往HBase导入数据的几种操作
HBase作为Hadoop DataBase,除了使用put进行数据导入之外,还有以下几种导入数据的方式:
(1)使用importTsv功能将csv文件导入HBase;
(2)使用import功能,将数据导入HBase;
(3)使用BulkLoad功能将数据导入HBase。
接下来,小编将对这三种方法分别进行介绍~
一、使用importTsv功能将csv文件导入HBase
使用importTsv功能可以将csv格式的文件导入到HBase中,其格式如下:
hbase [类] [分隔符] [行键,列族] [表] [导入文件]例如:
1、创建f.csv文件,其内容如下:
2、将文件上传至HDFS,并修改相应的读写权限

3、创建HBase表

4、执行上述的MapReduce操作
/etc/init.d/TDH-Client/hyperbase/bin/hbase \
org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator="," \
-Dimporttsv.columns=HBASE_ROW_KEY,f1 test /user/f.csvMapReduce执行成功之后会显示下图结果:

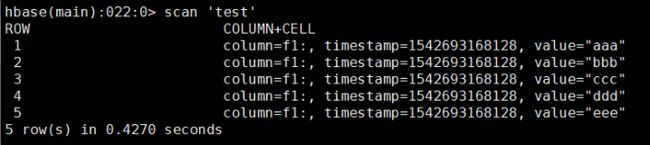
5、查看导入HBase中的数据
二、使用import功能,将数据导入HBase
使用import功能进行数据导入,导入的文件必须是sequence文件。与import相对的还有export功能,export功能导出的文件为sequence文件。
例如:
1、首先使用export功能将HBase表中的数据导出,代码如下:
/etc/init.d/TDH-Client/hyperbase/bin/hbase \
org.apache.hadoop.hbase.mapreduce.Export test /user/hbase/output得到结果如下图所示:

2、创建一个新的HBase表,此处需要注意的是:新表的列族需跟导出表的列族一致

3、执行import的MapReduce
/etc/init.d/TDH-Client/hyperbase/bin/hbase \
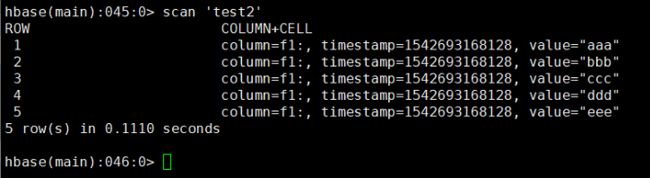
org.apache.hadoop.hbase.mapreduce.Import test2 /user/hbase/output4、查看HBase表中的数据
三、使用BulkLoad功能将数据导入HBase
HBase支持BulkLoad的导入方式,它是利用HBase的数据信息按照特定格式存储在hdfs内这一原理,直接在HDFS中生成持久化的HFile数据格式文件,然后上传至适当位置,即完成巨量数据快速入库的办法。配合MapReduce完成,不占用region资源,在大数据量写入时,能极大的提高写入效率,并降低对HBase节点的写入压力。
通过使用先生成HFile,然后再BulkLoad到HBase的方式来导入数据有如下的好处:
1、消除了对HBase集群的插入压力;
2、提高了Job的运行速度,降低了Job的执行时间。
其格式如下:
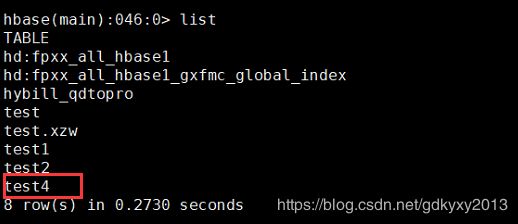
1、通过importTsv生成HFile文件,此过程会主动创建HBase表和HDFS上对应的目录
hbase [类] [分隔符] [输出存储路径] [行键,列族] [表] [导入原始数据文件]2、通过completebulkload将数据导入到HBase表
hadoop jar [hbase server jar包] completebulkload [HFile文件路径] [表名]例如:
1、通过importTsv生成HFile文件
/etc/init.d/TDH-Client/hyperbase/bin/hbase \
org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator="," \
-Dimporttsv.bulk.output=/user/hbase/hfile_output \
-Dimporttsv.columns=HBASE_ROW_KEY,f1 test4 /user/f.csv此过程会主动创建HBase表和HDFS上对应的目录

2、将数据导入到HBase表中
hadoop jar \
/etc/init.d/TDH-Client/hyperbase/lib/hbase-server-0.98.6-transwarp-5.1.1.jar \
completebulkload /user/hbase/hfile_output test4
你们在此过程中遇到了什么问题,欢迎留言,让我看看你们都遇到了哪些问题。