Cookie登录爬取实战:Python 利用urllib库的cookie实现网站登录并抓取
1 环境:Python 3 +urllib库
实战网站:http://www.mjzcnd.com/ 梅江之春论坛网站
2 背景:
现在许多网站都需要登录后才能访问某个页面,在登陆之前,我们是没有权限访问该页面的,因此我们要爬取该页面就要先登录,再去抓取那个页面。
3 怎么做:
利用urlib库保存我们登录时的cookie值,然后在之后的页面请求时,连同保存的cookie一同传递过去,这样就可以实现在登录状态下爬取我们想要的页面。
4 实现流程:
4.1.网站分析:
打开http://www.mjzcnd.com/forum.php网站,分析网站登录的实际url和登录请求要传递的参数。
在登录处,填写错误的账号密码,在点击登录之前F12打开network查看网络状态请求的情况,然后点击登录按钮
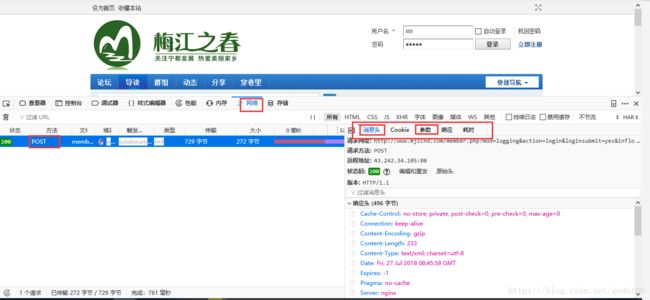
一般登录都是Post()方法,我们点击带有post请求的地址,会出现右边请求的信息,在这里我们就可以找到我们想要的信息。
请求网址:
http://www.mjzcnd.com/member.php?mod=logging&action=login&loginsubmit=yes&infloat=yes&lssubmit=yes&inajax=1
请求Headers:查看图中的请求头,找到User-Agent,原因:一般的网站会判断是不是浏览器访问,不设置服务器会认为不是浏览器的请求,就是判断你是爬虫,那就很有可能会阻止你的访问。
headers:一般会设置三个参数:
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0",
"HOST": "www.mjzcnd.com",
"Referer": "http://www.mjzcnd.com/forum.php"
这些都可以在请求头的信息中找到,复制一下,就可以把我们的请求伪装成浏览器。
登录请求参数:即要想服务器登录传递的参数,我们点击图片的参数就可以看到请求登录要传递的参数
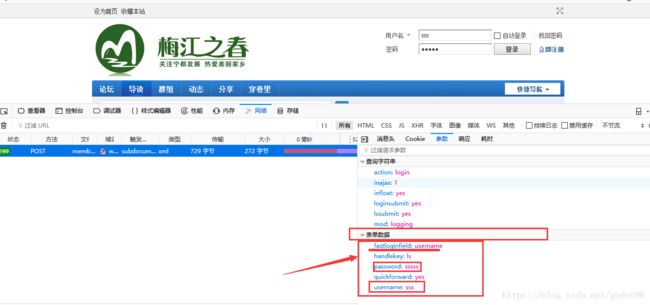
这些参数都是在请求登录时,要传递的参数,所以一般我们不确定就把所有的要的数据都按这个全部传递过去就可以。实际上,我发现传递三个参数就可以实现登录。
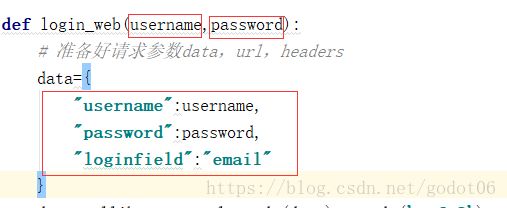
data:
4.2.代码实现
(1)登录并保存cookie
保存cookie主要有5步:
#1---> 构建一个cookie用来保存网站生成的cookies值 保存cookie文件名meijiangcookies.txt
cookie=http.cookiejar.MozillaCookieJar('meijiangcookies.txt')
#2---> 构建一个handler 处理器,利用HTTPCookieProcessor
handler=urllib.request.HTTPCookieProcessor(cookie)
#3---> 利用handler处理器通过build_opener构建opner请求网络
opener=urllib.request.build_opener(handler)
#4---> 使用opener请求网络
request=urllib.request.Request(url,data,headers)
response=opener.open(request)
#5---> 保存cookies值 其中ignore_expires=True 即使cookies将被丢弃也将它保存下来;
ignore_discard=True 如果文件中cookie已经存在,则覆盖原文件
cookie.save(ignore_expires=True,ignore_discard=True) #一定呀设置成True,因为cookie会过期def login_web(username,password):
# 准备好请求参数data,url,headers
data={
"username":username,
"password":password,
"loginfield":"email"
}
data=urllib.parse.urlencode(data).encode('utf-8')
url="http://www.mjzcnd.com/member.php?mod=logging&action=login&loginsubmit=yes&infloat=yes&lssubmit=yes&inajax=1"
# 构建一个cookie用来保存网站生成的cookies值
cookie=http.cookiejar.MozillaCookieJar('meijiangcookies.txt')
# 构建一个handler 处理器,利用HTTPCookieProcessor
handler=urllib.request.HTTPCookieProcessor(cookie)
# 利用handler处理器通过build_opener构建opner请求网络
opener=urllib.request.build_opener(handler)
# 使用opener请求网络
request=urllib.request.Request(url,data,headers)
response=opener.open(request)
#保存cookies值
cookie.save(ignore_expires=True,ignore_discard=True)
for item in cookie:
print("Name :"+item.name)
print("Value :"+item.value)
login(u'username',u'password')通过以上就可以实现网站的登录,同时保存登录后的cookie值,我们也可以通过打印也看看我饿我们保存的cookie值(当然也可以直接去查看保存的文件)
(2)从文件中读取cookie值并访问需要登录的页面
我们利用cookie登录很大程度的目的是为了访问其他要登录才能访问的页面,这就需要我们在访问的是时候携带我们保存的cookie去访问(这样就能实现登录状态下访问其他页面)
此处,我们去访问个人中心,顾名思义这个模块需要我们登录才能访问。
从文件读取cookie的操作,主要有以下4步骤:
#1---> 实例cookie并load()加载本地保存的cookie-meijiangcookies.txt
cookie=http.cookiejar.MozillaCookieJar('meijiangcookies.txt')
cookie.load('meijiangcookies.txt',ignore_discard=True,ignore_expires=True)
#2---> 利用urllib库的HTTPCookieProcessor构建处理器handler,此时的handler中已经包含了cookies值
handler=urllib.request.HTTPCookieProcessor(cookie)
#3---> 构建一个用于发起请求的opener
opener=urllib.request.build_opener(handler)
#4---> 使用opener 发起网络请求(此时的opener中已经含有存储的coookie值了)
request=urllib.request.Request(url,headers=headers)
response=opener.open(request)
def request_otherdex():
url="http://www.mjzcnd.com/forum.php?mod=guide&view=my"
# 加载cookie
cookie=http.cookiejar.MozillaCookieJar('meijiangcookies.txt')
cookie.load('meijiangcookies.txt',ignore_discard=True,ignore_expires=True)
# 利用urllib库的HTTPCookieProcessor构建处理器handler,此时的handler中已经包含了cookies值
handler=urllib.request.HTTPCookieProcessor(cookie)
# 构建一个用于发起请求的opener
opener=urllib.request.build_opener(handler)
# 使用opener 发起网络请求
request=urllib.request.Request(url,headers=headers)
response=opener.open(request)
html_page=response.read().decode()
print(html_page)
with open("meijiangmyindex.html","wb") as f:
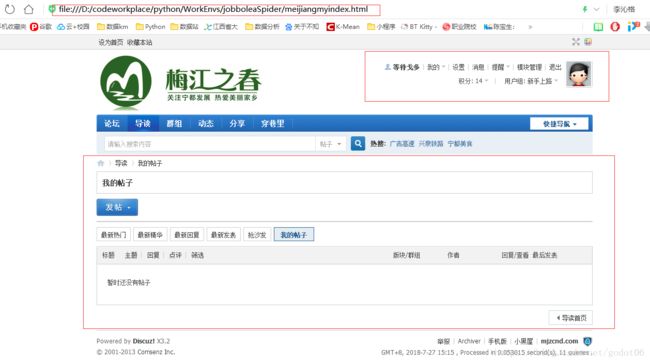
f.write(html_page.encode("utf-8"))怎么查看我们是否是成功用cookie登录了,我们将请求响应返回的response写入成html文件打开看看就知道了,当然写入操作要特别注意字符类型,我们向磁盘写文件要转成字节型,才能write()。关字符问题,可以查看参考这篇。 Python:常遇见的字符编码问题
我们打开保存的html文件,发现成功利用保存的cookie访问成功了,之后你想要怎么爬取信息,就是看自己的需求了。
这篇我们实现了网站登录并保存cookie,但是现在很多网站都是需要输入验证码登录的,这种方式,且听下回分析。
