Hadoop-2.5.2 viewfs详解(一篇文档让你读懂viewfs)
Hadoop-2.5.2 viewfs详解
-------------------一篇文档让你读懂viewfs
简介
视图文件系统提供一种可以管理多个Hadoop文件系统命名空间(命名空间卷)的方法,在联邦模式的多个NameNode核多个命名空间场景下尤为重要,viewfs类似于某些Unix/Linux操作系统下的客户端挂载表,
它不仅可以用于创建个性化的命名空间视图,还可以创建全局化的视图
本文的指导背景是拥有多个集群,每个集群都有联邦模式集成的多个命名空间的文件hadoop系统,同时本文也描述了如何在联邦模式下使用viewfs来提供各个集群可以使用的全局命名空间,
这样应用程序可以和之前没有联邦模式之前一样操作。
老时代("联邦时代"之前)
单个命名空间的集群
以前(联邦时代之前)一个集群只有一个NameNode来管理这个集群的文件系统命名空间,假设现在有多个集群,各个集群的文件系统命名空间完全独立,没有任何交集,
同时这些物理存储在多个集群之间也不能相关共享(datanode不能在多个集群间共享)
每个集群的core-site.xml文件都有一个配置属性用于设置该集群的namenode使用哪个文件系统
上面的这个属性允许我们使用无协议的方式(斜杠打头/xx/xx)来识别相对路径在集群的namenode中的具体位置,例如,上面的配置中“/foo/bar” 就指“hdfs://namenodeOfClusterX:port/foo/bar”
这个配置属性需要配置在集群中通讯的地方和集群的核心服务里,比如JobTracker和Oozie
路径名使用规则
集群中的core-site.xml像上面配置之后,几个典型的路径如下:
1./foo/bar
这个等价于hdfs://namenodeOfClusterX:port/foo/bar
2.hdfs://namenodeOfClusterX:port/foo/bar
尽管这个路径是有效的,我们还是建议使用/foo/bar,这样以后数据可以在必要的时候进行集群间的转移
3.hdfs://namenodeOfClusterY:port/foo/bar
这个指另外一个集群的路径,比如ClusterY,值得一提的是下面的命令可以实现从cluster Y拷贝文件到Cluster Z
distcp hdfs://namenodeClusterY:port/pathSrc hdfs://namenodeClusterZ:port/pathDest
4.webhdfs://namenodeClusterX:http_port/foo/bar and hftp://namenodeClusterX:http_port/foo/bar
上面的方式是通过WebHDFS和HFTP协议这两种文件系统对文件进行访问,注意:WEBHDFS和HFTP都使用namenode的http端口而不是RPC端口
5.http://namenodeClusterX:http_port/webhdfs/v1/foo/bar and http://proxyClusterX:http_port/foo/bar
上面的这两种方式是通过WEBHDFS rest风格的API和HDFS代理的方式对文件进行访问
路径使用的最佳实践
集群中我们建议使用(1)的相对路径的方式而不是(2)使用发全路径的方式,全路径就像一个完整地址一样,这样应用将不会允许跨集群间的数据转移
新时代-联邦和视图文件系统
集群的样子
假如我们现在有多个集群,每个集群至少有一个Namenode,每个namenode都有各自独立的命名空间,一个namenode同时只能属于且仅一个集群,同一个集群内的namenode可以共享集群的存储,
跨集群间的命名空间和之前一样独立
我们可以决定每个namenode存储对应的哪些数据,例如,我们可以把用的数据/user/xxx在其中一个namenode里,所有的数据源数据放在另一个namenode下的/data目录,
所有的项目数据/projects再放在另外一个namenode中
每个集群的全局命名空间都视图文件系统
为了兼容之前的“老时代”,视图文件系统(客户端的挂载表)允许在每个集群上创建独立的集群命名空间,这个和之前的命名空间很相似,客户端的挂载表和Unix挂载表比较像,
同时可以使用老的命名规范来挂载到一个新的命名空间卷上,下面的视图可以看到一个挂载表下有4个命名空间卷/user, /data, /projects和 /tmp:
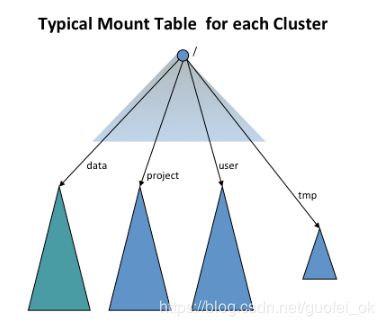
视图文件系统实现了hadoop文件系统的接口,就像Hdfs和本地文件系统一样,如果从他允许挂载到其他文件系统上看的话这个确实不怎么重要,
但是他实现了Hadoop文件系统的接口后就可以作为hadoop的工具了,例如,所有的shell命令都允许视图文件系统来和hdfs和本地文件系统一起使用
挂载表里面的挂载点是配置在标准的hadoop配置文件中,每个集群的默认文件系统都被设置如下的挂载表(对比之前的单个namenode集群的配置)
viewfs之后跟着的就是挂载表的名字(上面就是clusterX),建议挂载表的名字保持和集群名一致,从而hadoop系统会从配置中间中找到这个clusterX对应的挂载表
所有集群通讯和提供服务的点都需要配置这些挂载表,对于每个集群而言,默认的文件系统像之前描述的那样,会设置成文件系统系统的挂载表的方式。
路径使用的最佳实践
集群中的core-site.xml像上面配置挂载表之后,几个典型的路径如下:
1./foo/bar
这个等价于 viewfs://clusterX/foo/bar,如果这个配置在“老时代”里,可以直接过渡到联邦环境
2.viewfs://clusterX/foo/bar
尽管这个路径是有效的,我们还是建议使用/foo/bar,这样以后数据可以在必要的时候进行集群间的转移
3.viewfs://clusterY/foo/bar
这个指另外一个集群的路径,比如ClusterY,值得一提的是下面的命令可以实现从cluster Y拷贝文件到Cluster Z
distcp viewfs://clusterY:/pathSrc viewfs://clusterZ/pathDest
4.viewfs://clusterX-webhdfs/foo/bar and viewfs://clusterX-hftp/foo/bar
上面的方式是通过WebHDFS和HFTP协议这两种文件系统对文件进行访问,注意:WEBHDFS和HFTP都使用namenode的http端口而不是RPC端口
5.http://namenodeClusterX:http_port/webhdfs/v1/foo/bar and http://proxyClusterX:http_port/foo/bar(小郭飞飞刀注解:注意这里仍然是http协议)
上面的这两种方式是通过WEBHDFS rest风格的API和HDFS代理的方式对文件进行访问
路径使用的最佳实践
集群中我们建议使用(1)的相对路径的方式而不是(2)使用发全路径的方式,还有应用程序不应该使用已有的挂载点指向一个特定的namenode(hdfs://namenodeContainingUserDirs:port/joe/foo/bar),
应该直接使用 /user/joe/foo/bar
不同命名空间建的路径重命名
我们还记得在“老时代”里不同namenode或集群间不能随意重命名文件或者目录,但是“新时代”这个不是完全禁用的,新时代里我们可以像下面一样操作
rename /user/joe/myStuff /data/foo/bar
但是如果/user/和/data属于一个集群的不同的Namenode,这个操作也会被禁止
FAQ:
1。我从非联邦世界迁移到联邦世界,我想把namenode挂载不同的卷上,我怎么实现呢?
不可以,看上面的例子,你可以使用默认文件系统的相对路径的特性,还可以把hdfs://namenodeCLusterX/foo/bar改为 viewfs://clusterX/foo/bar.
2.集群内如果从一个namenode迁移文件到另外一个namenode会发生什么.
跨namenode之间的文件转义可能是为了解决存储问题,这样操作可以避免程序被打断,我们来举个栗子
栗子1:/user 和 /data属于同一个namenode管理,为了解决存储问题,我们需要把他们转移出去,说实在的,操作将为/user和/data创建单独的挂载点。
在更改/user和/data的挂载之前,会指向相同的namenode,比如namenodeContainingUserAndData,操作将更新挂载表,
以便将挂载点分别更改为namenodeContaingUser和namenodeContainingData
栗子2:目前所有的项目都在一个namenode里,我们想要更多的namenode,视图文件系统像 /project/foo 和 /project/bar允许挂载表更新到对应的namenode里。
3.挂载表是否存在每个core-site.xml文件或者单独的文件里?
首先挂载表需要单独存在在一个文件中,core-site.xml使用xincluding指向这个文件,尽管每个机器可以在本地保留一份这个文件,但是还是建议使用http的方式从配置中心拉取
4.每个集群的挂载表定义一定要一致吗?
是的,因为这样的话跨集群间数据转移就可以正常进行,比如distcp
5.如果操作可能随着时间的推移而更改挂载表,那么挂载表实际读取的时间是什么时候?
当job被提交到集群上的时候挂载表配置会被读取,core-site.xml中的XInclude在Job提交的时候也会读到,这意味着,如果挂载表被更改,
则需要重新提交作业。由于这个原因,我们希望实现合并挂载,这将大大减少更改挂载表的需要。此外,我们希望将来通过作业开始时初始化的另一种机制读取挂载表。
6.jobtrack(或者YARN的RM)也会用视图文件系统吗?
不需要,NodeManager也不需要
7.视图文件操作系统是否只允许挂载在根目录
不是的,但是一般情况下是挂在根目录下的,例如,你可以挂载到 /user/joe和/user/jane,这样的话, 挂载表中就会为/user创建一个内部的只读目录, 除/user是只读的外,对/user的所有操作都是有效的
8.一个应用程序需要在不同集群中使用,数据持久化的时候路径应该怎么写呢?
你可以使用viewfs://cluster/path这样的路径来命名你的路径,应用程序跑的时候就正常可以用了,只要显性地对文件进行移动操作,就可以避免在集群内的namenode中移动数据,不同集群间数据的移动不会被禁止,
但是老的联邦之前的系统就不会这么保护你了。
9. 委托令牌是什么?
提交作业的集群的委托令牌(包括该集群的挂载表的所有挂载卷)以及map-reduce作业的输入和输出路径(包括通过挂载表挂载指定输入和输出路径的所有卷)都将自动处理。此外,
还有一种方法可以为特殊情况向基本集群配置添加额外的委托令牌
附录: 一个挂载表的配置例子
一般情况下,我们不需要定义挂载表或者配置core-site.xml,这些只需要在通讯节点上进行配置就可以了
挂载表可以在core-site.xml中进行配置,但是最好建议在core-site.xml配置文件中指定一个单独的配置文件,比如moutntable.xml,把下面的配置元素加载core-site.xml里面
mountTable.xml中,比如下面的挂载表ClusterX就表示一个虚拟的联邦集群,这个集群有三个namenode,同时管理3个命名空间卷
nn1-clusterx.example.com:8020,
nn2-clusterx.example.com:8020,
nn3-clusterx.example.com:8020.
在这里/home/和/tmp被nn1-clusterx.example.com:8020管理, /foo和/bar挂在归其他联邦集群管理,home目录设置为/home方面用户可以直接使用FileSystem/FileContext中的getHomeDirectory()方法访问home目录