ms计算机视觉:深度学习方向
图像识别、物体检测、图像切割(分割)
一、图像识别
这里的图像识别是指给定框好的图像,然后判断图像的类型,属于图像分类的问题,或者判断两个人脸是否为同一张人脸等等,
主要涉及深度学习的分类问题,
重点是CNN的几个经典分类网络:LeNet、AlexNet、ZFNet、VGG、GoogleNet、ResNet、Densenet,以及人脸识别网络FaceNet
1.CNN几个经典网络介绍:https://blog.csdn.net/gui694278452/article/details/88567689
2.Facenet网络介绍:https://juejin.im/entry/5b0e0d98f265da092d519b0a
(DLib或者MTCNN进行人脸的检测,在使用opencv的仿射变换进行人脸的对齐)
二、图像检测
图像检测是指在图像中框出物体的位置并识别物体的类别(调用上面说的图像识别技术)
主要涉及深度学习的模型如下:
RCNN、SPP-Net 、fast-rcnn 、faster-rcnn 、ssd 、yolo以及专门针对人脸的dlib和mtcnn
1.目标检测rcnn系列:https://blog.csdn.net/linolzhang/article/details/54344350
rcnn SPP-Net fast-rcnn faster-rcnn
rcnn:
(1)Region Proposal提取2k个候选框,归一化处理(裁剪放大),进入cnn提取特征,进入分类器分类和边界回归
存在问题:
a.候选框要预先提取,占空间
b.cnn维度固定,需对图像裁剪拉伸,导致信息丢失
c.proposal region需要cnn计算,耗时
SPP-Net
(2)取消了crop/warp图像归一化过程,解决图像变形导致的信息丢失以及存储问题
采用空间金字塔池化替换了全连接层之前的最后一个池化层
a.SPP放在所有的卷积层之后,有效解决了卷积层重复计算的问题
FAST RCNN(首次提出roi,还不是end-to-end)
(1)提出ROI池化层,同时加入了反向传播
(2)多层Loss,分类和边界回归统一
FASTER RCNN(首个end-to-end)
(1)添加额外的RPN分支,将候选框提取合并到深度网络中

MASK RCNN(加入物体分隔功能)
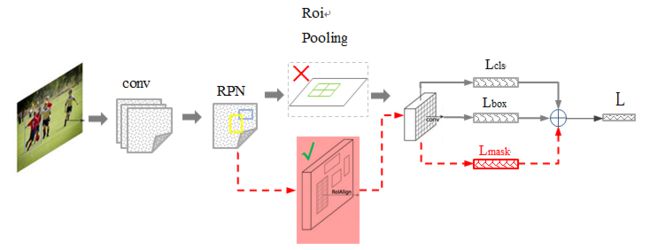
(1)将Roi Pooling 层替换成了 RoiAlign
(2)添加并列的FCN层
YOLO(You Only Look Once)
SSD(Single Shot MultiBox Detector)
三、Faster Rcnn详解
feature map:一次量化
roi pooling:又一次量化
1.Conv layers,提取feature maps,用于后面的rpn和roi层,对所有卷积做了扩边处理,pad=1,kernel_size=3,pad=1, stride=1,卷积后与原来的位置一一对应。(经典CNN网络,VGG,inception)原图:800*600,下采样16倍,feature map
ceil(800/16) * ceil(600/16)
2.rpn:使用RPN(区域候选网络)生成检测框,速度非常快,实现了end-to-end,传统的滑动窗口和Selective Search很耗时
每个feature map的点有9个anchor,anchor个数=ceil(800/16) * ceil(600/16) * 9
2个loss:分类,softmax,一个是检测框的回归,bounding box regression
anchor:9个规格(每个点都有9个anchor),softmax分background,
3.roi,和feature map结合,rpn输出不同的proposal boxes,cnn输入尺寸为固定值,roi,
4.classification:softmax对proposal进行分类,识别,然后再使用bounding box regression获取更高精度的
四、Yolo详解
分成7*7的框,每个框负责中心点落在框的检测,每个框有两个检测框,采用回归问题
(检测框太少,不好检测小物体)
Yolo2:特征提取器采用:darknet,13*13(小物体不够),yolo2采用Multi-scale Training 策略
五、SSD
Yolo:难以检测小目标、定位不准
(1)采用多尺寸特征图用于检测
(2)
(3)设置先验框