P4实战特训营听课笔记(一)
今天来参加未来网络学院举报的P4实战特训营,跟着课程记下笔记,帮助记忆,也便于分享给大家。

早期使用的ASIC器件虽然性能强大,但是是不可编程的(已经烧死的),所以只能处理特定的数据包

使用了P4可编程器件后,用户可以自定义数据包格式和转发格式

以上为一些常用的可编程网络器件,基本都有各自的长处,但也有各自的性能限制。
DPDK舍弃中断机制采用轮询机制,是用于数据平面快速转发的一个架构。DPDK在加速了转发的同时,增加了开发难度,因为要辨别协议栈,而且只能依托于intel芯片上。总的来说DPDK是一个做NFV的一个较好的选择,但不是万能的。
FPGA是一个不错的选择,但是基于硬件结构,FPGA是有性能上限的,所以有很大的局限。
Protocol Independent Packet Processing
为了保证芯片的泛用性,开发一种不依托于特定协议的机制是未来发展所必要的,因此产生了一系列的协议与芯片。

PISA的packet转发流程

不管是v4还是v6,走同样的表,只是v4包过v6表时不产生动作,两种包的处理时间相同。(所以v6转v4的软件原理就是把v4的报头拿掉,换成v6的报头?)
P4的三个目标

这三个目标的意思是什么呢?

P4可以把自己的log信息写到包里,便于查询、处理。(基于自身优越的对包的处理能力)
可编程转发的主要优点有哪些呢?

刚出场的P4芯片是什么都不能做的,需要编程:

写好需要的协议和内容后,就可以进行使用了:
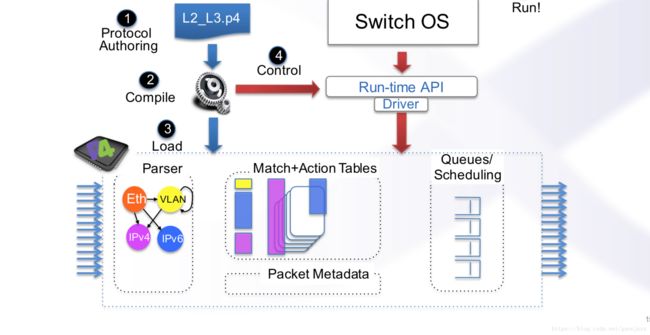
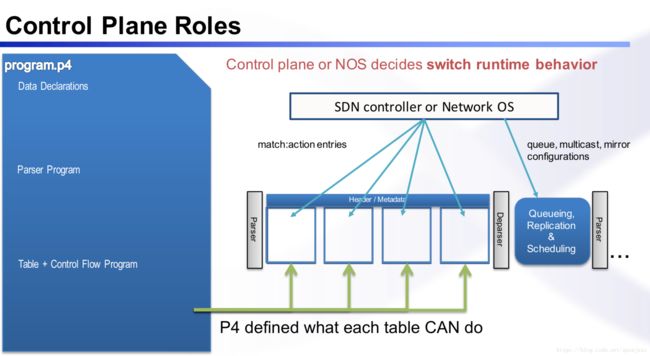
P4是不会自己产生路由表的,需要controller把路由表下发到P4芯片里。
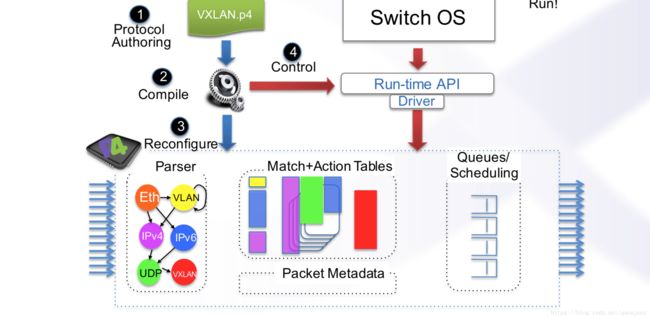
盛科不支持P4.
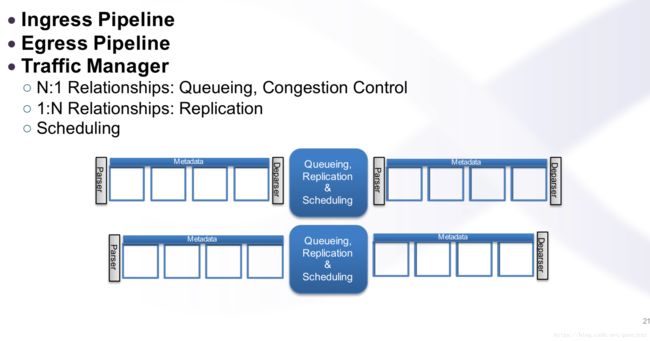
P4的概念结构

对基础传输管道的解析:

metadata是可以解析的,其他是不可解析的(如报头)
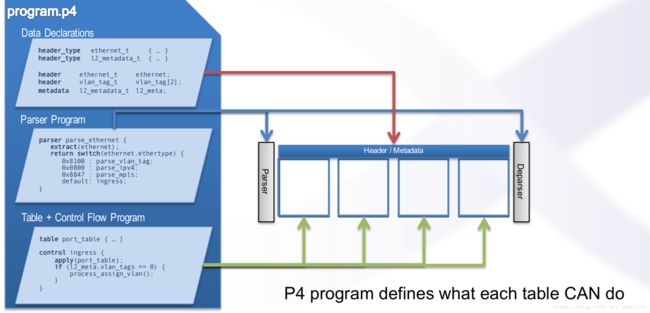
对于转换流程的剖析:
一个简单的P4程序
控制平面
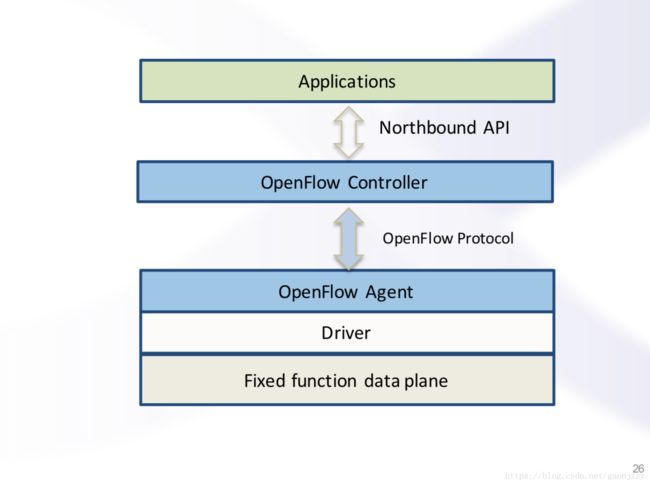
P4&Openflow
传统的openflow网络是有局限的:
openflow定义的太过复杂,从性能上来说很难支持所有的协议。
引入P4解决了openflow的问题

从应用程序里得出可能需要使用的功能,再用P4编译、生成API让应用程序来调用。
更好的方法:

加一个x86的平台可以对需求进行预先处理,使数据交互变成了application与application的交互,生成想要的东西下发到转发平面去。
P4组件:

以太网封包


metadata与packet headers的区别:

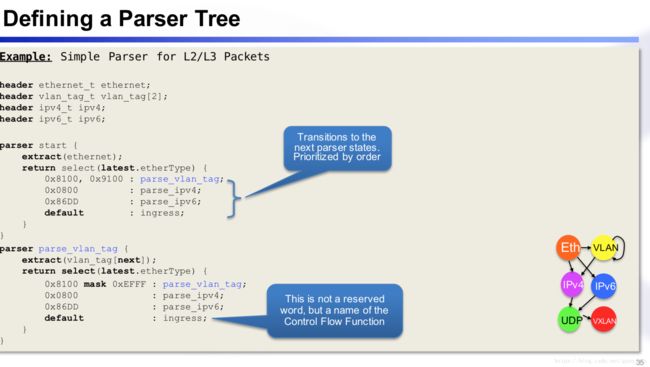
如何定义一个Parser tree:
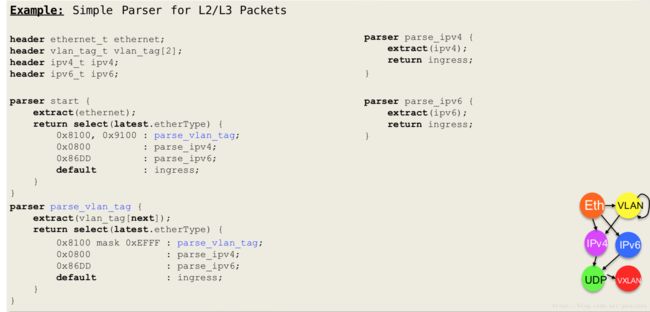
parser处理完之后进行deparser:

转发:


假如顺序执行,A和B都为1;假如并行执行,B会变成之前A里的值,A会赋为1.
经过版本更新,此处定义为严格顺序执行。
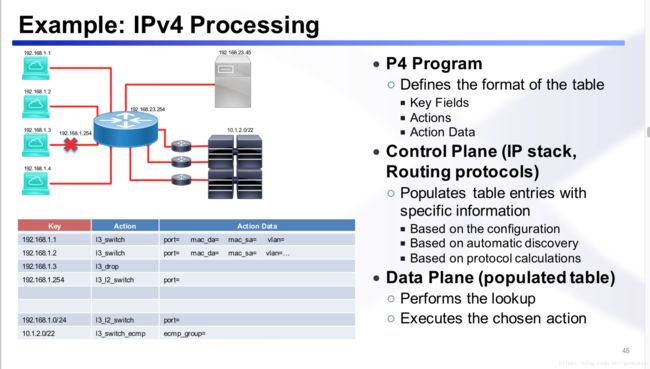
一个实际的match表如何定义?
tips:学习一下红黑树
match过程中的三元组match
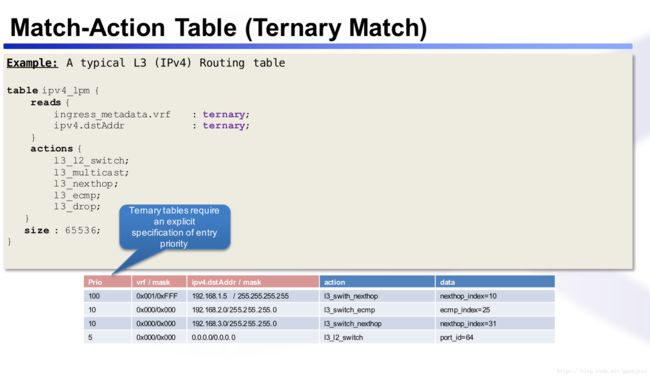
match类型

假如packet进来查表查不到进default action,action内容为上传到CPU,等CPU返回新的路径

状态机

indirect counter

与direct counter不同,counter表项不与列表行数绑定,只判定逻辑关系。
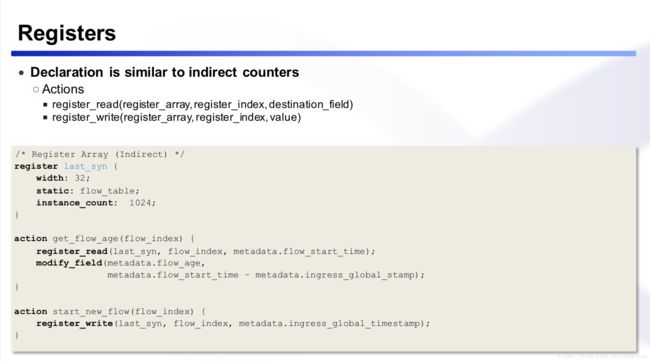
register是全局的,所以可以在不同的管道里共同计数,保证同一个flow会被记录在一张表里,使flow不会被随意清掉。
控制面函数

control里必须先apply一张表,再进行下一步操作。

如何使进来的所有packet进行同样的操作?写一个空key的表,使所有的packet都miss,都进行default操作。
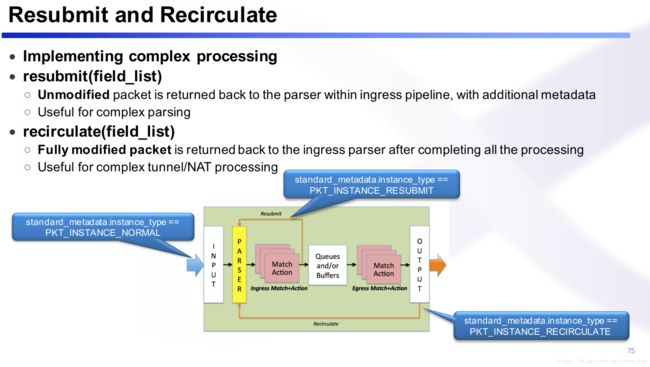
MPLS

MPLS先根据标签进行猜测,猜错了进行resubmit,再重新猜测。

CLONEING

正常的packet被drop掉,在drop之前mirror一份,拿到后台进行debug。

所有的P4代码首先要编译成HLIR,再进行下一步处理。
编译器分成两步,先前端再后端,后端各个厂商都有自己的实现方式。
自动生成API


第一部分笔记就到这里啦,下一篇开始讨论P4.16的内容。