input/* /output/wc1
[hduser@node1 ~]$ hadoop jar hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar wordcount /input/* /output/wc1
19/01/07 14:55:28 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
19/01/07 14:55:29 INFO client.RMProxy: Connecting to ResourceManager at node1/192.168.3.55:8032
19/01/07 14:55:31 INFO input.FileInputFormat: Total input paths to process : 2
19/01/07 14:55:31 INFO mapreduce.JobSubmitter: number of splits:2
19/01/07 14:55:32 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1546823348160_0001
19/01/07 14:55:32 INFO impl.YarnClientImpl: Submitted application application_1546823348160_0001
19/01/07 14:55:33 INFO mapreduce.Job: The url to track the job: http://node1:8088/proxy/application_1546823348160_0001/
19/01/07 14:55:33 INFO mapreduce.Job: Running job: job_1546823348160_0001
19/01/07 14:55:45 INFO mapreduce.Job: Job job_1546823348160_0001 running in uber mode : false
19/01/07 14:55:45 INFO mapreduce.Job: map 0% reduce 0%
19/01/07 14:56:01 INFO mapreduce.Job: map 100% reduce 0%
19/01/07 14:56:12 INFO mapreduce.Job: map 100% reduce 100%
19/01/07 14:56:13 INFO mapreduce.Job: Job job_1546823348160_0001 completed successfully
19/01/07 14:56:14 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=162
FILE: Number of bytes written=323858
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=283
HDFS: Number of bytes written=95
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=27047
Total time spent by all reduces in occupied slots (ms)=8817
Total time spent by all map tasks (ms)=27047
Total time spent by all reduce tasks (ms)=8817
Total vcore-milliseconds taken by all map tasks=27047
Total vcore-milliseconds taken by all reduce tasks=8817
Total megabyte-milliseconds taken by all map tasks=27696128
Total megabyte-milliseconds taken by all reduce tasks=9028608
Map-Reduce Framework
Map input records=6
Map output records=19
Map output bytes=171
Map output materialized bytes=168
Input split bytes=188
Combine input records=19
Combine output records=13
Reduce input groups=12
Reduce shuffle bytes=168
Reduce input records=13
Reduce output records=12
Spilled Records=26
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=431
CPU time spent (ms)=2170
Physical memory (bytes) snapshot=461422592
Virtual memory (bytes) snapshot=6173335552
Total committed heap usage (bytes)=256724992
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=95
File Output Format Counters
Bytes Written=95
查看/output下面是否有wc1:
[hduser@node1 ~]$ hadoop fs -ls /output/
19/01/07 14:57:13 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
drwxr-xr-x - hduser supergroup 0 2019-01-07 14:56 /output/wc1查看/output/wc1/下面是否有文件:
[hduser@node1 ~]$ hadoop fs -ls /output/wc1
19/01/07 14:57:27 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 2 items
-rw-r--r-- 2 hduser supergroup 0 2019-01-07 14:56 /output/wc1/_SUCCESS
-rw-r--r-- 2 hduser supergroup 95 2019-01-07 14:56 /output/wc1/part-r-00000查看两个文件的运算结果集:
[hduser@node1 ~]$ hadoop fs -cat /output/wc1/*
19/01/07 14:58:26 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
. 2
.hadoop 1
a 3
application 1
example 1
hadoop 2
is 3
java 1
mybatis 1
mysql 1
text 1
this 2 结果:
this 2
is 3
hadoop 3