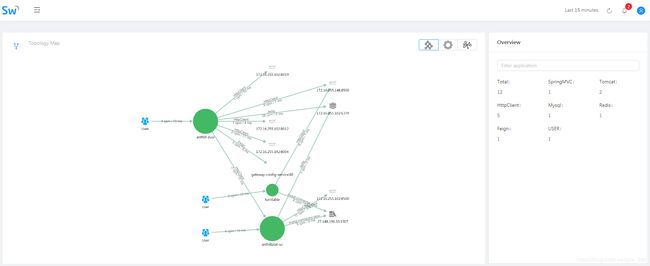
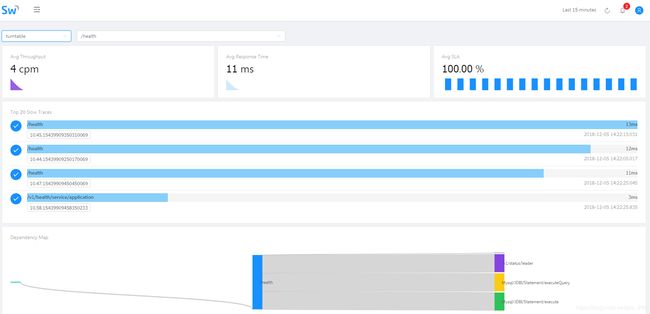
服务追踪工具 SkyWarking 安装与部署,并整合微服务,集群环境。
SkyWalking 是用于对微服务,Cloud Native,容器等提供应用性能监控和分布式调用链追踪的工具
环境
- ElasticSearch 5.6.10
- SkyWalking 5.0.0-GA
- centos7
- jdk1.8
ElasticSearch安装
- 下载解压 ElasticSearch 5.6.10
curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.6.10.tar.gz
tar -vxf elasticsearch-5.6.10.tar.gz
mv elasticsearch-5.6.10 elasticsearch
- 修改配置文件 elasticsearch/config/elasticsearch.yml
cluster.name: CollectorDBCluster
node.name: CollectorDBCluster1
network.host: 172.16.255.148
需要注意的是cluster.name最好是CollectorDBCluster,network.host最好是局域网 IP,否则可能会在使用时出现很多问题
- 启动elasticsearch,注意:elasticsearch不能以root身份运行
groupadd elsearch
useradd elsearch -g elsearch -p elasticsearch
chown -R elsearch:elsearch elasticsearch
su elsearch
先运行命令 elasticsearch/bin/elasticsearch 查看是否运行成功,若是出现错误,请看 elasticsearch 异常归纳 进行解决
没问题后使用此命令在后台运行 nohup elasticsearch/bin/elasticsearch > elasticsearch/elasticsearch.log &
启动 elasticsearch 异常归纳(https://www.e-learn.cn/content/java/1069602)
SkyWorking安装
- 下载解压skywalking 5.0.0-GA
wget http://mirror.bit.edu.cn/apache/incubator/skywalking/5.0.0-GA/apache-skywalking-apm-incubating-5.0.0-GA.tar.gz
tar -vxf apache-skywalking-apm-incubating-5.0.0-GA.tar.gz
mv apache-skywalking-apm-incubating skywalking
- 修改配置 skywalking/config/application.yml
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#cluster:
# zookeeper:
# hostPort: localhost:2181
# sessionTimeout: 100000
naming:
jetty:
#OS real network IP(binding required), for agent to find collector cluster
host: 0.0.0.0
port: 10800
contextPath: /
cache:
# guava:
caffeine:
remote:
gRPC:
# OS real network IP(binding required), for collector nodes communicate with each other in cluster. collectorN --(gRPC) --> collectorM
host: 172.16.255.148
port: 11800
agent_gRPC:
gRPC:
#OS real network IP(binding required), for agent to uplink data(trace/metrics) to collector. agent--(gRPC)--> collector
host: 172.16.255.148
port: 11800
# Set these two setting to open ssl
#sslCertChainFile: $path
#sslPrivateKeyFile: $path
# Set your own token to active auth
#authentication: xxxxxx
agent_jetty:
jetty:
# OS real network IP(binding required), for agent to uplink data(trace/metrics) to collector through HTTP. agent--(HTTP)--> collector
# SkyWalking native Java/.Net/node.js agents don't use this.
# Open this for other implementor.
host: 172.16.255.148
port: 12800
contextPath: /
analysis_register:
default:
analysis_jvm:
default:
analysis_segment_parser:
default:
bufferFilePath: ../buffer/
bufferOffsetMaxFileSize: 10M
bufferSegmentMaxFileSize: 500M
bufferFileCleanWhenRestart: true
ui:
jetty:
# Stay in `localhost` if UI starts up in default mode.
# Change it to OS real network IP(binding required), if deploy collector in different machine.
host: 172.16.255.148
port: 12800
contextPath: /
storage:
elasticsearch:
clusterName: CollectorDBCluster
clusterTransportSniffer: true
clusterNodes: 172.16.255.148:9300
indexShardsNumber: 2
indexReplicasNumber: 0
highPerformanceMode: true
# Batch process setting, refer to https://www.elastic.co/guide/en/elasticsearch/client/java-api/5.5/java-docs-bulk-processor.html
bulkActions: 2000 # Execute the bulk every 2000 requests
bulkSize: 20 # flush the bulk every 20mb
flushInterval: 10 # flush the bulk every 10 seconds whatever the number of requests
concurrentRequests: 2 # the number of concurrent requests
# Set a timeout on metric data. After the timeout has expired, the metric data will automatically be deleted.
traceDataTTL: 90 # Unit is minute
minuteMetricDataTTL: 90 # Unit is minute
hourMetricDataTTL: 36 # Unit is hour
dayMetricDataTTL: 45 # Unit is day
monthMetricDataTTL: 18 # Unit is month
#storage:
# h2:
# url: jdbc:h2:~/memorydb
# userName: sa
configuration:
default:
#namespace: xxxxx
# alarm threshold
applicationApdexThreshold: 2000
serviceErrorRateThreshold: 10.00
serviceAverageResponseTimeThreshold: 2000
instanceErrorRateThreshold: 10.00
instanceAverageResponseTimeThreshold: 2000
applicationErrorRateThreshold: 10.00
applicationAverageResponseTimeThreshold: 2000
# thermodynamic
thermodynamicResponseTimeStep: 50
thermodynamicCountOfResponseTimeSteps: 40
# max collection's size of worker cache collection, setting it smaller when collector OutOfMemory crashed.
workerCacheMaxSize: 10000
#receiver_zipkin:
# default:
# host: localhost
# port: 9411
# contextPath: /
说明: naming host为0.0.0.0 其他都为skywalking部署所在服务器的局域网ip,,注意:elasticsearch的clusterNodes是elasticsearch所在服务器的ip+port,默认端口都为9300
- 修改配置 skywalking/webapp/webapp.yml
server:
port: 8080collector:
path: /graphql
ribbon:
ReadTimeout: 10000
listOfServers: 172.16.255.148:10800security:
user:
admin:
password: admin
- 修改配置 skywalking/agent/config/agent.config
agent.application_code=unkown //随意填写,可根据启动命令修改
collector.servers=172.16.255.148:10800
logging.level=INFO
- 启动 Collector 和 Webapp
skywalking/bin/startup.sh
- 单独启动 Collector 和 Webapp
skywalking/bin/collectorService.sh
skywalking/bin/webappService.sh
使用
说明:1、skywalking-agent.jar为安装的真实路径,可以linux下用 find / -name skywalking-agent.jar 查找
2、 -Dskywalking.agent.application_code=application 就是设置节点名称,如果是微服务,就写成服务名称即可
- Jar 启动时添加 VM 参数 ,例如:springboot打包的java应用(服务)为 application.jar
java -jar -javaagent:/opt/webapps/skywalking/agent/skywalking-agent.jar -Dskywalking.agent.application_code=application application.jar
- Tomcat 修改bin/catalina.sh首行配置(这个方式是参考其他来源,Jar方式已验证可行,具体情况以自己的环境为准)
# Linux/Mac
CATALINA_OPTS="$CATALINA_OPTS -javaagent:/path/to/skywalking-agent/skywalking-agent.jar"; export CATALINA_OPTS# Win
set "CATALINA_OPTS=-javaagent:/path/to/skywalking-agent/skywalking-agent.jar"
集群 (多服务不在同一台服务器中挂在SkyWalking上)
假设三台服务器:172.16.255.148 172.16.255.149 172.16.255.150
ElasticSearch和SkyWalking安装在172.16.255.148
application.jar服务在172.16.255.149
turntable.jar服务在172.16.255.150
- 拷贝SkyWalking中的agent目录所有东西到其他服务器中
SkyWalking原始解压到的东西 (172.16.255.148)
--- agent
--- bin
--- collector-libs
--- config
--- DISCLAIMER
--- LICENSE
--- licenses
--- logs
--- NOTICE
--- README.txt
--- webapp
SkyWalking拷贝的东西(172.16.255.149 172.16.255.150),然后启动命令同上即可
--- agent
截图