Java互联网架构-分布式架构Mycat的前世今生
转载自:https://www.toutiao.com/a6478223053904937486/
概述
Mycat是一个开源的分布式数据库系统,其核心功能是分表分库,即将一个大表水平分割为多个小表,存储在后端MySQL或者其他数据库里。取名Mycat原因一是简单好记,另一个则是希望未来能够入驻 Apache,Apache的开源产品Tomcat也是一只猫。
一丶 MyCAT猫的前世
最近猫为什么这么火,Apache的猫,MyCAT的猫。
差不多都长这个样

MyCAT原来本没有想着来生做猫的,因为他的前世是阿里的Cobar,
转世之后,成为了MyCAT,并且开源了,就立志做一个中国的Apache猫.
说道他的前世是阿里的Cobar, Cobar的作者离职了以后,Cobar就几乎没有进行后续开发和维护了,
后来转为开源的MyCAT,又进行了迅速的发展,现在初步统计有超过300个项目使用mycat,其中包括:
中国电信/中国联通/蒲公英传媒/天狮集团等等

为什么有这么多的知名公司使用mycat 呢, 我们看看他们的业务量,
1.安智账户系统, 数据量单表6000万条,20多张表,上亿条数据, 系统运行良好,偶尔有SQL操作迟缓的现象。
2.公安项目,20个表,30多亿条数据,选取适合的业务使用mycat
从这些项目中我们可以看出,mycat擅长对上亿条单表数据量的处理,并提供良好的实时查询服务。
而我们知道,MYSQL的库中很难处理上亿条数据的查询工作,MYCAT提高了MYSQL数据库的处理能力,
从官方的解释来看,MYCAT适合处理千亿条以下的数据,千亿条以上的数据更适合HADOOP这些系统来处理。
说了半天,什么是MYCAT呢?
MYCAT就是一个虚拟的MYSQL SERVER, 这么说可能不太理解, 但是对于应用来说,他就是一个MYSQL SERVER,
应用就像连接普通的MYSQL数据库一样的 去连接他,SQL查询、操作等等一模一样。
而MYCAT把数据库复杂的架构,以及背后复杂的分表分库的逻辑全部透明化了,MYCAT中间件连接多个MYSQL数据库,
多个数据库之间还可以做主从同步,而这一切的一切,对应用来说,只有一个数据库,那就是MYCAT。
二丶 MyCAT猫的今生
MYCAT发展到现在已经不仅仅是MYSQL的代理了,它还支持SQLSERVER/ORACLE/DB2/POSTGRESQL等主流数据库。
MYCAT还可以将一个表定义为任何一种MYCAT支持的存储方式,比如MySQL的MyISAM 表、内存表、或者MongDB这种
内存数据库上。
MYCAT这么强大,那么他的原理是不是特别的复杂,非也,Mycat 的原理可以用一个动词来形容:”拦截“
它拦截应用发送过来的SQL, 并对SQL语句进行一些特定的分析:分片分析、路由分析、读写分离分析、缓存分析等,然后将
分析后的SQL分别发送到不同的真实数据库,最后对数据库返回的结果进行处理,返回给用户。
下面列举几个MYCAT 典型的应用场景:
· 单纯的读写分离,在下面我们会有讲解如何进行Mycat下面的读写分离的配置
· 分表分库,对于超过1000万的表进行分片,最大支持1000亿的单表分片
· 多租户应用,每个应用一个库,但应用程序只连接MYCAT ,从而不改变程序本身,实现多租户
· 报表系统,借助于MYCAT的分表能力,处理大规模报表的统计
· 替代HBase, 分析大数据
· 作为海量数据实时查询的一种简单有效的解决方案, 比如100亿条数据需要在3秒内实时查询出来,此时可以考虑MYCAT
现在MYCAT社区活跃,MYCAT 周边的系统也慢慢衍生出来,慢慢的形成了MYCAT生态圈了,像MYCAT-WEB 监控,MYCAT-HA
高可用方案等等,所以MYCAT还是很值得我们学习和研究的。
三丶 十分钟安装使用
MYCAT虽然强大,但是他的安装却十分简单, 下面我们进入我们十分钟安装教程:
1.下载MYCAT安装包
在GitHub 的 MyCATApache项目下,我们找到
https://github.com/MyCATApache/Mycat-download/tree/master/1.5-RELEASE
选取 Mycat-server-1.5.1-RELEASE-20160929233042-linux.tar.gz
linux 版本进行 下载
目前1.6版本部分功能还在开发中,1.5版本比较稳定,建议下载1.5用于生产环境使用
2. 解压运行MYCAT安装包
下载文件是一个tar的linux压缩包,用解压命令
tar -zxvf Mycat-server-1.5.1-RELEASE-20160929233042-linux.tar.gz
启动命令
./mycat start|restart|stop|console 常用几项内容

日志文件
logs/wrapper.log mycat服务器日志
logs/mycat.log 数据库操作日志,分析数据库操作路由使用。
启动MyCat最主要的几个配置文件:
conf/server.xml 服务器用户、虚拟Sechma、端口等配置信息。
conf/sechma.xml 物理数据库映射。
使用MyCAT来说的话,最主要的就是修改这两个文件,接下来我们实现MYCAT下的读写分离。
四丶 MYCAT下实现读写分离
首先参考上一节MYSQL配置主从复制,配置好主从数据库之间的数据复制功能。
1.登录主服务器的mysql,查询master的状态
mysql> show master status;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000010 | 106 | db1,db2,db3 | mysql |
+------------------+----------+--------------+------------------+
Master 重启后会修改mysql-bin(序号加1)
2.查看Slave机有没有配置成功:
mysql> show slave statusG
以下两个参数必须为YES:
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
3.MyCAT的配置
不使用Mycat托管的 MySQL主从服务器
schema.xml
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
支持MySQL主从复制状态绑定的读写分离机制,让读更加安全可靠,配置如下
writeType="0" dbType="mysql" dbDriver="native" switchType="2" slaveThreshold="100">
设置 balance="1"与writeType="0"
Balance参数设置:
1. balance=“0”, 所有读操作都发送到当前可用的writeHost上。
2. balance=“1”,所有读操作都随机的发送到readHost。
3. balance=“2”,所有读操作都随机的在writeHost、readhost上分发
WriteType参数设置:
1. writeType=“0”, 所有写操作都发送到可用的writeHost上。
2. writeType=“1”,所有写操作都随机的发送到readHost。
3. writeType=“2”,所有写操作都随机的在writeHost、readhost分上发。
这样配置了以后,就已经实现了读写分离的功能, 还可以对数据库进行负载均衡
启动mycat , 用应用或者Navicat等工具 连接mycat ,端口是 8066
insert , select 进行测试。
五丶MyCAT中分表分库策略
上面只是实现了如何进行读写分离,基于数据库的主从同步复制的原理, 我们在之前的课程里已经知道,
主从同步复制的数据是 ,保证从数据库和主库的数据一模一样,也就是说数据是多复制了一份出来,
而MYCAT 只所以能支持上百亿的数据量,在于他的另一个功能:分表分库策略
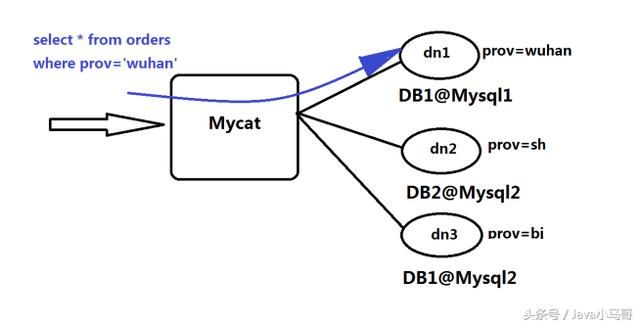
分表分库简单来说,就是MYCAT 下面连接的数据库节点,打比方说有dn1,dn2,dn3, 他们每个库中的数据
是各不相同的。
把MYCAT当做一个虚拟数据库来看,travelrecord 是MYCAT下面建的一张表, 应用调用MYCAT
库可以调用到整张表的数据, 但是如果查询某一个节点dn1 , 则只能查询到一部分数据(通常是1/3)的数据
dn1, dn2 , dn3 各自存储了一部分的数据, 但是可以通过MYCAT 来查询到整张表的数据,
这样增强了每个数据库的数据存储处理能力, 这就是MYCAT的高明之处,也就是为什么他能够处理上百亿条数据的奥妙。
这里列出一个简单的分表分库的配置:
schema.xml
在schema中 我们需要配置mycat 中的虚拟表table ,以及他的rule ,分表规则
auto-sharding-long 的意思是 事先已经定义好每个dn的 范围,根据范围划分,这个规则在rule.xml中进行配置.
datanode 的配置:
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
这样数据就是自动切分到这3个不同的datanode中了, select 取出来也是完整的数据。
分表分库还有一点窍门就是,你的数据是纵向来切,还是横向来切,
上面讲的那个是 横向来切:就是把一张表的数据 切到不同的 数据库中。
纵向切更简单,就是以表来分库, 不同的表 放到不同的库中, 表中的数据在某个库中是完整的。
六丶 MyCAT的五脏六腑
学会了MYCAT来做读写分离和分表分库的使用以后,我们应该更深入MYCAT的五脏六腑,了解MYCAT的运行机制,这样对线上的应用处理一些
应急事故,以及解决一些问题提供思路,非常的有帮助,有能力的童鞋还可以参与到MYCAT的后续开发中来。
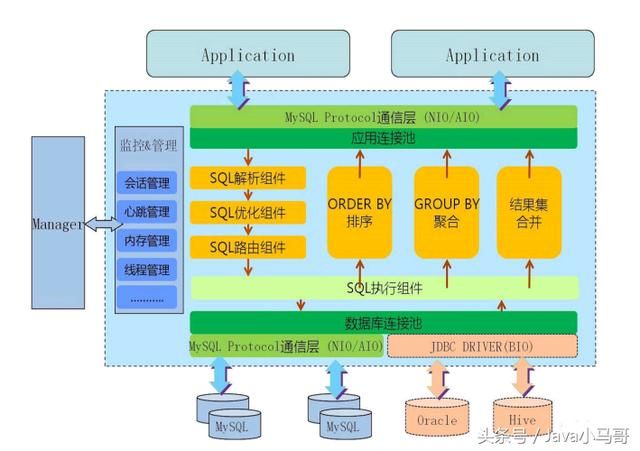
MYCAT 的后端通信采用了NIO非阻塞 和AIO 异步通信方式, 使得通信效率更高
SQL解析这一块用到了阿里的Druid进行解析
协议这一块,对于MYSQL数据库采用原生的二进制协议,还支持驱动方式的连接
并且MYCAT还增加order by , group by ,limit 等聚合功能的支持。
总结
到这里,分布式架构Mycat的前世今生就结束了,,不足之处还望大家多多包涵!!觉得收获的话可以点个关注收藏转发一波喔,谢谢大佬们支持。(吹一波,233~~)
下面和大家交流几点编程的经验:
1、多写多敲代码,好的代码与扎实的基础知识一定是实践出来的
2丶 测试、测试再测试,如果你不彻底测试自己的代码,那恐怕你开发的就不只是代码,可能还会声名狼藉。
3丶 简化编程,加快速度,代码风骚,在你完成编码后,应回头并且优化它。从长远来看,这里或那里一些的改进,会让后来的支持人员更加轻松。
最后,每一位读到这里的网友,感谢你们能耐心地看完。希望在成为一名更优秀的Java程序员的道路上,我们可以一起学习、一起进步。