Hadoop伪分布式的搭建
这里我使用的hadoop的版本为hadoop2.5.0-cdh5.3.6。传送门:下载地址
安装步骤:
1.创建用户,使用hadoop用户
2.修改主机名以及ssh免密码登录
3.jdk安装
4.hadoop安装
1.1步骤:
1. 使用useradd hadoop添加用户
2. 使用passwd hadoop设置用户密码,密码自拟
3. 给用户赋予使用sudo命令的权限。
4. chmod u+w /etc/sudoers
6. vim /etc/sudoers
7. 在root ALL=(ALL) ALL下面加上一行hadoop ALL=(ALL) ALL。(分隔的是制表符)
8. chmod u-w /etc/sudoers
2.1Hadoop环境搭建-修改主机名以及ssh免密码登录
步骤:(使用hadoop用户登录)
1. 使用sudo hostname hadoop修改主机名,当前生效,重启后失效。
2. 使用vim /etc/sysconfig/network修改主机名,重启生效。
3. 在/etc/hosts文件中添加主机名对于的ip地址。
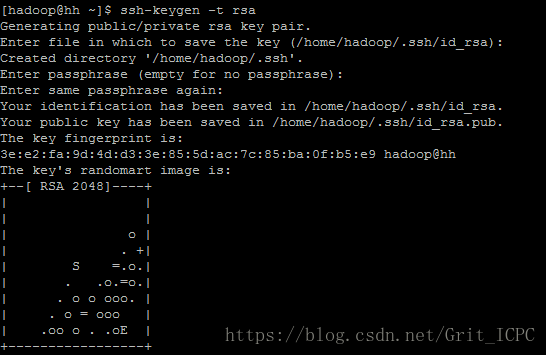
4. 使用ssh-keygen -t rsa生成ssh秘钥。dsa
5. 进入.ssh文件夹,创建authorized_keys文件,并将id_rsa.pub的内容添加到文件中去,修改文件权限为600(必须)。
6. ssh hh验证

3.1步骤:
1. 复制jdk压缩包到softs文件夹中
2. 解压tar -zxvf softs/jdk-7u79-linux-x64.tar.gz
3. 创建软连接sudo ln -s /home/hadoop/bigdater/jdk1.7.0_79 /usr/local/jdk
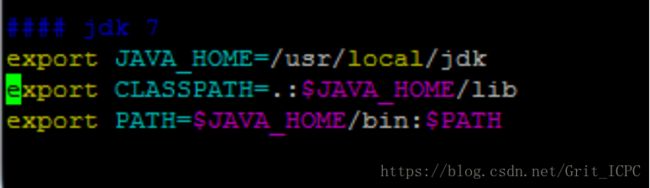
4. 配置相关环境变量vim ~/.bash_profile: JAVA_HOME, CLASSPATH, PATH。全局生效配置文件/etc/profile。
5. 使环境变量生效 source ~/.bash_profile
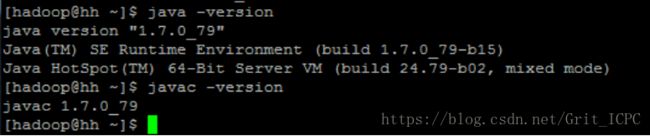
7. 验证java version/ javac version
4.1Hadoop环境搭建-hadoop安装
步骤:
1. 下载hadoop安装包并复制到到softs文件夹中。
2. 解压tar -zxvf softs/hadoop-2.5.0-cdh5.3.6.tar.gz,并创建数据保存文件hdfs(~/bigdater/hadoop-2.5.0-cdh5.3.6/hdfs/)。
3. 配置hadoop-env.sh mapred-env.sh yarn-env.sh文件
4. 配置基本环境变量core-site.xml文件
5. 配置hdfs相关变量hdfs-site.xml文件
7. 配置mapre相关环境变量mapred-site.xml文件
8. 配置yarn相关环境变量yarn-site.xml文件
9. 配置datanode相关变量slaves文件
10. 配置hadoop相关环境变量
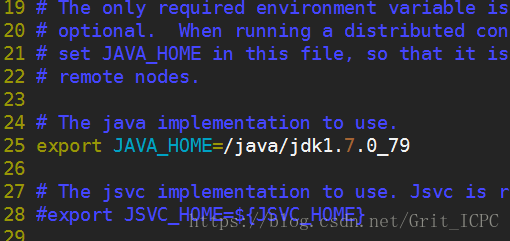
4.11 编辑文件hadoop-env.sh
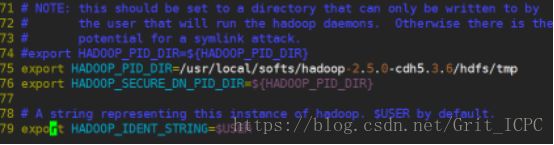
4.12 mapred-env.sh
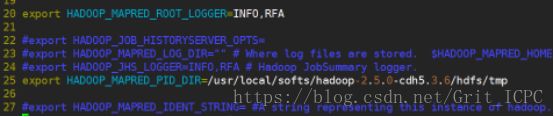
4.13 yarn-env.sh

4.14 core-site.xml
fs.defaultFS
hdfs://hadoop:8020
io.file.buffer.size
131072
hadoop.tmp.dir
/usr/local/softs/hadoop-2.5.0-cdh5.3.6/hdfs/tmp
4.15 hdfs-site.xml
dfs.namenode.name.dir
/usr/local/softs/hadoop-2.5.0-cdh5.3.6/hdfs/name
namenode 用来持续存放命名空间和交换日志的本地文件系统路径
dfs.datanode.data.dir
/usr/local/softs/hadoop-2.5.0-cdh5.3.6/hdfs/data
DataNode 在本地存放块文件的目录列表,用逗号分隔
dfs.replication
1
设定 HDFS 存储文件的副本个数,默认为1
dfs.permissions.enabled
false
4.16 mapred-site.xml
mapreduce.framework.name
yarn
4.17 yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
4.18 修改slaves文件
将文件的内容修改为 主机名称
4.19配置hadoop相关环境变量(vim /etc/profile)
#hadoop
export HADOOP_HOME=/usr/local/softs/hadoop-2.5.0-cdh5.3.6/
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_PREFIX
export HADOOP_CONF_DIR=$HADOOP_PREFIX/etc/hadoop
export HADOOP_HDFS_HOME=$HADOOP_PREFIX
export HADOOP_MAPRED_HOME=$HADOOP_PREFIX
export HADOOP_YARN_HOME=$HADOOP_PREFIX
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
5. Hadoop环境搭建-hadoop启动
步骤:
1. 第一次启动hadoop之前需要格式化namenode节点,命令为hadoop namenode -format。
2. 两种方式启动start-all.sh或者start-hdfs.sh start-yarn.sh。
3. 查看是否启动成功。
6.Hadoop环境搭建-验证hadoop是否启动成功
步骤:
1. 验证hadoop是否启动成功有两种方式,第一种:通过jps命令查看hadoop的进行是否启动,第二种:查看web界面是否启动显示正常内容。
2. 验证hadoop对应的yarn(MapReduce)框架是否启动成功:直接运行hadoop自带的example程序。
使用hadoop自带的mapreduce程序验证:/home/hadoop/bigdater/hadoop-2.5.0-cdh5.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar
将文件内容添加上去后执行:hadoop jar hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar wordcount /test.txt output/1234