网络蜘蛛爬虫 Scrapy - 简介&Demo
- Company: Yappam
- Date: 20150325
- Author: Yuewen Hao
序
大家都说现在是移动互联网的时代, 那么有”网”的地方, 就肯定有”蜘蛛”.
今天, 我们就来在这个连接着全世界的巨型网络中, 创造一只小小的”蜘蛛”, 去爬取我们想要的”食物”.
引
说到爬虫, 我最初接触到它, 应该是在一部关于 互联网之子 – Aaron Swartz 的记录片中, 其中, 有一个桥段:
Aaron觉得那些对人类有价值的科学和文化遗产属于全人类,美国大学每年会向那些出版学术期刊、论文的机构(比如 ISI,Jstor)支付许可费用,许可费用极高,他觉得这是这个时代的悲剧。于是完美主义的他产生了一种责任感。
这让他在2010年到2011年,在哈佛大学Edmond J. Safra研究实验室以Lab Fellow的身份主导到了“制度腐败”课题的研究。也因为这个身份,Aaron在MIT做访问学者的时候有 JSTOR的帐号可以通过MIT的网络访问大量的学术期刊。
于是,他把他的laptop放到了地下室网络交换机的机房中,直接插上网线,然后全天后地下载那些JSTOR的学术期刊。(他利用了这些学术期刊的URL链接中的规律来下载所有的期刊)
这个纪录片, 让我对互联网的自由, 开源, 分享 有了全新的定义, 感触很深; 同时也感受到 Aaron 处于这个社会的那种无助, 悲伤. 推荐热爱互联网的你去感受一下.
正文
好了, 闲话少说, 引文中 “利用 URL 链接中的规律, 下载期刊”, 便是网络爬虫的核心理念. 准确的来说, 是利用URL链接中的规律, 以及页面中要爬取内容所在位置的规则, 来下载我们需要的内容.
那么问题来了,
什么是URL 链接中的规则呢?
http://club.autohome.com.cn/bbs/thread-c-875-39780593-1.html
http://club.autohome.com.cn/bbs/thread-c-875-18770776-1.html
上面两个URL链接, 是汽车之家论坛中, 两篇文章.
做过开发的人都知道. 其他文章的URL 链接肯定也都是类似的规则.
如果按正则匹配的话, 就是:http://club.autohome.com.cn/bbs/thread-c-875*.html这就是汽车之家论坛中文章的规则, 注意: 这个只是为了举例, 实际的规则会有偏差.
什么是页面中要爬取内容所在位置的规则呢?
光看这段话, 好像有点晕, 我们把它分成一个数组来理解一下.
[“页面中要爬取内容”, “在页面中的位置”, “所在位置的规则”]好像有点懂了.
举个例子:<html> <head> <title>标题title> head> <body> <div> 要爬取的内容 <div> body> html>PATH 规则:
/html/body/div/text()按照 DOM 元素所在的位置逐级找到它 “/html/body/div”, 然后取它的文本内容 “text()”
按照我们开发网页的习惯, 我们都知道, 所有涉及到文章内容的页面, 肯定都是采用的同样一个页面模板, 页面元素的位置, 在规则上不会有太大的变动.
有了爬取的规则, 我们再编写一系列页面请求和业务处理, 自然就能爬取到各种各样, 我们所需要的”食物”了.
Coding
这里我们使用 Python 的开源框架 Scrapy, 它的 官方文档 很详细, 使用方法也很简单.
官方安装指南
简易安装介绍
入门教程
还是一样, 选择汽车之家论坛的文章标题和内容, 作为我们最终爬取的目标.
源码: autohome_bss_buick
有注释, 就不多赘述了.
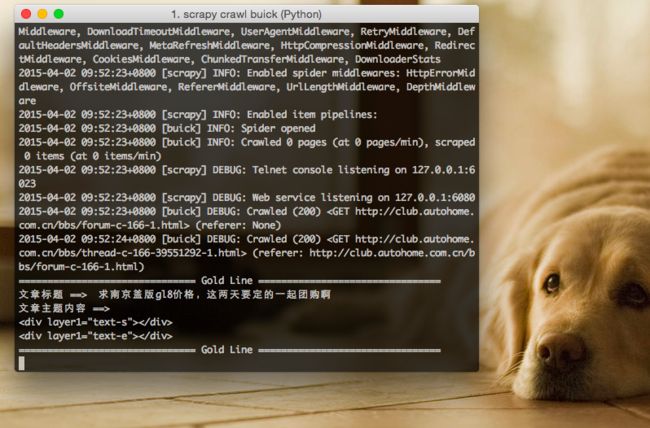
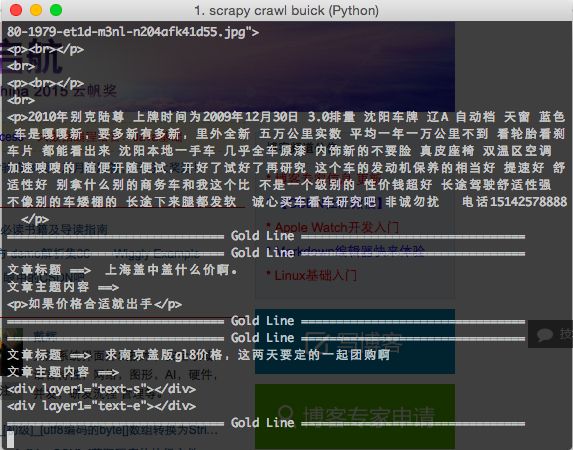
爬取的”食物”, 如图: