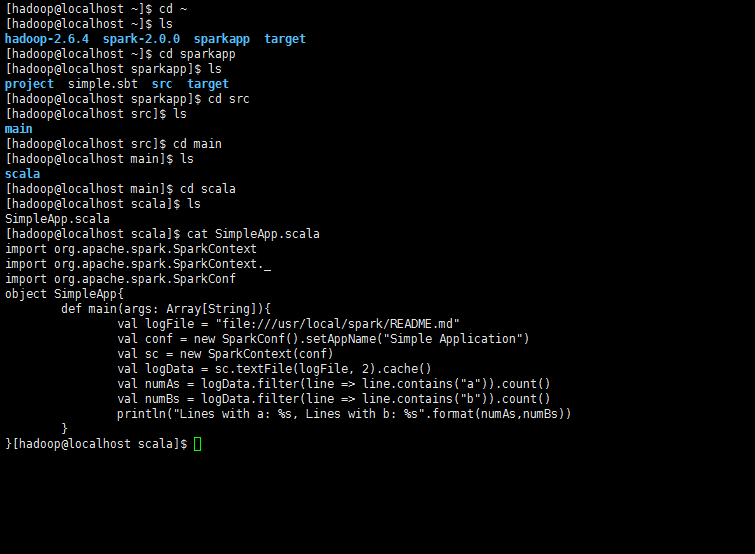
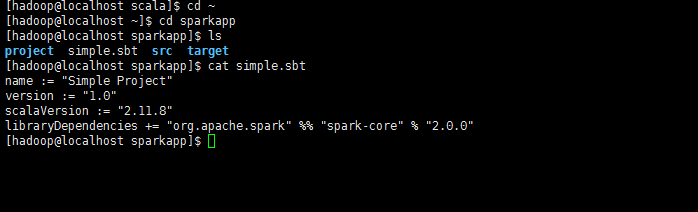
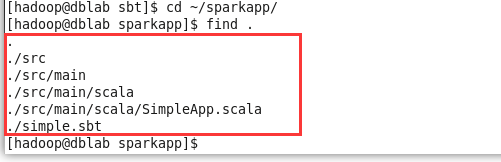
spark的安装和使用
spark最近出了2.0版本,其安装和使用也发生了些许的变化。笔者的环境为:centos7.
该文章主要是讲述了在centos7上搭建spark2.0的具体操作和spark的简单使用,希望可以给刚刚接触spark的朋友一些帮助。
按照惯例,文章的最后列出了一些参考文献,以示感谢。下面我们就来看一下spark的安装。
spark的依赖环境比较多,需要Java JDK、hadoop的支持。我们就分步骤依次介绍各个依赖的安装和配置。spark2.0运行在Java 7+, Python 2.6+/3.4+ , R3.1+平台下,如果是使用scala语言,需要 Scala2.11.x版本,hadoop最好安装2.6以上版本。 由于spark本身是用scala实现的,所以建议使用scala,本文中的示例也大多是scala语言。当然spark也可以很好地支持java\python\R语言。
spark的使用有这么几类:spark shell交互,spark SQL和DataFrames,spark streaming, 独立应用程序。
注意,spark的使用部分,不特殊说明,都是以hadoop用户登录操作的。
1.安装Java环境
我的centos7安装系统的时候选择了安装openJDK的环境,所以可以直接使用。但这里还是列出jdk的安装步骤供大家参考。java环境可以使用Oracle的jdk或者openjdk. 下面的步骤是openjdk的安装示范。
a.首先检查是否安装了jdk, 和版本是否符合要求。
java -version若安装了java环境,但是版本太低,则先卸载原版本,再安装新版本。
卸载可参考以下步骤
yum -y remove java-1.7.0-openjdk* yum -y remove tzdata-java.noarchb.若未安装或已卸载,安装新版本
查看可用版本
yum -y list java*

以安装1.7版本为例
yum -y install java-1.7.0-openjdk*
c.配置环境变量
vi /etc/profile
在文件的最后添加
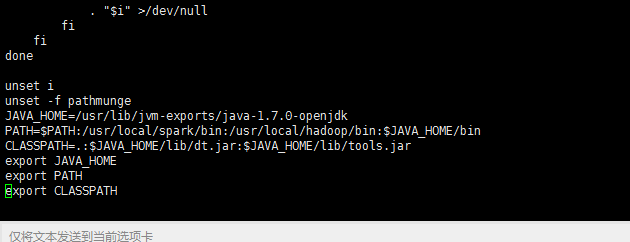
JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk
PATH=$JAVA_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export JAVA_HOME export PATH export CLASSPATH
其中JAVA_HOME是你的java安装路径。其中PATH这个参数是以冒号:来分割不同的项的,后面我们hadoop和spark的环境变量配置也要修改这个参数。
保存退出后,还需要执行
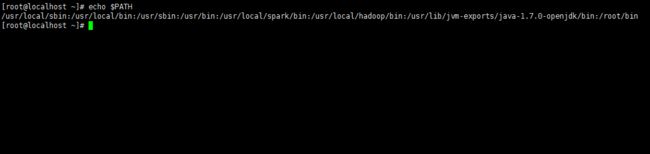
source /etc/profile该文件才可以生效。检查环境变量是否配置生效
echo $PATH
2.安装hadoop
如果你安装 CentOS 的时候不是用的 “hadoop” 用户,那么需要增加一个名为 hadoop 的用户。
a.以root身份登录,添加”hadoop”用户
useradd -m hadoop -s /bin/bash密码输入两次,笔者使用”hadoop”作为密码,比较好记忆。这样,一个用户名为hadoop, 密码也是hadoop的用户就添加好了。
b.可为 hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题
visudo找到 root ALL=(ALL) ALL 这行(应该在第98行,可以先按一下键盘上的 ESC 键,然后输入 :98 (按一下冒号,接着输入98,再按回车键),可以直接跳到第98行 ),然后在这行下面增加一行内容:hadoop ALL=(ALL) ALL (当中的间隔为tab),如下图所示: 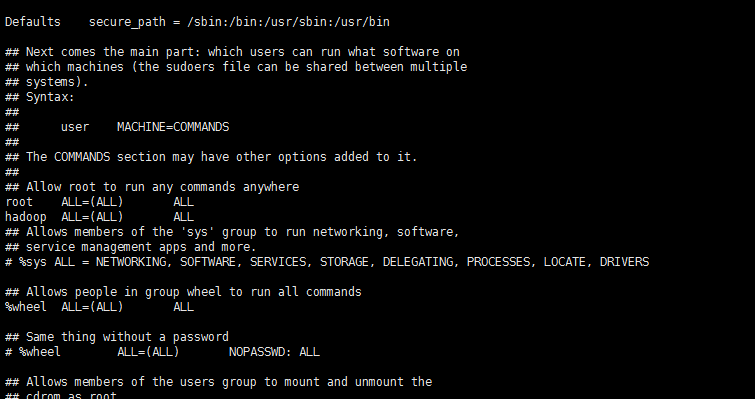
c.centos默认安装ssh. 如果你的操作系统中没有ssh, 可以自行安装,最后的参考资料中有ssh的安装和配置。
d.安装hadoop
去官网下载hadoop的安装包,下载时请下载 hadoop-2.x.y.tar.gz 这个格式的文件,这是编译好的,另一个包含 src 的则是 Hadoop 源代码,需要进行编译才可使用。
下载时强烈建议也下载 hadoop-2.x.y.tar.gz.mds 这个文件,该文件包含了检验值可用于检查 hadoop-2.x.y.tar.gz 的完整性,否则若文件发生了损坏或下载不完整,Hadoop 将无法正常运行。
校验一下下载文件是否完整
cat hadoop-2.6.4.tar.gz.mds | grep 'MD5' # 列出md5检验值 md5sum hadoop-2.6.4.tar.gz | tr "a-z" "A-Z"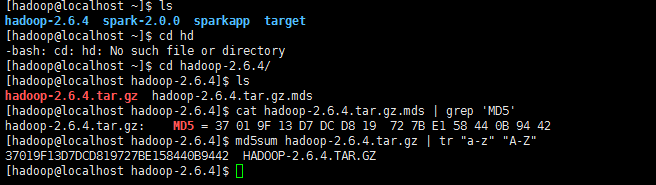
我们选择将 Hadoop 安装至 /usr/local/ 中:
sudo tar -zxf hadoop-2.6.4.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/ sudo mv ./hadoop-2.6.0/ ./hadoop # 将文件夹名改为hadoop sudo chown -R hadoop:hadoop ./hadoop
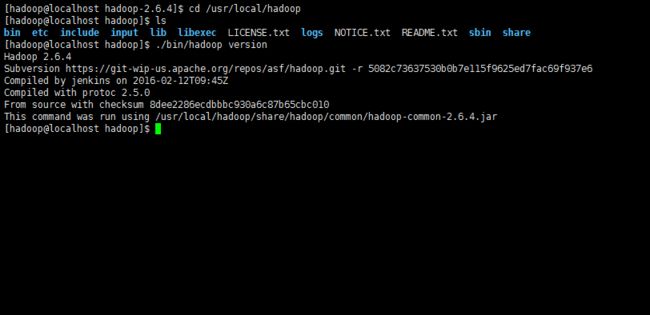
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
cd /usr/local/hadoop
./bin/hadoop version
Hadoop 默认模式为非分布式模式,无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
现在我们可以执行例子来感受下 Hadoop 的运行。Hadoop 附带了丰富的例子(运行 ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar 可以看到所有例子),包括 wordcount、terasort、join、grep 等。 
在此我们选择运行 grep 例子,我们将 input 文件夹中的所有文件作为输入,筛选当中符合正则表达式 dfs[a-z.]+ 的单词并统计出现的次数,最后输出结果到 output 文件夹中
cd /usr/local/hadoop
mkdir ./input
cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+' cat ./output/*
执行信息会很多,最后结果如下图所示: 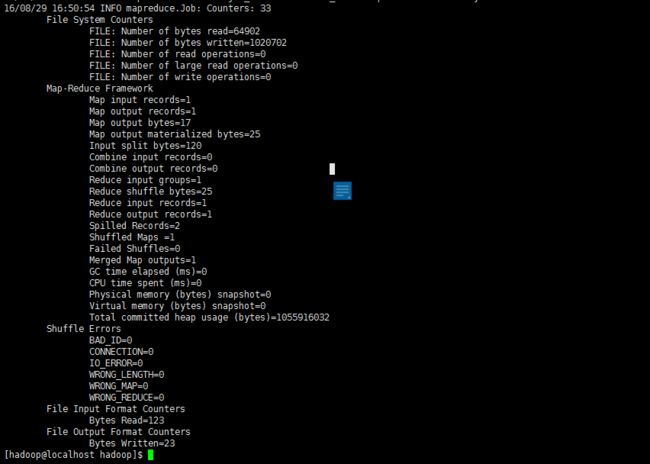
注意,Hadoop 默认不会覆盖结果文件,因此再次运行上面实例会提示出错,需要先将 ./output 删除。
3.spark的安装
a.先到官网下载安装包 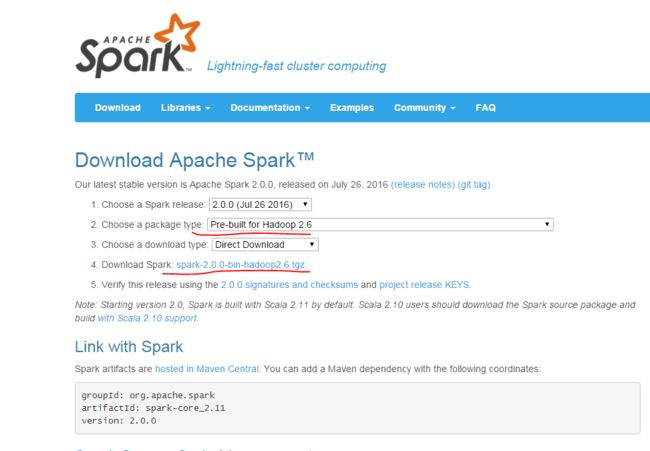
注意第二项要选择和自己hadoop版本相匹配的spark版本,然后在第4项点击下载。若无图形界面,可用windows系统下载完成后传送到centos中。 
b.安装spark
sudo tar -zxf ~/spark-2.0.0/spark-2.0.0-bin-without-hadoop.tgz -C /usr/local/ cd /usr/local sudo mv ./spark-1.6.0-bin-without-hadoop/ ./spark sudo chown -R hadoop:hadoop ./spark # 此处的 hadoop为用户名
c.配置spark
安装后,需要在 ./conf/spark-env.sh 中修改 Spark 的 Classpath,执行如下命令拷贝一个配置文件:
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
编辑 ./conf/spark-env.sh(vim ./conf/spark-env.sh) ,在最后面加上如下一行:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
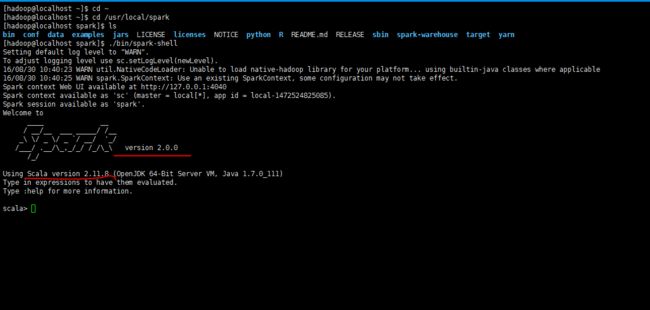
保存后,Spark 就可以启动了。
4.spark的简单使用
在 ./examples/src/main 目录下有一些 Spark 的示例程序,有 Scala、Java、Python、R 等语言的版本。我们可以先运行一个示例程序 SparkPi(即计算 π 的近似值),执行如下命令:
cd /usr/local/spark
./bin/run-example SparkPi
执行时会输出非常多的运行信息,输出结果不容易找到,可以通过 grep 命令进行过滤(命令中的 2>&1 可以将所有的信息都输出到 stdout 中,否则由于输出日志的性质,还是会输出到屏幕中):
cd /usr/local/spark
./bin/run-example SparkPi 2>&1 | grep "Pi is roughly"
过滤后的运行结果如下图所示,可以得到 π 的 近似值 : 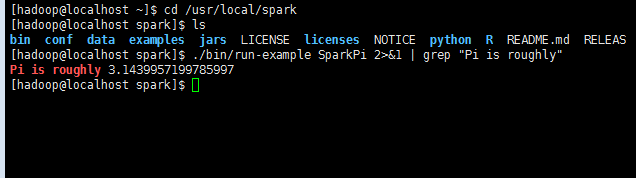
如果是Python 版本的 SparkPi, 则需要通过 spark-submit 运行:
./bin/spark-submit examples/src/main/python/pi.py
5.spark的交互模式
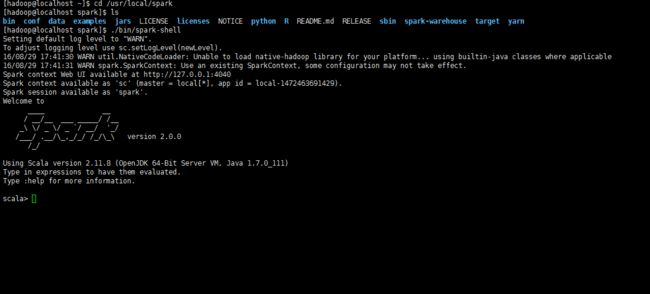
a.启动spark shell
Spark shell 提供了简单的方式来学习 API,也提供了交互的方式来分析数据。Spark Shell 支持 Scala 和 Python,本文中选择使用 Scala 来进行介绍。
Scala 是一门现代的多范式编程语言,志在以简练、优雅及类型安全的方式来表达常用编程模式。它平滑地集成了面向对象和函数语言的特性。Scala 运行于 Java 平台(JVM,Java 虚拟机),并兼容现有的 Java 程序。