《码出高效:java开发手册》读书笔记
- 二进制的原码、补码、反码、移码
原码:就是早期用来表示数字的一种方式: 一个正数,转换为二进制位就是这个正数的原码。负数的绝对值转换成二进制位然后在高位补1就是这个负数的原码
反码:正数的反码就是原码,负数的反码等于原码除符号位以外所有的位取反
补码:正数的补码与原码相同,负数的补码为 其原码除符号位外所有位取反(得到反码了),然后最低位加1.
移码:(又叫增码)是符号位取反的补码
正数的反码和补码都与原码相同。
负数的反码为对该数的原码除符号位外各位取反。
负数的补码为对该数的原码除符号位外各位取反,然后在最后一位加1
各自的优缺点:
原码最好理解了,但是加减法不够方便,还有两个零。。
反码稍微困难一些,解决了加减法的问题,但还是有有个零
补码理解困难,其他就没什么缺点了
- 浮点数
浮点数由符号位、有效数字、指数三部分组成。



说明:
第0位用s表示。s=1表示负数,s=0表示正数。s即符号位(Sign)。
第[1,7]位用E表示。称为指数。E即指数(Exponent)
第[8,31]位用M表示。称为尾数。M即尾数(Mantissa)
若E全0,则尾数附加位为0。否则尾数附加位为1。
一个Float浮点数的值为:Value = (-1)^s *(1+M)*2^(E-127)
浮点数值 = -1*2^(129-127)*(2^0+2^-2)
float:2^23 = 8388608,一共七位,这意味着最多能有7位有效数字,但绝对能保证的为6位,也即float的精度为6~7位有效数字;
- 乱码产生的原因
最开始的计算机都是国外人员使用,在进行编码的时候,只需要表示24个英文字母、一些符号就行,没有多少,所有使用2的8次方-1,128中字符就足够了,其中一位作为奇偶校验位。这就是ASCLL码,但是汉字那么多,仅仅靠ASCLL码肯定不行,必选增加,所有有了GB2312(看名字知道是国人用的)以及后来的GBK(国标扩展)还有后来的GB18030都是国人的自己的编码表,最后由国际组织统一发布了UniCode 就是现在常用的UTF-8,UTF-16等,可以理解成一种压缩方式。
- TCP/IP协议
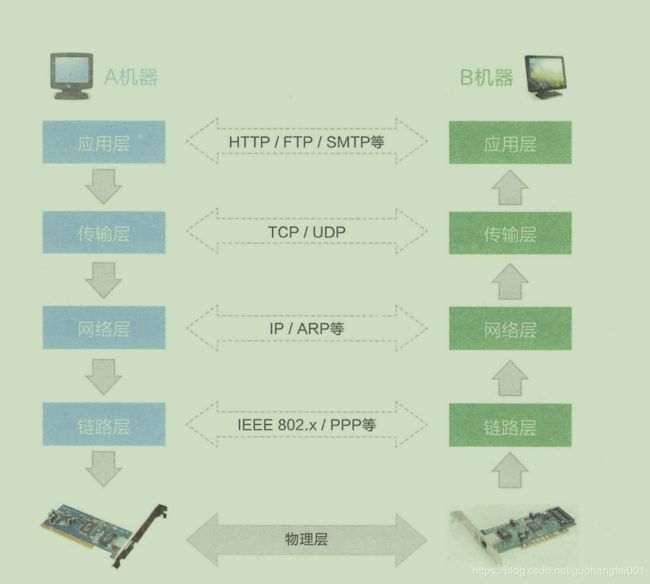
在程序发送数据的时候,应用层按照既定的协议打包数据,随后又传输层加上双方的端口号,由网络层加上双方的IP地址,又链路层加上双方的mac地址(根据ip路由表决定下一网络在哪,但是最终需要通过mac地址(外层包装)来决定传送给谁)并将数据拆分成数据帧,经过多个路由器和网关后,达到目标机器。简单的说就是按照“端口-IP地址-MAC地址”这样的路径进行数据的封装和发送,解包的时候反过来操作即可!



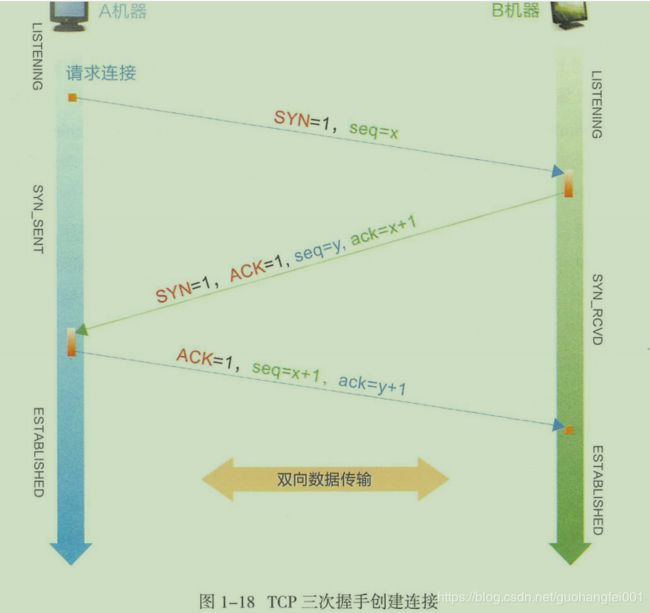
- TCP三次握手协议
为什么是三次?因为只用通过三次握手才能完全确认链接正常!

其中TCP报文SYN和ACK标志位很重要。SYN(Synchronize Sequence Number)用作建立链接时候同步信号,ACK(Acknowledgement)对于收到的数据进行确认,所收到的数据由确认序列表示!
如果只使用两次握手,可能会造成脏链接,因为TTL( Time To Live- IP包被路由器丢弃之前允许通过的最大网段数量,这个时间设置是为了防止信息在网络上无限期的存在)的存在时间可能超过TCP请求超时时间,如果两次握手可以建立链接。那么当超时请求链接A->B,B同意建立链接,返回数据B-A,链接建立!如果是三次握手,B会向A同意却请求链接,但是A的SYN_SEND状态错误,直接丢弃链接!
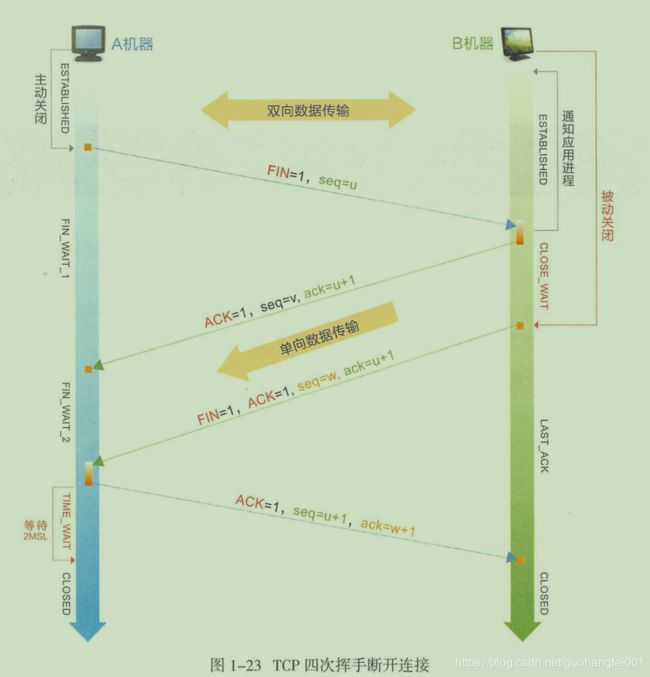
断开TCP链接需要4次握手协议,举个简单的例子,A和B都在吃饭(链接转态),两人预定一起去玩游戏,A已经吃完了,A->B说一会去shopping,B->A,我吃饭了就去。吃完了告诉你。B吃完了,B->A ,我吃完了,走吧!A->B好的走,有其他安排给我说,别放我鸽子!A等待一会,没有消息!链接断开!
- 连接池
数据库层面的请求应答时间必须在100ms以内,秒级的SQL查询通常存在巨大的性能提升空间,主要有一下几种方案;
-
- 建立高效且合适的索引
- 排查链接资源未显示关闭的情形
- 合理拆分多个表join的sql,若超过三个表则禁止join。同时最好保持关联字段数据类型一致,且应确保关联字段有索引
- 使用临时表
- 信息安全
Sql注入:防止方法:过滤特殊字符,禁止使用字符串拼接的SQL语句,严格使用参数绑定传入的SQL查询;合理使用数据库访问框架提供的防止SQL注入的机制,例如mybatis的中#{},不要使用${};
XSS=Cross-Site Scripte(和CSS冲突了,所有叫XSS),XSS是在正常用户请求的HTML页面中执行了黑客提供的恶意代码
实例 :http://xss.demo/self-xss.jsp?userName=张三
&errorMessage=XSS示例