白皮书:InfiniBand简介
原文链接:Introduction to InfiniBand
摘要
InfiniBand是一种功能强大的新架构,旨在支持Internet基础设施的 I/O 连接。 所有主要OEM服务器供应商都支持InfiniBand作为扩展服务器以及在服务器中创建下一代 I/O 互连标准的手段。 大批量工业标准 I/O互连首次扩展了传统“盒中”总线的作用。 InfiniBand 独一无二的提供“盒中”背板解决方案,外部互连和“带宽开箱即用”,因此它为仅以先前传统网络互连保留的方式提供连接。 I/O 和系统区域网络的统一需要一种新的体系结构,以支持这两个先前独立的域的需求。
这一主要 I/O 转换的基础是InfiniBand支持Internet对RAS要求的能力:可靠性,可用性和可维护性。 本白皮书讨论了展示InfiniBand相对于传统PCI总线和其他专有交换结构和 I/O 解决方案支持RAS的卓越能力的特性和功能。 此外,它还概述了InfiniBand架构如何全面的支持芯片,软件和系统解决方案。 通过提供InfiniBand 1.1规范主要部分的概述,说明了该体系结构的全面性。该1.1规范的范围从行业标准电气接口和机械连接器到明确定义的软件和管理接口。
本文分为四个部分:
引言(introduction)部分为InfiniBand奠定了基础,并说明了为什么所有主要服务器供应商都决定采用这一新标准。 第二节将回顾InfiniBand将对传统技术目前正在解决的各种市场产生的影响。 第三节提供了交换结构和总线架构之间的比较,然后深入研究了InfiniBand与PCI和其他专有解决方案的比较细节。 最后一节详细介绍了该体系结构,从高层次上回顾了InfiniBand最重要的特性。
1. Introduction
Amdahl定律是计算机科学的基本原理之一,并且基本上表明高效系统必须在CPU性能,内存带宽和 I/O 性能之间取得平衡。 与此不一致的是,摩尔定律准确地预测半导体大约每18个月就会使其性能翻倍。 由于 I/O 互连受机械和电气限制的控制比半导体的扩展能力更严重,因此这两个定律导致最终的不平衡并限制系统性能。 这表明 I/O 互连需要每隔几年彻底改变一次,以保持系统性能。 实际上,还有另一个实用法则可以防止 I/O 互连频繁更改——如果没有损坏则不要修复它。
总线架构具有巨大的惯性,因为它们决定了计算机系统和网络接口卡的机械连接以及半导体设备的总线接口架构。 因此,成功的总线架构通常在十年或更长时间内占据主导地位。 PCI总线在90年代早期被引入标准PC架构,并且在此期间仅保持了一次主要升级:从 32 bit/33 MHz到 64 bit/66 Mhz。 PCI-X计划进一步向133MHz迈进,似乎应该为PCI架构提供更长的使用寿命。但个人电脑和服务器存在差异。
个人计算机或 PCs 没有推动 PCI 64/66的带宽功能。 PCI插槽为家庭或企业用户提供了购买网络,视频解码,高级声音或其他卡并升级其PC功能的绝佳方式。另一方面,如今的服务器通常在单个系统中包括群集,网络(千兆以太网)和存储(光纤通道)卡,这些卡推动了PCI-X的1GB带宽限制。随着InfiniBand架构的部署,PCI-X的带宽限制变得更加尖锐。 InfiniBand架构定义了4X链路,这些链路目前正在市场上部署为PCI HCA(主机通道适配器)。尽管这些HCA提供了过去曾经实现的更大带宽,但PCI-X是一个瓶颈,因为单个InfiniBand 4X链路的总聚合带宽为20 Gb / s或2.5 GB / s。这就是HyperTransport和3GIO等新的“本地” I/O 技术将成为InfiniBand的关键补充角色。
互联网的普及以及对24/7正常运行时间的需求正在推动系统性能和可靠性要求达到当今PCI互连架构无法再支持的水平。 数据存储元件; Web,应用程序和数据库服务器; 企业计算正在推动对故障安全,始终可用的系统的需求,提供更高的性能。 该行业的趋势是将存储从服务器移出到隔离存储网络,并跨容错存储系统分发数据。 这些要求超出了对更多带宽的简单要求,并且基于PCI的系统已达到共享总线架构的限制。 由于CPU频率超过千兆赫兹(Ghz)阈值且网络带宽超过每秒千兆位(Gb / s),因此需要一种新的 I/O互连,提供更高的带宽,用以支持和扩展当今的设备。
InfiniBand简介,这是一种基于交换机的串行 I/O 互连架构,在每个方向(每个端口)以2.5 Gb/s或10 Gb/s的基本速度运行。 与共享总线架构不同,InfiniBand是一种低引脚数串行架构,可连接PCB上的器件,实现“开箱即用带宽”,与普通双绞线铜线的距离可达17米。 通过普通光纤电缆,它可以跨越几公里或更长的距离。 此外,InfiniBand还提供 QoS(服务质量)和RAS。这些RAS功能从一开始就被设计到InfiniBand架构中,对于其作为Internet核心下一代计算服务器和存储系统的通用 I/O基础架构的能力至关重要。 因此,InfiniBand将从根本上改变互联网基础设施的系统和互连。 本文讨论了InfiniBand固有的特性,可以实现这种转换。
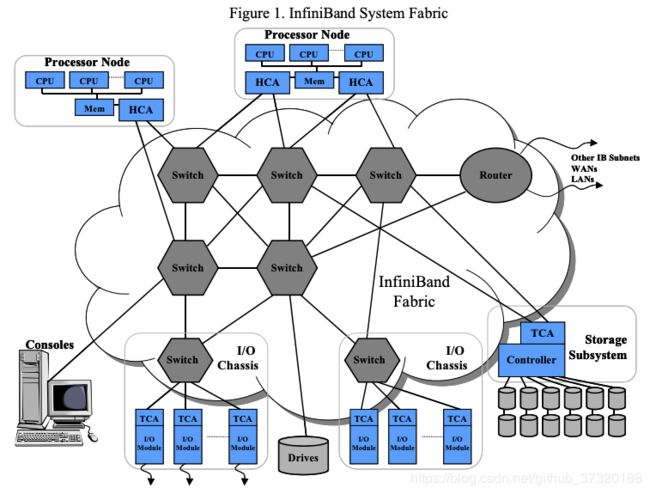
InfiniBand得到业内顶级公司的支持,包括指导委员会成员:Compaq,戴尔,惠普,IBM,英特尔,微软和Sun. InfiniBand贸易协会共有220多名成员。 InfiniBand架构提供了所提到的所有优势,但是,为了实现当前10 Gb/s链路的全部性能带宽,必须消除PCI限制,而这正是当前开发的互连技术将协助InfiniBand的地方。 本文将在后面的部分中说明如何实现InfiniBand的全部潜力,包括全带宽,甚至高达12X链路规范(或每个方向30 Gb/s)。
2. Markets
应用集群,存储区域网络,层间通信和处理器间通信(IPC)等重要市场需要高带宽,QoS和RAS功能。 此外,许多嵌入式系统(包括路由器,存储系统和智能交换机)都采用PCI总线(通常采用Compact PCI格式)来实现内部 I/O 架构。 这样的系统无法跟上千兆以太网和ATM等高速网络互连,因此许多公司正在开发专有的 I/O 互连架构。 凭借开发以太网局域网(LAN),光纤通道存储区域网络和众多广域网(WAN)互连的经验,InfiniBand已经联网以超越当今市场的需求,并为广泛的市场提供一致的互连 系统范围。 这是通过直接支持高度重要的项目(如RAS,QoS和可伸缩性)来实现的。
2.1 Application Clustering 应用程序集群
如今,互联网已发展成为支持流媒体,企业对企业解决方案,电子商务和互动门户网站等应用的全球基础设施。这些应用程序中的每一个都必须支持不断增加的数据量和对可靠性的需求。服务提供商反过来又面临着支持这些应用程序的巨大压力。它们必须通过日益拥挤的通信线路有效地路由流量,同时提供针对不同QoS和安全级别收费的机会。应用服务提供商(ASP)已经出现,支持将电子商务,电子营销和其他电子商务活动外包给专门从事基于Web的应用程序的公司。这些ASP必须能够提供高度可靠的服务,能够在短时间内大幅度扩展以适应互联网的爆炸性增长。集群已发展成为支持这些要求的首选机制。集群只是由负载平衡交换机连接的一组服务器,它们并行工作以服务于特定应用程序。
通过InfiniBand内置的服务质量机制,可以在优先级较低的项目之前处理设备之间的高优先级事务。
2.2 Inter-Processor Communication (IPC) 处理器间通信
处理器间通信允许多个服务器在单个应用程序上协同工作。 服务器之间需要高带宽,低延迟的可靠连接,以确保可靠的处理。 可扩展性至关重要,因为应用程序需要更多的处 InfiniBand的交换特性通过允许系统之间的多条路径为IPC系统提供连接可靠性。 通过单个设备(子网管理器)管理的完全热插拔连接支持可扩展性。 通过多播支持,可以对多个目的地进行单个事务。 这包括发送到子网上的所有系统,或仅发送到这些系统的子集。 InfiniBand定义的带宽较高的连接(4X,12X)为IPC集群提供了骨干功能,无需辅助 I/O 互连。
2.3 Storage Area Networks 存储区域网络
存储区域网络是通过托管交换机连接在一起的复杂存储系统组,允许从多个服务器访问大量数据。 如今,存储区域网络使用光纤通道交换机,集线器和服务器构建,这些服务器通过光纤通道主机总线适配器(HBA)连接。 存储区域网络用于提供与Internet数据中心所需的大型信息数据库的可靠连接。 存储区域网络可以限制各个服务器可以访问的数据,从而提供重要的“分区”机制(有时称为分区或防护)。
InfiniBand的结构拓扑允许在存储和服务器之间简化通信。 移除光纤通道网络允许服务器直接连接到存储区域网络,而无需昂贵的HBA。 凭借远程DMA(RDMA)支持,同步对等通信和端到端流量控制等功能,InfiniBand克服了光纤通道的不足,无需昂贵,复杂的HBA。 本白皮书后面将介绍带宽比较。
3.0 I/O Architectures - Fabric vs. Bus I/O 架构 - Fabric与总线
共享总线架构是当今最常见的 I/O 互连,尽管存在许多缺点。 集群和网络要求系统具有高速容错互连,而总线架构无法正确支持这些互连。 因此,所有总线体系结构都需要网络接口模块来实现可扩展的网络拓扑。 为了跟上系统的步伐, I/O 架构必须提供具有扩展能力的高速连接。 表1提供了交换结构体系结构和共享总线体系结构之间的简单功能比较。
为了跟上系统的步伐,I/O 架构必须提供具有扩展能力的高速连接。

3.1 Shared Bus Architecture 共享总线架构
在总线架构中,所有通信共享相同的带宽。 添加到总线的端口越多,每个外设可用的带宽就越少。 它们还具有严重的电气,机械和电力问题。 在并行总线上,每个连接需要许多引脚(64位PCI需要90个引脚),这使得板的布局非常棘手并且消耗了宝贵的印刷电路板(PCB)空间。 在高总线频率下,每个信号的距离仅限于PCB板上的短迹线。 在具有多个卡插槽的基于插槽的系统中,终端不受控制,如果设计不当可能会导致问题。
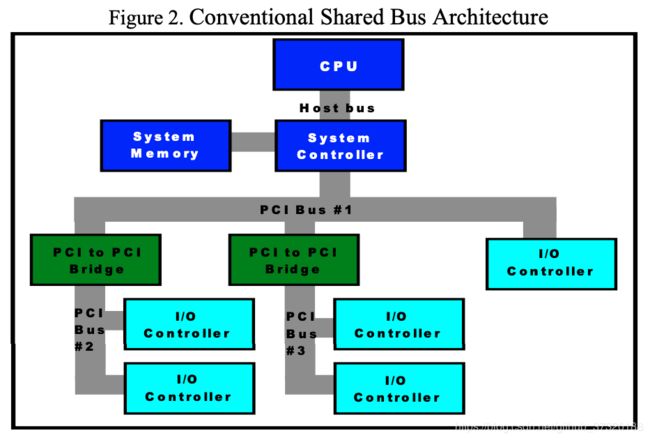
总线设计存在负载限制,每个总线只允许少量设备。 添加桥设备以在桥后面提供具有新负载限制的另一总线克服了这种限制。 虽然这允许更多设备连接到系统,但是当访问系统其他部分上的设备时,数据仍然流经中央总线。 每个桥都添加到系统中,延迟和拥塞会增加。 总线必须设计为在满载条件下工作,假设规范允许的最坏情况的设备数量,这从根本上限制了总线频率。 总线的一个主要问题是它不能支持“开箱即用”的系统互连。 要使系统一起通信,需要单独的互连,例如以太网(服务器到服务器通信)或光纤通道(存储网络)。
3.2 Switched Fabric Architecture 交换结构体系结构
交换结构是一种基于点对点交换机的互连,旨在实现容错和可扩展性。 点对点交换结构意味着每个链路只有一个设备连接在链路的每一端。 因此,加载和终止特性得到很好的控制,并且(与总线架构不同),只允许一个器件,最坏的情况与典型情况相同,因此结构的 I/O 性能可以更高。
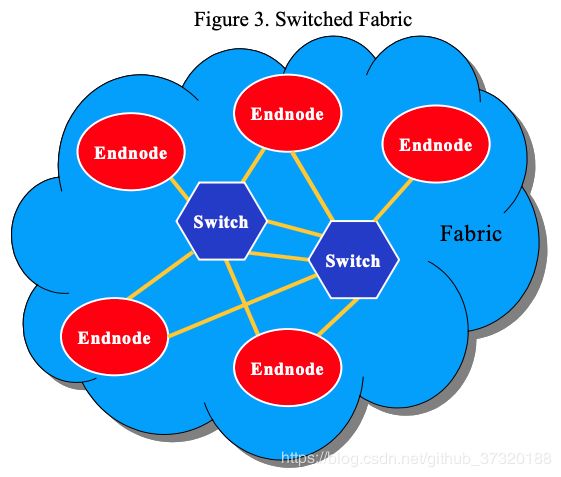
交换结构体系结构提供可扩展性,可通过向交换矩阵添加交换机并通过交换机连接更多终端节点来实现。 与共享总线架构不同,系统的总带宽随着额外交换机添加到网络而增加。 设备之间的多条路径可保持高带宽,并提供故障安全的冗余连接。
3.3 I/O Interconnect Comparison I/O互连比较
如今,许多标准都在争夺互连市场的霸主地位。 与InfiniBand一起,包括PCI-X,光纤通道,3GIO,千兆以太网和RapidIO。
随着PCI-X的推出,I/O互连市场的统治领导者试图支持下一代高速系统。 虽然PCI不会完全消失,但其缺陷会使增长非常有限。 与InfiniBand进行比较是微不足道的。 工作在133Mhz的PCI-X是90针总线,扇出为1。 这严重限制了其在市场上的影响力,并且没有交换机的概念,PCI-X不提供可扩展性。 相比之下,InfiniBand每个子网支持64k节点,利用高端口密度交换机,每个连接只需要四个引脚。
另一个优点是InfiniBand物理层设备(PHY)相对于其他串行互连技术的低功耗要求。 InfiniBand铜PHY每端口仅需0.25瓦。 相比之下,千兆以太网PHY每端口大约需要2瓦。 通过实现千兆以太网PHY设计为支持需要跨越至少100米的连接的局域网(LAN)来解释数量级差异。 InfiniBand仅处理Internet数据中心内的服务器和存储连接,因此无需跨越如此长的时间,因此可以以更低的功耗运行
水平。
较低的PHY功率导致InfiniBand的集成和RAS成本优势。在这种情况下,半导体集成受到芯片最大功率水平的限制(这次摩尔定律进入热力学第一定律)。因此,对于千兆以太网,将PHY集成到具有8,16,24或更多端口的交换机中可能是不可行的。相比之下,随着InfiniBand降低PHY功率要求,这些更高端口数的器件完全可以实现。将多芯片系统简化为单芯片解决方案可以节省大量成本并节省面积。无论PHY是否集成,InfiniBand的功耗降低都可为高可用性应用节省成本。高可用性要求在电源故障时使用不间断电源。在这个滚动停电增加的时代,这是设施管理者在设计其互联网基础设施时必须考虑的一个非常现实的问题。即使是中等规模的网络,使用InfiniBand也可以节省数百瓦的功率,同时相应地降低了成本。
InfiniBand是唯一可用于PCB的架构,同时还提供“开箱即用”的系统互连(通过光纤或铜缆布线)。
表2“功能比较”检查InfiniBand和其他互连硬件在硬件中支持的功能。 每种其他技术都有严重的缺点,即InfiniBand是系统级互连的明确选择。 最值得注意的是,InfiniBand是唯一一种设计用于PCB的架构,同时还提供“开箱即用”系统互连(通过光纤或铜缆布线)。 InfiniBand设计为 I/O 结构,可在硬件中提供传输级连接,因此是唯一可在单个统一结构上支持所有数据中心的技术。 这些技术中的每一种都为它们旨在解决的特定问题带来了好处,但只有InfiniBand为集群,通信和存储提供单一的统一有线互连。
以下是许多计算I / O技术之间的功能比较。
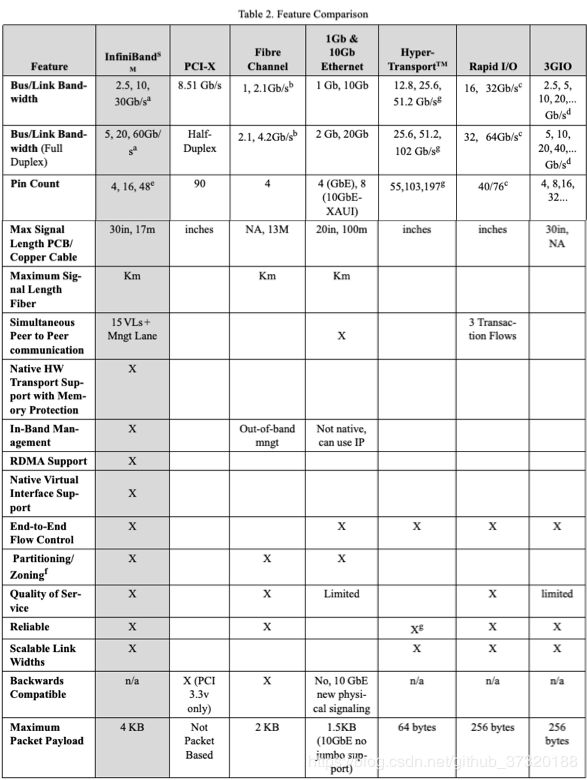
a. InfiniBand 1x链路的原始带宽为2.5Gb / s(每对双绞线)。 数据带宽减少了8b / 10b编码,1X为2.0Gb / s,4X为8Gb / s,12x为24Gb / s。 与半双工总线相比,全双工串行连接产生两倍的数据速率:4/16/48 Gb / s。
b. 2Gb光纤通道的带宽为2.1Gb / s,但实际原始带宽(由于8b / 10b编码)低20%或大约1.7Gb / s(全双工的两倍)。
c. 值适用于8位/ 16位数据路径峰值@ 1GHz操作。 支持125,250和500 MHz的速度。
d. 3GIO链路的原始带宽为2.5Gb / s(每对双绞线)。 数据带宽减少了8b / 10b编码到2.0Gb / s,4.0Gb / s,8.0Gb / s等。与半双工总线相比,全双工串行连接产生两倍的数据速率:4,8,16 ,Gb / s等
e. 1x链路的引脚数为4个引脚,4X链路使用16个引脚,12X链路使用48个引脚。
f. 内存分区使多个主机能够基于密钥以受控方式访问存储端点。 对该特定端点的访问由该密钥控制,因此不同的主机可以访问网络中的不同元素。
g. 基于8,16,32位HyperTransport(它可以支持2和4位模式),每秒高达8亿次传输操作(可支持400 MHz DDR模式)。 错误管理功能将在未来的规范修订版中进行细化。
h. 3GIO具有1X,2X,4X,8X,16X和32X通道宽度。 铜,光学和新兴物理信号媒体。
3.4 Interconnects Complement InfiniBand 互连补充InfiniBand
其中一些新的互连实际上是InfiniBand的关键推动因素,因为它们提供了对新级别处理器带宽的访问,并允许InfiniBand将此带宽扩展到盒外。 正在开发3GIO,HyperTransport和Rapid I/O等技术,这将为InfiniBand提供系统逻辑的连接点,可支持4X InfiniBand链路所需的20 Gb / s甚至12X所需的60 Gb / s InfiniBand链接。 这些技术很好地补充了InfiniBand。
3.5 Bandwidth Out of the Box 带宽开箱即用
InfiniBand架构的一个基本方面是“带宽开箱即用”的概念。 InfiniBand能够获取带宽,这在历史上一直被困在服务器内部,并在整个结构中扩展。 InfiniBand可以有效地利用10Gb / s的性能,通过在结构中的任何位置精确地提供数据。历史上,带宽越来越远离CPU数据传输。图4“开箱即带宽”说明了这一现象和历史趋势。盒外是指从处理器到I / O的带宽,用于集群或处理器间通信(IPC)的服务器之间的带宽,到存储,以及一直到数据中心边缘的带宽。当前现有技术的处理器具有能够以25Gb /秒与其他处理器和存储器通信的前端总线,但是现在可用的PCI-X系统将“盒外”可用带宽限制为仅8Gb / s。数据中心内的实际带宽进一步受限,IPC带宽限制为1或2 Gb / s,光纤通道或存储通信最多为2 Gb /秒,系统之间的通信(通常通过以太网)限制为1Gb / s。这说明了从处理器到数据中心的边缘,丢失了一个数量级的带宽。

如上所述,新的互连,即3GIO,HyperTransport或Rapid I / O可用于将I / O带宽提高到30甚至60 Gb / s。 随着新处理器和/或系统芯片组合并这些互连,克服了当前的PCI限制。 从那里可以释放InfiniBand的带宽,因为HCA将连接到这些互连,这使得集群,通信和存储都可以以本机InfiniBand速度连接。 自2001年以来,正在部署1X(2.5 Gb / s)和4X(10 Gb / s)链路,2003年标志着部署12X或30 Gb / s链路。
下图说明了InfiniBand如何通过对数据中心带宽进行历史考察来释放开箱即用的带宽。大约1998年:英特尔的奔腾II提供了世界级的性能,但计算服务器架构的整体设计将处理器带宽限制在“内部”。进一步的数据从处理器传播带宽越低,直到在边缘100Mb /秒时丢失超过一个数量级的带宽。大约1999年:奔腾III提高了处理器性能,但方程式保持不变。由于数据中心仍然在边缘仅以100 Mb /秒的速度通信,因此带宽会随着距离而丢失。在2000年和2001年,奔腾4和所有其他数据中心子系统提高了带宽,但方程仍然保持不变:从处理器到数据中心边缘的带宽损失超过一个数量级。 InfiniBand架构改变了这个等式。 InfiniBand架构提供从处理器到数据中心边缘的20Gb / s带宽(汇总波特率),包括LAN / WAN和存储连接。 InfiniBand支持Bandwidth Out of the Box,允许处理器级带宽一直移动到数据中心的边缘。此外,InfiniBand架构在2003年提供了12倍的扩展空间,可扩展至60 Gb / s。
值得注意的是,InfiniBand不仅可以提供带宽,还可以在需要的地方提供数据; 通过RDMA从系统内存传输到系统内存。 InfiniBand在硬件中实现可靠的有序传输连接,因此数据传输效率极高,延迟较低且无需主机CPU辅助。 与以太网相比,这是一个巨大的好处,它具有更长的延迟并且消耗大量CPU周期来运行TCP堆栈。
4.0 InfiniBand Technical Overview InfiniBand技术概述
InfiniBand是一种基于交换机的点对点互连架构,为当今的系统开发,具有扩展下一代系统要求的能力。 它既可以在PCB上作为组件到组件的互连,也可以在“开箱即用”的机箱到机箱互连上运行。 每个链路都基于四线2.5 Gb / s双向连接。 该体系结构定义了分层硬件协议(物理,链路,网络,传输层)以及用于管理设备之间的初始化和通信的软件层。 每个链路可以支持多种传输服务以实现可靠性和多个优先化的虚拟通信信道。
为了管理子网内的通信,该体系结构定义了一个通信管理方案,负责配置和维护每个InfiniBand元素。 管理方案定义为错误报告,链路故障转移,机箱管理和其他服务,以确保稳固的连接结构。
InfiniBand功能集:
- 分层协议 - 物理,链路,网络,传输,上层
- 基于分组的通信
- 服务质量
- 三个链路速度
- 1X - 2.5 Gb / s,4线
- 4X - 10 Gb / s,16线
- 12X - 30 Gb / s,48线
- PCB,铜缆和光纤电缆互连
- 子网管理协议
- 远程DMA支持
- 多播和单播支持
- 可靠的传输方法 - 消息队列
- 通信流控制 - 链路级和端到端
4.1 InfiniBand Layers InfiniBand分层
InfiniBand架构分为多个层,每个层彼此独立运行。 如图5所示,“InfiniBand层”InfiniBand分为以下几层:物理层,链路层,网络层,传输层和上层。

4.1.1 Physical Layer
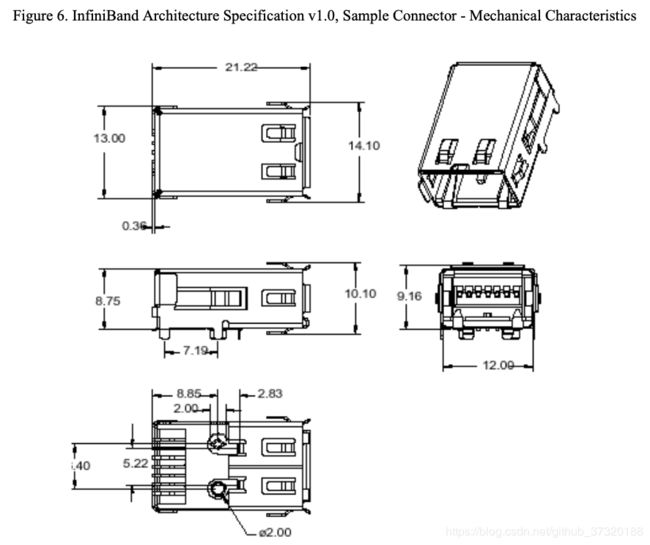
InfiniBand是一种综合架构,可定义系统的电气和机械特性。 这些包括用于光纤和铜介质的电缆和插座,背板连接器和热插拔特性。
InfiniBand在物理层定义了三种链路速度,1X,4X,12X。 每个单独的链路是四线串行差分连接(每个方向两根线),提供2.5 Gb / s的全双工连接。 这些链接如图7“InfiniBand物理链路”所示。
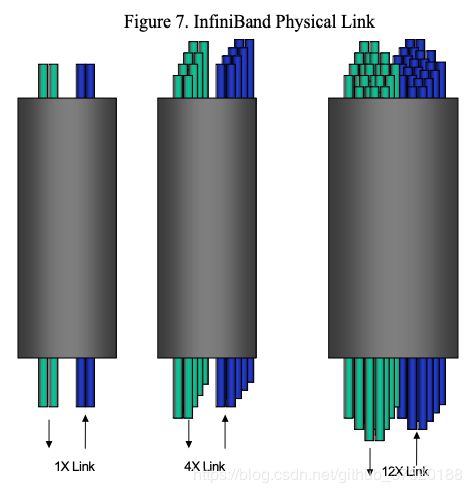
这些链路的数据速率和引脚数显示在表3“InfiniBand链路速率”中。

注意:InfiniBand 1X链路的带宽为2.5 Gb / s。 实际原始数据带宽为2.0 Gb / s(数据为8b / 10b编码)。 由于链路是双向的,因此相对于总线的总带宽是4 Gb / s。 大多数产品都是多端口设计,其中聚合系统I / O带宽将是累加的。
InfiniBand为“开箱即用”通信定义了多个连接器。 定义了光纤和铜缆连接器以及用于机架安装系统的背板连接器。
4.1.2 Link Layer
链路层(以及传输层)是InfiniBand架构的核心。 链路层包括分组布局,点对点链路操作以及本地子网内的切换。
- Packets 包
链路层内有两种类型的数据包,即管理和数据包。 管理数据包用于链路配置和维护。 使用管理数据包确定设备信息,例如虚拟通道支持。 数据包最多可携带4k字节的事务有效负载。 - Switching 交换
在子网内,在链路层处理分组转发和交换。 子网内的所有设备都具有由子网管理器分配的16位本地ID(LID)。 子网内发送的所有数据包都使用LID进行寻址。 链路级别切换将数据包转发到数据包中本地路由标头(LRH)内的目标LID指定的设备。 LRH存在于所有分组中。 - Qos 服务质量
InfiniBand通过虚拟通道(VL)支持QoS。 这些VL是独立的逻辑通信链路,它们共享单个物理链路。 每个链路最多可支持15个标准VL和一个管理通道(VL 15)。 VL15是最高优先级,VL0是最低优先级。 管理数据包仅使用VL15。 每个器件必须支持最小VL0和VL15,而其他VL是可选的。 当数据包遍历子网时,定义服务级别(SL)以确保其QoS级别。 沿路径的每个链路可以具有不同的VL,并且SL为每个链路提供期望的通信优先级。 每个交换机/路由器都有一个SL到VL映射表,由子网管理器设置,以保持每个链路上支持的VL数量的适当优先级。 因此,InfiniBand架构可以通过交换机,路由器和长期运营来确保端到端的QoS。
InfiniBand通过虚拟通道(VL)支持QoS。 这些VL是独立的逻辑通信链路,它们共享单个物理链路。
- Credit Based Flow Control 基于信用的流量控制
流控制用于管理两个点对点链路之间的数据流。 流量控制基于每个VL进行处理,允许单独的虚拟结构使用相同的物理介质保持通信。 链路的每个接收端向链路上的发送设备提供信用,以指定可以在不丢失数据的情况下接收的数据量。 每个设备之间的信用传递由专用链路分组管理,以更新接收器可以接受的数据分组的数量。 除非接收方通告表示接收缓冲区空间可用的信用,否则不传输数据。 - Data integrity 数据的完整性
在链路级,每个数据包有两个CRC,变量CRC(VCRC)和不变CRC(ICRC),可确保数据完整性。 16位VCRC包括数据包中的所有字段,并在每一跳重新计算。 32位红十字国际委员会仅涵盖不会从一跳到另一跳的字段。 VCRC提供两跳之间的链路级数据完整性,红十字国际委员会提供端到端数据完整性。 在像以太网这样只定义单个CRC的协议中,可以在设备中引入错误,然后重新计算CRC。 即使数据已损坏,下一跳的检查也会显示有效的CRC。 InfiniBand包括红十字国际委员会,因此当引入误码时,将始终检测到错误。
4.1.3 Network Layer
网络层处理从一个子网到另一个子网的数据包路由(在子网内,不需要网络层)。 子网之间发送的数据包包含全局路由标头(GRH)。 GRH包含数据包源和目标的128位IPv6地址。 数据包根据每个设备的64位全局唯一ID(GUID)通过路由器在子网之间转发。 路由器使用每个子网内的适当本地地址修改LRH。 因此,路径中的最后一个路由器将LRH中的LID替换为目标端口的LID。 在网络层内,InfiniBand数据包在单个子网内使用时不需要网络层信息和报头开销(这可能是Infiniband系统区域网络的情况)。
4.1.4 Transport Layer
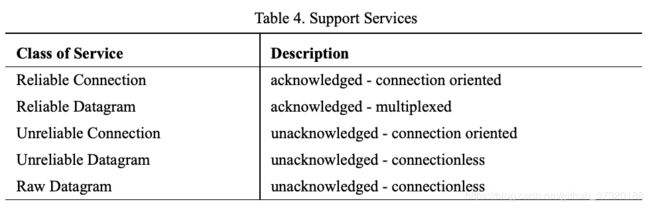
传输层负责有序数据包传送,分区,信道多路复用和传输服务(可靠连接,可靠数据报,不可靠连接,不可靠数据报,原始数据报)。 传输层还在发送时处理事务数据分段,并在接收时重新组装。 基于路径的最大传输单元(MTU),传输层将数据划分为适当大小的分组。 接收器基于包含目的地队列对和分组序列号的基本传输报头(BTH)重新组装分组。 接收方确认数据包,发送方接收这些确认,并使用操作状态更新完成队列。 Infiniband Architecture为传输层提供了重大改进:所有功能都在硬件中实现。
InfiniBand为数据可靠性指定了多种传输服务。 表4“支持服务”描述了每种支持的服务。 对于给定的队列对,使用一个传输级别。
4.2 InfiniBand Elements InfiniBand元素
InfiniBand架构定义了多个用于系统通信的设备:通道适配器,交换机,路由器和子网管理器。 在子网内,每个端节点必须至少有一个通道适配器,并且子网管理器必须设置和维护链路。 所有通道适配器和交换机必须包含处理与子网管理器通信所需的子网管理代理(SMA)。
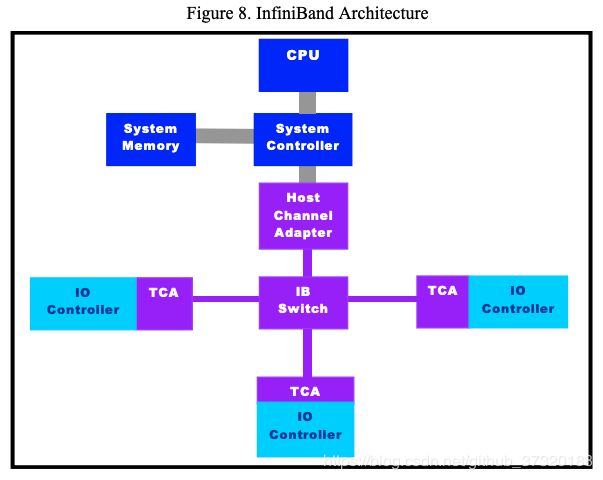
4.2.1 Channel Adapters 通道适配器
通道适配器将InfiniBand连接到其他设备。 有两种类型的通道适配器,主机通道适配器(HCA)和目标通道适配器(TCA)。
HCA为主机设备提供接口,并支持InfiniBand定义的所有软件动词。 动词是一种抽象表示,它定义了客户端软件和HCA功能之间所需的接口。 动词不指定操作系统的应用程序编程接口(API),而是定义OS供应商开发可用的操作
API。
TCA提供与InfiniBand的I / O设备的连接,以及每个设备的特定操作所需的HCA功能子集。
4.2.2 Switch 交换机
交换机是InfiniBand结构的基本组件。 交换机包含多个InfiniBand端口,并根据第二层本地路由标头中包含的LID将数据包从其中一个端口转发到另一个端口。 除管理数据包外,交换机不会消耗或生成数据包。 与通道适配器一样,交换机需要实现SMA以响应子网管理数据包。 交换机可以配置为转发单播数据包(到单个位置)或多播数据包(寻址到多个设备)。
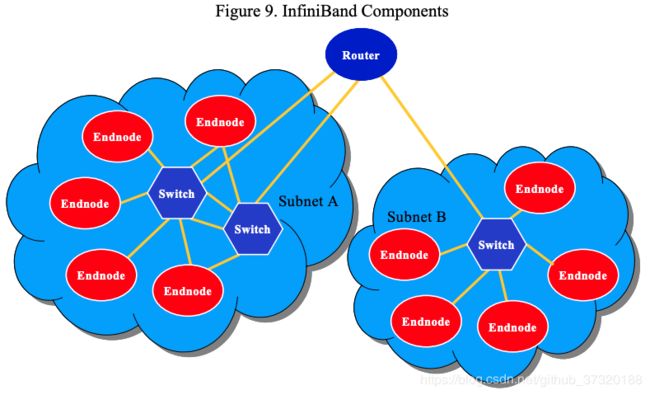
4.2.3 Router 路由器
InfiniBand路由器将数据包从一个子网转发到另一个子网,而不消耗或生成数据包。 与交换机不同,路由器读取全局路由标头以根据其IPv6网络层地址转发数据包。 路由器在下一个子网上使用适当的LID重建每个数据包。
4.2.4 Subnet Manager 子网管理器
子网管理器配置本地子网并确保其继续运行。 子网中必须至少有一个子网管理器才能管理所有交换机和路由器设置,以及在链路出现故障或新链路出现时进行子网重新配置。 子网管理器可以位于子网上的任何设备中。 子网管理器通过每个专用SMA(每个InfiniBand组件都需要)与子网上的设备进行通信。
只要只有一个处于活动状态,就可以有多个子网管理器驻留在子网中。 非活动子网管理器(备用子网管理器)保留活动子网管理器的转发信息的副本,并验证活动子网管理器是否正常运行。 如果活动子网管理器出现故障,备用子网管理器将接管责任,以确保结构不会随之崩溃。
4.3 Management Infrastructure 管理基础设施
InfiniBand体系结构定义了两种系统管理方法,用于处理与子网中的设备关联的所有子网启动,维护和一般服务功能。 每种方法都有一个专用队列对(QP),子网上的所有设备都支持该队列,以区分管理流量和所有其他流量。
4.3.1 Subnet Management 子网管理
第一种方法是子网管理,由子网管理器(SM)处理。 子网中必须至少有一个SM才能处理配置和维护。 这些职责包括LID分配,SL到VL映射,链路启动和拆卸以及链路故障转移。
所有子网管理都使用QP0,并且仅在高优先级虚拟通道(VL15)上处理,以确保子网内的最高优先级。
所有子网管理都使用QP0,并且仅在高优先级虚拟通道(VL15)上处理,以确保子网内的最高优先级。 子网管理数据包(SMP - 发音为“sumps”)是QP0和VL15上允许的唯一数据包。 此VL使用不可靠数据报传输服务,并且不遵循与链路上的其他VL相同的流控制限制。 子网管理信息在链路上的所有其他流量之前通过子网传递。
子网管理器通过满足所有配置要求并在后台处理它们来简化客户端软件的职责。
4.3.2 General Services 一般服务
InfiniBand定义的第二种方法是通用服务接口(GSI)。 GSI处理机箱管理,带外I / O操作以及与子网管理器无关的其他功能等功能。 这些功能与子网管理不具有相同的高优先级需求,因此GSI管理数据包(GMP - 发音为“gumps”)不使用高优先级虚拟通道VL15。 所有GSI命令都使用QP1,并且必须遵循其他数据链路的流量控制要求。
4.4 InfiniBand Support for the Virtual Interface Architecture (VIA) 支持虚拟接口架构(VIA)
虚拟接口体系结构是一种分布式消息传递技术,既独立于硬件又与当前网络互连兼容。 该体系结构提供了一个API,可用于在集群应用程序中的对等体之间提供高速和低延迟通信。
InfiniBand是在考虑VIA架构的情况下开发的。 InfiniBand通过使用执行队列从软件客户端卸载流量控制。 这些队列称为工作队列,由客户端启动,然后留给InfiniBand进行管理。 对于设备之间的每个通信通道,在每端分配工作队列对(WQP - 发送和接收队列)。 客户端将事务放入工作队列(工作队列条目 - WQE,发音为“wookie”),然后由通道适配器从发送队列处理该事务并发送到远程设备。 当远程设备响应时,通道适配器通过完成队列或事件将状态返回给客户端。
客户端可以发布多个WQE,通道适配器的硬件将处理每个通信请求。 然后,通道适配器生成完成队列条目(CQE),以按适当的优先顺序为每个WQE提供状态。 这允许客户端在处理事务时继续执行其他活动。

4.5 Realizing the Full Potential of Blade Computing 实现刀片计算的全部潜力
为了充分实现基于刀片式服务器计算的TCO(总拥有成本)优势,刀片技术必须至少提供以下核心功能:可扩展性,容错,热插拔,QoS,群集,支持I / O连接(两者都兼备) 内存和消息语义),可靠性,冗余,故障转移的主动备用,互连可管理性和错误检测。 理解为什么IT Manager在部署的每个新服务器平台中都需要这些属性,这是相当直接的。 如本文所述,所有这些属性都是在InfiniBand架构中本地提供的,它们将真正释放刀片计算所承诺的全部潜力。 使用InfiniBand架构实现服务器,交换机和I / O刀片的全部潜力的白皮书(文档#2009WP)详细探讨了属性和TCO优势。
5.0 总结
行业领导者的共同努力已经成功地将InfiniBand从技术演示转变为第一次真正的产品部署。 IBTA目前拥有超过220个成员,规范已经成熟,多家供应商公开展示了工作芯片和系统,并且InfiniBand芯片供应商之间的互操作性已得到证明。 InfiniBand架构的优势非常明显,包括:支持RAS(可靠性,可用性,可维护性),既可以开箱即用,也可以实现带宽开箱即用的结构,以及未来的可扩展性。
IBTA的愿景是通过InfiniBand技术及其作为服务器,通信和存储互连的结构来改进和简化数据中心。想象一下,由服务器组成的数据中心都紧密地聚集在一起。这些服务器只有处理器和内存,通过InfiniBand端口连接到存储和通信。这样可以通过虚拟接口群集实现更高的处理器性能,更高的处理器和内存密度(因为大多数外围设备已经移出服务器机架),以及更大的(InfiniBand)I / O带宽。最重要的是,所有这些改进都基于为RAS设计的架构。现在想象所有这些都包含了升级现有服务器的灵活性,尽管是PCI(由3GIO升级)和InfiniBand Server Blades。随着越来越多的企业和消费者更频繁地以更高的带宽利用互联网,Infiniband的迅速普及继续受到欢迎。
6.0关于Mellanox
Mellanox是InfiniBand半导体的领先供应商,为服务器,通信,数据存储和嵌入式市场提供包括交换机,主机通道适配器和目标通道适配器在内的完整解决方案。 Mellanox Technologies已经在两代10 Gb /秒InfiniBand设备上提供了超过100,000个InfiniBand端口,包括InfiniBridge,InfiniScale和InfiniHost设备。如今,Mellanox InfiniBand互连解决方案的性能是以太网的八倍以上,是专有互连性能的三倍以上。该公司得到了包括戴尔,IBM,英特尔投资,广达电脑,Sun Microsystems和Vitesse在内的企业投资者的大力支持,以及Bessemer Venture Partners,Raza Venture Management,Sequoia Capital,US Venture Partners等公司的强大风险投资支持。该公司在加利福尼亚州圣克拉拉,Yokneam和特拉维夫以色列设有主要办事处。有关Mellanox的更多信息,请访问www.mellanox.com。