CNN for NLP——Convolutional Neural Networks for Sentence Classification
又要开始一段看论文的调研生活了。那我开始翻译整理论文了。
《Convolutional Neural Networks for Sentence Classification》
这是一篇很经典的用卷积神经网络做文本分类的文章。
作者是纽约大学(New York University)的 Yoon Kim
github是 https://github.com/yoonkim/CNN_sentence (代码也有)
Abstract
报告了一系列CNN的实验(experiment),这些卷积神经网络在预先训练的单词向量的基础上进行训练,以进行句子级 的分类任务。
本文讨论的CNN模型改进了7个任务中的4个任务的现有技术水平,其中包括情感分析和问题分类
Introduction
[这段话挺重要,说到了一些关于CNN在NLP上的研究]
Convolutional neural networks (CNN) utilize layers with convolving filters that are applied to local features (LeCun et al., 1998).
Originally invented for computer vision, CNN models have subsequently been shown to be effective for NLP and have achieved excellent results in semantic parsing (Yih et al., 2014), search query retrieval (Shen et al., 2014), sentence modeling (Kalchbrenner et al., 2014), and other traditional NLP tasks (Collobert et al., 2011).
语义分析(Yih et al.,2014),搜索查询检索(Shen et al.,2014),句子建模(Kalchbrenner et al.,2014)和其他传统的NLP任务(Collobert et al.,2011)
Model
下图 Figure 1 所示的模型架构是Collobert等人(2011年)的CNN架构的一个细微变体。
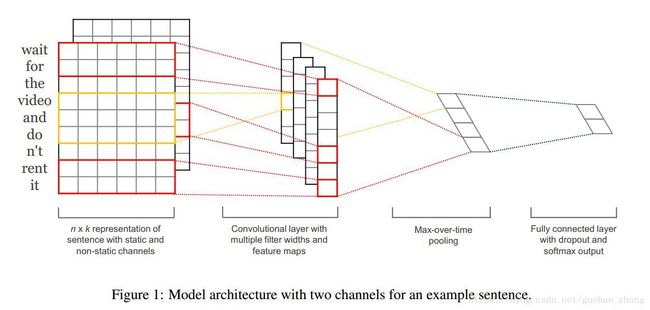
问题定义以及卷积过程
下面形式化定义一下问题:
xi∈Rk x i ∈ R k 为句子中第 i i 个单词对应的 k k 维词向量
长度为n的句子表示为:(padded where necessary 必要时填充)
其中⊕是连接运算符。
【注意,这里的 xi x i 是300维!这里的卷积的最小单位是 xi x i ,这里跟图像处理或者其他深度学习任务有点不一样的】
卷积核包含一个滤波器(filter) w∈Rhk w ∈ R h k :应用于 h h 个词单词的窗口产生一个新的特征,例如:
一个特征 ci c i is generated from a window of words xi:i+h−1 x i : i + h − 1 by:
b∈R b ∈ R 是偏置项, f f 是一个非线性函数,如双曲正切(the hyperbolic tangent)。
然后一个句子就被这样卷积成了:
max-overtime pooling operation:
^ = maxfcg
作为对应于这个特定滤波器 filter 的特征.
The model uses multiple filters (with varying window sizes) to obtain multiple features.
模型采用不同的滤波器 filter (不同的时间窗口)
These features form the penultimate layer and are passed to a fully connected softmax layer whose output is the probability distribution over labels.
这些特征形成倒数第二层并传递到完全连接的softmax层,其输出是标签上的概率分布。
变体
【这个模型对我来说挺重要,我得看仔细点】
【就像计算机视觉那样,其中彩色图像具有红色,绿色和蓝色通道 channels】
在其中一个模型变体中,我们试验了两个词向量的“通道” ( two ‘channels’ of word vectors) —— 一个在整个训练过程中保持静态,另一个通过反向传播进行 fine-tune(第3.2节)。【那我直接跳过去】
在多通道架构中,如图1所示,每个滤波器都应用于两个通道,结果被添加到方程(2)中计算ci。 该模型在其他方面等同于单通道架构
- CNN-multichannel: A model with two sets of word vectors. Each set of vectors is treated as a ‘channel’ and each filter is applied to both channels, but gradients are backpropagated only through one of the channels. Hence the model is able to fine-tune one set of vectors while keeping the other static. Both channels are initialized with word2vec
两组词向量,一组一个通道。
filter作用于两个channels
但是梯度只通过其中一个通道反向传播。
因此,该模型能够微调一组矢量,同时保持其他静态。 两个通道都使用word2vec进行初始化
理论上就这样的了,下面直接来看代码好了。
先载入各种东西:
from keras.layers import Input, Dense, Embedding, Conv2D, MaxPool2D
from keras.layers import Reshape, Flatten, Dropout, Concatenate
from keras.callbacks import ModelCheckpoint
from keras.optimizers import Adam
from keras.models import Model
from sklearn.model_selection import train_test_split
from data_helpers import load_dataload_data 载入并预处理文本文件
print('Loading data')
x, y, vocabulary, vocabulary_inv = load_data()
# x.shape -> (10662, 56)
# y.shape -> (10662, 2)
# len(vocabulary) -> 18765
# len(vocabulary_inv) -> 18765load_data后面再说。先分析一下zhe