Python练手爬虫系列No.2 抓取知乎问题下所有回答中的图片(待续)
接着上一篇Python练手爬虫系列No.1 知乎福利收藏夹图片批量下载,今天我们来按照知乎问题抓图片!比起收藏夹,更加直接精准。为什么先抓收藏夹后抓取问题呢,其实是因为知乎的一点限制。
那就是!知乎问题下方的回答是通过动态加载的……普通的静态网站抓取的办法是没办法获取到所有的数据的。
那么怎么处理呢?我们一起试试。
网页数据分析
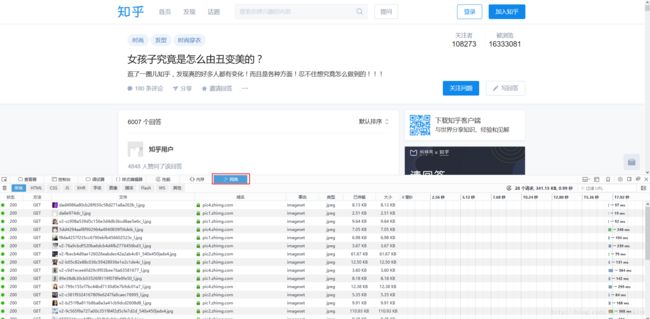
这个时候跟我做打开Firefox浏览器,按F12,进入网络模式下,图上红框所示。这个时候显示的内容,是浏览器试试加载的数据,我们首先点左上角的垃圾桶清空数据,然后用力将进度条拉倒最下面开始加载新数据
![]()
点击更多,立刻看到了这一条。这就是我们要找的,加载的请求项目
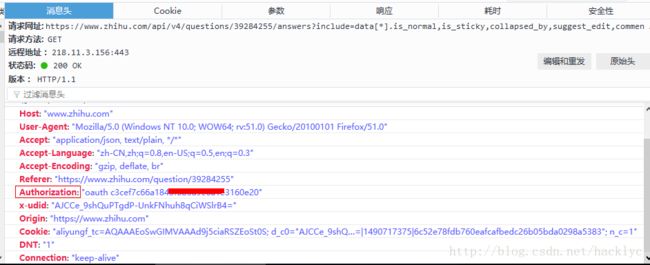
我们立刻查看下他的属性细节,可以通过查看请求头来寻找线索。
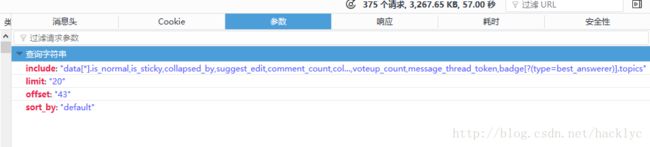
首先,这个请求是以get的形式,也就是所有参数通过组合来加载到URL上,我们可以看一下他包含的参数,基本上就是回传属性。最终组合的效果就是
“https://www.zhihu.com/api/v4/questions/39284255/answers?include=data[].is_normal,is_sticky,collapsed_by,suggest_edit,comment_count,collapsed_counts,reviewing_comments_count,can_comment,content,editable_content,voteup_count,reshipment_settings,comment_permission,mark_infos,created_time,updated_time,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,upvoted_followees;data[].author.is_blocking,is_blocked,is_followed,voteup_count,message_thread_token,badge[?(type=best_answerer)].topics&limit=20&offset=43&sort_by=default”
这一大段URL
而请求头最重要的一个参数就是
【Authorization:”oauth c3cef7c66a1843f8b……”】这一条,因此,我们提前复制下你的电脑上的数值用来测试数据。需要声明的是,登录与不登录的条件下参数不同。如果只是小规模的抓取,直接复制你电脑上的数值就好了。如果大规模的抓取……这里不做讨论,用你的oauth小心从此上不了知乎……
代码测试
import requests
import json
header = {
"Host": "www.zhihu.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate, br",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"X-Requested-With": "XMLHttpRequest",
"Referer": "https://www.zhihu.com/question/39284255",
"Authorization":"oauth c3cef7c66a1843f8b3a9e6a1e3160e",
"Connection": "keep-alive"
}
url = 'https://www.zhihu.com/api/v4/questions/39284255/answers?include=data[*].is_normal,is_sticky,collapsed_by,suggest_edit,comment_count,collapsed_counts,reviewing_comments_count,can_comment,content,editable_content,voteup_count,reshipment_settings,comment_permission,mark_infos,created_time,updated_time,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,upvoted_followees;data[*].author.is_blocking,is_blocked,is_followed,voteup_count,message_thread_token,badge[?(type=best_answerer)].topics&limit=20&offset=43&sort_by=default'
session = requests.session()
session.headers = header
resp = session.get(url)
content = json.loads(resp.content)
print(content)这里说个小技巧,header的构建最简单的办法就是……把你用浏览器查看时候的请求头全部写进去,然后一点一点去掉,找到关键要素保留之。这里访问页面使用了requests库的session功能。具体功能使用方法可以看文档。
这里的运行结果是
![]()
也就是说,他回传的是一段JSON代码。立刻 百度下JSON在线解析,解析代码

JSON的结构化展现,因为图片并没有单独罗列出来,所以不能通过JSON的结构调取,那么我们就直接用暴力法,上正则筛选吧。
import re
cont_str = resp.text
pattern = re.compile('data-original=\\"(.*?)\\"',re.S)
urls = re.findall(pattern=pattern,string=cont_str)待续……