Hadoop3.1.1+Hbase3.0 完全分布式集群部署实战
Hadoop3.x 出来已经有一段时间了,之前安装的都是Hadoop3.0 alpha1--beta4,各个版本基本都尝试过了,
最近想, 如何把Hbase3.0 和Hadoop3.x 有机的结合在一起。 看了官方的文档后,心里凉了一大截。因为官方还没宣布正式支持。
http://hbase.apache.org/book.html#arch.overview
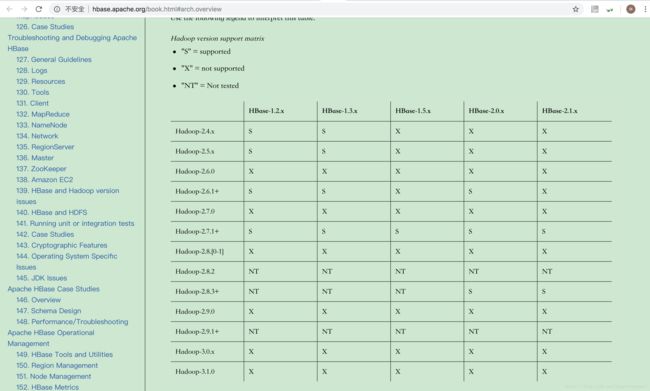
后来就干脆把Hbase 代码下载下来,自己编译了主分支master一个版本,尝试的部署看看,不行再改改代码呗。
Hadoop3.1.1+Hbase3.0 完全分布式集群部署实战
环境描述:
| 序号 | 软件名称 | 版本 | 是否必须安装 | ||
| 1 | centos7 | 1608 | 是 | ||
| 2 | jdk | 1.8.0_121 | 是 | ||
| 3 | hadoop | 3.1.0 | 是 | ||
| 4 | zookeeper | 3.5.0 | 是 | ||
| 5 | hbase | 3.0.0beta | 是 | ||
| 6 | ntp-server | 4.2.6p5 | 是(可以用互联网的 ) | ||
| 7 | lsof | 4.8.7 | 否(网络诊断工具) | ||
| 8 | ntp-client | 4.2.6p5 | 是 |
| 序号 | 虚拟机名 | IP | 安装软件 | 备注 |
| 1 | zka1 | 10.20.2.51 | zookeeper ntp-client | |
| 2 | zka2 | 10.20.2.52 | zookeeper ntp-client | |
| 3 | zka3 | 10.20.2.53 | zookeeper ntp-client | |
| 4 | zka4 | 10.20.2.54 | zookeeper ntp-client | |
| 5 | zka5 | 10.20.2.55 | zookeeper ntp-client | |
| 6 | hadoop-namenode1 | 10.20.2.1 | namenode ntp-client | |
| 7 | hadoop-namenode2 | 10.20.2.2 | namenode ntp-client | |
| 8 | hadoop-namenode3 | 10.20.2.3 | namenode ntp-client | |
| 9 | hadoop-datanode1 | 10.20.2.11 | datanode ntp-client | |
| 10 | hadoop-datanode2 | 10.20.2.12 | datanode ntp-client | |
| 11 | hadoop-datanode3 | 10.20.2.13 | datanode ntp-client | |
| 12 | hadoop-datanode4 | 10.20.2.14 | datanode ntp-client | |
| 13 | hadoop-datanode5 | 10.20.2.15 | datanode ntp-client | |
| 14 | hadoop-datanode6 | 10.20.2.16 | datanode ntp-client | |
Centos7 1608 Linux 4.4.58-1.el7.elrepo.x86_64 #1 SMP Thu Mar 30 11:18:53 EDT 2017 x86_64 x86_64 x86_64 GNU/Linux
jdk1.8
虚拟机部署形式 vsphere6.5 Esxi6.0 虚拟化平台
all_hosts:
zookeeper-hosts:
- name: "zka1.yourdomain.com"
uuid: "zka1.yourdomain.com"
ip: "10.20.2.51"
cpu: "1"
memory: "4096" # 600MB 以上
disk: 30
username: "root"
password: "yourpassword"
datastore: "cw_m4_pcie_datastore1"
host_machine: "192.168.5.11"
- name: "zka2.yourdomain.com"
uuid: "zka2.yourdomain.com"
ip: "10.20.2.52"
cpu: "1"
memory: "4096"
disk: 30
username: "root"
password: "yourpassword"
datastore: "cw_m4_pcie_datastore2"
host_machine: "192.168.5.11"
- name: "zka3.yourdomain.com"
uuid: "zka3.yourdomain.com"
ip: "10.20.2.53"
cpu: "1"
memory: "4096"
disk: 30
username: "root"
password: "yourpassword"
datastore: "cw_m4_pcie_datastore1"
host_machine: "192.168.5.11"
- name: "zka4.yourdomain.com"
uuid: "zka4.yourdomain.com"
ip: "10.20.2.54"
cpu: "1"
memory: "4096"
disk: 30
username: "root"
password: "yourpassword"
datastore: "cw_m4_pcie_datastore2"
host_machine: "192.168.5.11"
- name: "zka5.yourdomain.com"
uuid: "zka5.yourdomain.com"
ip: "10.20.2.55"
cpu: "1"
memory: "4096"
disk: 30
username: "root"
password: "yourpassword"
datastore: "cw_m4_pcie_datastore1"
host_machine: "192.168.5.11"
hadoop-namenode-hosts:
- name: "hadoop-namenode1.yourdomain.com"
uuid: "hadoop-namenode1.yourdomain.com"
ip: "10.20.2.1"
cpu: "6"
memory: "20480"
disk: "100"
username: "root"
password: "yourpassword"
datastore: "cw_m4_pcie_datastore1"
host_machine: "192.168.5.11"
- name: "hadoop-namenode2.yourdomain.com"
uuid: "hadoop-namenode2.yourdomain.com"
ip: "10.20.2.2"
cpu: "6"
memory: "20480"
disk: "100"
username: "root"
password: "yourpassword"
datastore: "cw_m4_pcie_datastore1"
host_machine: "192.168.5.11"
- name: "hadoop-namenode3.yourdomain.com"
uuid: "hadoop-namenode3.yourdomain.com"
ip: "10.20.2.3"
cpu: "6"
memory: "20480"
disk: "100"
username: "root"
password: "yourpassword"
datastore: "cw_m4_pcie_datastore2"
host_machine: "192.168.5.11"
hadoop-datanode-hosts:
- name: "hadoop-datanode1.yourdomain.com"
uuid: "hadoop-datanode1.yourdomain.com"
ip: "10.20.2.11"
cpu: "6"
memory: "20480"
disk: "200"
username: "root"
password: "yourpassword"
datastore: "cw_m4_pcie_datastore1"
host_machine: "192.168.5.11"
- name: "hadoop-datanode2.yourdomain.com"
uuid: "hadoop-datanode2.yourdomain.com"
ip: "10.20.2.12"
cpu: "6"
memory: "20480"
disk: "200"
username: "root"
password: "yourpassword"
datastore: "cw_m4_pcie_datastore2"
host_machine: "192.168.5.11"
- name: "hadoop-datanode3.yourdomain.com"
uuid: "hadoop-datanode3.yourdomain.com"
ip: "10.20.2.13"
cpu: "6"
memory: "20480"
disk: "200"
username: "root"
password: "yourpassword"
datastore: "cw_m4_pcie_datastore2"
host_machine: "192.168.5.11"
- name: "hadoop-datanode4.yourdomain.com"
uuid: "hadoop-datanode4.yourdomain.com"
ip: "10.20.2.14"
cpu: "6"
memory: "20480"
disk: "800"
username: "root"
password: "yourpassword"
datastore: "cw_m4_sas_datastore"
host_machine: "192.168.5.11"
- name: "hadoop-datanode5.yourdomain.com"
uuid: "hadoop-datanode5.yourdomain.com"
ip: "10.20.2.15"
cpu: "6"
memory: "20480"
disk: "800"
username: "root"
password: "yourpassword"
datastore: "cw_m4_sas_datastore"
host_machine: "192.168.5.11"
- name: "hadoop-datanode6.yourdomain.com"
uuid: "hadoop-datanode6.yourdomain.com"
ip: "10.20.2.16"
cpu: "6"
memory: "20480"
disk: "800"
username: "root"
password: "yourpassword"
datastore: "cw_m4_sas_datastore"
host_machine: "192.168.5.11"
以上是我在实际环境中部署成功的实例,部署时间全程大概:20分钟,采用ansible 自动化部署
部署过程:
1.先自动化从虚拟机模版部署虚拟机到vsphere 6.0 平台, 自动化扩容磁盘,自动化设置IP 掩码, dns (ansible自动化部署)
2.安装 zookeeper 集群 (ansible自动化部署), 安装ssh-passwordless-login
3.安装hadoop3.1.1集群 (ansible自动化部署) 安装ssh-passwordless-login
4.安装zookeeper 集群 (ansible 自动化部署) 安装ssh-passwordless-login
详细请见: 之前写的 Ansible实现Linux SSH免密码登陆的role模块 https://mp.csdn.net/postedit/82709963
zookeeper /etc/hosts 内容如下
[root@zka1 ~]# more /etc/hosts
# Ansible managed
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
#格式类似
#192.168.12.21 master.yourdomain.com master
10.20.2.51 zka1.yourdomain.com zka1
10.20.2.52 zka2.yourdomain.com zka2
10.20.2.53 zka3.yourdomain.com zka3
10.20.2.54 zka4.yourdomain.com zka4
10.20.2.55 zka5.yourdomain.com zka5
hadoop ,hbase
每个虚拟机/etc/hosts 文件内容如下
# Ansible managed
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.20.2.1 hadoop-namenode1.yourdomain.com hadoop-namenode1
10.20.2.2 hadoop-namenode2.yourdomain.com hadoop-namenode2
10.20.2.3 hadoop-namenode3.yourdomain.com hadoop-namenode3
10.20.2.11 hadoop-datanode1.yourdomain.com hadoop-datanode1
10.20.2.12 hadoop-datanode2.yourdomain.com hadoop-datanode2
10.20.2.13 hadoop-datanode3.yourdomain.com hadoop-datanode3
10.20.2.14 hadoop-datanode4.yourdomain.com hadoop-datanode4
10.20.2.15 hadoop-datanode5.yourdomain.com hadoop-datanode5
10.20.2.16 hadoop-datanode6.yourdomain.com hadoop-datanode6
hadoop 关键配置文件如下:
=================
[hadoop@hadoop-namenode1 hadoop]$ more core-site.xml
more hdfs-site.xml
sshfence
shell(/bin/true)
more yarn-site.xml
more mapred-site.xml
more slaves
10.20.2.11
10.20.2.12
10.20.2.13
10.20.2.14
10.20.2.15
10.20.2.16
[hadoop@hadoop-namenode1 hadoop]$ more datanode-hosts
10.20.2.11
10.20.2.12
10.20.2.13
10.20.2.14
10.20.2.15
10.20.2.16
[hadoop@hadoop-namenode1 hadoop]$ more datanode-hosts-exclude
10.20.2.1
10.20.2.2
10.20.2.3
[hadoop@hadoop-namenode1 hadoop]$ more datanode-hosts-exclude
10.20.2.1
10.20.2.2
10.20.2.3
[hadoop@hadoop-namenode1 hadoop]$ more hadoop-env.sh
#!/bin/bash
export JAVA_HOME=/var/server/jdk
export JRE_HOME=$JAVA_HOME/jre
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:.
export PATH
export HADOOP_PREFIX=/var/server/hadoop
#export HADOOP_HOME=/var/server/hadoop
export PATH=$PATH:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin
[hadoop@hadoop-namenode1 hadoop]$ more yarn-env.sh
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
##
## THIS FILE ACTS AS AN OVERRIDE FOR hadoop-env.sh FOR ALL
## WORK DONE BY THE yarn AND RELATED COMMANDS.
##
## Precedence rules:
##
## yarn-env.sh > hadoop-env.sh > hard-coded defaults
##
## YARN_xyz > HADOOP_xyz > hard-coded defaults
##
###
# Resource Manager specific parameters
###
# Specify the max heapsize for the ResourceManager. If no units are
# given, it will be assumed to be in MB.
# This value will be overridden by an Xmx setting specified in either
# HADOOP_OPTS and/or YARN_RESOURCEMANAGER_OPTS.
# Default is the same as HADOOP_HEAPSIZE_MAX
#export YARN_RESOURCEMANAGER_HEAPSIZE=
# Specify the JVM options to be used when starting the ResourceManager.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# Examples for a Sun/Oracle JDK:
# a) override the appsummary log file:
# export YARN_RESOURCEMANAGER_OPTS="-Dyarn.server.resourcemanager.appsummary.log.file=rm-appsummary.log -Dyarn.server.resourcemanager.appsummary.logger=INFO,RMSUMMARY"
#
# b) Set JMX options
# export YARN_RESOURCEMANAGER_OPTS="-Dcom.sun.management.jmxremote=true -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.port=1026"
#
# c) Set garbage collection logs from hadoop-env.sh
# export YARN_RESOURCE_MANAGER_OPTS="${HADOOP_GC_SETTINGS} -Xloggc:${HADOOP_LOG_DIR}/gc-rm.log-$(date +'%Y%m%d%H%M')"
#
# d) ... or set them directly
# export YARN_RESOURCEMANAGER_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -Xloggc:${HADOOP_LOG_DIR}/gc-rm.log-$(date +'%Y%m%d%H%M')"
#
#
# export YARN_RESOURCEMANAGER_OPTS=
###
# Node Manager specific parameters
###
# Specify the max heapsize for the NodeManager. If no units are
# given, it will be assumed to be in MB.
# This value will be overridden by an Xmx setting specified in either
# HADOOP_OPTS and/or YARN_NODEMANAGER_OPTS.
# Default is the same as HADOOP_HEAPSIZE_MAX.
#export YARN_NODEMANAGER_HEAPSIZE=
# Specify the JVM options to be used when starting the NodeManager.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# See ResourceManager for some examples
#
#export YARN_NODEMANAGER_OPTS=
###
# TimeLineServer specific parameters
###
# Specify the max heapsize for the timelineserver. If no units are
# given, it will be assumed to be in MB.
# This value will be overridden by an Xmx setting specified in either
# HADOOP_OPTS and/or YARN_TIMELINESERVER_OPTS.
# Default is the same as HADOOP_HEAPSIZE_MAX.
#export YARN_TIMELINE_HEAPSIZE=
# Specify the JVM options to be used when starting the TimeLineServer.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# See ResourceManager for some examples
#
#export YARN_TIMELINESERVER_OPTS=
###
# TimeLineReader specific parameters
###
# Specify the JVM options to be used when starting the TimeLineReader.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# See ResourceManager for some examples
#
#export YARN_TIMELINEREADER_OPTS=
###
# Web App Proxy Server specifc parameters
###
# Specify the max heapsize for the web app proxy server. If no units are
# given, it will be assumed to be in MB.
# This value will be overridden by an Xmx setting specified in either
# HADOOP_OPTS and/or YARN_PROXYSERVER_OPTS.
# Default is the same as HADOOP_HEAPSIZE_MAX.
#export YARN_PROXYSERVER_HEAPSIZE=
# Specify the JVM options to be used when starting the proxy server.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# See ResourceManager for some examples
#
#export YARN_PROXYSERVER_OPTS=
###
# Shared Cache Manager specific parameters
###
# Specify the JVM options to be used when starting the
# shared cache manager server.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# See ResourceManager for some examples
#
#export YARN_SHAREDCACHEMANAGER_OPTS=
#HDFS_DATANODE_OPTS=
#YARN_RESOURCEMANAGER_OPTS=
#YARN_NODEMANAGER_OPTS=
#YARN_PROXYSERVER_OPTS=
#MAPRED_HISTORYSERVER_OPTS=
#
#export YARN_RESOURCEMANAGER_HEAPSIZE=500
#export YARN_NODEMANAGER_HEAPSIZE=500
#export YARN_PID_DIR=/var/run/hadoop/yarn
export YARN_LOG_DIR=/var/server/yarn/logs
#export HADOOP_YARN_HOME=/var/server/yarn
[hadoop@hadoop-namenode1 hadoop]$ more mapred-env.sh
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
##
## THIS FILE ACTS AS AN OVERRIDE FOR hadoop-env.sh FOR ALL
## WORK DONE BY THE mapred AND RELATED COMMANDS.
##
## Precedence rules:
##
## mapred-env.sh > hadoop-env.sh > hard-coded defaults
##
## MAPRED_xyz > HADOOP_xyz > hard-coded defaults
##
###
# Job History Server specific parameters
###
# Specify the max heapsize for the JobHistoryServer. If no units are
# given, it will be assumed to be in MB.
# This value will be overridden by an Xmx setting specified in HADOOP_OPTS,
# and/or MAPRED_HISTORYSERVER_OPTS.
# Default is the same as HADOOP_HEAPSIZE_MAX.
#export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=
# Specify the JVM options to be used when starting the HistoryServer.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#export MAPRED_HISTORYSERVER_OPTS=
# Specify the log4j settings for the JobHistoryServer
# Java property: hadoop.root.logger
#export HADOOP_JHS_LOGGER=INFO,RFA
#
#
#export JAVA_HOME=/usr/lib/jvm/java-1.6.0-openjdk-1.6.0.0.x86_64/ export HADOOP_MAPRED_IDENT_STRING=mapred
#export HADOOP_MAPRED_PID_DIR=/var/run/hadoop/mapred
#export HADOOP_MAPRED_LOG_DIR==/var/log/hadoop/mapred
#export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=250
#export HADOOP_MAPRED_HOME=/var/server/mapred
export HADOOP_CONF_DIR=$HADOOP_PREFIX/etc/hadoop
export HADOOP_PID_DIR=/var/server/hadoop/tmp
export HADOOP_LOG_DIR=/var/server/hadoop/logs
#HADOOP_HEAPSIZE_MAX=5g
#to do 改成根据内存大小来设置.
export HDFS_NAMENODE_OPTS="-XX:+UseParallelGC -Xmx19055m"
#HDFS_DATANODE_OPTS=
#YARN_RESOURCEMANAGER_OPTS=
#YARN_NODEMANAGER_OPTS=
#YARN_PROXYSERVER_OPTS=
#MAPRED_HISTORYSERVER_OPTS=
export HDFS_NAMENODE_USER=hadoop
export HDFS_DATANODE_USER=hadoop
export HDFS_JOURNALNODE_USER=hadoop
export HDFS_ZKFC_USER=hadoop
export YARN_NODEMANAGER_USER=yarn
export YARN_RESOURCEMANAGER_USER=yarn
=======================
HBase 集群配置:
[hadoop@hadoop-namenode1 conf]$ more hbase-site.xml
[hadoop@hadoop-namenode1 conf]$ more hbase-env.sh
#!/usr/bin/env bash
#
#/**
# * Licensed to the Apache Software Foundation (ASF) under one
# * or more contributor license agreements. See the NOTICE file
# * distributed with this work for additional information
# * regarding copyright ownership. The ASF licenses this file
# * to you under the Apache License, Version 2.0 (the
# * "License"); you may not use this file except in compliance
# * with the License. You may obtain a copy of the License at
# *
# * http://www.apache.org/licenses/LICENSE-2.0
# *
# * Unless required by applicable law or agreed to in writing, software
# * distributed under the License is distributed on an "AS IS" BASIS,
# * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# * See the License for the specific language governing permissions and
# * limitations under the License.
# */
# Set environment variables here.
# This script sets variables multiple times over the course of starting an hbase process,
# so try to keep things idempotent unless you want to take an even deeper look
# into the startup scripts (bin/hbase, etc.)
# The java implementation to use. Java 1.8+ required.
# export JAVA_HOME=/usr/java/jdk1.8.0/
# Extra Java CLASSPATH elements. Optional.
# export HBASE_CLASSPATH=
# The maximum amount of heap to use. Default is left to JVM default.
# export HBASE_HEAPSIZE=1G
#这个内存必须留50%以上给hadoop进程使用,请不要全部用完.
export HBASE_HEAPSIZE=9G
# Uncomment below if you intend to use off heap cache. For example, to allocate 8G of
# offheap, set the value to "8G".
# export HBASE_OFFHEAPSIZE=1G
# Extra Java runtime options.
# Below are what we set by default. May only work with SUN JVM.
# For more on why as well as other possible settings,
# see http://hbase.apache.org/book.html#performance
#export HBASE_OPTS="$HBASE_OPTS -XX:+UseConcMarkSweepGC"
#下面这个参数仅作为调试参数使用临时使用,实际产品中请不要这样设置,会影响性能的.
export HBASE_OPTS="$HBASE_OPTS -XX:+UseConcMarkSweepGC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:/var/server/hbase/logs/gc-hbase.log"
# Uncomment one of the below three options to enable java garbage collection logging for the server-side processes.
# This enables basic gc logging to the .out file.
# export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps"
# This enables basic gc logging to its own file.
# If FILE-PATH is not replaced, the log file(.gc) would still be generated in the HBASE_LOG_DIR .
# export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:
# This enables basic GC logging to its own file with automatic log rolling. Only applies to jdk 1.6.0_34+ and 1.7.0_2+.
# If FILE-PATH is not replaced, the log file(.gc) would still be generated in the HBASE_LOG_DIR .
# export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:
# Uncomment one of the below three options to enable java garbage collection logging for the client processes.
# This enables basic gc logging to the .out file.
# export CLIENT_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps"
# This enables basic gc logging to its own file.
# If FILE-PATH is not replaced, the log file(.gc) would still be generated in the HBASE_LOG_DIR .
# export CLIENT_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:
# This enables basic GC logging to its own file with automatic log rolling. Only applies to jdk 1.6.0_34+ and 1.7.0_2+.
# If FILE-PATH is not replaced, the log file(.gc) would still be generated in the HBASE_LOG_DIR .
# export CLIENT_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:
# See the package documentation for org.apache.hadoop.hbase.io.hfile for other configurations
# needed setting up off-heap block caching.
# Uncomment and adjust to enable JMX exporting
# See jmxremote.password and jmxremote.access in $JRE_HOME/lib/management to configure remote password access.
# More details at: http://java.sun.com/javase/6/docs/technotes/guides/management/agent.html
# NOTE: HBase provides an alternative JMX implementation to fix the random ports issue, please see JMX
# section in HBase Reference Guide for instructions.
# export HBASE_JMX_BASE="-Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false"
# export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10101"
# export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10102"
# export HBASE_THRIFT_OPTS="$HBASE_THRIFT_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10103"
# export HBASE_ZOOKEEPER_OPTS="$HBASE_ZOOKEEPER_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10104"
# export HBASE_REST_OPTS="$HBASE_REST_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10105"
# File naming hosts on which HRegionServers will run. $HBASE_HOME/conf/regionservers by default.
# export HBASE_REGIONSERVERS=${HBASE_HOME}/conf/regionservers
# Uncomment and adjust to keep all the Region Server pages mapped to be memory resident
#HBASE_REGIONSERVER_MLOCK=true
#HBASE_REGIONSERVER_UID="hbase"
# File naming hosts on which backup HMaster will run. $HBASE_HOME/conf/backup-masters by default.
# export HBASE_BACKUP_MASTERS=${HBASE_HOME}/conf/backup-masters
# Extra ssh options. Empty by default.
# export HBASE_SSH_OPTS="-o ConnectTimeout=1 -o SendEnv=HBASE_CONF_DIR"
# Where log files are stored. $HBASE_HOME/logs by default.
# export HBASE_LOG_DIR=${HBASE_HOME}/logs
# Enable remote JDWP debugging of major HBase processes. Meant for Core Developers
# export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8070"
# export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8071"
# export HBASE_THRIFT_OPTS="$HBASE_THRIFT_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8072"
# export HBASE_ZOOKEEPER_OPTS="$HBASE_ZOOKEEPER_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8073"
# A string representing this instance of hbase. $USER by default.
# export HBASE_IDENT_STRING=$USER
# The scheduling priority for daemon processes. See 'man nice'.
# export HBASE_NICENESS=10
# The directory where pid files are stored. /tmp by default.
export HBASE_PID_DIR=/var/server/hbase/pids
# Seconds to sleep between slave commands. Unset by default. This
# can be useful in large clusters, where, e.g., slave rsyncs can
# otherwise arrive faster than the master can service them.
# export HBASE_SLAVE_SLEEP=0.1
# Tell HBase whether it should manage it's own instance of ZooKeeper or not.
# export HBASE_MANAGES_ZK=true
export HBASE_MANAGES_ZK=false
# The default log rolling policy is RFA, where the log file is rolled as per the size defined for the
# RFA appender. Please refer to the log4j.properties file to see more details on this appender.
# In case one needs to do log rolling on a date change, one should set the environment property
# HBASE_ROOT_LOGGER to "
# For example:
# HBASE_ROOT_LOGGER=INFO,DRFA
# The reason for changing default to RFA is to avoid the boundary case of filling out disk space as
# DRFA doesn't put any cap on the log size. Please refer to HBase-5655 for more context.
#HBase 远程调试用途,用Intellij idea
#export HBASE_OPTS="$HBASE_OPTS -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005"
[hadoop@hadoop-namenode1 conf]$
[hadoop@hadoop-namenode1 conf]$ more regionservers
hadoop-datanode1
hadoop-datanode2
hadoop-datanode3
hadoop-datanode4
hadoop-datanode5
hadoop-datanode6
部署注意事项: 1.每个步骤完成后要验证确认是否功能正常,特别是zookeeper
=======
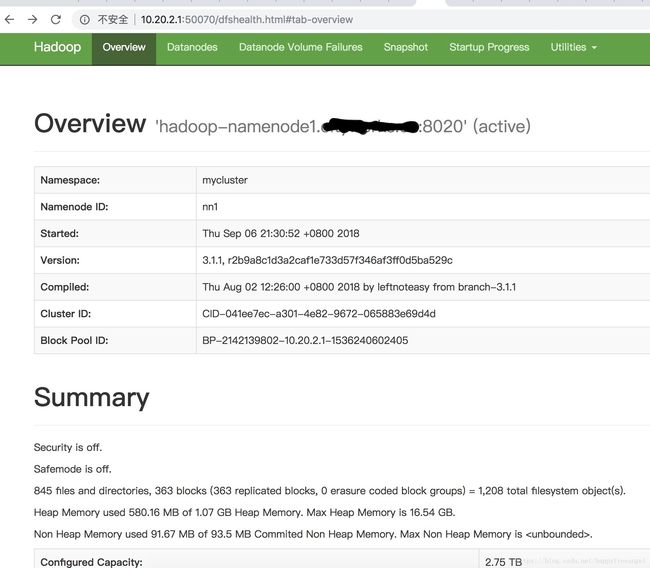
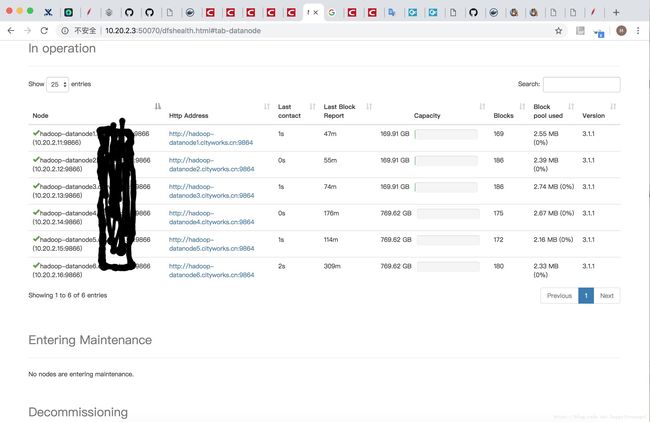
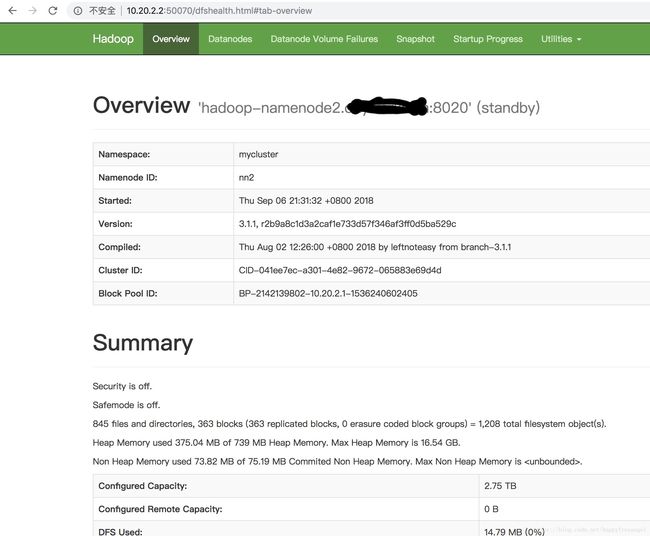
部署成功图片:
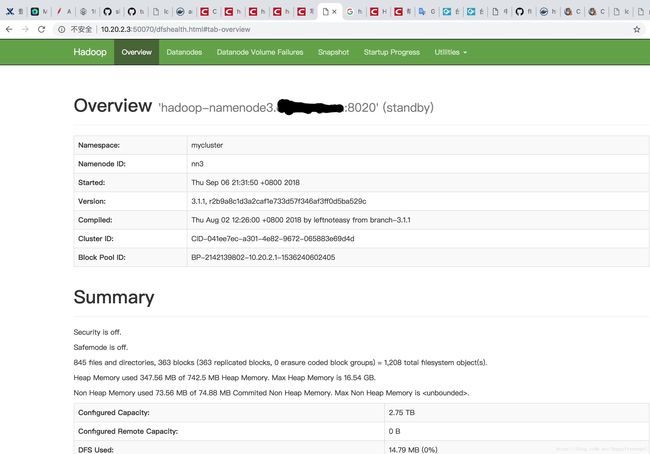
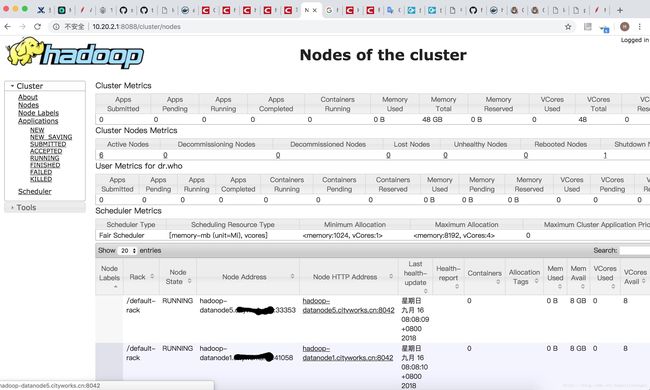
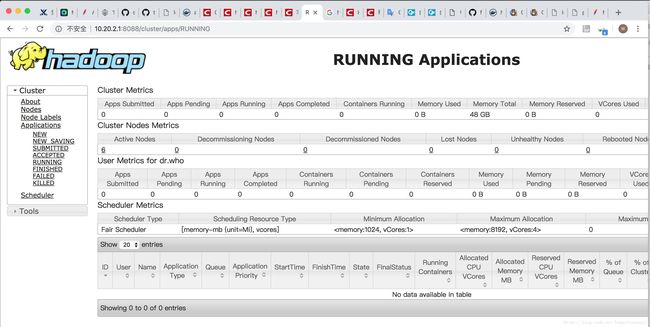
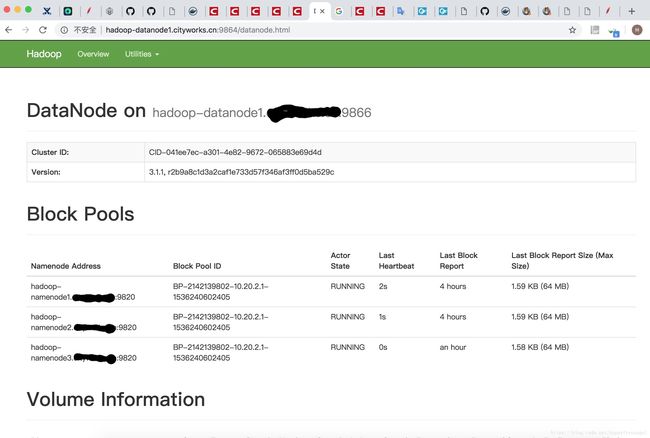
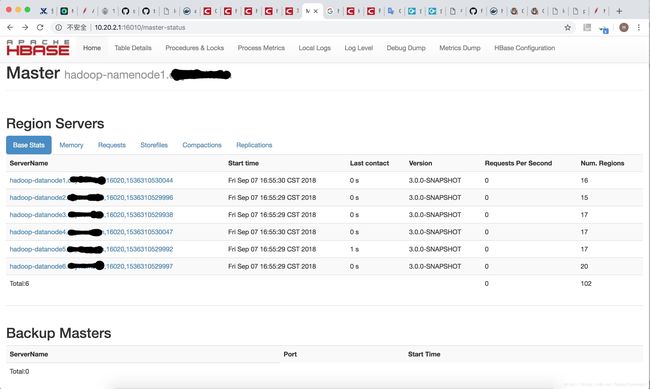
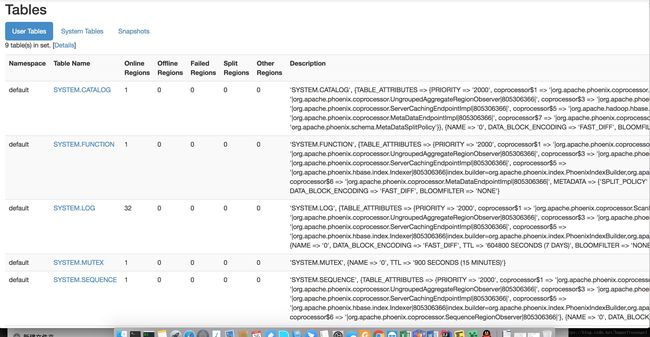
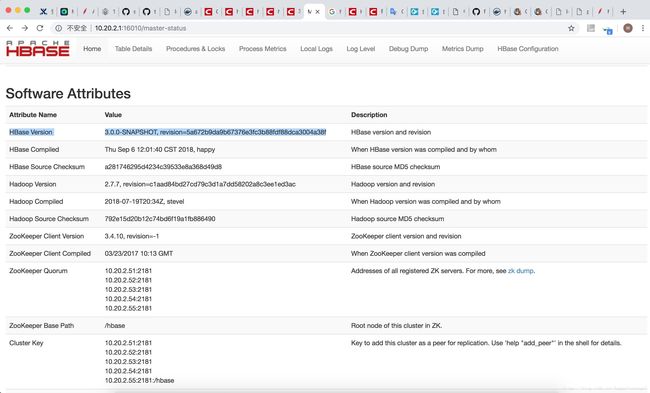
其中遇到的坑: 1.zookeeper 脚本代码问题,导致zookeeper 集群 不正常,每个都是standalone,
正确状态是1个 master,其他都是flower 状态,
$ echo stat | nc 10.20.2.51 2181
Zookeeper version: 3.5.4-beta-7f51e5b68cf2f80176ff944a9ebd2abbc65e7327, built on 05/11/2018 16:27 GMT
Clients:
/10.20.2.62:42470[1](queued=0,recved=382499,sent=382499)
/10.20.2.35:47972[1](queued=0,recved=57326,sent=57326)
/10.20.2.11:60420[1](queued=0,recved=56997,sent=56998)
/10.20.2.12:53410[1](queued=0,recved=56997,sent=56998)
/10.20.2.81:60520[1](queued=0,recved=242163,sent=242164)
/192.168.2.33:65388[0](queued=0,recved=1,sent=0)
/10.20.2.82:59600[1](queued=0,recved=242175,sent=242178)
/10.20.2.61:58280[1](queued=0,recved=382661,sent=382665)
/10.20.2.65:54374[1](queued=0,recved=382493,sent=382493)
Latency min/avg/max: 0/0/108
Received: 1818069
Sent: 1818138
Connections: 9
Outstanding: 0
Zxid: 0x100001d52
Mode: follower
Node count: 288
echo stat | nc 10.20.2.55 2181
Zookeeper version: 3.5.4-beta-7f51e5b68cf2f80176ff944a9ebd2abbc65e7327, built on 05/11/2018 16:27 GMT
Clients:
/10.20.2.64:48084[1](queued=0,recved=382519,sent=382519)
/10.20.2.31:57072[1](queued=0,recved=57337,sent=57337)
/192.168.2.33:65413[0](queued=0,recved=1,sent=0)
/10.20.2.81:49774[1](queued=0,recved=152869,sent=152871)
/10.20.2.75:56022[1](queued=0,recved=1101402,sent=1101402)
Latency min/avg/max: 0/0/105
Received: 1709308
Sent: 1709355
Connections: 5
Outstanding: 0
Zxid: 0x100001d52
Mode: leader
Node count: 288
Proposal sizes last/min/max: 92/32/54063
echo conf | nc 10.20.2.55 2181
clientPort=2181
secureClientPort=-1
dataDir=/var/server/zookeeper/data/version-2
dataDirSize=67108880
dataLogDir=/var/server/zookeeper/log/version-2
dataLogSize=653
tickTime=2000
maxClientCnxns=2048
minSessionTimeout=4000
maxSessionTimeout=40000
serverId=5
initLimit=20
syncLimit=5
electionAlg=3
electionPort=3888
quorumPort=2888
peerType=0
membership:
server.1=10.20.2.51:2888:3888:participant
server.2=10.20.2.52:2888:3888:participant
server.3=10.20.2.53:2888:3888:participant
server.4=10.20.2.54:2888:3888:participant
server.5=10.20.2.55:2888:3888:participant