Java HashSet与hashCode详解
在进入主题之前,先来扯一些前话,帮大家复习一下基础,看下面的一个例子,比如我们先定义一个Point类
public class Point {
public int x;
public int y;
public Point(int x, int y) {
super();
this.x = x;
this.y = y;
}
}
如果我们不重写它的equals方法,那么Point p1 = new Point(3,3); Point p2 = new Point(3,3); System.out.println(p1 == p2);返回的是false,因为我们比较它们是否相等是调用该类的equals方法,如果没有重写该方法,默认equals方法是比较他们的hashCode值,通常是根据内存地址换算过来的。当重写equals方法,如下:
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Point other = (Point) obj;
if (x != other.x)
return false;
if (y != other.y)
return false;
return true;
}
那么p1与p2便是相等的。我们再来看下面一个例子:
ArrayList
Point p1 = new Point(3,3);
Point p2 = new Point(3,3)
list.add(p1);
list.remove(p2);
System.out.println(list.size());
我们知道当调用ArrayList的remove方法时,它会把集合中的每个元素依次取出来与p2相比较(调用该类的equals方法),如果相等则删除。所以如果不重写equals方法,p1不等于p2,上面输出1,重写之后便输出0。
以上集合中只存入2个元素,如果存入一万个元素,并且没有包含要查找的元素,则意味着需要比较一万次。
为了提高查找元素的效率,便有了哈希算法。当我们存入一个元素时,它会根据哈希算法计算出该元素的哈希值,每个哈希值对应着一片存储区域。如下图:
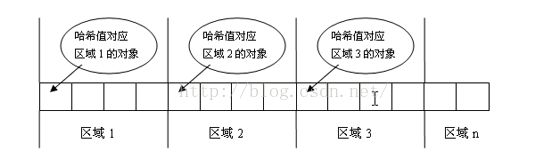
简单的说我们以前要查找一个元素,需要把集合中每个元素都取出来比较,而现在在查找之前,先计算出该元素的哈希值,直接去对应哈希值所指向的区域去查找元素,这样便不用一个个比较,提高了查找效率。
HashSet就是采用哈希算法存取对象的集合,它内部采用对某个数字n进行取余的方式对哈希码进行分组和划分对象的存储区域,Object类中定义了一个hashCode()方法来返回每个Java对象的哈希码,当从HashSet集合中查找某个对象时,Java系统首先调用对象的hashCode()方法获得该对象的哈希码,然后根据哈希码找到对应的存储区域,最后取出该存储区域的每个元素与该对象进行equals()方法比较,这样不用遍历集合中所有元素就可以得到结论。
为了保证一个对象能在HashSet正常存储,要求这个类的两个实例对象用equals方法比较结果相等的同时他们的哈希码也必须相等,即当obj1.equals(obj2)为true时,那么obj1.hashCode()==obj2.hashCode()也为true(两个对象如果不重写hashCode方法,默认返回值是不同的,因为它的返回值是通过对象的内存地址推算出来的)。比如下面的例子:
public void hashsetTest(){
HashSet
Point p1 = new Point(3, 3);
Point p2 = new Point(3, 3);
hPoints.add(p1);
hPoints.add(p2);
System.out.println(hPoints.size());
}
当没有重写hashCode()方法时,添加p1时计算出一个哈希值,放入对应的存储区域,当加入p2时,由于默认hashCode()方法返回值不同,p2就被存放另一个区域,所以输出结果为2。当重写之后:
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + x;
result = prime * result + y;
return result;
}
存入p2时,它计算出的哈希值与p1相同,就存放到p1那个区域,结果已经有一个相同的元素,所以存不进去,输出结果为1。
另外我们还需注意一点,当一个对象被存储进HashSet集合中以后,就不要修改这个对象中参与计算哈希值的字段了。如下例子:
public void hashsetTest(){
HashSet
Point p1 = new Point(3, 3);
Point p2 = new Point(4, 4);
hPoints.add(p1);
hPoints.add(p2);
p1.x = 5;
hPoints.remove(p1);
System.out.println(hPoints.size());
}
按理说在集合中添加两个元素又删除了其中一个元素,此时应该输出结果为1,但实际上结果为2。这时因为在删除p1之前,修改了p1的y值,删除时去计算该元素的哈希值与存入时的不同,指向了另外一个区域,然后没找到相同的元素,就没有删除成功。这样就会造成内存泄漏,本以为已经删除的无用元素却仍然留在内存中。
讲到这里我相信大家都明白的hashCode的作用了。总结一下:
1.当一个对象以hashSet存取的时候,才需要重写它的hashCode方法,如果是ArrayList就没必要了,当然equals方法是都要重写的。
2.hashCode()与equals方法都用来比较两个对象是否相等,只不过HashSet为了提高比较效率,当对象存取时先比较hsahCode的值,如果不同,直接pass,如果相同,再去hashCode的值对应的区域查找元素,再用equals方法进行进一步比较。
好啦,以上就是我对hashCode的理解,如有不当之处,还请指出,我们一起学习。