mysql性能优化总结
总目录
- 一、性能优化简介
- 1、性能优化定义
- 2、优化原则
- 3、优化常用工具
- 3.1、性能剖析报告
- 3.2 、Explain执行计划
- 3.3、Show Status
- 3.4、show processlist
- 4、 使用慢查询日志
- 二、性能优化分类
- 1、表结构设计和数据类型优化
- 1.1、数据类型优化
- 1.2、范式和反范式
- 1.3、缓存表和汇总表
- 2、索引优化
- 2.2、B+树索引
- 2.3、聚簇索引和非聚簇索引
- 2.4、覆盖索引
- 2.5、使用索引来group by 和order by
- 2.6、索引区分度
- 2.7、数据行碎片优化
- 2.8、整体原则
- 3、查询优化
- 3.1、查询执行过程
- 3.2、优化特定类型的查询
- 3.2.1、优化子查询
- 3.2.2、优化关联查询
- 3.2.3、优化group by 和 distinct
- 3.2.4、优化limit 分页
- 3.2.5、优化union查询
- 2、服务器配置优化
- 3、操作系统和硬件优化
一、性能优化简介
1、性能优化定义
优化目标: 在一定的工作负载下,尽可能的降低响应时间。
2、优化原则
无法测量就无法优化。所以第一步就是测量响应时间都花在什么地方了。时间又可以进一步分成等待时间和执行时间。所谓“等待”就是等待某种资源(CPU、内存、IO),“执行”指实际的CPU处理或IO操作(网络或磁盘)。
3、优化常用工具
3.1、性能剖析报告
常用的性能剖析报告工具使用Percona Toolkit中包含的pt-query-digest,

这是一个性能剖析报告示例
3.2 、Explain执行计划

这是一个explain的一个示例,需要注意的explain只是一个估计结果,不是一个实测结果。
3.3、Show Status
可以通过show status包含很mysql很多计数器,下面举一个来自,获取myql服务和存储引擎直接的交互结果:
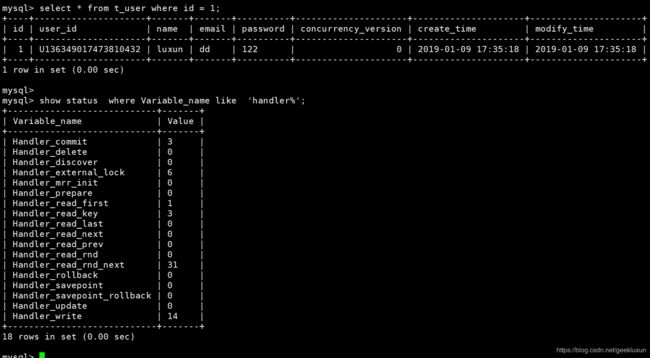 这是执行一次查询后显示的存储引擎句柄计数器相关结果。
这是执行一次查询后显示的存储引擎句柄计数器相关结果。
show global status显示全局计数器
show status显示当前会话(连接)计数器

线程相关计数器
3.4、show processlist

查看当前客户端线程状况
4、 使用慢查询日志
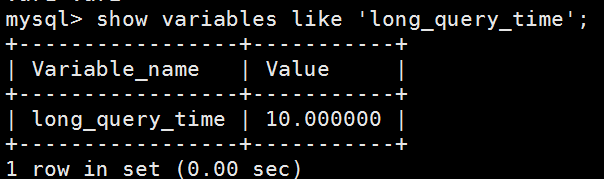
可以把慢查询的时间调整到0,来记录所有的查询日志,然后再通过pt-query-digest来生成一个性能剖析报告分析性能问题。
二、性能优化分类
1、表结构设计和数据类型优化
1.1、数据类型优化
1、数据类型从大的分类主要分成3中,字符串、数值、日期时间,先选择好大类型,然后尽量选择满足条件的小类型(更小类型意味着占用更小CPU、磁盘、内存)
2、DECIMAL最多允许65个数字 ,DECIMAL使用每4个字节存储9个数字方式,相对FLOAT(4字节)和DOUBLE(8字节)占用更多的存储空间,所以一般只在要求精确计算的财务数据时才使用DECIMAL
3、VARCHAR(5)和VARCHAR(200)在存储‘hello’所消耗的存储空间是一致的,但是在使用临时表进行排序时,通常系统需要分配200个字节空间,更浪费空间,所以在满足需求的情况下,尽量使用小的
4、CHAR分成时候存储一些定长的字符串,例如MD5值(16字节)
5、DATETIME使用8字节存储,时间范围为1001年到9999年,TIMESTAMP使用4字节,时间范围1970年到2038年,和时区有关
1.2、范式和反范式
范式化意味着数据在数据库只出现一次,没有冗余,通常需要多表关联才能查询,而反范式以为同一个字段在一张表中存储,有冗余,优点是只在一张表查询,不需要关联查询,但如果数据行很多,因为存在很多重复数据,通常需要group by和distinct等耗时操作。
1.3、缓存表和汇总表
对于一些很耗时的查询,例如各种聚合查询、分组查询等可以单独建立汇总表,这样避免慢查询。
2、索引优化
2.2、B+树索引
InnoDB存储引擎使用B+树作为索引的默认数据结构,B+树是一种平衡二叉树,所有的节点是按照键值的大小顺序存放在同一层的叶子节点上。

2.3、聚簇索引和非聚簇索引
聚簇索引是指所有的叶子节点存储的是数据行
非聚簇索引是指叶子节点存储的不是数据行本身,而是指向数据行的页地址
一张表只能有一个聚簇索引(所有的数据行是按照索引有序的,只能有一个顺序)
2.4、覆盖索引
如果一个索引包含的列包含了要查询的所有列,那么就是说这个索引覆盖了查询,因为索引的叶子节点存储了所有的列值,就不需要回表查询数据行,这样效率高,表现为执行计划中extra字段显示using index
2.5、使用索引来group by 和order by
如果分组和排序所包含的字段正好是一个索引的最左前缀列,则会使用索引来完成分组和排序,否则只能创建临时表来实现分组和排序。前者效率更高。
2.6、索引区分度
建立多列组合索引时,尽量先把区分度高的列放在前面,因为索引匹配是按照最左前缀原则。索引列的区分度越高,索引查询效率越高。
2.7、数据行碎片优化
当逻辑上顺序的行在物理上存储在不同的页,对于全表扫描会有很大的性能损耗,可以使用optimize table命令重新整理数据
2.8、整体原则
1、能通过索引查询到数据的,直接通过索引查询
2、如果必须回表查询的,尽量先通过索引来查询到数据行
3、查询优化
3.1、查询执行过程

这是一次查询执行过程,查询缓存-》解析-》预处理-》查询优化器-》执行查询-》返回结果集
1、要分析一次查询每个执行路径上花费的时间找到一次慢查询的瓶颈在哪
2、mysql是通过“嵌套关联查询”方式实现关联查询的,

是一个左侧深度优先的树
3.2、优化特定类型的查询
3.2.1、优化子查询
如果关联子查询效率比较低,可以使用左外连接代替