web缓存技术总结
转载请注明出处,谢谢!
1 web缓存的简介
1.1 采取Web加速技术措施
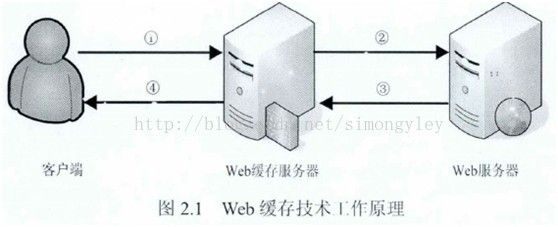
采取Web加速技术,减少用户访问的延迟。如采用Web缓存[8](Web Caching )技术、Web预取(Web Prefetching)技术、CDN ( Content Delivery Network)技术等,以此来降低用户可感知的网络访问延迟,提高网络服务质量。
典型的缓存体系结构有IRCache, Summary Cache, AWC ( Adaptive WebCaching), CRSP (Cachingand Replication for Internet Service Performance) 计划等;代表性的缓存协议有ICP ( Internet Cache Protocol,应用最广泛的Web缓存协议)、CARP ( Cache Array Routing Protocol)、HICP(Hyper Text Cache Protocol),WCCP ( Web Cache Control Protocol )等
1.2 Web缓存分类
根据Web缓存所在的网络位置:服务器端、代理服务器端、客户端,可将Web缓存分为以下三类:
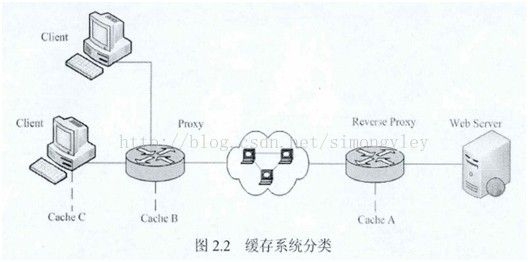
1) 服务器端缓存(Cache A )
2) 代理服务器端缓存(Cache B )
3) 客户端缓存(Cache C)
设计Web缓存系统经常面临以下问题:
1) 缓存体系结构:研究如何按层次式、分布式、混合式组织缓存系统结构。
2) 缓存策略:研究如何缓有及缓存哪些对象
3) 预取技术:研究如何建立预测模型和预取控制的模型。
4) 动态信息缓存及缓存一致性:对于动态对象,研究如何缓存动态对象及如何保持动态对象与源服务器对象一致性
1.3 Web缓存体系结构
以代理服务器端缓存为主的典型缓存体系可分为以下两类:单点Web缓存系统和协作Web缓存系统。
1.3.1单点Web缓存系统

若用户请求的内容不在缓存中,Web缓存将请求转发到Internet中的原始服务器,并根据一定的缓存替换算法决定是否把对象保存到Web缓存上,然后把请求对象发送给用户。
优点:结构简单,容易实现
缺点:可靠性差,可扩展性差
1.3.2 协作Web缓存系统
在协作环境下,由一组相互合作的缓存服务器共同服务于用户。代理缓存之间可以转发用户请求信息,当所有协作的代理都没有用户访问的请求对象时,代理服务器代表用户向Web服务器获取相应请求对象。因此应确保缓存体系结构中各代理缓存之间能够有效地合作,能保证缓存系统性能的提高。
典型的缓存体系结构有以下几种:层次式Web缓存体系结构、分布式Web缓存体系结构和混合式Web缓存体系结构。
1)层次式Web缓存体系结构
层次式Web缓存体系结构首次在Harvest项目中提出,在层次式Web缓存体系结构中,缓存在网络上呈现多级配置,并以一棵树的形状进行构建,为了节省系统开销,层次式Web缓存体系结构最多设置为三层或者四层,最下层是客户端的缓存,最一上层则直接连接服务器。如图2.4(a)所示,为简单起见,假定Web缓存层次模型有四层:底层缓存、局域层缓存、区域层缓存、广域层缓存。底层是客户/浏览器缓存,当请求的对象在底层缓存中未命中时,该请求被转发到局域层缓存,如果请求对象仍然不在局域层缓存,则该请求被转发到区域层缓存直至广域层缓存。如果请求对象不在各层缓存中,则请求被转发到服务器,由服务器响应该请求对象,然后在沿途的每级缓存中存储此请求对象 ,最后该请求对象被转发给用户。
层次式Web缓存体系结构缩短了客户端请求的距离,每层内部节点具有一定的相关性,“热点”的Web对象可以快速、高效地分布到网络中,具有提高命中率,缩短查找时间等优点。但该体系结构也存在一些缺陷,
①各缓存服务器之间需要相互合作 ,必须保证缓存服务器配置在网络中关键节点认。
②如果请求对象不在缓存中,则每一级的缓存将带来额外的访问延迟。
③由于不同的缓存中可能保存同一个对象的副本,降低了整个缓存空间利用率.
2)分布式Web缓存体系结构
分布式Web缓存体系结构把缓存设置在网络体系结构的底层,没有中间层次的缓存,各缓存之间不存在从属和层次关系。如图2.4(b)所示的分布式Web缓存结构,每一个局域层缓存都保存有其它局域层缓存的目录信息,以便快速地确定将请求发送到哪一个局域层缓存。分布式Web缓存体系结构通常采用缓存阵列路由协议CARP(Cache Array Routing protocol ),把客户端请求对象的URL空间分割成不同的部分,然后把每一部分指定给特定的缓存。此外,Cache Mesh和适应缓存也是分布式缓存系统。与层次式Web缓存体系结构的父子节点间单一的关系不同,分布式Web缓存结构中节点间的网状关系,使缓存服务器之间能够通过相互协作,提高缓存存储空间使用效率,达到均衡网络负载、减少网络拥塞发生的目的。然而,分布式Web缓存系统的配置可能会遇到一些问题,如系统管理困难、连接次数多等。
3)混合式Web缓存体系结构
混合式Web缓存体系结构 是由若干个缓存组成的分布式、层次式的一种集成的结构,如图2.4(c)所示,采用分布式缓存结构应用于同级缓存,而采用层次式缓存结构应用于较高层,混合式Web体系结构具备层次式缓存体系结构和分布式缓存体系结构的优点。研究表明,层次式Web缓存具有较短的连接时间,因此在中间层缓存中保存较小的对象可以提高访问速度;而分布式Web缓存具有较高的响应速度和有效的带宽利用率,因此将两者结合起来,同时减少连接时间和传输时间。很多国家(如美国的NLANR、英国的JANET、欧洲的CHOICE等)都建立了这样的项目,Harvest集团设计的ICP ( the Internet Cache Protocol,互联网缓存协议)协议,就是混合式缓存体系结构的一个典型代表,广泛应用于Squid和NetCache中。如何管理和配置混合式Web缓存体系结构,使混合式 Web缓存体系结构具有较低复杂性、较低冗余度和较高的命中率等优点,仍然是当前研究的热门课题。
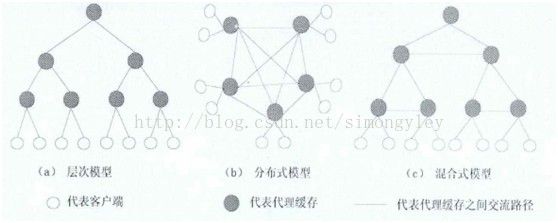
图2.4 web缓存体系结构
2 Web缓存模型描述

2.1无限缓存空间模型
如果请求对象在缓存中,则直接从缓存中获取请求对象;否则,如果请求对象不在缓存中,则将从服务器下载请求对象,并存储到缓存中以便后续访问。无限缓存空间模型的缓存空间C无限大,确实有足够空间存储请求对象而不需要使用缓存替换算法,但是此模型是一种理想化的情况,在现实生活中很难达到。

2.2 有限缓存空间模型
基本思想是:如果请求对象在缓存中,则直接从缓存中获取请求对象;否则,如果请求对象不在缓存中且剩余缓存空间足以容纳新的请求对象,则将从服务器下载请求对象并存储到缓存中以便后续用户访问;换算法选取对象Et,井将对象Et移出缓存,直到有足够的缓存空间容纳此对象。

2.3 Web缓存替换算法
在Web缓存模型中,当剩余缓存空间不足以存储新的对象时,这时需要按某种替换算法将当前不再具有存储价值的对象移出缓存;缓存替换算法需要确定移出价值较低的缓存对象以便存储新的请求对象,因此Web缓存替换算法的选取能够影响缓存系统的整体性能。当前的Web缓存替换算法有以下五种类型:
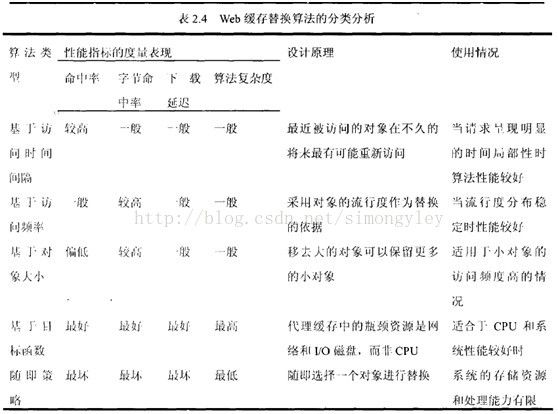
2.3.1 基于访问时间间隔的替换算法
这种替换算法的典型代表是LRU(Least Recently Used )算法。LRU替换算法基于请求访问的时间局部性原理,当发生缓存末命中时,如果请求对象的大小大于剩余缓存空间时,需要将最近最少使用的对象移出缓存,直到当前剩余缓存空间能够容纳此请求对象。从算法的描述中可以看到,LRU替换算法仅考虑对象访问的时间问隔,比较容易实现,被广泛应用在Harvest和Squid等系统中;但是LRU替换算法并没有将对象大小、访问频率、延迟时间等因素作为替换时的考虑因素,可能使缓存系统获得较低的命中率或字节命中率,例如,当有一个大的对象放入缓存,就有可能以替换出若干个小的对象为代价,这样会严重影响命中率。改进的替换算法如LRU-Threshold,在LRU替换算法的基础上,通过引入一个阈值,仅缓存对象大小低于此阈值的对象,避免因缓存一个较大的对象而移出若干个小的对象。
2.3.2基于访问频率的替换算法
这种替换算法的典型代表是LFU ( Least Frequency Used )算法。LFU算法基于对象的访问频率作为替换依据,当发生对象替换时,从缓存移出访问次数最少的对象,保留访问次数高的对象。LFU算法实现简单,因为它只需采用计数器统计每个对象的访问次数,在发生替换时,只需将访问次数最少的对象移出缓存;但是LFU算法没有考虑对象的访问时间间隔、对象大小等因素,例如,某些实时性很强的“热点”对象虽然具有较高的访问次数,但是经过一段时间以后,己经变得不再具有存储价值,如果一直保存在缓存中,会导致缓存空间的浪费,造成缓存“污染”。改进的替换算法如LFU-Aging,当发生对象替换时,除考虑对象访问次数之外,还考虑对象的“年龄”,从而避免已经失效的对象仍占据在缓存中,能够更有效地利用缓存空间。
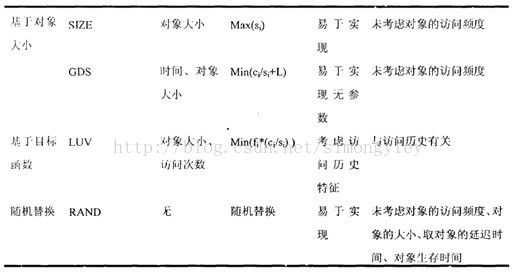
2.3.3基于对象大小的替换算法
这种算法的典型代表是SIZE算法,SIZE替换算法仅考虑对象的大小,当发生对象替换时,将从缓存中移出最大的对象。SIZE替换算法仅考虑对象大小,容易实现,由于将最大的对象移出缓存之后,会有更多的空间容纳其他请求对象,有可能提高命中率。然而,SIZE替换算法由于没有考虑对象的访问次数、访问时间间隔等因素,有可能出现刚从缓存移出的对象会被再次访问,这样不仅导致命中率的下降,也会导致用户访问速度的下降。为了避免SIZE替换算法的缺点,引入GDS替换算法,通过计算权值 ,将权值最小的对象移出缓存,其中,取对象t到缓存所产生的代价用Ct表示;对象t的大小用st表示;L是一个膨胀因子,开始时赋初值为0,当对象t被替换时就用对象的权值Kt更新L,即L=Kt.
2.3.4基于目标函数的替换算法
这种算法典型代表是LUV (Least-Unified Value)算法,LUV替换算法是针对缓存对象不一致性提出的,依照缓存对象过去的访问历史,如采用最近被访问的时间和过去被访问的次数估计对象重新被访问的可能性和对象的单元代价。采用下面的代价函数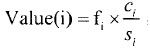 ,fi 表示对象i被访问的概率。其中,ci为取对象i的代价,si为对象i的大小;当发生缓存未命中时,将Value(i)值最小的对象移出缓存。
,fi 表示对象i被访问的概率。其中,ci为取对象i的代价,si为对象i的大小;当发生缓存未命中时,将Value(i)值最小的对象移出缓存。
2.3.5随机替换算法
这种算法的典型代表是RAND算法,当缓存空间占满时,随机地选择一个对象移出缓存,然后把需要放入的对象存储到缓存中。RAND算法对环境依赖程度较大,如在不同的环境下,采用RAND算法处理相同的请求序列,当需要发生对象替换时,由于替换时没有考虑对象的任何访问特性,导致每次替换的对象可能不一样,从而致使缓存性能不稳定。