《R语言数据挖掘》读书笔记:二、频繁模式、关联规则和相关规则挖掘
第二章、频繁模式、关联规则和相关规则挖掘
关联规则挖掘算法可以从多种数据类型中发现频繁项集,包括数值数据和分类数据,基础算法有Apriori算法和FP-Growth算法。
1.关联模式和关联规则
1.1 模式和模式发现(频繁模式可以有以下几种形式)
1.1.1频繁项集
项集:项集就是项的集合,例如:{矿泉水,泡面,火腿} 这是一个3项集,项集的出现频度是包含项集的事务数,把它记作支持度计数,通俗的来说,假设有三个顾客分别买了{矿泉水,泡面,火腿}、{矿泉水,泡面,火腿、牛栏山}、{矿泉水,火腿}。那么这个3项集的支持度计数就是2。
频繁项集:如果我们预定义的支持度计数是2,也就是此时的支持度计数阈值为2,而上述的3项集的支持度计数是2,所以该3项集是频繁项集。
Apriori原理:如果某个项集是频繁的,那么该项集的任何一个子集也一定是频繁的。
为优化频繁项集生成算法,提出一些概念:闭项集、最大频繁项集、约束频繁项集、近似频繁项集、top-k频繁项集
1.1.2频繁子序列
频繁子序列是元素的一个有序列表,其中每个元素包含至少一个事件。
序列包含的项数定义为序列的长度,长度为k的序列定义为k序列。子序列和超序列是对应的
1.1.3频繁子结构
在某些领域中,研究任务可借助图论来进行建模,子图就是一个子结构,如果频繁就成为了频繁子结构。
1.2 关系和规则发现(基于已发现的频繁模式,可以挖掘关联规则,根据关系的兴趣度不同侧重点,有下面两种类型的关系)
1.2.1关联规则
关联分析可以从数据集中发现有意义的关系,这种关系可以表示成关联规则或频繁项集的形式。
当X∩Y=∅(X,Y不相交),则X—>Y是关联规则。规则的兴趣度通过支持度和置信度测量。
支持度表示数据集中规则出现的频率。
置信度测量在X出现的前提下,Y出现的可能性。
可能遇到的不同种类的规则:布尔关联规则、单维(指的维度上的关系)关联规则、多维关联规则、相关关联规则、定量关联规则(至少一个项或属性是定量的)
1.2.2相关规则
在某些情况下,仅仅凭借支持度和置信度不足以过滤掉无意义的关联规则,此时需要利用支持计数、置信度和相关性对关联规则进行筛选。
计算关联规则的相关性的一些方法:卡方分析、全置信度分析、余弦分析等。
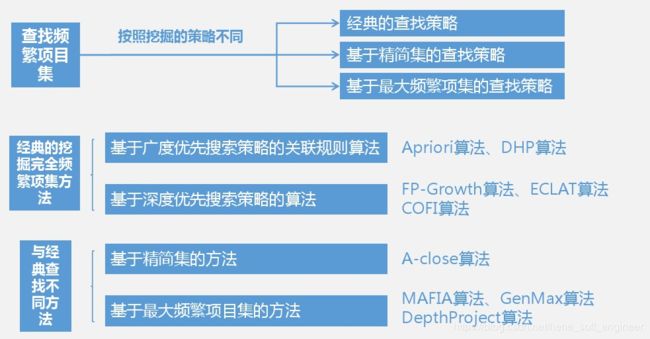
2.购物篮分析(用来挖掘消费者已购买或保存在购物车中物品组合规律的方法)
2.1 购物篮模型
说明购物篮和其关联的商品之间的关系的模型。
Apriori算法是逐层挖掘项集的算法。与Apriori算法不同,Eclat算法是基于事务标识项集合交集的TID集合交集项集的挖掘算法,而FP-Growth算法是基于频繁模式树的算法。TID集合表示交易记录标识号的集合。
以下2.2——2.6都是来寻找频繁项集的算法策略(其中Apriori算法是基础,其他为改进算法)
2.2 Apriori算法
Apriori算法挖掘关联规则可以分解为以下两个问题:1.频繁项集生成 2.关联规则生成
具体参考算法解析: https://blog.csdn.net/huihuisd/article/details/86489810
2.3 Eclat算法
Apriori算法循环的次数与模式的最大长度是一样的。Eclat算法是为了减少循环次数而设计的算法,数据输入格式是样本购物篮文件中的垂直格式(从事务数据集中发现的频繁模式)
具体参考算法解析: https://blog.csdn.net/ARPOSPF/article/details/86632408
2.4 FP-growth算法
该算法是在大数据集中挖掘频繁项集的高校算法,该算法不需要生成候选项集,而是使用模式增长策略。频繁模式(FP)树是一种数据结构。
采用频繁模式树才存储事务项集。自上而下生成树结构,要用到递归方式查找频繁模式。
具体参考算法解析: https://blog.csdn.net/baixiangxue/article/details/80335469
上述三种算法的比较: https://www.cnblogs.com/infaraway/p/6774521.html
2.5 基于最大频繁项集的GenMax算法
该算法用于挖掘最大频繁项集,增加多步来检查最大频繁项集而不只是频繁项集,这部分基于Eclat算法的事务编号集合交集运算,差集用于快速频繁检验。可以通过候选最大频繁项集的定义来确定它。假定最大频繁项集记为M,若X属于M,且X是新得到的频繁项集Y的超集,则Y被丢弃;然而,若X是Y的子集,则将X从M中移除。
2.6 基于频繁闭项集的Charm算法
用于高效挖掘频繁闭项集。
闭项集:给定数据集S,如果对于元素Y是S中的一个项集,X也是Y的一个子集,如果X的支持计数不等于Y的支持计数,那么X成为闭项集,如果X是频繁的,则X是频繁闭项集。
通过频繁闭项集,可以得到具有相同支持度的最大频繁模式。这样可以对冗余的频繁模式进行剪枝。Charm算法还利用垂直事务编号集合的交集运算来进行快速的封闭检查。
2.7 关联规则生成算法

根据算法生成的频繁项集,计算并保存每个频繁项集的支持计数以便于后面的关联规则挖掘过程。
为生成关联规则X—>Y,l =X∪Y,l 为某个频繁项集,需要以下两个步骤:
①首先得到 l 的所有非空子集
②然后,对于 l 的子集X,Y= l -X,规则X—>Y为强关联规则,当且仅当confidence(X—>Y)>=minimumconfidence。一个频繁项集的任何规则的支持计数不能小于最小支持计数。
3.混合关联规则挖掘
3.1 多层次和多维度关联规则挖掘
对于给定的事务数据集,若数据集的某些唯独存在概念层次关系,则需要对该数据集进行多层次关联规则挖掘。
3.2 基于约束的频繁模式挖掘
基于约束的频繁模式挖掘是使用用户设定的约束对搜索空间进行剪枝的启示式算法。
常见的约束有:知识类型约束(指定我们想要挖掘什么)、数据约束(对初始数据集的约束)、维度层次约束、兴趣度约束、规则约束。
4.序列数据集挖掘
序列数据集挖掘的一个重要任务是序列模式挖掘。A-Priori-life算法被用来进行序列模式挖掘,采用广度优先策略。
从序列模式中我们能够发现商店消费者的常见购买模式。
一些常见的序列模式:序列规则、标签序列规则、类序列规则
4.1 序列数据集
序列数据集S定义为元组(sid,s)的集合,其中sid为序列ID,s为序列。
在序列数据集S中,序列X的支持度定义为S中包含X的元组数,即
supports(X)={(sid,s)∨(sid,s)∈S<—X ⊆ s}
这是序列模式的一个内在性质,它应用于相关算法,如Apriori算法的Apriori性质,对于序列X及其子序列Y,support(X)≤ support(Y)。
4.2 GSP算法
广义序列模式算法(GSP)是一个类似Apriori算法,但它应用于序列模式。该算法是逐层算法,采取宽度优先策略,具有以下特征:
(1)GSP算法是Apriori算法的扩展。它利用Apriori性质(向下封闭),即给定最小支持计数,若不接受某个序列,则其超序列也将丢弃。
(2)需要对初始事务数据集进行多次扫描。
(3)采用水平数据格式。
(4)每次扫描中,通过将前一次扫描中发现的模式进行自连接来产生候选项集。
(5)在第k此扫描中,仅当在第(k-1)次扫描中接受所有的(k-1)子模式,才接受改序列模式。
具体算法参考解析: https://www.cnblogs.com/liuqing910/p/8964863.html
5.R语言实现规则挖掘
Spade算法,使用等价类的序列模式发现算法是应用于序列模式的垂直挖掘算法,它采用深度优先的策略,算法特征是:
(1)SPADE算法是Apriori算法的拓展
(2)算法采用Apriori性质
(3)需要对初始数据集进行多次扫描
(4)采用垂直数据格式
(5)算法采用简单的连接运算
(6)所有序列的发现都需要对数据进行三次扫描
从序列模式中生成规则:
序列规则、标签序列规则和类序列规则都可以从序列模式中生成,这些也可以从前面的序列模式发现算法中得到。
6.高性能算法
7.参考资料:
一些算法总结的很好的PPT: https://wenku.baidu.com/view/1142185f30b765ce0508763231126edb6f1a7628.html
https://wenku.baidu.com/view/7c60f77e86c24028915f804d2b160b4e777f8178.html
关于项集的一些定义: https://blog.csdn.net/u013007900/article/details/54743395
下一章将介绍基本分类算法,包括ID3、C4.5和CART等算法,同时也是数据挖掘的重要应用