索引的分类
按照类型分类
- 主键索引 : 一个表的主键就是一种特殊的唯一索引,不能有控制,一个表只能有一个主键
- 普通索引 : 是最基本的索引,它没有任何限制
- 唯一索引 : 索引列的值必须唯一,但允许有空值,如果是组合索引,则列值的组合必须唯一
- 全文索引 : 主要用来查找文本中的关键字,而不是直接与索引中的值相比较
按照数量还可以分成:单列索引和组合索引
索引的操作
创建索引
create [UNIQUE|FULLTEXT|SPATIAL|不填(不填表示普通索引)] index 索引名称 [USING index_type(索引类型:默认是Btree)] on 表名(列1(长度),列2...)
#列里面可以指定长度,指定了特定的长度就表示用了前缀索引
删除索引
alter table 表名 drop index 索引名;
查看索引
show index from 表名 [FROM db_name]
前缀索引
对于BLOB,TEXT或很长的VARCHAR类型列如果要作为索引显然是不合适的,这时候可以用前缀索引,MySQL不允许索引这些列的完成长度。
创建前缀索引
只需要在创建索引的时候加上长度
create [UNIQUE|FULLTEXT|SPATIAL|不填(不填表示普通索引)] index 索引名称 [USING index_type(索引类型:默认是Btree)] on 表名(列1(长度),列2...)
#列里面可以指定长度,指定了特定的长度就表示用了前缀索引
如何决定前缀索引的长度
1.首先先计算得到完整列的比例
select count(DISTINCT name) / count(*) from student;
#查询不重复列跟总列的比例,例如得到值为0.0322
2.继续执行
select count(DISTINCT LEFT(name,3)) / count(*) from student;
select count(DISTINCT LEFT(name,4)) / count(*) from student;
#算出来的值如果接近于0.0332则可以选择对应的长度
前缀索引的缺点
Mysql无法使用前缀索引做group by , order by,也无法使用其做覆盖扫描
多列索引(组合索引)
多列索引是指一个索引中使用了多个列,不是多个单个索引
索引最左匹配原则
如果是联合索引,那么key也由多个列组成,同时,索引只能用于查找key是否存在(相等),遇到范围查询(>、<、between、like左匹配)等就不能进一步匹配了,后续退化为线性查找。因此,列的排列顺序决定了可命中索引的列数。
例子:
如有索引(a, b, c, d),相当于我们建立了(a),(a,b),(a,b,c)索引,查询条件a = 1 and b in (2) and c > 3 and d = 4,则会在每个节点依次命中a、b、c,无法命中d。(很简单:索引命中只能是相等的情况,不能是范围匹配)
#不需要纠结=和in的顺序,mysql会自动优化以匹配尽可能多的索引
如何选定哪个列可以作为最左的索引,这里有一个例子可以参考:
如下,有一个表需要选择customer_id或者staff_id谁作为最左边的索引,根据下面的语句:
select count(distinct customer_id)/count(*),count(distinct staff_id)/count(*),count(*) from student;
# count(distinct customer_id)/count(*) : 0.0324
#count(distinct staff_id)/count(*) : 0.0001
#count(*) : 1453566
如下面数据可知customer_id的不可重复性(基数)更高,适合作为第一项索引

image.png
聚簇索引
聚簇索引的两大特点:
- 使用记录主键值的大小进行记录和页的排序
- 页内的记录是按照主键的大小顺序排成一个单向链表
- 各个存放用户记录的页也是根据页中记录的主键大小顺序排成一个双向链表
3.各个存放目录项的页也是根据页中记录的主键大小顺序排成一个双向链表
- B+树的叶子节点存储的是完整的用户记录
我们把具有这两种特性的B+树称为聚簇索引,所有完整的用户记录都存放在这个聚簇索引的叶子节点处。这种聚簇索引并不需要我们在MySQL语句中显式的去创建,InnoDB存储引擎会自动的为我们创建聚簇索引。另外有趣的一点是,在InnoDB存储引擎中,聚簇索引就是数据的存储方式(所有的用户记录都存储在了叶子节点),也就是所谓的索引即数据
索引优化建议
- 尽可能的扩展索引,不要新建立索引。比如表中已经有了a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可,为什么不新建一个b列索引呢,因为mysql查询只能使用一个索引,如果条件是 a =1 and b=2 实际上也只能用到其中一个索引
- 最左前缀匹配原则。这是非常重要、非常重要、非常重要(重要的事情说三遍)的原则,MySQL会一直向右匹配直到遇到范围查询(>,<,BETWEEN,LIKE)就停止匹配
- 尽量选择区分度高的列作为索引,区分度的公式COUNT(DISTINCT col) / COUNT(*)。表示字段不重复的比率,比率越大我们扫描的记录数就越少
- 索引列不能参与计算,比如,FROM_UNIXTIME(create_time) = '2016-06-06' 就不能使用索引
- 单个多列组合索引和多个单列索引的检索查询效果不同,因为在执行SQL时,MySQL只能使用一个索引,会从多个单列索引中选择一个限制最为严格的索引
InnoDB索引原理
InnoDB的存储结构
是一个将表中的数据存储到磁盘上的存储引擎。他的存储方式是将数据划分为若干个页,以页作为磁盘和内存之间交互的基本单位,InnoDB中页的大小一般为 。
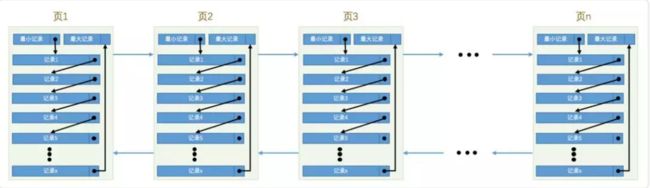
image.png
如图,记录存在页中,按照 单向链表方式存储,页与页之间采用 双向列表连接。
参考
数据库两大神器【索引和锁】
MySQL的索引